-
-
Main
-
Inspiration
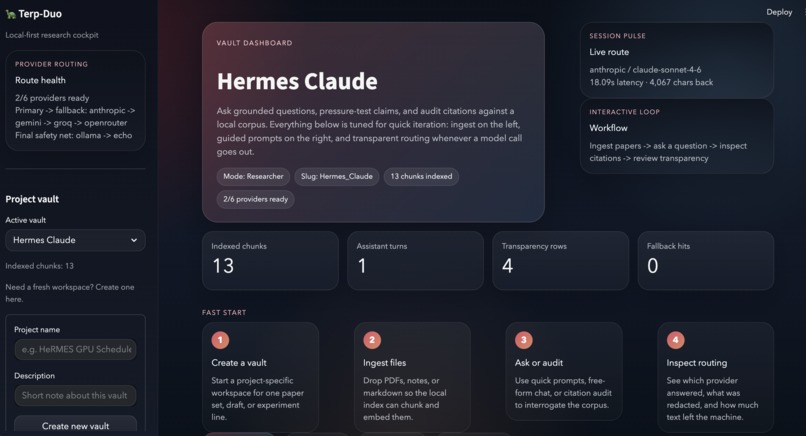
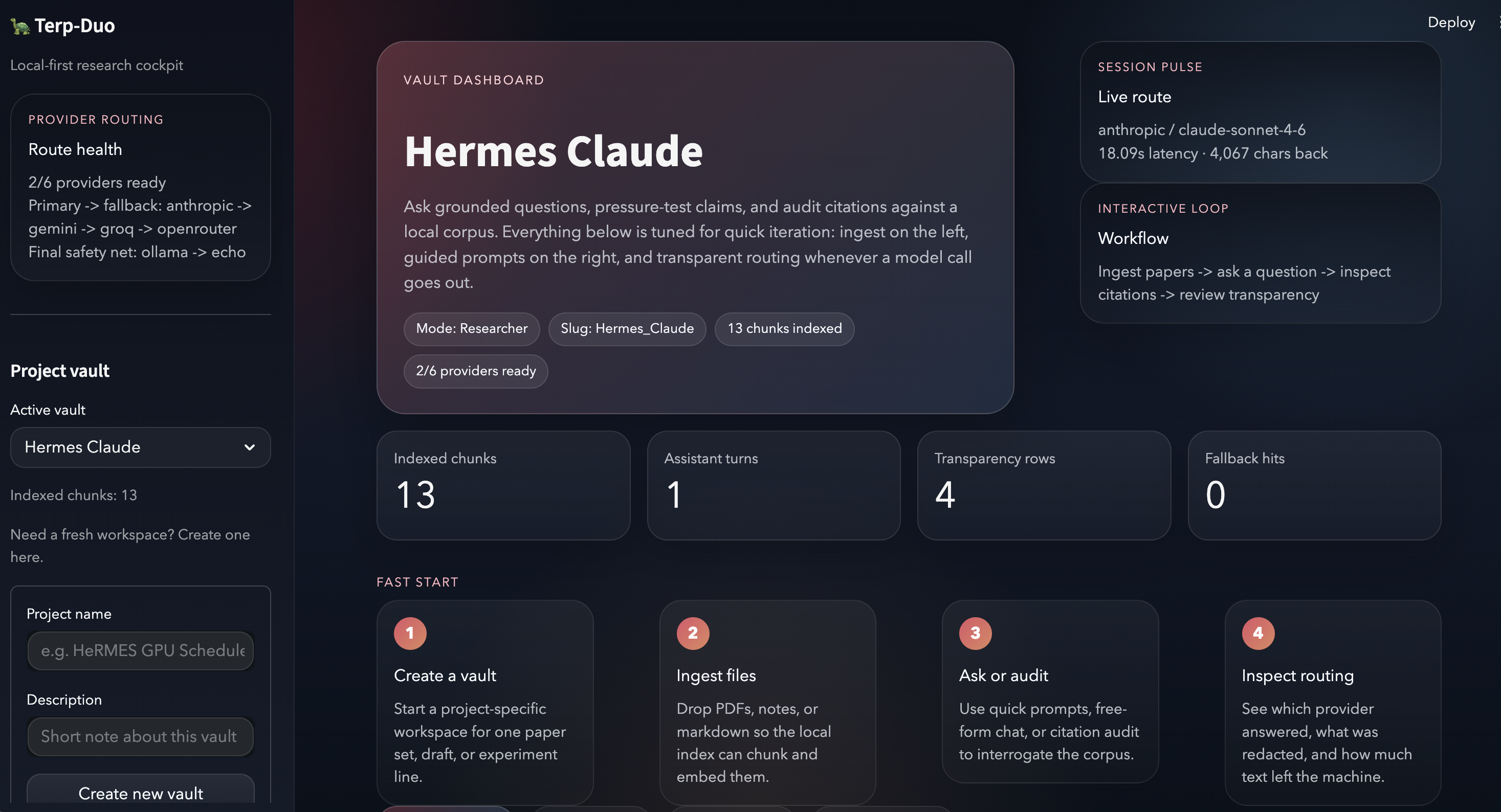
What it does# Terp-Duo: The Local-First Research Operating System
Inspiration: The Amnesiac Librarian
As researchers at the University of Maryland, we noticed a fundamental flaw in using general-purpose LLMs for academic work. Standard tools like ChatGPT or Claude act like a "Smart Librarian with Amnesia." You can upload 50 PDFs, but by the time you reach the 51st, the model starts losing context, or worse, you have to re-upload and re-tokenize the entire library next week, wasting time and money.
