Inspiration
As avid Valorant players and passionate fans of the Valorant Champions Tour (VCT), we were excited to dive deep into the world of esports data. Watching the pros dominate the competitive scene left us curious about the vast amount of data available behind the scenes. Our mission? To explore how this data could be used to better understand team strategies, individual player performance, and how it all ties together into creating the ultimate VCT team.
The project started out as a simple curiosity, but quickly evolved into a full-fledged exploration of team composition theory, the strengths and weaknesses of players, and ultimately how foundational models and data science could provide insights into building winning rosters.
What It Does
The VCT Team Building tool uses a prompt flow to categorize user inputs and streamline decision-making through specialized agents. Here's how the process works:
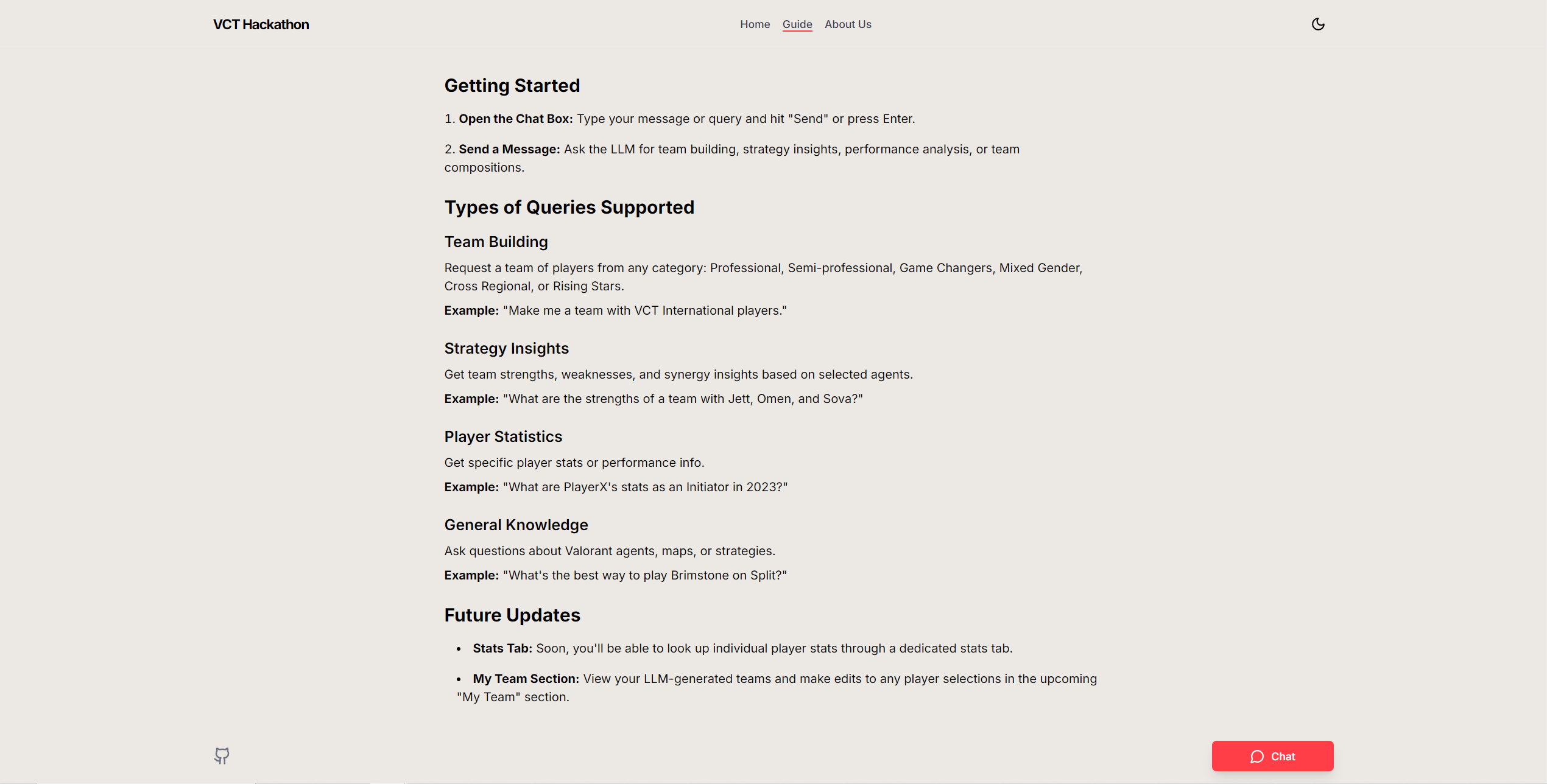
Input Classification: The system begins by using a language model prompt to classify the user input into one of four categories:
- Team Building
- Team Strategy
- Player Performance
- General Questions
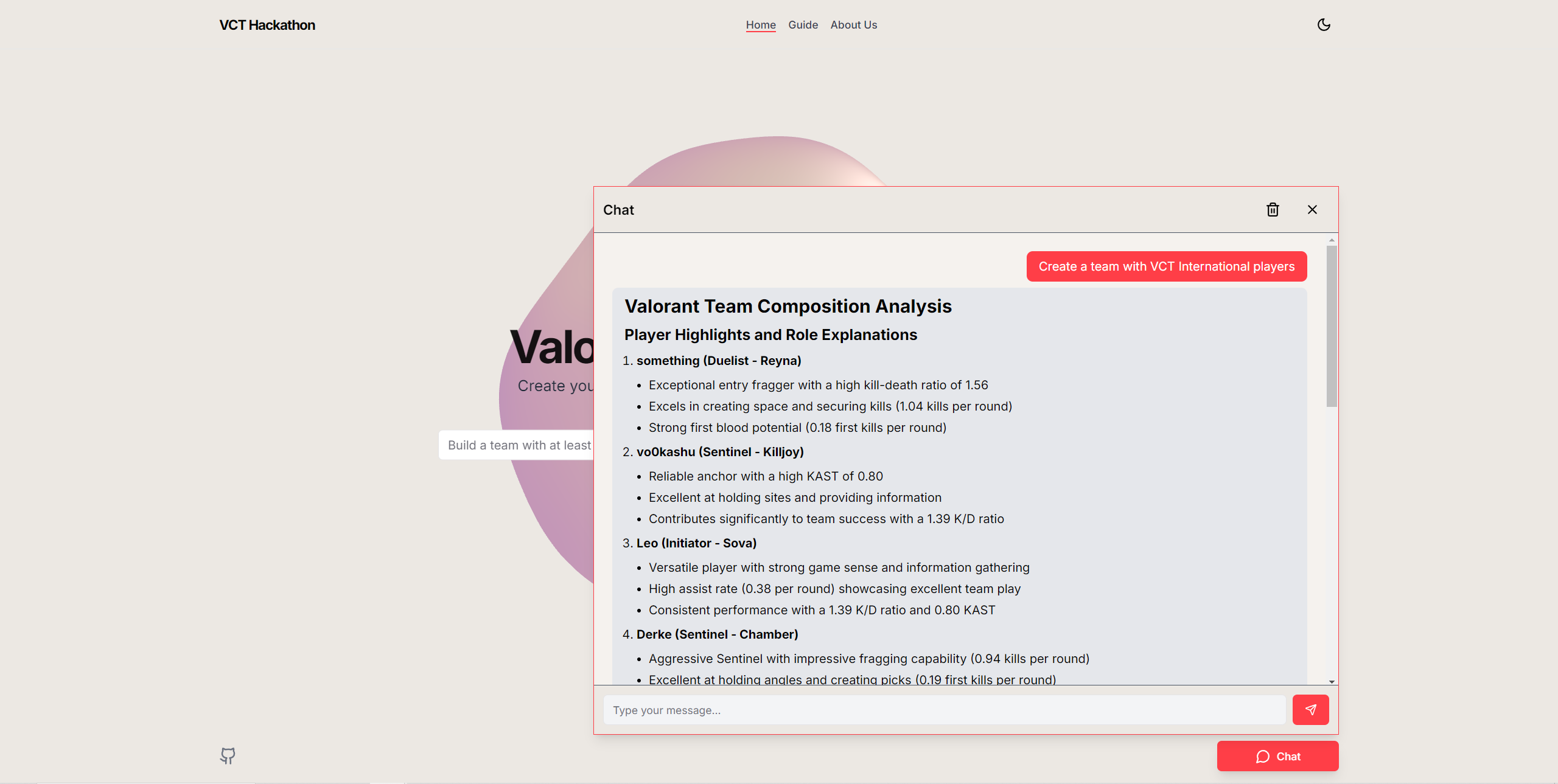
Team Building Agent: In this mode, the tool selects the top 5 players for each role (Duelist, Controller, Initiator, Sentinel, Flex) or based on specific agent picks according to map selection. These top players are then passed to the LLM agent, which decides the final team composition and provides reasoning behind the choices. This ensures balanced team selections that align with in-game strategies and player strengths.
