-
-
Ariadne Clew
-
Ariadne Clew Architecture
The Problem: Lost Reasoning in the AI Building Era
I've been vibecoding with LLMs since January 2025. By July, I had my first working builds. By September, I was deep in AWS infrastructure.
But I kept hitting the same wall: brilliant conversations with Claude disappeared into chat history. I'd solve a bug at 2am, close the tab, and forget the reasoning by morning. I'd make a design decision, implement it, then weeks later wonder "why did I do it this way?"
Every builder using AI assistants faces this: we're generating reasoning faster than we can preserve it.
The Inspiration
After winning 2nd place at CCC AI Camp (Cal Poly SLO/AWS, August 2025), I knew I could build something meaningful. The AWS Agent Hackathon gave me the perfect excuse to tackle reasoning preservation.
The insight: What if an AI agent could analyze my AI-assisted work sessions and extract the signal from the noise?
What I Built
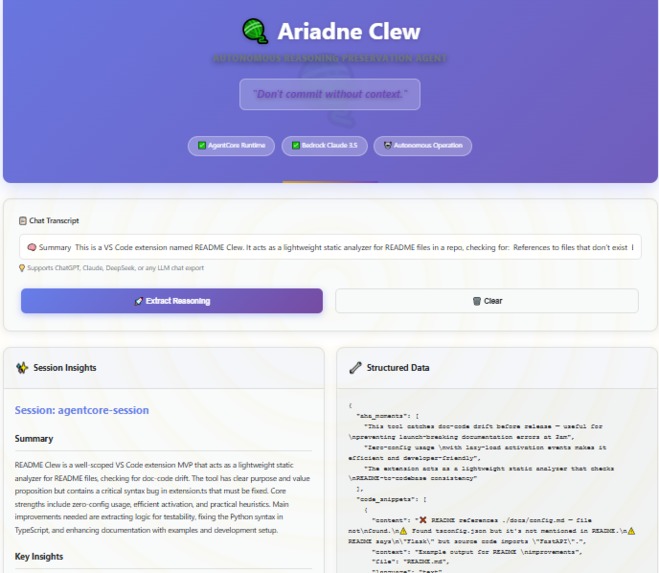
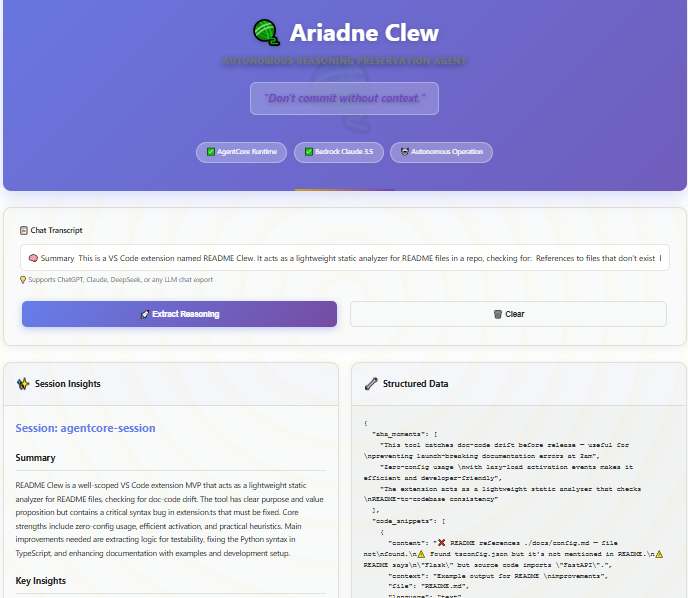
Ariadne Clew is an autonomous reasoning extraction agent built on AWS AgentCore Runtime. It:
- Analyzes chat transcripts from any LLM conversation (Claude, ChatGPT, etc.)
