-
-
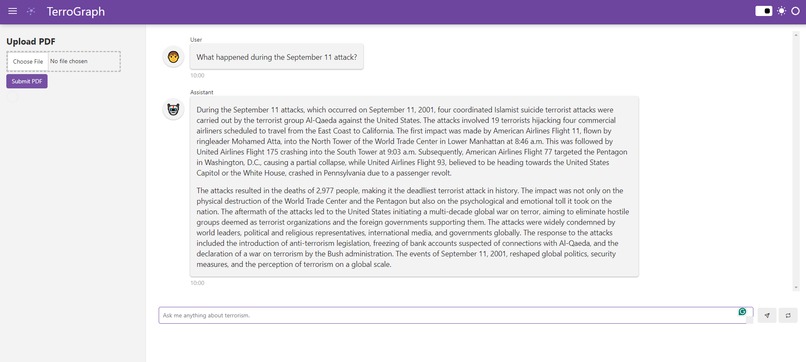
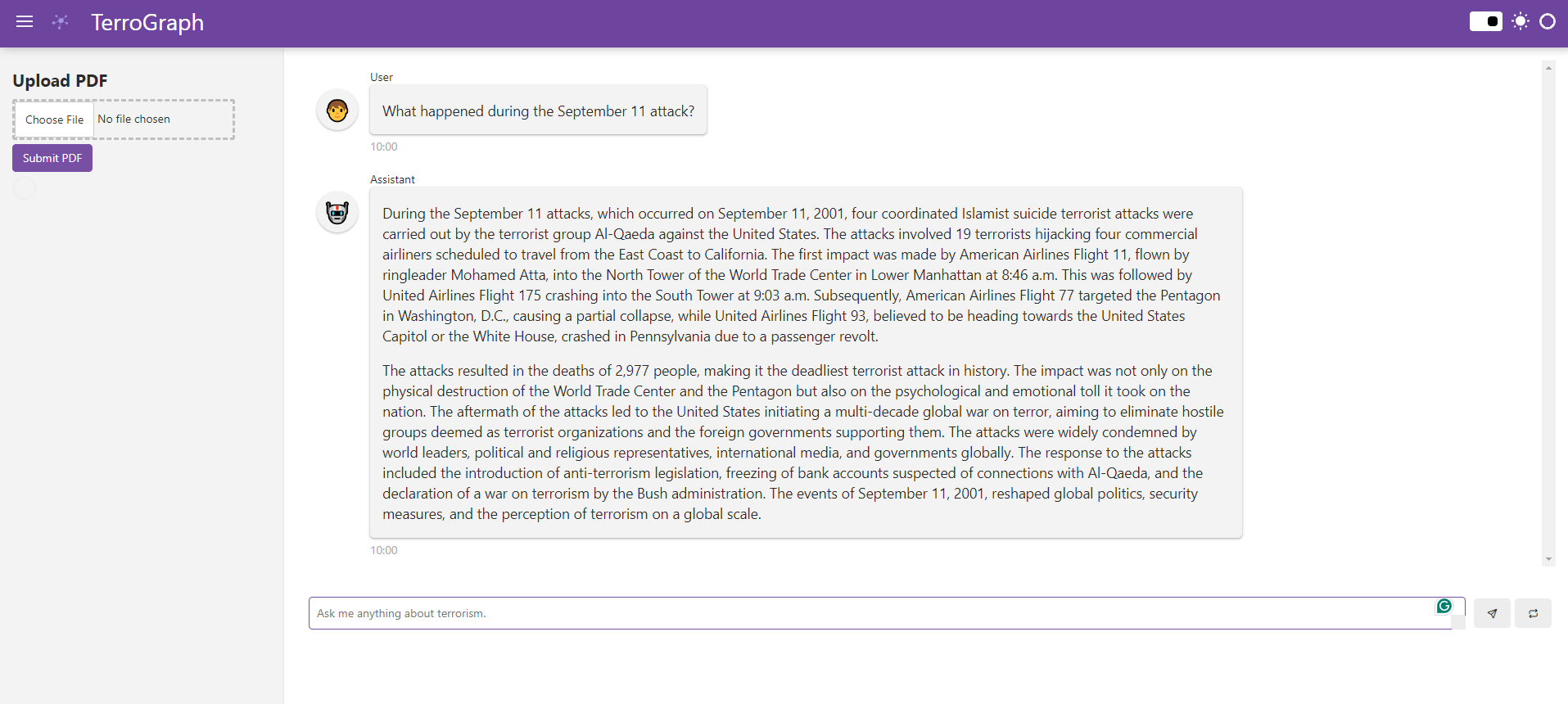
User Interface
-
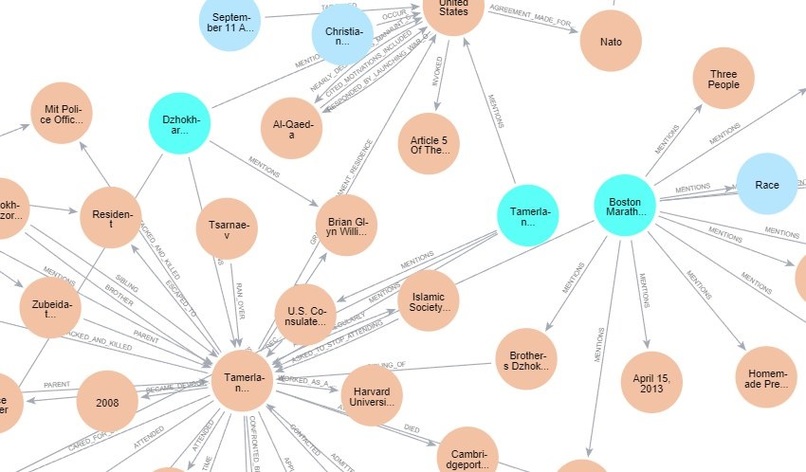
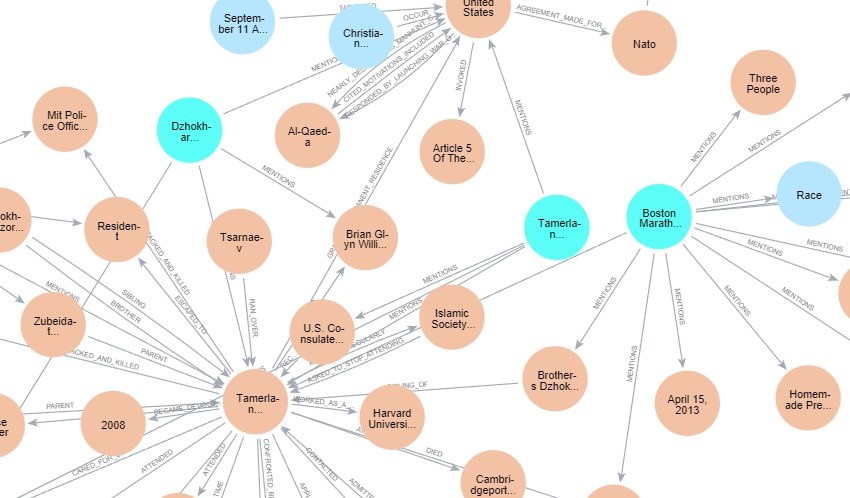
Knowledge Graph
Background
Reports and articles on terrorism usually contain a lot of text, which are unstructured and difficult to resolve across reports in an automated fashion. For instance, linking articles about a terror incident, all coming in at different times in a day with varying details, can be challenging. Each report contains entities (Person, Object, Location, Events) that could be represented in a knowledge graph and accessed through a chatbot. TerroGraph aims to design and implement a Large Language Model (LLM) that can extract entities from reports into a knowledge graph, and an LLM that can answer questions based on the generated knowledge graph.
Features
Our project leverages LLMs (OpenAI) and Neo4j's knowledge graphs to create a comprehensive system for managing and querying information about terrorism incidents. The project consists of several key components:
- User Interface
- Chatbot: The chatbot interface allows users to ask queries about terrorism. It retrieves relevant information from the Neo4j database and provides responses based on the knowledge graph.
- PDF Uploader: Users can upload PDF files containing articles about terrorism. The system extracts text from the PDFs, processes the content to identify entities, and updates the knowledge graph accordingly.
