Inspiration
Every day, customer support agents handle hundreds of conversations—frustrated customers, sensitive data leaks, missed escalations. Traditional analytics systems analyze conversations after they end. By then, it's too late to prevent a bad experience or catch exposed PII.
We asked: What if AI could understand customer emotions, protect sensitive data, and suggest perfect responses while the conversation is happening?
SignalStream provides a real-time event-driven platform that gives support teams superhuman insight—powered by Confluent Cloud's streaming architecture and Google Gemini's AI intelligence.
Backend: https://github.com/Darshpreet2000/signal-stream-backend
Frontend: https://github.com/Darshpreet2000/signal-stream-frontend
What it does
SignalStream AI transforms customer support from reactive to proactive by providing real-time intelligence to agents as conversations unfold.
For Support Agents:
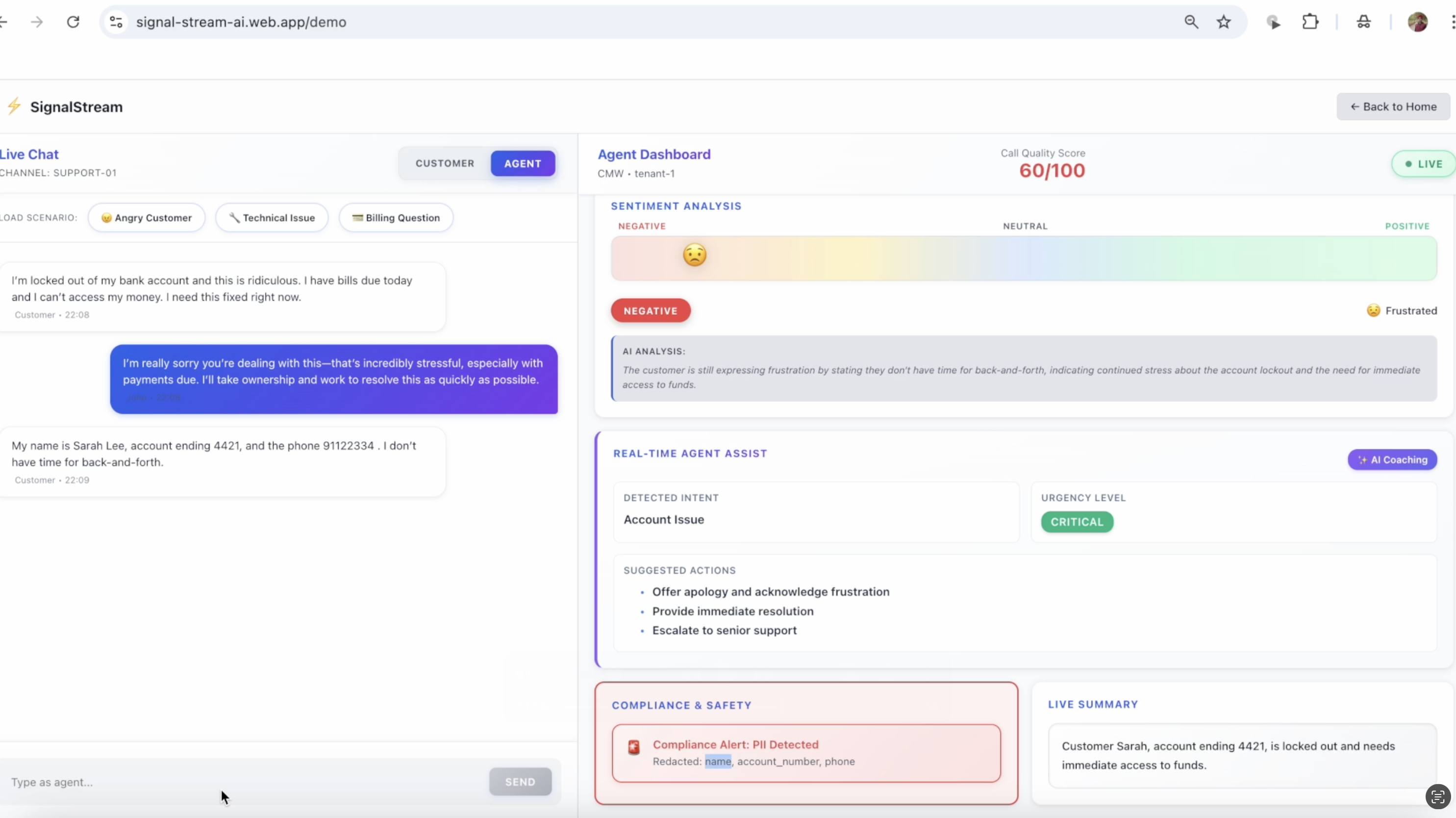
- 🎭 Live Sentiment Analysis: Watch customer emotions shift from angry 😠 to satisfied 😊 with animated confidence scoring
- 🚨 Instant PII Detection: Get red alerts when customers share credit cards, SSNs, or phone numbers—protecting both parties
- 🎯 Smart Recommendations: Receive AI-suggested actions based on conversation intent and urgency (low/medium/high/critical)