Team Strategy Agent: This agent queries the database to gather information on team strategies and synergies. It pulls data from historical matches and pre-determined team compositions to offer insights into how specific teams or agent combinations can be used to maximize in-game effectiveness.
Player Performance Agent: This agent is dedicated to querying the database for individual player statistics. It allows the user to access specific performance metrics for any player, such as their Kill/Death ratio, assists, or other relevant statistics, depending on the role they play.
General Questions Agent: For broader, non-specific queries, this agent provides answers to general questions about Valorant or VCT, offering more general insights.
This prompt flow ensures that the right context and data are provided based on the user’s query, enabling efficient and intelligent team building, strategy formation, and performance analysis.
How we built it
The process started by analyzing the Riot data available, which we quickly found to be difficult to derive insights from—pushing us to explore other sources like VLR.gg and rib.gg. Here's the step-by-step breakdown of how we built the project:
Scraping Third-Party Data: We wrote scripts to pull data from VLR.gg and rib.gg, ensuring we got the most up-to-date player stats and team compositions for Valorant.
Data Preprocessing: We cleaned and standardized the data, generating new features like IGL score and flex score to make comparisons easier.
Player Selection Logic: We established specific metrics for each role (Duelist, Controller, Sentinel, Initiator, and Flex) based on stats like First Kills Per Round (FKPR), Kill-Assist-Survive-Trade (KAST), and Average Combat Score (ACS). This helped guide our LLM in choosing the right player for each role.
AWS Architecture: While we did some data preprocessing locally, the core system was built on AWS, with Lambda functions handling database queries, Bedrock providing LLM prompt flows, and Amplify acting as the frontend to deliver results to users in a seamless interface. Although we could have set up the data scraping on Lambda, we opted to do it locally due to time constraints and our level of experience with AWS.
Prompt Flow Design: We designed the prompt flow to make sure it could handle four main intents: team building, player performance, team strategy, and general questions about Valorant. By categorizing inputs and querying the database when necessary, the LLM could generate precise insights.
Team Building Logic: We built rules to avoid common issues like duplicate agent picks for the Flex role and integrated specific constraints for mixed-gender and cross-regional teams, ensuring our selections complied with real-world scenarios.
Challenges we ran into
Data Availability: One of the biggest challenges was sourcing reliable and up-to-date data. While Riot’s official data was plentiful, it was difficult to use. Third-party sites like VLR.gg and rib.gg provided the insights we needed but required substantial data scraping and processing efforts.
Cost Efficiency: Fine-tuning LLMs for our use case was not feasible due to the high cost, so we focused on cost optimization by relying on prompt engineering and dynamic querying instead. This allowed us to avoid training models from scratch while still getting high-quality results. Additionally, Claude 3.5 Sonnet was quite expensive, so we explored using Claude 3 Haiku in as many places as possible to reduce costs. We reserved Sonnet only for areas that required more critical thinking, such as team reasoning and complex decision-making.
Model Bias: We faced some struggles in controlling the LLM’s behavior when it came to team composition. The model sometimes picked repeat agents for different roles, particularly the Flex role, despite our constraints, requiring us to rethink how we structured prompts and set up rules to enforce unique selections.
Token Limit Constraints: With the resource limit on the Bedrock agent’s prompt input, we had to be careful with how much data was included in each prompt. This led us to implement a multi-step prompt flow, which ensured the model had the right context for generating accurate results while staying within the agent's input constraints.
AWS Amplify Response Limits: Another challenge we encountered was with AWS Amplify, which times out requests exceeding 30 seconds, resulting in 504 errors. This limitation forced us to keep the LLM response times shorter by relying on simpler models and optimizing prompt flows, ensuring quicker responses to avoid timeout errors while maintaining high-quality outputs.
Accomplishments We’re Proud Of
Cost Effectiveness: One of the key accomplishments of this project was finding cost-effective solutions to integrate large language models (LLMs). Instead of using expensive fine-tuning or creating a knowledge graph, we optimized costs by relying on prompt engineering and querying a structured database. By strategically using Claude 3 Haiku and Claude 3.5 Sonnet, we minimized expenses while maintaining high-quality insights. This approach allowed us to achieve our goals without exceeding budget constraints.
Robust AWS Architecture: The project was built using a well-structured AWS architecture, combining services such as Bedrock for LLM management, Lambda for serverless database querying, Amplify for frontend deployment, and RDS for storing player and team data. This architecture ensured that the system was scalable, flexible, and efficient. It allowed us to seamlessly query databases, deliver prompt-driven insights, and optimize performance, all while keeping the infrastructure lean and cost-efficient.