- Extracts structured insights: aha moments, MVP changes, design tradeoffs, code snippets, scope creep
- Generates human-readable summaries alongside machine-readable JSON
- Validates code snippets using AgentCore Code Interpreter
- Assigns quality scores to flag empty sessions vs. substantive work
Tech Stack:
- AWS Bedrock AgentCore Runtime - Core agent orchestration primitive
- Amazon Bedrock (Claude Sonnet 4) - Content analysis and classification
- Strands Agents SDK - Agent implementation framework
- AWS Lambda - Container execution environment
- AWS CodeBuild - Containerization pipeline
- Amazon ECR - Container image registry
- Python + Flask - Bridge server connecting frontend to AgentCore
- Pydantic - Schema validation and type safety
- HTML/CSS/JS - Polished frontend with drag-drop file upload
How I Built It
Phase 1: Foundation (September)
- First Bedrock connection established
- Built classification logic for identifying technical content
- Created schema for structured recap output
Phase 2: AgentCore Integration (September)
- Wrapped logic in Strands Agent framework
- Connected to BedrockAgentCoreApp runtime
- Implemented proper error handling and fallbacks
Phase 3: Production Hardening (Late September/October)
- Solved persistent AgentCore container caching issue
- Built bridge server to connect frontend to deployed agent
- Comprehensive test suite
- Added quality flags and validation logic
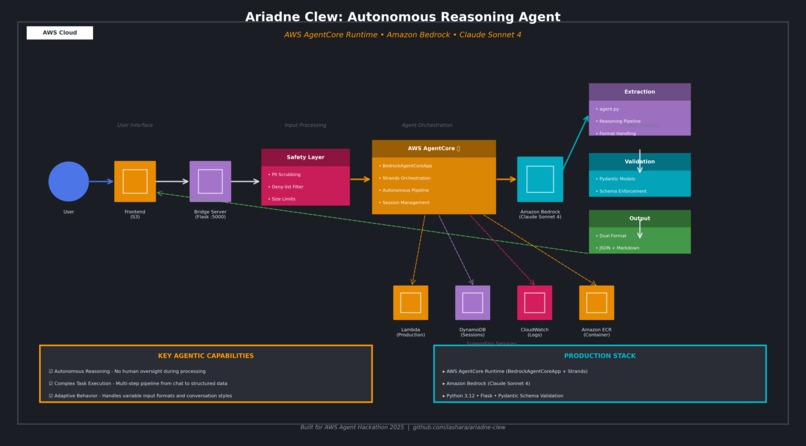
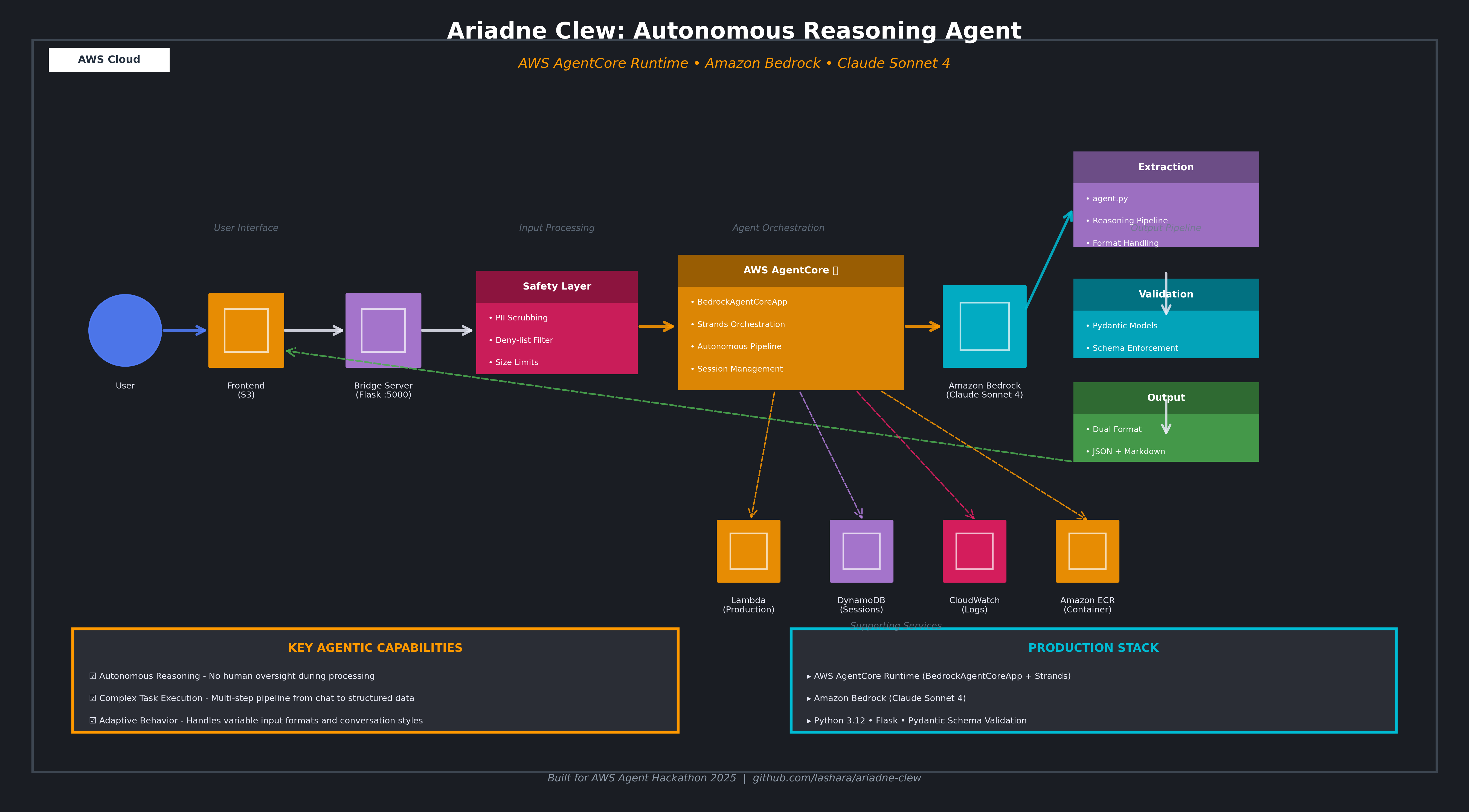
Architecture:
User uploads chat transcript
↓
Frontend (http://localhost:5000)
↓
Bridge Server (Flask API)
↓
AgentCore Runtime (AWS Lambda + ECR)
↓
Strands Agent (agent.py)
↓
Bedrock Claude Sonnet 4
↓
Structured JSON + Readable Summary
Deployment Pipeline:
agent.py → CodeBuild → ECR → Lambda
Challenges I Faced
1. AgentCore Container Caching Hell
The biggest technical challenge was AgentCore's persistent caching. Updated code wouldn't deploy despite:
- Multiple
agentcore launchattempts - Complete destroy/rebuild cycles
- Deleting config files
- Using
--force-rebuildflags
Solution: Nuclear reset approach
rm .bedrock_agentcore.yaml
agentcore configure --entrypoint backend/agent.py
agentcore launch --auto-update-on-conflict
The --auto-update-on-conflict flag was the key to forcing cache invalidation.
2. Strands Response Format Wrestling
AgentCore wraps Bedrock responses in a complex format:
{
"content": [{"text": "```json\n{actual_data}\n```"}],
