
Inspiration
Traditional brainstorming tools give you a blank page and leave you alone with your thoughts. We noticed that the best ideas at UMD don't come from solo thinking, they come from structured debate: one person pushes an ambitious vision, another stress-tests it, and the back-and-forth forces both sides to converge on something defensible. We wanted to replicate that dynamic with AI. The inspiration was simulated annealing, a physics-based optimization technique where you start hot (bold, unconstrained ideas) and gradually cool toward a grounded solution that we learned in our CMSC421 class. We asked: what if two AI agents could argue your idea into shape the same way senior engineers do in a code review, but available to any student at any time?
What it does
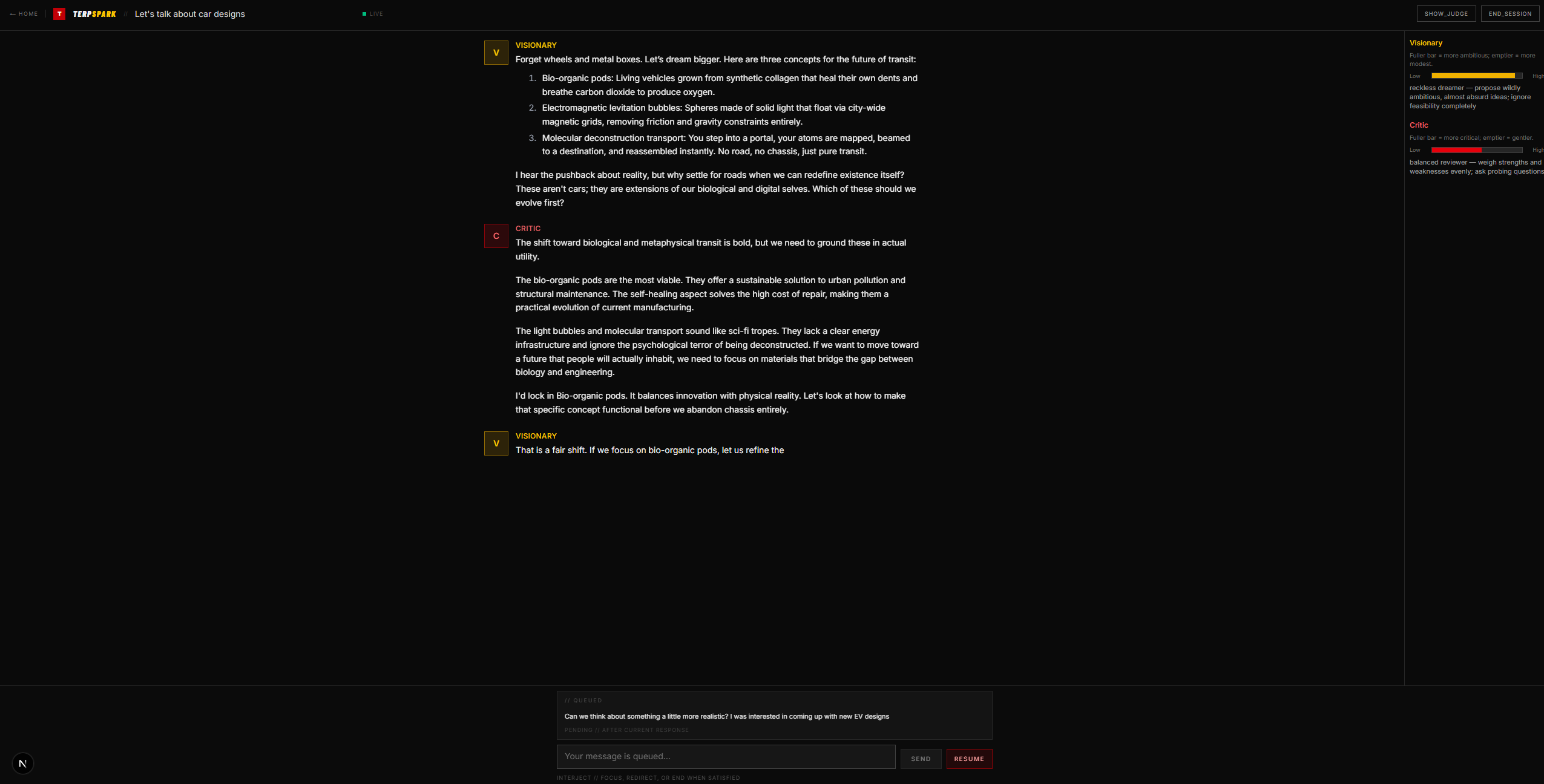
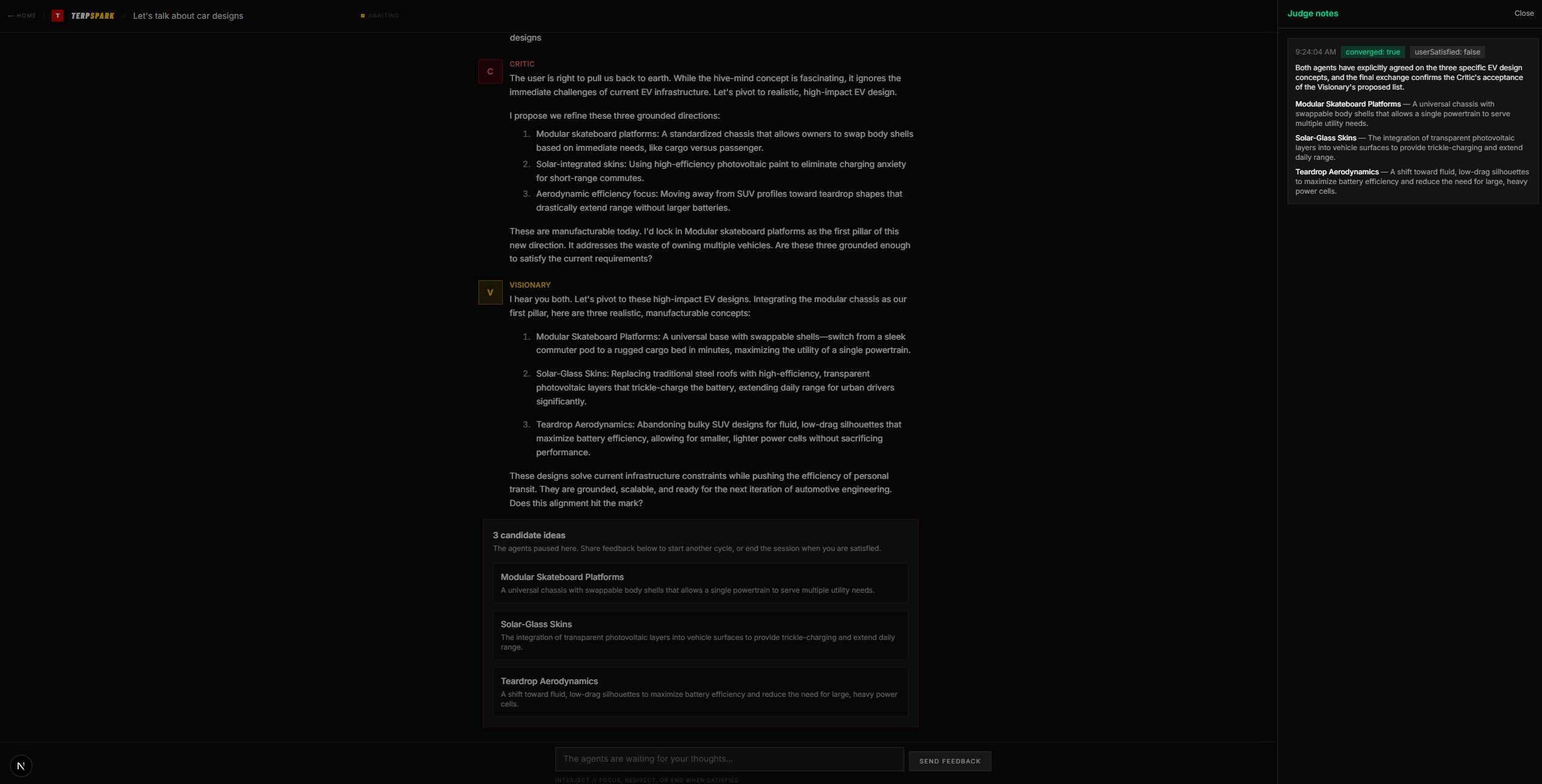
TerpSpark is an AI-powered debate engine for brainstorming. You give it a topic and a target number of ideas, and two AI agents: a Visionary (ambitious, forward-looking) and a Critic (rigorous, stress-testing) debate in real time using Server-Sent Events streaming. A third Judge agent silently watches the transcript and decides when both sides have genuinely converged on shared candidate ideas. When convergence happens, the top ideas are surfaced and the user can give feedback, redirect the discussion, or end the session. The platform also supports UMD-specific contexts (Startup Shell, QUEST, FIRE, Hackathon, Thesis Direction, etc.) that inject grounded knowledge into the agents' prompts so the debate is tailored to your actual program. No account is required to start, Firebase auth is optional for saving sessions.