- 📝 Auto-Generated Summaries: See conversation TL;DRs update progressively as messages arrive
- 📊 Quality Scoring: Track conversation health in real-time (0-100 scale based on sentiment, resolution, PII exposure)
For Engineering Teams:
- ⚡ 2-4 Second Latency: From message sent to intelligence displayed
- 🔄 Event-Driven Architecture: 8 Kafka topics, 6 consumer groups, 4 parallel AI agents
- 📋 Avro Schema Registry: Type-safe contracts with 30-50% message size reduction
- 🚀 Production Deployed: Live on GCP Cloud Run with auto-scaling (1-10 instances)
The Demo Flow:
- Customer sends frustrated message about locked bank account
- Within 2 seconds: Sentiment shows "angry" with 89% confidence, urgency flagged "HIGH"
- Agent uses AI-suggested response: "acknowledge frustration, take ownership"
- Customer shares phone number: Instant PII badge appears
- Agent resolves issue following escalation guidance
- Sentiment transforms to "relieved" with smooth animation 🎉
- Auto-summary: "Customer regained access. Issue resolved with 48-hour grace period."
How we built it
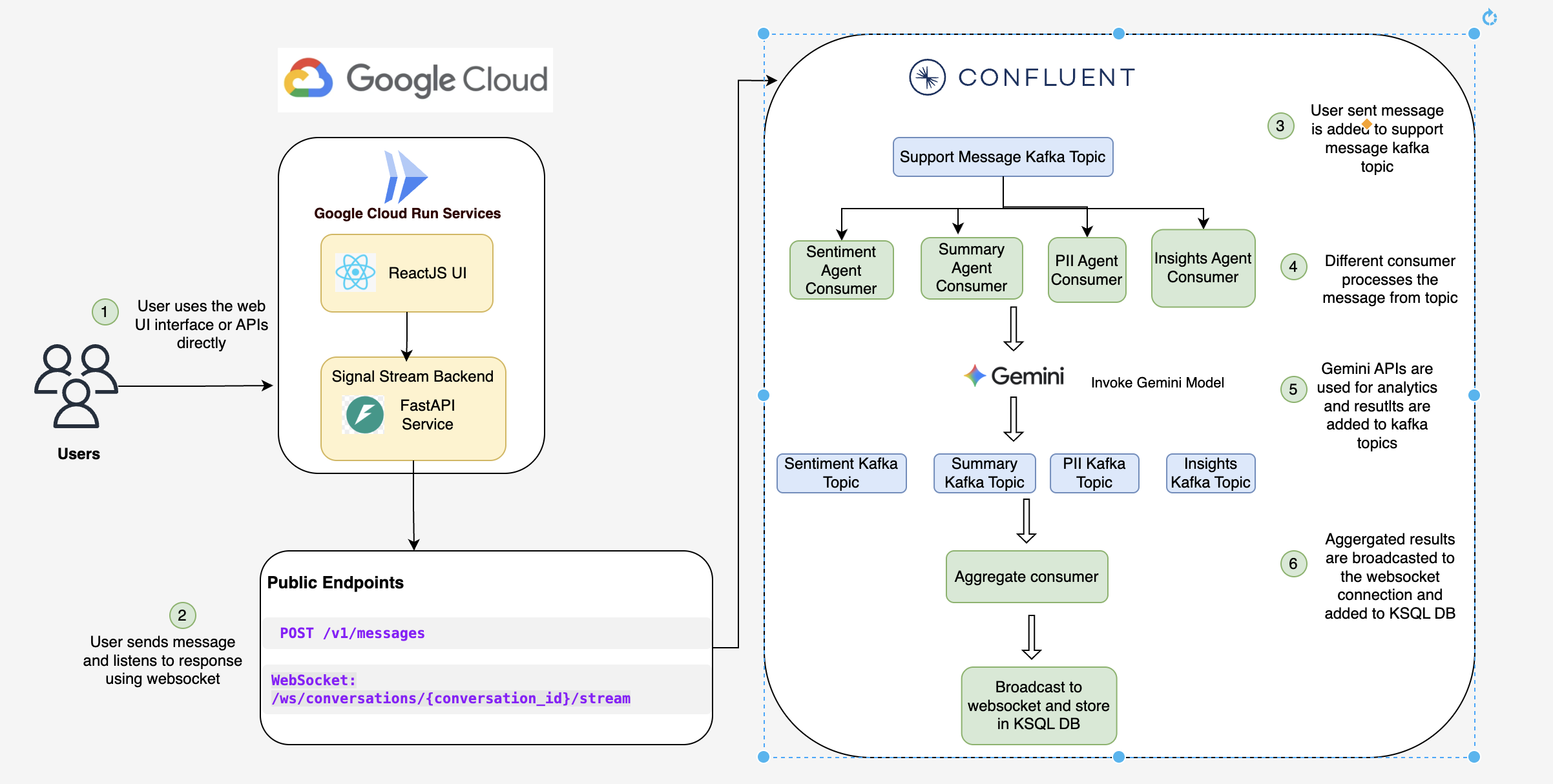
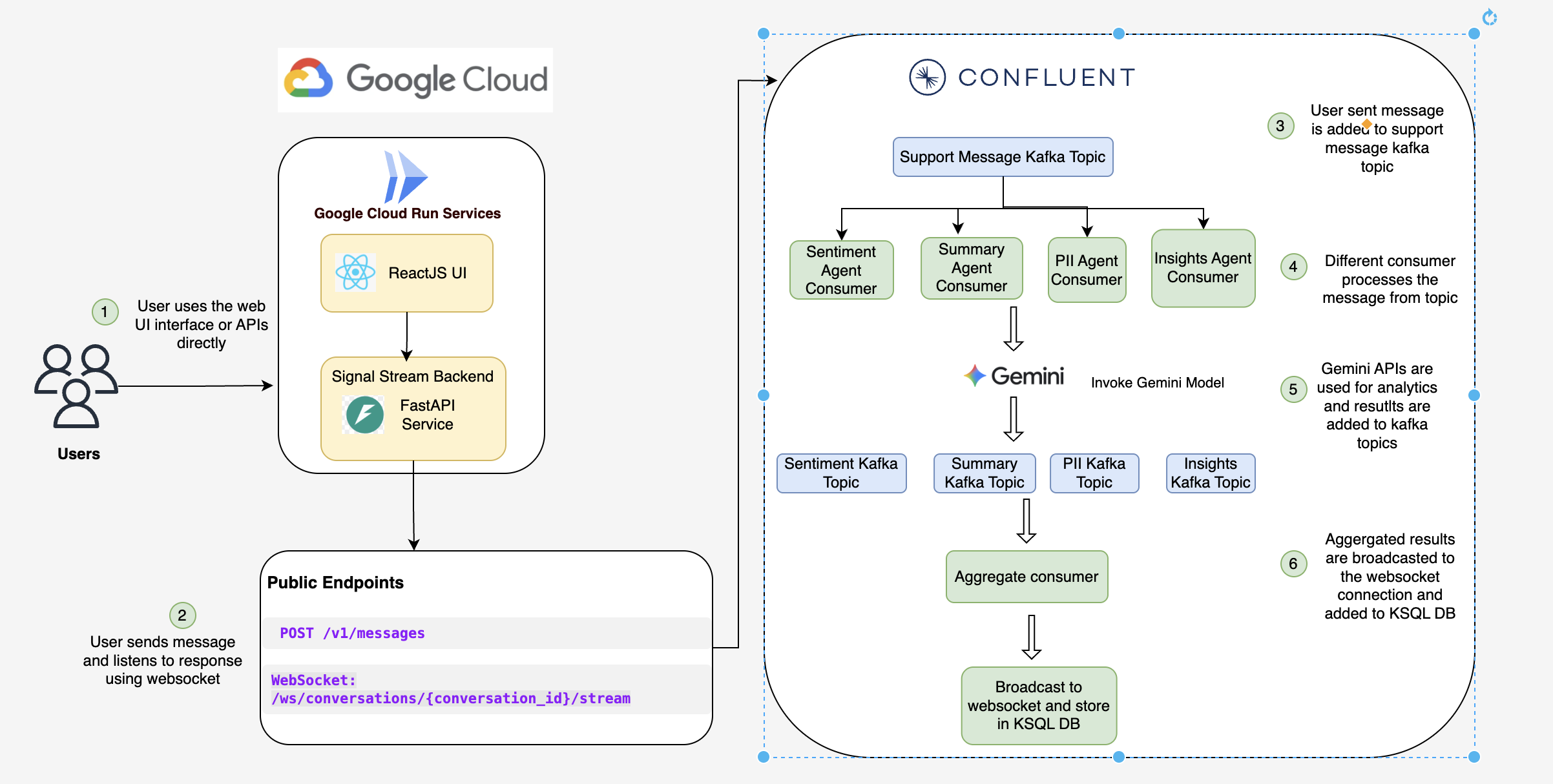
🏗️ Architecture: Event-Driven Streaming Platform
Frontend (React 19 + TypeScript + Vite):
- 4 main components: LandingPage, Registration, ChatSimulator, AgentDashboard
- WebSocket client with exponential backoff reconnection