- Backend Components
- Knowledge Graph: A Neo4j-based graph database that stores entities (Person, Object, Location, Events) and their relationships extracted from terrorism reports and articles.
- Web Scraper: A scheduler-based web scraper that periodically gathers new articles from reputable news sources and updates the knowledge graph.
- RAG Model: Combines information retrieval and generation to provide accurate and relevant responses to user queries by leveraging both the knowledge graph and external web searches.
How we built it
- Knowledge Graph Prepopulation:
- Collected data from an online database of known terror attacks.
- Processed the data to extract entities and relationships.
- Populated the Neo4j knowledge graph with the preprocessed data.
- RAG Model Implementation:
- Integrated a Retrieval-Augmented Generation model to handle user queries.
- Configured the model to retrieve relevant nodes and relationships from the Neo4j database.
- Set up the LLM to generate responses based on the retrieved information.
- LangGraph Routing
- Using LangChain's Langgraph API, we implemented agent-based routing for different LLM outputs.
- Web Scraping Scheduler:
- Developed a web scraper to collect news articles from AP News and CNA.
- Implemented a scheduling mechanism to run the scraper weekly.
- Processed and indexed the scraped articles in a MongoDB database to ensure no duplicates.
- PDF Processing:
- Created a function to extract text from uploaded PDFs using Tesseract OCR.
- Developed an entity extraction pipeline to identify and store relevant entities in the knowledge graph.
- Allowed users to upload PDFs through the chatbot interface.
- Web Search Functionality:
- Configured the LLM to perform web searches if the knowledge graph does not contain sufficient information to answer a user query.
- Extracted relevant information from the web search results and included it in the chatbot response.
Why TerroGraph works
- Scalable: Knowledge graph is kept up-to-date automatically from various sources and condenses the varying details by establishing nodes and edges to the relevant event entity dynamically
- Innovative: Combines structured graph data with unstructured high-dimensional vectors to achieve the best of both worlds, enhancing the depth and contextuality of the information retrieved
- Transparent: LLM agent component recognises its shortfall and will utilise web search as last resort instead of hallucinating
Challenges we ran into
We faced numerous challenges in the process of this project. Here's what we encountered:
- Finding a Proper Prompt: crafting an appropriate prompt for the language model to generate relevant and accurate responses was difficult. Defining the right level of specificity and context was crucial to ensure the model could effectively leverage the knowledge graph and external information sources.
- Data Preprocessing: Preprocessing the data from various sources, including PDF files and web articles, presented its own set of challenges. We had to handle different file formats, extract relevant information, and clean the data to ensure consistency and accuracy before populating the knowledge graph.
- Finding the Proper Technologies: Selecting the right technologies and tools for each component of the project was a non-trivial task. We evaluated various options for knowledge graph databases, language models, web scraping libraries, and other tools before settling on the final tech stack that met our requirements.
Accomplishments that we're proud of
We are proud that we are able to produce a fully functional Proof-Of-Concept (POC) application within the time limits of this hackathon.
What we learned
Throughout the course of this project, we learned several key lessons:
- Entity Extraction: Extracting structured information from unstructured text is a challenging yet crucial step in building a useful knowledge graph. We learned various techniques for entity extraction and relationship mapping.
- Knowledge Graphs: Working with Neo4j provided insights into the advantages of graph databases, especially for storing and querying complex relationships between entities.
- LLM Integration: Integrating LLMs with knowledge graphs can significantly enhance the ability to retrieve and generate relevant responses, demonstrating the power of combining different AI technologies.
- Web Scraping: Developing a reliable and efficient web scraping system taught us the importance of handling various edge cases and ensuring data quality.
- Scheduling and Automation: Implementing scheduling mechanisms for periodic tasks (like web scraping) highlighted the importance of automation in maintaining an up-to-date knowledge base.
What's next for TerroGraph
Moving forward, we wish to further enhance the capabilities of Terrograph by:
Prepopulate the knowledge graph with the full dataset for the real application.
We will train or finetune the latest performing models for better entity extraction.
We wish to store article citations and output them alongside results for greater credibility and explainability.




Log in or sign up for Devpost to join the conversation.