Furthermore, for those of us working on sensitive projects—like the HeRMES GPU Scheduler—uploading unpublished results or internal cluster logs to a public cloud is a non-starter. We needed a lab partner that stays local, remembers everything, and proactively finds the gaps in our research.
How We Built It
Terp-Duo was built as a Local-First "Bunker" Architecture using a modular Python stack:
- The Vault (Storage): We used ChromaDB for a persistent local vector database. This ensures data survives session closures and context window resets.
- The Ingestor (Processing): PDFs are chunked and embedded locally using the
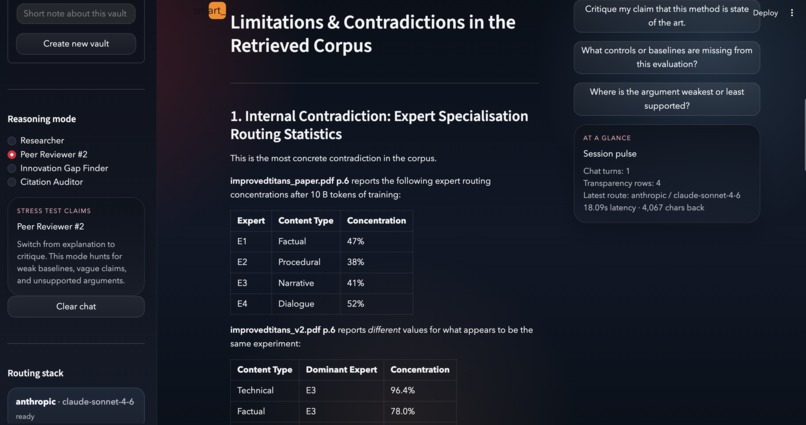
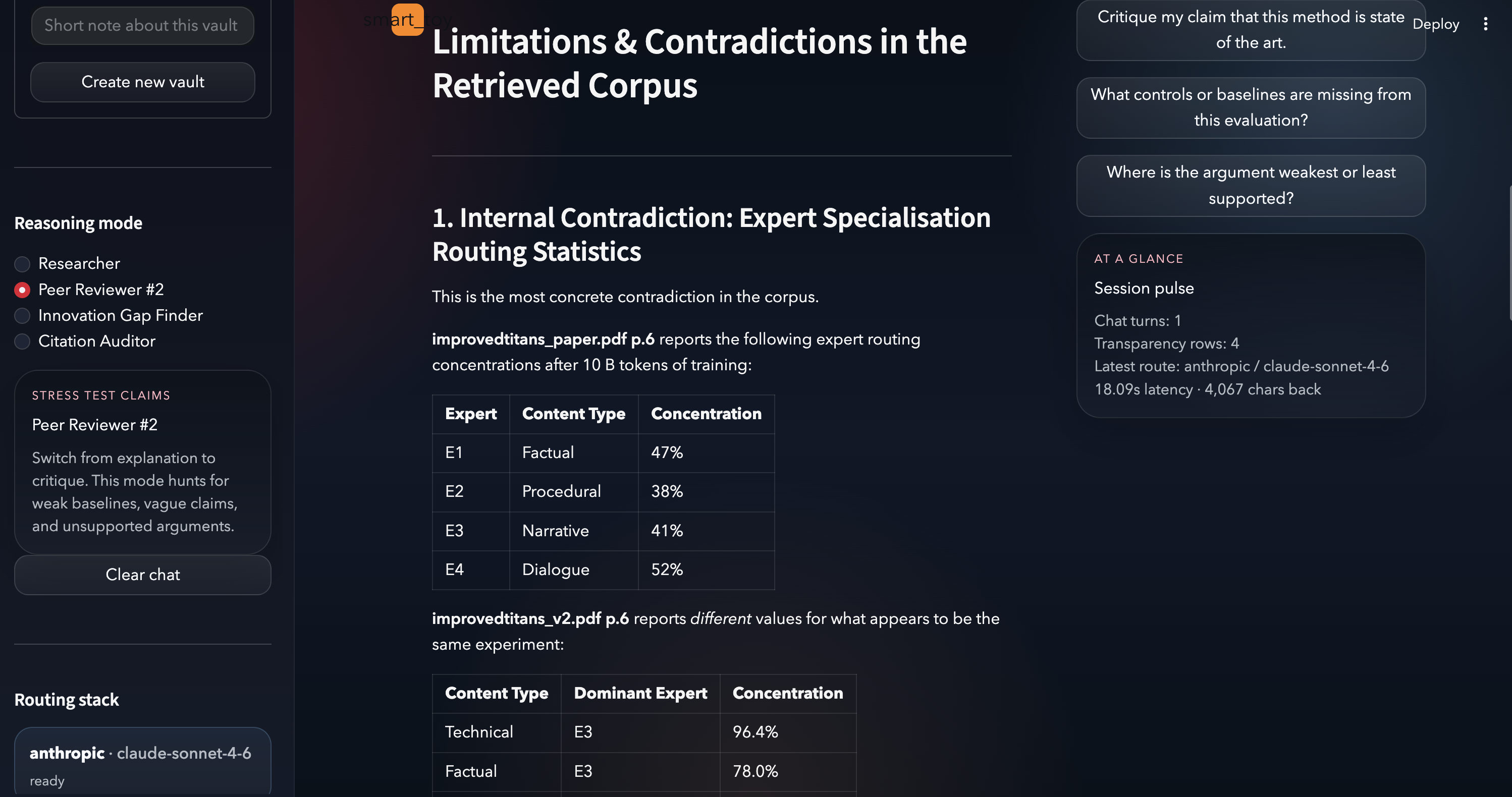
sentence-transformers/all-MiniLM-L6-v2model. This runs entirely in-process, meaning your data never leaves your machine during indexing. - The Redactor (Privacy): Before any query hits the Anthropic API, we run a deterministic redaction pass. Sensitive entities (IPs, emails, AWS keys) are replaced with placeholders like $\langle IPV4_1 \rangle$.
- The UI: A customized Streamlit dashboard featuring a "Transparency Log" that shows exactly what data was redacted and sent to the cloud.
The Challenges We Faced
- Deterministic Redaction: It wasn't enough to just hide an IP; we had to ensure that if
192.168.1.42appeared twice, it was replaced by the same placeholder both times so the LLM could still reason about the logic of the logs without knowing the real values. - Dependency Hell: Integrating heavy ML libraries like