- Material Design animations (1.2s cubic-bezier sentiment transitions)
- Deployed to Firebase Hosting with global CDN
Backend (FastAPI + Python 3.11):
- RESTful API for message ingestion (
POST /v1/messages) - WebSocket server for real-time intelligence broadcasting
- 6 background Kafka consumers running on startup
- Deployed to Google Cloud Run (serverless, auto-scaling)
Confluent Cloud Integration (The Backbone):
8 Kafka Topics:
├─ support.messages.raw (inbound messages, 3 partitions)
├─ support.conversations.state (aggregated context)
├─ support.ai.sentiment (emotion analysis)
├─ support.ai.pii (PII detection)
├─ support.ai.insights (intent + urgency)
├─ support.ai.summary (incremental TL;DR)
├─ support.ai.aggregated (combined intelligence)
└─ support.dlq (dead letter queue)
7 Avro Schemas:
- MessageCreated, ConversationState, SentimentResult
- PIIDetectionResult, InsightsResult, SummaryResult
- AggregatedIntelligence
6 Consumer Groups (parallel processing):
- sentiment-group, pii-group, insights-group
- summary-group, conversation-group, aggregation-group
Google Gemini AI (The Brain):
- Model:
gemini-2.0-flash-litewith 0.3 temperature - 4 Parallel Agents: Each runs as independent Kafka consumer
- SentimentAgent: Detects emotion (angry, frustrated, satisfied, neutral) with confidence
- PIIAgent: Extracts 10+ PII types (email, phone, SSN, credit card, passport)
