-
-

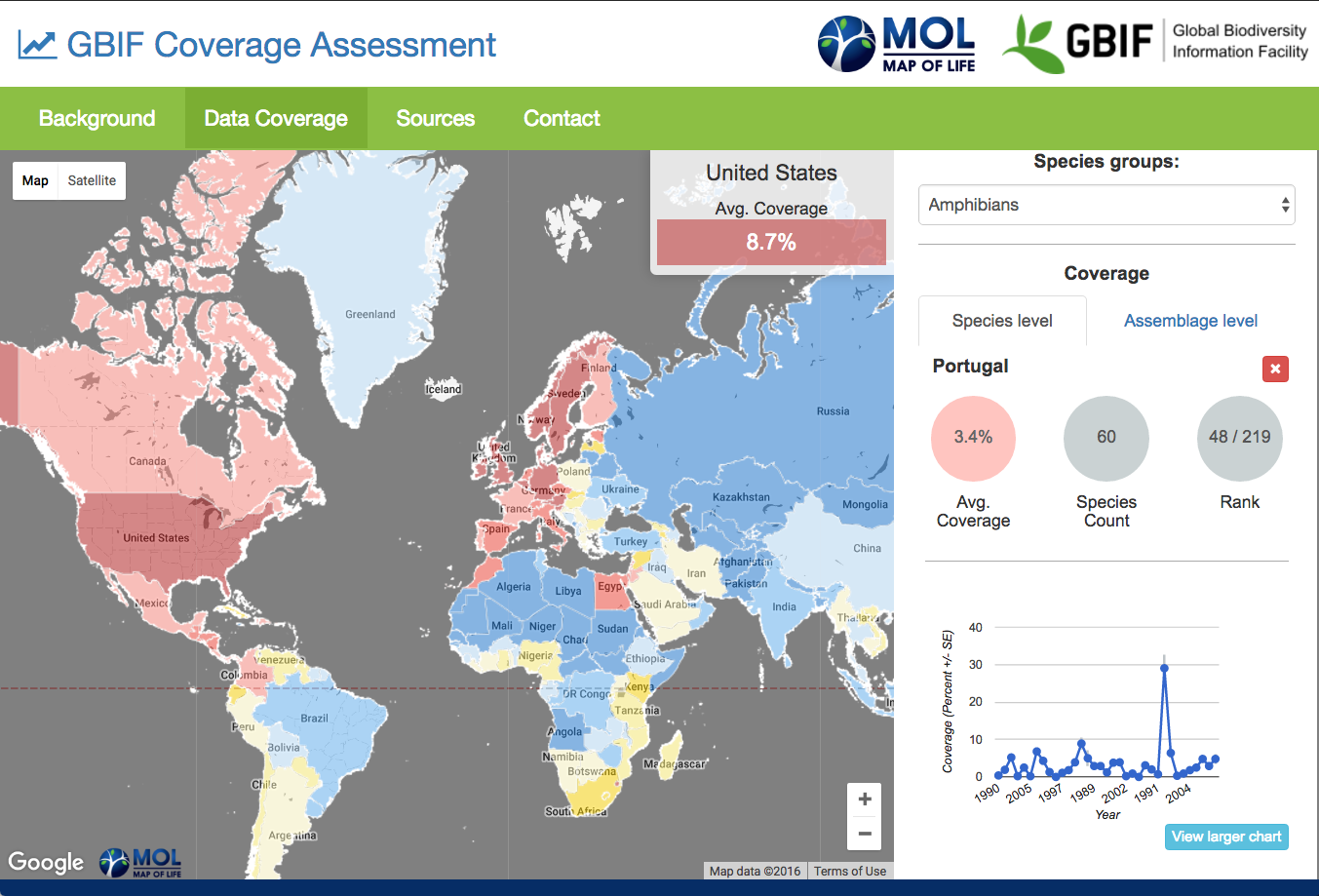
Species-level coverage of GBIF data for Amphibians: global variation in average annual coverage, and temporal trends in Portugal
-
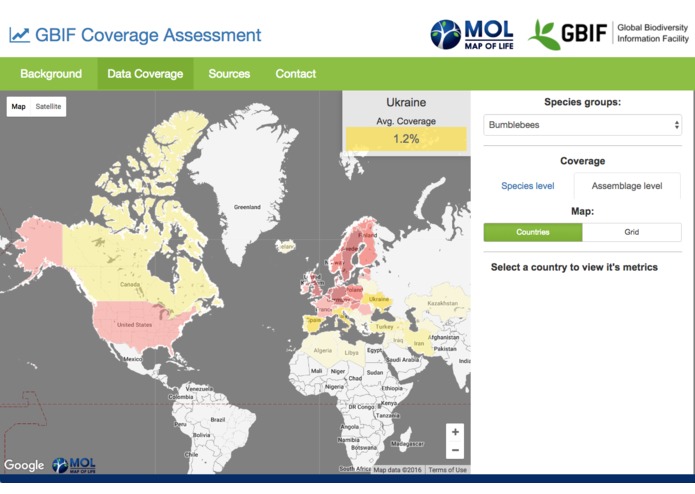
Assemblage-level coverage by GBIF data for bumblebees, averaged across years and countries
-
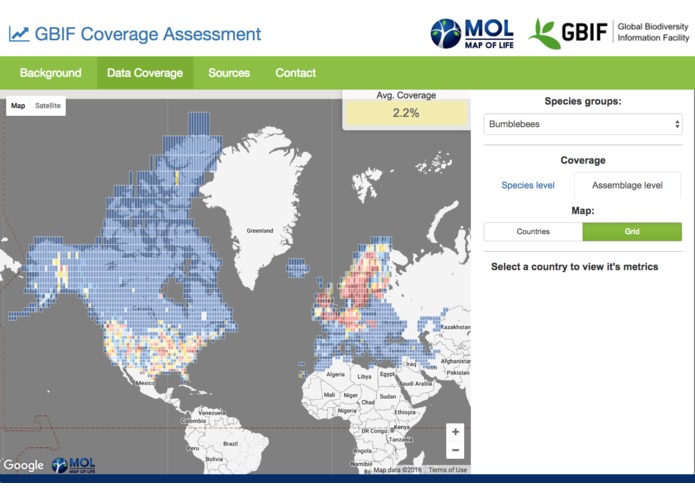
