💡 Inspiration
We were sick of how annoying it still is to get a 3D model of a real object. Most options need CAD skills, special scanners, or slow photogrammetry. Cameras are everywhere… so why can’t a web app just watch an object and generate a 3D model? The Overshoot track was the perfect excuse to build something that’s actually real-time instead of “upload → wait → maybe it works”.
🧠 What it does
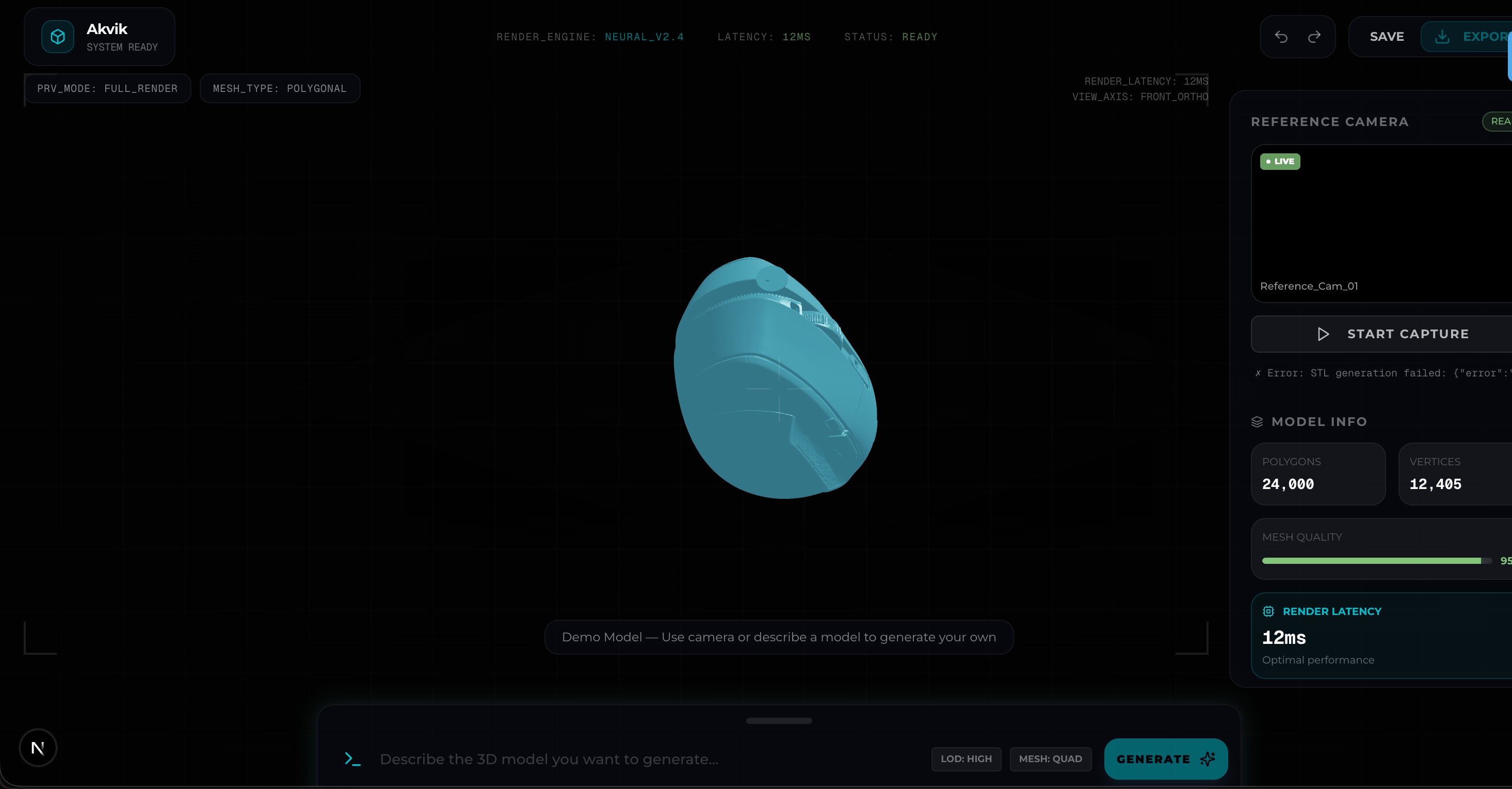
🎥 Record live video or upload a clip of an everyday object → get a 3D model you can preview + download as STL.
✅ Live “what the AI sees” text updates ✅ Stabilizes the description over time (not single-frame guessing) ✅ Generates a 3D mesh using TRELLIS (text → 3D) on a remote GPU ✅ Shows the model in a browser 3D viewer + STL export
🛠️ How we built it
Frontend: camera capture + video upload → live “what the AI sees” panel → 3D preview + STL download.
Overshoot (core): we stream the video into Overshoot, which analyzes rolling windows of frames and returns continuous plain-text geometry interpretations in real time.
Prompt processing: we combine multiple streaming outputs to reduce noise / prompt drift and produce one stable geometry description.
3D generation: that final description is sent to TRELLIS (text → 3D) running on a remote GPU, then we decode the mesh, export an STL, and render it in-browser.
If you want it even tighter (1–2 lines total), tell me.
😵 Challenges we ran into
⚠️ Streaming instability: the model’s interpretation can change window-to-window, so we needed aggregation to stabilize it ⚠️ Text-to-3D variance: text-conditioned 3D generation can be unpredictable, so prompts had to be strict + geometry-first ⚠️ Remote GPU latency: inference time + reliability (Modal/RunPod tradeoffs) ⚠️ Scope management: accuracy is hard in a hackathon, so we focused on shape + usability first
🏆 Accomplishments we’re proud of
🔥 Built an end-to-end pipeline: video → real-time vision → 3D model 👀 Live interpretation UI (not “upload and pray”) 📦 Generated STL outputs without scanners or manual CAD 🎯 Strong Overshoot alignment: real-time vision intelligence driving the whole app
📚 What we learned
🧩 Real-time vision changes the entire UX — it becomes interactive, not batch processing 🧠 Aggregating multiple observations over time makes the system more reliable ✍️ Prompt quality matters a lot more than expected for both vision + 3D generation ✅ Judges care about clarity + honesty: “shape-first MVP now, accuracy later” is defensible
🔜 What’s next
📏 Add calibration + multi-view reasoning for better real-world scale 🧠 Smarter aggregation (confidence scoring / outlier rejection) 🧰 Object-specific modes (containers, phone cases, tools) for better output quality 🧱 Explore parametric CAD generation (not just mesh) ⚡ Speed improvements + caching to reduce end-to-end latency
Built With
- javascript
- next.js
- overshoot
- python
- react
- three.js
- trellis
- typescript
- webgl

Log in or sign up for Devpost to join the conversation.