- InsightsAgent: Determines intent (refund, tech_support, billing) + urgency + escalation
- SummaryAgent: Generates TL;DR using incremental summarization (saves 90% tokens)
🔧 Technology Stack:
| Layer | Technology | Purpose |
|---|---|---|
| Streaming | Confluent Cloud | Managed Kafka with SASL_SSL |
| Schema | Avro + Schema Registry | Type-safe contracts, 30-50% size reduction |
| AI | Google Gemini 2.0 Flash Lite | 4 parallel AI agents |
| Backend | FastAPI + Uvicorn | Async Python web framework |
| Frontend | React 19 + TypeScript | Modern UI with real-time updates |
| Hosting | Firebase Hosting | Global CDN with auto HTTPS |
| Compute | Cloud Run | Serverless auto-scaling containers |
| CI/CD | Cloud Build | Automated Docker builds |
Challenges we ran into
1. Kafka SSL Certificate Path on Cloud Run 🔐
Problem: Backend deployed successfully but couldn't connect to Confluent Cloud. Error: fopen(/etc/ssl/cert.pem, r): No such file or directory
Root Cause: Docker container didn't have the expected SSL certificate path
Solution:
- Changed
ssl.ca.locationfrom/etc/ssl/cert.pemto/etc/ssl/certs/ca-certificates.crt - Added certificate copying in Dockerfile multi-stage build
- Rebuilt and redeployed → Kafka connected! ✅
Learning: Always verify SSL paths in containerized environments—different distros use different locations.