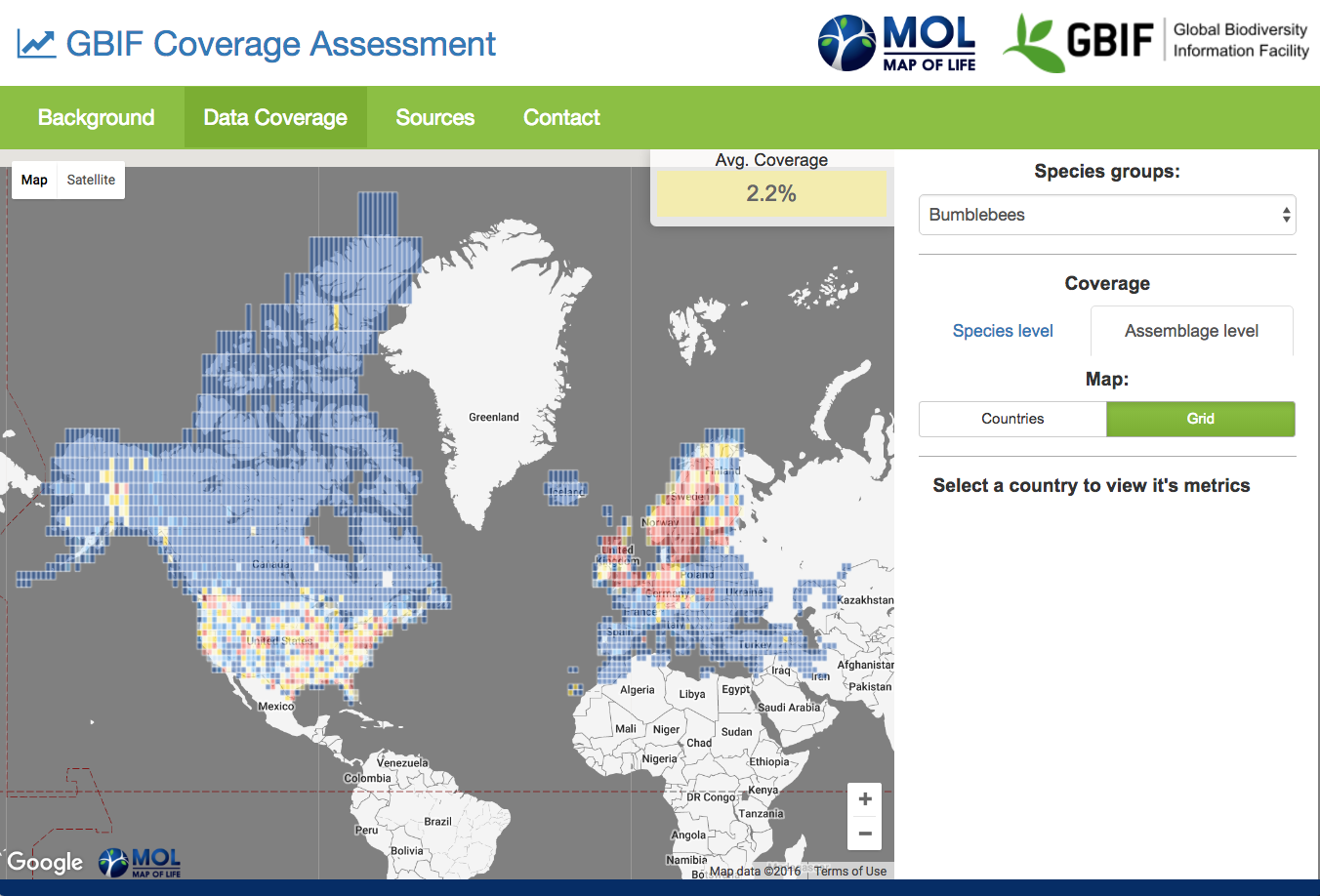
Assemblage-level coverage of GBIF data for bumblebees, at grid cell level and averaged across years
-
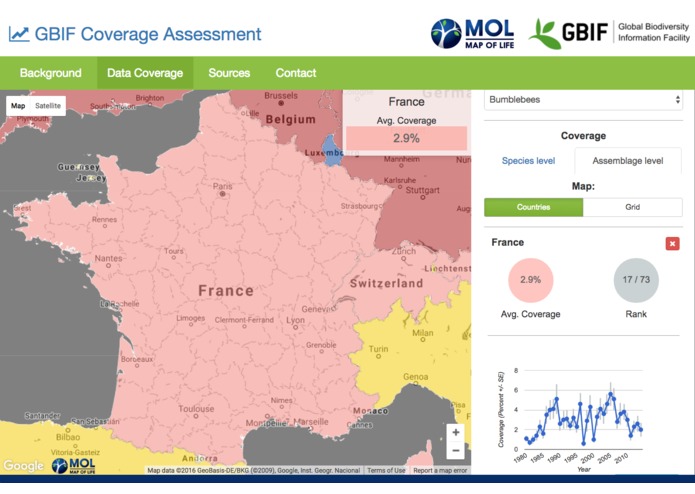
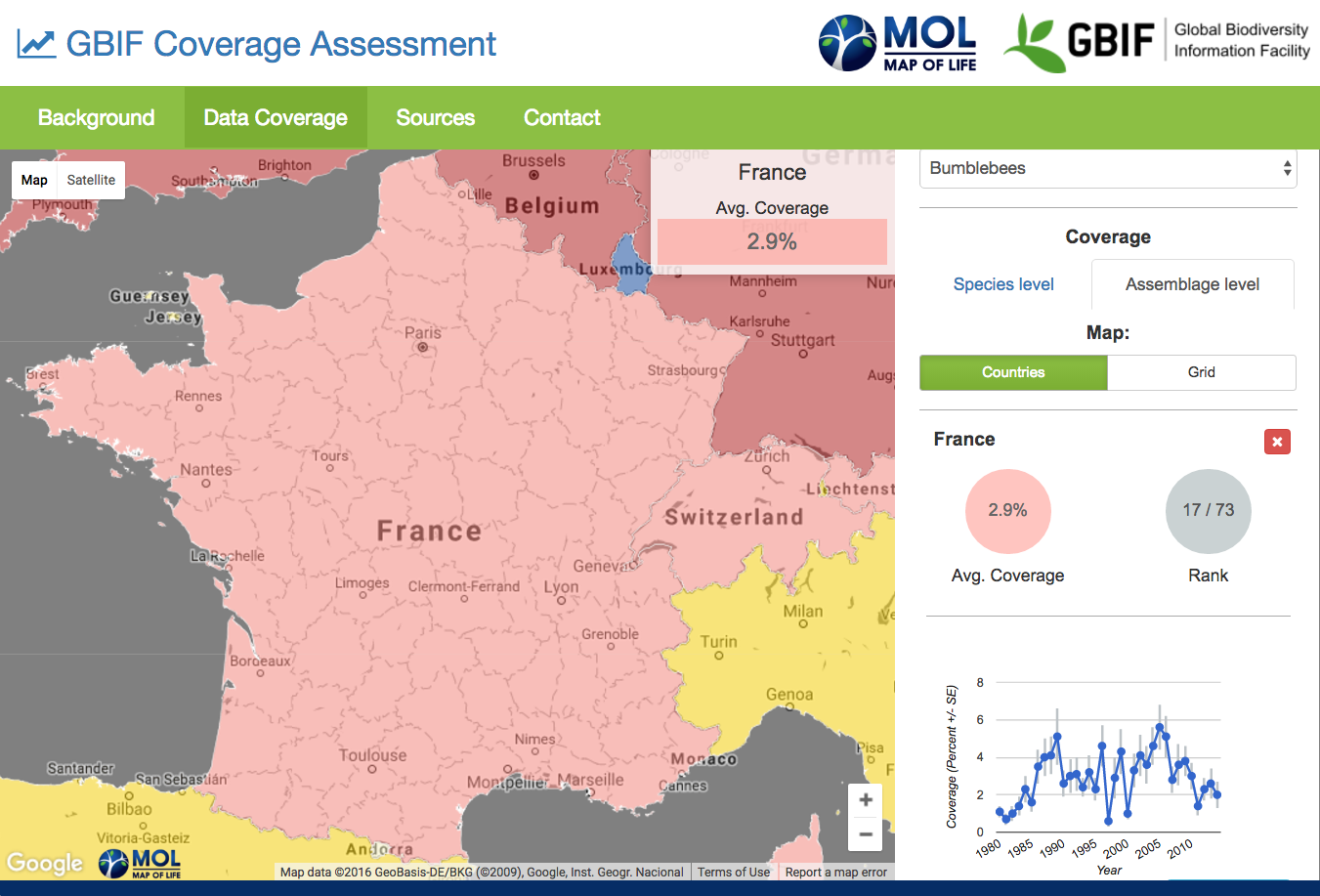
Assemblage-level coverage of GBIF data for bumblebees, annual trend for France

URL: https://mol.org/indicators/coverage
Inspiration
Primary species occurrence records as mediated through GBIF are essential for a detailed understanding of the distribution of biodiversity in space and time. Yet, despite an impressive recent growth and now hundreds of millions of accessible records, the ability of this vast information to represent biodiversity and its change has remained largely unquantified. In the case of a relatively small and species-poor region, a small number of records may effectively characterize the distribution of species or composition of assemblages year after year. In contrast, in the case of a large and hyperdiverse region, even a large number of records may only poorly do so, especially if data is repeatedly coming from just a small portion of species, locations, or years.