torchandtransformerswithin a lightweight Streamlit app led to recursive import warnings and overhead, which we solved by optimizing our environment configuration and silencing non-critical telemetry. - API Resilience: When we hit API credit limits, we had to quickly pivot to build a Local Fallback Mode using Ollama, allowing the system to run 100% offline using Llama 3.
What We Learned
We learned that Privacy is a Feature, not a Constraint. By building "Bunker Mode," we realized we could actually improve the AI's performance. Because we aren't sending thousands of pages of raw text, we can focus the model's attention on the specific, redacted snippets that matter most for solving the current research gap.
The Math of Efficiency
Terp-Duo optimizes the research workflow by reducing the Token Overhead ($T_o$). In a standard session, re-uploading a library of $n$ papers results in a cost $C$ that scales linearly with every new session: $$C_{total} = \sum_{i=1}^{sessions} (n \times \text{tokens per paper})$$ With Terp-Duo’s local embeddings, the cost is reduced to only the specific query and retrieved context $k$: $$C_{TerpDuo} = \sum_{i=1}^{sessions} (k \times \text{tokens per query}) \quad \text{where } k \ll n$$
http://googleusercontent.com/interactive_content_block/0
https://drive.google.com/file/d/1EUCKBNfzo_dG93VEobE37WrT5BopP6yY/view?usp=drive_link
Built With
- claude
- python


Log in or sign up for Devpost to join the conversation.