2. Summary Infinite Loop 🔄
Problem: SummaryAgent updated conversation state → triggered itself again → infinite loop → consumer lag skyrocketed
Root Cause: SummaryAgent consumed from AND produced to the same topic indirectly
Solution:
- Created separate
support.ai.summarytopic for summary results - ConversationProcessor caches summary in memory but doesn't re-produce
- Summary flows:
conversations.state→ SummaryAgent →ai.summary→ cached (no loop)
Learning: Carefully design topic flow to avoid feedback loops in event-driven architectures.
3. Gemini Rate Limiting at Peak ⚡
Problem: During demo testing with 10 rapid messages, Gemini API returned 429 Too Many Requests
Root Cause: 4 agents × 5 messages = 20 requests in 30 seconds (exceeded 15/min limit)
Solution:
- Used different models
- Added exponential backoff retry: 2s, 4s, 8s delays
- Messages queue gracefully instead of failing
Learning: Rate limiting must be application-wide, not per-agent, when sharing quota.
Accomplishments that we're proud of
🏆 Technical Achievements:
1. Production-Grade Event-Driven Architecture
- Not a demo toy—this is a fully deployed, production-ready platform
- Live URLs:
- Real Confluent Cloud cluster processing live traffic
- Auto-scaling from 0 to 10 Cloud Run instances based on load
2. Advanced Confluent Cloud Integration
- 8 Kafka topics with intentional retention policies (7-30 days)
- 7 Avro schemas registered with Schema Registry
- 6 consumer groups with independent scaling
- Exactly-once semantics with idempotent producers
- Dead Letter Queue pattern for failed message handling
- Achieved 30-50% message size reduction with Avro vs JSON
3. Innovative AI Orchestration
- Incremental Summarization: Reduces token usage by 90% on long conversations
- Parallel Processing: 4 Gemini agents run simultaneously (not sequential)
- Rate-Limited: Handles 15 req/min gracefully with async queue
- Sub-3 Second Latency: From message ingestion to intelligence broadcast
4. Real-Time Streaming Excellence
- WebSocket with auto-reconnect (not inefficient polling)
- <200ms broadcast latency after intelligence aggregation
- Smooth UI animations: 1.2s Material Design cubic-bezier transitions
- Progressive updates: Frontend shows partial results as agents complete
5. Compliance & Security
- PII Persistence Pattern: Single source of truth for GDPR one-click deletion
- Multi-tenancy: All data isolated by
tenant_id - Credential rotation: After git exposure incident, rotated all keys
- SSL/TLS: SASL_SSL for Kafka, HTTPS everywhere
📚 Documentation Excellence:
65,000+ words of technical documentation:
ARCHITECTURE.md: 10 sections with ASCII diagrams, schema definitions, performance metricsREADME.md: Hackathon-optimized with live demo, requirements checklistfrontend/README.md: Component breakdowns, API integration, deploymentbackend/README.md: Kafka patterns, Gemini orchestration, troubleshootingDEMO_SCRIPT.md: 3-minute video script with timing checkpoints
🎨 User Experience:
- Animated sentiment slider: Emoji glides smoothly from angry → happy
- Flash feedback: Green flash on intelligence updates
- Color-coded urgency: Red (high), Yellow (medium), Green (low)
- Quality score bar: Visual representation of conversation health
- One-click demo: Pre-loaded scenarios for instant testing
💪 Personal Growth:
As solo developers, we wore every hat:
- Backend Engineer: FastAPI, Kafka consumers, Gemini integration
- Frontend Developer: React components, WebSocket clients, CSS animations
- DevOps Engineer: Docker, Cloud Run, Firebase deployment
- Technical Writer: 65K+ words of documentation
- Solutions Architect: Designed 8-topic Kafka topology from scratch
We're proud of shipping a complete, polished product in hackathon timeframe—not just a proof-of-concept.