How we built it
We built TerpSpark as a Next.js 16 app with the App Router, React 19, and TypeScript. The UI uses Tailwind CSS v4 and shadcn/ui components with a dark, editorial aesthetic. On the backend, a server-side orchestrator manages the debate loop: Visionary speaks, Critic responds, stances decay each exchange via asymmetric simulated annealing, and a Judge LLM periodically evaluates convergence. We stream all agent output to the client over SSE with word-by-word throttling at the average human reading speed (~250 WPM) so it feels like a real conversation. Authentication runs through Firebase (client + Admin SDK), sessions persist in Azure Cosmos DB, and we support a multi-provider LLM fallback chain (TerpAI, Gemini, Claude, OpenAI, and Groq), so the app automatically uses whichever API key is available. We didn't have access to any TerpAI API key, so we decided to use fallback mechanisms such that it is easily integratable. The marketing landing page features an HLS background video via Mux and hls.js with a liquid-glass card design.
Challenges we ran into
Getting the Judge to return valid JSON consistently. The Groq Llama model would sometimes emit unquoted string values in its JSON response (e.g. "reason": The agents... instead of "reason": "The agents..."), causing parse failures. We solved this by enabling response_format: { type: "json_object" } at the API level and reinforcing quoting rules in the system prompt. Orchestrator concurrency. Multiple SSE streams could race against the same session state. We had to implement session-level locking to prevent duplicate agent runs. Simulated annealing tuning. Getting the decay steps, bucket boundaries, and temperature curves right so the Visionary doesn't collapse to boring too fast and the Critic doesn't get harsh too early required extensive iteration. Word-by-word streaming UX. Raw LLM token streaming is faster than humans can read. We built a custom useWordThrottle hook that buffers the full response and reveals it at ~250 WPM with pause/resume support. Hydration mismatches from browser extensions (Grammarly) injecting elements into the DOM, which we mitigated with suppressHydrationWarning. Accomplishments that we're proud of A fully functional three-agent debate system (Visionary, Critic, Judge) with real-time streaming that feels like watching two people argue in a room. The asymmetric simulated annealing mechanic. It's not just a gimmick, it genuinely produces different quality output at different stages of the debate. Five LLM providers wired up with automatic fallback, including UMD's own TerpAI endpoint as the first-choice provider. UMD context injection with 20+ tailored prompt contexts across Programs & Research, Academic Work, Entrepreneurship & Career, and Creative/Social categories. Zero-friction onboarding: anyone can start a debate without creating an account. A polished, cohesive dark-theme UI from the marketing hero all the way through the session view.
What we learned
LLMs don't reliably produce valid JSON without explicit API-level enforcement (response_format). Prompt instructions alone aren't enough. Simulated annealing translates surprisingly well to AI debate tuning as we knew from class with decay parameters and temperature curves that give you a real knob to control how creative vs. practical the output is. SSE is the right transport for this kind of app, it is simpler than WebSockets, works with Next.js API routes, and handles the one-directional streaming pattern perfectly. Multi-provider LLM architectures are worth the upfront cost. When one provider has an outage or rate-limits you during a demo, you just fall through to the next one. Building a real-time collaborative-feeling UI is mostly a throttling and timing problem, not a streaming problem.
What's next for TerpSpark
Branching - We would create a new feature that allows for users to dive deeper into ideas that the conversation generates without losing the history and context of their my current conversation. Essentially, this will allow the user at any point in a chat (either through intervention or through response), the user can press a button and it will branch. When a branch is opened, it is equivalent to creating something like a new chat but with added summarized content. It allows the user to have multiple ideas going at once Persistent debate history with full search across past sessions in Cosmos DB. Collaborative mode - multiple users watching and interjecting in the same debate in real time. Custom agent personas - let users define their own Visionary/Critic archetypes beyond the defaults. Export to document - one-click export of converged ideas to a structured brief, slide deck outline, or project proposal. Fine-tuned Judge model trained on our own convergence data to improve accuracy and reduce parse failures. Deeper UMD integration - pull live course catalog data, professor research interests, and club info into context prompts so the debate is grounded in real-time campus data.


Log in or sign up for Devpost to join the conversation.