User-Friendly Interface: We are proud of the user-friendly interface that enables seamless interaction with complex data. By designing a chatbox interface that classifies user inputs and automates player selection, team strategy, and performance analysis, we made advanced esports analytics accessible to all users. The intuitive design ensures that users can build teams, analyze stats, and gather strategic insights effortlessly, all within a simple and responsive platform.
What we learned
Through this project, we gained an immense understanding of various concepts, including:
Data Preprocessing: One of the first challenges was preparing the raw data for analysis. With data sourced from multiple places, including VLR.gg for player stats and rib.gg for team compositions, we had to clean, transform, and standardize this data before feeding it into our model.
Web Scraping: Not all the data we needed was readily available, so we employed web scraping techniques to pull relevant information from third-party sites, including player statistics and team compositions.
Foundational Models & Fine-Tuning: We learned the advantages and challenges of using large language models (LLMs), and why fine-tuning models for our specific use case was a costly endeavor. Instead, we focused on prompt engineering and integrating structured data to get the best results from our LLMs without needing to fine-tune.
Prompt Engineering & Retrieval-Augmented Generation (RAG): Initially, we explored using RAG to dynamically pull relevant information from a knowledge base during inference. However, we struggled to get the results we wanted, primarily due to how we chunked out the data. The model had trouble retrieving the right context, which led to suboptimal answers. Moreover, we found the RAG approach to be quite costly, both in terms of processing and storage. As a result, we pivoted to a more efficient solution—querying a database for specific data points and integrating those into our prompt engineering. This method proved to be both cost-effective and reliable, allowing the LLM to deliver precise insights without the complexity of managing a large knowledge base.
AWS: Working with AWS services like Bedrock, Lambda, Amplify, and RDS, we developed an efficient cloud-based architecture to handle player data queries, manage agent performance, and present team strategies. This also helped with cost optimization by leveraging different model variants (Claude 3 Haiku and Claude 3.5 Sonnet) to minimize expenses while maintaining quality.
What’s Next
User Authentication: The next step is to implement user authentication, allowing users to create accounts, log in, and save their progress. This feature will provide a personalized experience, enabling users to manage their teams and track their interactions with the tool over time.
Team Management on the UI: We plan to enhance the UI by introducing a "My Team" section where users can view their LLM-generated teams directly on the website. This section will allow users to edit player selections, tweak their compositions, and save their preferred lineups, giving them greater control over team building.
Player Stats and Team Strategy Review: We will also introduce a stats tab where users can review detailed player statistics and analyze team strategies directly on the platform. This will allow for deeper insights into performance metrics and strategic planning, giving users the ability to explore the data behind their teams without leaving the site.
Update
After experiencing timeout limitations with AWS Amplify—where requests that exceeded 30 seconds would result in 504 errors—I made the decision to switch to an alternative service. Despite multiple attempts, I was unable to find a workaround that allowed Amplify to handle the LLM responses without timing out.
In addition, I implemented another step in the prompt flow specifically for follow-up questions, which uses the same agent as the Team Building category to maintain context and memory. This enhancement ensures that the system retains continuity across multiple queries, allowing users to build on previous insights and receive responses that consider prior interactions. By retaining context about previously asked questions, the tool now offers a more cohesive and fluid user experience, enabling deeper exploration into queries without losing track of earlier interactions.
What Would We Do If No Throttling Issues
If there were no throttling issues, the project’s core structure and functionality would largely remain the same. However, we would have fully leveraged more advanced Claude models, like Claude 3.5 Sonnet v2 and Claude 3 Sonnet, without needing to compromise due to cost and processing limitations. To mitigate the throttling issues, it seemed Claude 3 Haiku currently doesn't have throttling issues. This would have allowed us to enhance certain areas requiring complex reasoning, such as team reasoning and intricate decision-making processes, delivering even more robust and nuanced insights for team building and strategy.
Currently, the throttling issues sometimes cause the model to return messages like “No response provided” or “Sorry, the model cannot answer that.” The fix for this is to wait a little bit and then try again, as the model should work fine after a brief pause.
Built With
- amazon-bedrock
- amazon-rds-relational-database-service
- amazon-web-services
- aws-amplify
- aws-lambda
- javascript
- next.js
- pandas
- python


Log in or sign up for Devpost to join the conversation.