"role": "assistant"
}
I had to build extraction logic to unwrap this, parse the JSON string, and validate the structure before generating human-readable summaries.
3. First AWS Production Deployment
This was my first time deploying to AWS Agentcore infrastructure. Learning curve included:
- Understanding Lambda cold starts
- Configuring ECR image pushes
- Managing IAM permissions for Bedrock access
- Debugging CloudWatch logs for silent failures
4. Balancing Autonomous Processing with Quality
Early versions would "analyze" any text and generate meaningless recaps. I implemented quality flags to detect:
- Empty or minimal transcripts
- No technical content
- Sessions too short to extract insights
This ensures the agent provides honest feedback when there's nothing substantive to extract.
What I Learned
Technical Skills:
- AWS AgentCore Runtime architecture and deployment
- Bedrock model invocation and prompt engineering
- Strands Agents SDK for building production agents
- Lambda + ECR containerization
- Real-time debugging of distributed systems
Product Judgment:
- When to ship MVP vs. perfect solution
- How to scope a hackathon project (froze scope in
MVP_ROADMAP.md) - Importance of quality signals over naive extraction
- Value of comprehensive error handling and fallbacks
Meta-Learning:
- LLMs are brilliant assistants but require human architecture
- Persistent debugging pays off (the cache issue took 2+ days)
- Good documentation helps future-you and judges
- Test suites catch regressions during rapid iteration
Why This Matters
For indie builders: We're entering an era where reasoning happens in conversations with AI. Those insights disappear unless we preserve them systematically.
For teams: Shared context is the foundation of collaboration. Ariadne Clew turns ephemeral chat into durable memory artifacts.
For the AI ecosystem: As agents become more sophisticated, reasoning transparency matters. This project demonstrates how agents can make their own thinking auditable and preservable.
Future Vision
Post-MVP enhancements:
- Multi-session reasoning chains (track decisions across weeks)
- Agentcore Memory with chunking for longer chat extracts
- Team collaboration features (shared context pools)
- Pattern detection (identify recurring design tradeoffs)
- Integration with project management tools (auto-populate docs)
The big idea: Every builder deserves a ghost cofounder who remembers everything and explains it clearly.