Consequently, assessment of how well GBIF-mediated data represent species ranges or assemblage make-up over time, or how well-suited those data are for associated modeling and inference, requires information about an expectation: How well are mobilized data actually representing expected taxonomic, spatial, and temporal variation in biodiversity? Recent research by members of our team developed the use of expert-based information for this purpose (Meyer, C., H. Kreft, R. Guralnick, and W. Jetz. 2015. Global priorities for an effective information basis of biodiversity distributions. Nature communications 6: 8221).
For the Ebbe Nielsen Challenge, we, over the past couple of months, developed a suite of novel informatics tools and services that build on these concepts and report, spatially explicit, on temporal trends in data gaps and biases among countries. The concepts behind our metrics have been have been endorsed as sound quantification of species occurrence data gaps (“Species Status Information Index”) by GEO BON (http://geobon.org/geo-bon-presents-a-new-generation-of-biodiversity-indicators-at-cbd-ahteg), and recently IPBES and the CBD (https://www.cbd.int/doc/strategic-plan/strategic-plan-indicators-en.pdf). After initial offline explorations for just a few taxa and continental resolution, it was over the summer, triggered by the Ebbie Nielsen competition, that we decided to take the metrics to country scale and annual resolution, extend them flexibly to many more taxa, and build interactive visualizations and embeddable components and services. We designed these tools with components embeddable in partner websites and with the potential of automated country reports that in collaboration with GBIF could be built out to be near-real-time. Information about gaps and biases in this coverage, and how successful countries and their institutions are in closing them is vital. It can help identify priority targets for data collection and mobilization, inform about the suitability of data for modeling and inference.
What it does
The GBIF Coverage Tools characterize coverage of data mobilized for a given species group, country and year by setting it in relation to expert expectation across a standardized grid. Two metrics are calculated:
Species-level Coverage measures how well, on average, GBIF-mediated data characterize the broad distributions of species. Specifically, it is the proportion of grid cells expectedly occupied by a species with records in a given year, averaged across all species in a country. In a given year, a value of 1.00 would suggest that at least one record is available for every range cell of all species occurring in a country, i.e. a complete species distribution coverage for this spatial resolution.
Assemblage-level Coverage measures how well, on average, GBIF-mediated data characterize the makeup of grid cell assemblages. Specifically, it is the proportion of species expected to occur in a cell that have been recorded in a given year, averaged across all cells in a country. In a given year, a value of 1.00 would suggest that at least one record is available for all species expected in each of a country’s grid cells, i.e. complete assemblage structure coverage for this spatial resolution. This metric can be shown as country average or for individual cells to learn about within-country data gaps and biases that may inform future sampling and mobilization.
The two metrics convey distinct messages. The magnitude and temporal trends in a country’s Species-level Coverage inform about how well it’s mobilized data may be suited for characterizing species distributions and their changes over time for a given species group (directly, or through modeling). In contrast, the ‘Assemblage-level Coverage’ measure would relate questions about the status and changes in the makeup of communities, and their associated aggregate functions.
Calculations are performed over a standardized global grid of ca. 150-km resolution at the equator for which expert expectations are deemed broadly reliable (see Hurlbert, A. H., and W. Jetz. 2007. Species richness, hotspots, and the scale dependence of range maps in ecology and conservation. PNAS 104:13384-13389). Expert expectation information is pulled in from Map of Life, and for the sources used assumed to be broadly characteristic for the past 35 years. We carefully developed synonym lists to match species names in GBIF-mediated data to names used for the expert information. We note, however, several caveats: expert maps may suffer from errors of omission and commission that even at this coarse spatial resolution may slightly affect metric values; the currently used grid is not equal-area; taxonomic mismatches may remain in the data. In future updates, we plan to replace expert maps with increasingly sophisticated multi-source, modeled maps, move to an equal area grid, and further improve the synonym match-up.