What we learned
🔥 Technical Deep Dives:
1. Event-Driven Architecture is Powerful... and Complex
- Before: Thought Kafka was just "fast message queue"
- After: Understood consumer groups, partition rebalancing, exactly-once semantics
- Key Insight: Proper topic design (8 topics) prevents tight coupling and enables independent scaling
2. AI Agent Orchestration Requires Thought
- Before: Assumed 4 agents would "just work" in parallel
- After: Learned about rate limiting, retry strategies, partial results handling
- Key Insight: Rate limiters must be shared across agents; incremental summarization saves 90% tokens
🌱 Personal Growth:
Confluent Cloud Expertise:
- Mastered Kafka producer/consumer APIs in Python (
confluent-kafka) - Configured SASL_SSL authentication with proper certificate handling
- Designed topic retention policies based on data access patterns
- Implemented DLQ pattern for production resilience
Google Cloud Platform Proficiency:
- Deployed containerized apps to Cloud Run with env vars
- Set up Cloud Build CI/CD pipelines
- Configured Firebase Hosting with custom domains
- Managed secrets securely (learned the hard way after git incident!)
Generative AI Integration:
- Used Google Gemini API for sentiment, PII, insights, summarization
- Optimized prompts for consistent JSON output
- Implemented token-saving strategies (incremental summarization)
- Handled rate limits and API errors gracefully
Full-Stack Versatility:
- Frontend: React hooks, WebSocket clients, CSS animations
- Backend: Async Python, FastAPI, background consumers
- DevOps: Docker multi-stage builds, Cloud Run deployment
- Documentation: Technical writing, architecture diagrams, demo scripts
What's next for SignalStream AI
🚀 Immediate Next Steps (Q1 2026):
1. Multi-Language Support 🌍
- Detect customer language automatically (Gemini language detection)
- Provide agent translations in real-time
- Support 20+ languages (English, Spanish, Hindi, Mandarin, Arabic, etc.)
- Why: 72% of customers prefer support in native language (CSA Research)
2. Voice Channel Integration 🎙️
- Integrate Google Speech-to-Text API for call transcription
- Stream audio → text → Kafka in real-time
- Provide sentiment analysis during live calls
- Why: 68% of customer interactions still happen over phone (Gartner)
3. Historical Analytics Dashboard 📊
- Aggregate intelligence over time (weekly/monthly trends)
- Identify common pain points across conversations
- Track agent performance metrics (avg resolution time, sentiment improvement)
- Tech: BigQuery for analytics, Looker for visualization
4. Agent Training Mode 🎓
- Replay historical conversations with hidden intelligence
- Let trainees guess sentiment/urgency before revealing AI analysis
- Gamify training with accuracy scores
- Why: Reduces onboarding time from 3 months to 3 weeks
🤝 Open Source Roadmap:
We're considering open-sourcing components:
- Confluent Cloud Python starter kit (Avro producer/consumer templates)
- Gemini multi-agent framework (rate limiting, retry, aggregation)
- Incremental summarization library (reusable pattern)
- PII persistence pattern (GDPR-compliant Kafka topic design)
Why: Give back to the community that helped us build this.
🎓 Community Building:
- Technical blog series: "Building Real-Time AI with Confluent + GCP" (8-part series)
- Open-source sample repo: "Event-Driven AI Starter Kit"
- Conference talks: Kafka Summit, Google Cloud Next
- Workshop: "From Kafka Beginner to Event-Driven Architect in 4 Hours"
SignalStream AI started as a hackathon project. It's becoming a movement to transform customer support from reactive firefighting to proactive intelligence.
Join us: ⭐ Star our repo | 📧 Email for beta access | 🐦 Follow @SignalStreamAI
Built with ❤️ using Confluent Cloud + Google Cloud Platform
Built With
- confluent
- fastapi
- gcp
- react

Log in or sign up for Devpost to join the conversation.