🏗️ Built With
Languages:
- Python 3.12
- JavaScript (ES6+)
- HTML5
- CSS3
Frameworks & Libraries:
- Flask (Python web framework)
- Pydantic (Schema validation)
- Strands Agents SDK (Agent implementation)
- boto3 (AWS SDK for Python)
AWS Services:
- Amazon Bedrock (Claude Sonnet 4)
- AWS AgentCore Runtime (BedrockAgentCoreApp)
- AWS Lambda (Agent execution)
- AWS CodeBuild (Containerization)
- Amazon ECR (Container registry)
- Amazon CloudWatch (Logging)
- AWS X-Ray (Tracing)
Development Tools:
- pytest (Test framework)
- Black (Code formatting)
- mypy (Type checking)
- GitHub Actions (CI/CD)
🔧 Amazon Tools Used
✅ Amazon Bedrock AgentCore - Runtime primitive for agent orchestration ✅ Amazon Bedrock - Claude Sonnet 4 for content analysis ✅ Strands Agents SDK - Agent implementation framework
🔗 Project Links
Code Repository: https://github.com/earlgreyhot1701D/Ariadne-Clew
Live Demo: Local deployment (instructions below)
🧪 Testing Instructions
Prerequisites
- Python 3.12+
- AWS CLI configured with Bedrock access
- AgentCore CLI installed
Local Setup
Clone the repository
git clone https://github.com/earlgreyhot1701D/Ariadne-Clew.git cd Ariadne-ClewInstall dependencies
python -m venv .venv source .venv/bin/activate # On Windows: .venv\Scripts\activate pip install -r requirements.txtConfigure AgentCore
agentcore configure --entrypoint backend/agent.py agentcore launch --auto-update-on-conflictStart the bridge server
python backend/bridge_server.pyOpen the frontend
http://localhost:5000
Testing the Agent
Option 1: Via Frontend
- Open
http://localhost:5000in your browser - Copy and paste text
- Click "Generate Recap"
- View structured insights in the Session Insights panel
- View raw JSON in the Structured Data panel
Option 2: Direct AgentCore Invocation
agentcore invoke '{"prompt":"User: We need authentication\nAssistant: Use JWT tokens\nUser: Why JWT?\nAssistant: Stateless and scalable"}' --session-id "test-session-12345678-1234-1234-1234-123456789012"
Expected Output:
{
"status": "success",
"result": {
"human_readable": "## Session Recap: Authentication Discussion\n\n### 💡 Key Insights\n- Decided on JWT tokens for authentication...",
"structured_data": {
"aha_moments": ["JWT tokens chosen for stateless authentication"],
"design_tradeoffs": ["JWT: stateless scaling vs. session: simpler revocation"],
"code_snippets": [],
"mvp_changes": ["Added JWT authentication"],
"quality_flags": []
}
}
}
Sample Test Files
Use Demo_Test.txt included in the repository for a realistic test case. This file contains:
- Technical discussion about auth strategies
- Code snippets (Python JWT implementation)
- Design tradeoffs (JWT vs sessions)
- MVP scope decisions
Running the Test Suite
pytest tests/ -v
📊 Architecture Diagram
See: ARCHITECTURE_DIAGRAM.png (uploaded to image gallery)
Components:
- Frontend Layer: HTML/CSS/JS with drag-drop file upload
- Bridge Server: Flask API handling CORS and request routing
- AgentCore Runtime: AWS Lambda + ECR container orchestration
- Strands Agent: agent.py implementing reasoning extraction logic
- Bedrock Claude: LLM performing content analysis and classification
- Data Flow: User input → API → AgentCore → Bedrock → Structured output
Key Interactions:
- Frontend sends POST request with chat_log to bridge server
- Bridge server invokes AgentCore with properly formatted payload
- AgentCore executes Strands agent.py
- Agent sends classification prompt to Bedrock Claude
- Claude analyzes transcript and returns structured JSON
- Agent extracts and validates response
- Bridge server returns human_readable + structured_data to frontend
🏆 Why This Project Stands Out
Technical Achievement:
- Real AWS AgentCore Runtime integration (not simulated)
- Production-grade error handling and fallbacks
- Comprehensive test coverage with quality signals
- Solved complex container caching issues
Product Value:
- Addresses genuine pain point for AI-assisted builders
- Autonomous processing (no human-in-the-loop required)
- Structured output enables downstream automation
- Quality flags ensure honest feedback
Developer Experience:
- Clear documentation and testing instructions
- Frozen MVP scope demonstrates shipping discipline
- Comprehensive error messages for debugging
- Polished frontend shows attention to UX
Built by: La Shara Cordero
Contact: lsjcordero@gmail.com
Timeline: July 2025 (first Bedrock connection) → October 2025 (production deployment)
Previous Win: 2nd Place, CCC AI Camp (Cal Poly SLO/AWS, August 2025)
"Don't commit without context. Don't build without reason. Don't lose the thread." 🧶
Built With
- agentcore
- amazon-cloudwatch
- amazon-web-services
- bedrock
- claude
- ecr
- lambda
- pydantic
- python
- sonnet
- strands

Log in or sign up for Devpost to join the conversation.