How we built it
Efficiently intersecting GBIF’s half a billion point records with the 45,000+ species expert polygons (from Map of Life, MOL) and country data presented our largest challenge. Performing these intersections via our Postgres/PostGIS backend proved to be quite slow and error prone, so a more scalable approach was needed. To solve this, we encoded location data from both datasets using the geohash algorithm.
Google’s BigQuery data archiving and analysis system was used to quickly calculate geohashes across all GBIF records and aggregate by species and year to lower precision (3 geohash characters, ~156 km resolution at the equator). Species range and region (country) polygons were filled using PostGIS geohash functions in the Map of Life Postgres backend. Final queries to generate statistics shown in the UI were then run in Postgres and exported to the Carto mapping service, which serves maps and data through an API to a JavaScript driven front-end.
What's next
We look forward to building significantly on this initial set of tools developed for the Ebbe Nielsen Challenge. These include extensions of the taxonomic coverage, improvements to the scientific rigor, inclusion of additional knowledge dimensions, reporting to the mobile app, and misc. design, reporting, and performance improvements.
In the coming weeks and months we will add a variety of taxonomic groups. These include specific plant groups and also all plants (providing the assemblage-level metric and using gridded modelled-plant species richness as expectation). We will also add miscellaneous marine taxa and work with OBIS to also include their data. Several other invertebrate groups are also on the horizon.
We plan to soon move to an equal area grid that overcomes some of the uneven sample size issues that arise from using a geographical grid. Further, although geohashes serve the current purpose well, a better spherical representation of the globe with faster intersection and proximity query support can be achieved using the S2 geometry library. Developed at Google, S2 efficiently covers the globe with near-equal area cells using a space-filling curve similar to geohash. Regions as large as 1/6th of the globe down to a square centimeter can be represented via a single 64 bit integer. Unlike geohash, cells are of approximately the same size on the ground at a given precision level, and precision can be determined via simple bit math. We intend to use this technique to build a spatio-temporal index of all data in Map of Life that can support high precision intersections at scale. This will allow MOL to support higher polygon detail and higher precision point data in the calculations, to produce more accurate and timely metrics.
Over the next 3-9 months we will add an additional knowledge dimension: environmental data gaps. In the initially intended version, we will use the environmental conditions of the same grid cells over which we are currently reporting to evaluate how the (spatial) data gaps result environmental data biases. We foresee including these metrics and visualizations in the same web interface in the form of relative coverage of environmental space. This should be highly useful in particular for data selection and interpretation in a species distribution modeling context.
We will build on the APIs developed for this challenge to communicate assemblage level coverage metrics to users of the Map of Life mobile app. The Map of Life mobile application is uniquely positioned to help fill gaps in GBIF made discoverable via the inventory completeness interface, and completeness datasets produced by MOL. Localized completeness data can be synced to the application and then queried offline using geohash-driven intersections. Geofencing techniques can be used to drive user-submissions by alerting users to knowledge gaps as they browse the map or visit them on the ground. Submissions can then be rapidly integrated into the dataset to support near-realtime updates.
We plan to make a variety of improvements to the web interface design and reporting. Specifically, we aim to develop printable country reports that summarize the status and trends in both coverage metrics and that can readily be used by various stakeholders, alongside the raw data mobilization trends provided by GBIF (http://www.gbif.org/analytics/country/about). We will add various download functions to the website and provide example code for embedding components or tapping into the API.
Our data processing pipeline can be further improved and integrated with GBIF to maintain near-realtime updates of the completeness dataset. Daily GBIF dumps can be processed or streaming mechanisms from GBIF can be supported using scalable data processing pipeline tools such as Apache Beam (Cloud Dataflow).
Built With
- angular-ui
- angular.js
- bootstrap
- carto
- github
- google-bigquery
- google-compute-engine
- javascript
- python
- sql-(postgres-and-bigquery)
- webapp2




Log in or sign up for Devpost to join the conversation.