-
-
Data Ingestion Layer
-
Application Layer
-
Feature: Personalized Search
Introduction
Termify is an AI-powered chatbot designed to help users easily understand the terms and conditions, privacy policies, and related documents of various companies. By providing concise and accurate explanations, Termify simplifies complex legal jargon, making it accessible for everyone.
Problem That our Project Solves
Understanding the terms and conditions of a company is a daunting task for most users. The legal jargon and complex language used in these documents make it difficult for users to comprehend the information. As a result, users often skip reading these documents, which can lead to misunderstandings and disputes in the future.
Impact
- Empowers Users: Simplifies legal jargon, making terms and policies easy to understand.
- Builds Trust: Promotes transparency between companies and users, reducing disputes.
- Enhances Inclusivity: Makes legal documents accessible to all, regardless of expertise or background.
- Encourages Informed Choices: Helps users make better decisions by understanding their rights and obligations.
- Supports Ethical Tech: Aligns with the goal of creating transparent, user-focused digital solutions.
Tech stack
- Snowflake
- Mistral LLM (mistral-large2)
- Cortex Search for retrieval
- Trulens
- Streamlit
- Docker
Architecture
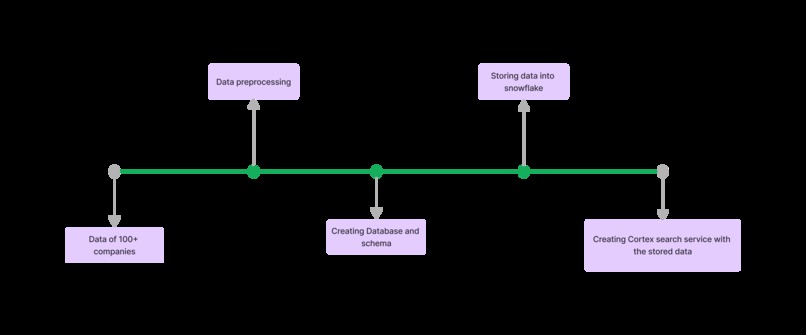
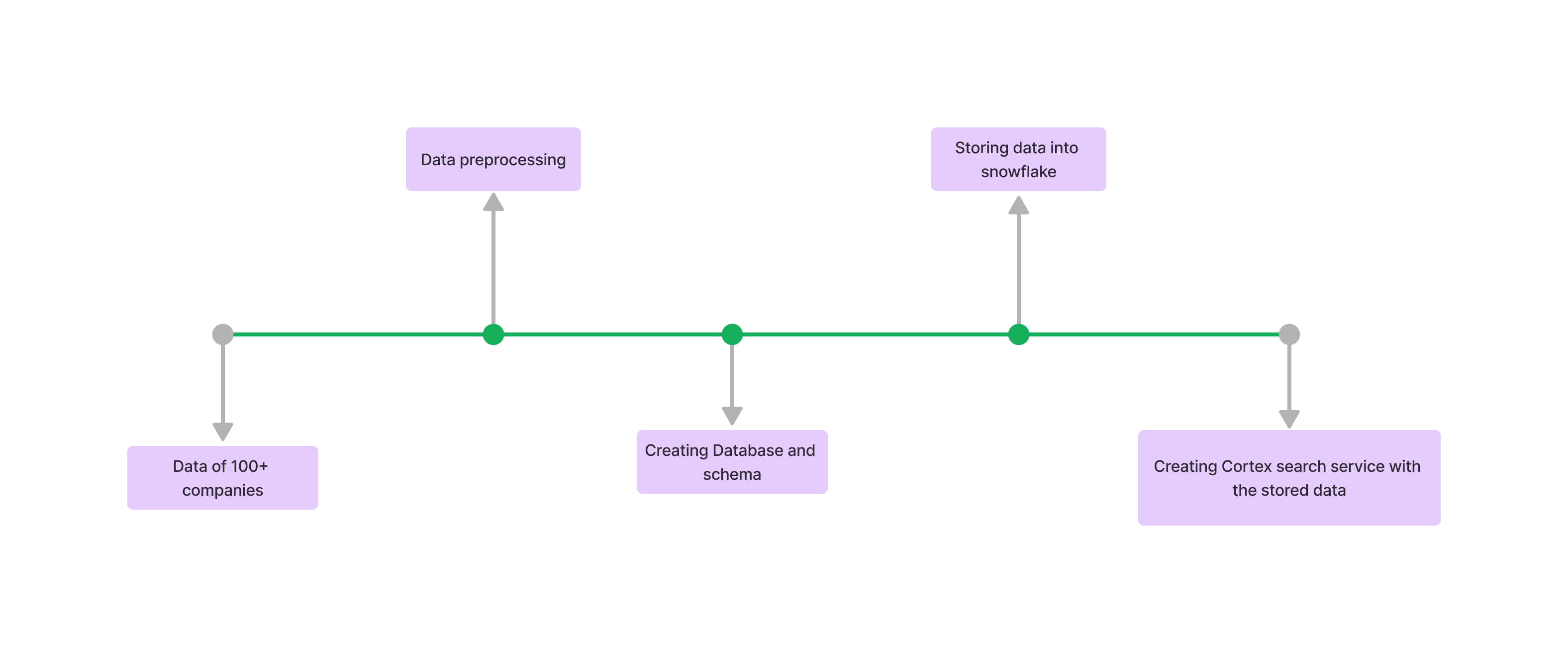
Data Ingestion Layer
This layer manages the process of importing raw data, pre-processing it, and organizing it in Snowflake.
Key Steps:
- Data Import: Raw data is ingested from various sources.
- Pre-processing: Data is cleaned and transformed as required.
- Database Setup: Databases and schemas are created in Snowflake.
- Storage: Processed data is stored in tables within Snowflake.
- Search Service: A Cortex search service is configured for efficient data retrieval.
See the architecture diagram for a detailed view of the data flow in this layer.
Fig1: Data Ingestion Layer
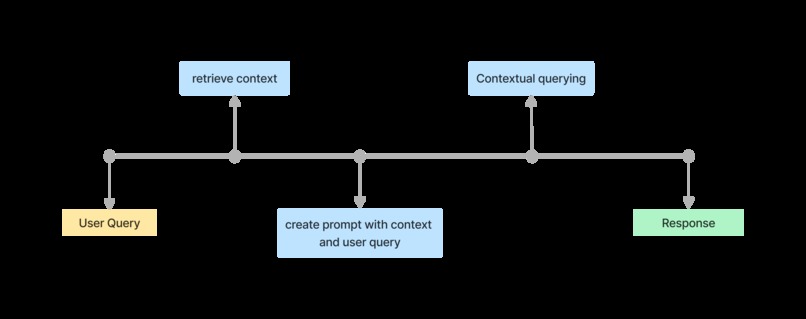
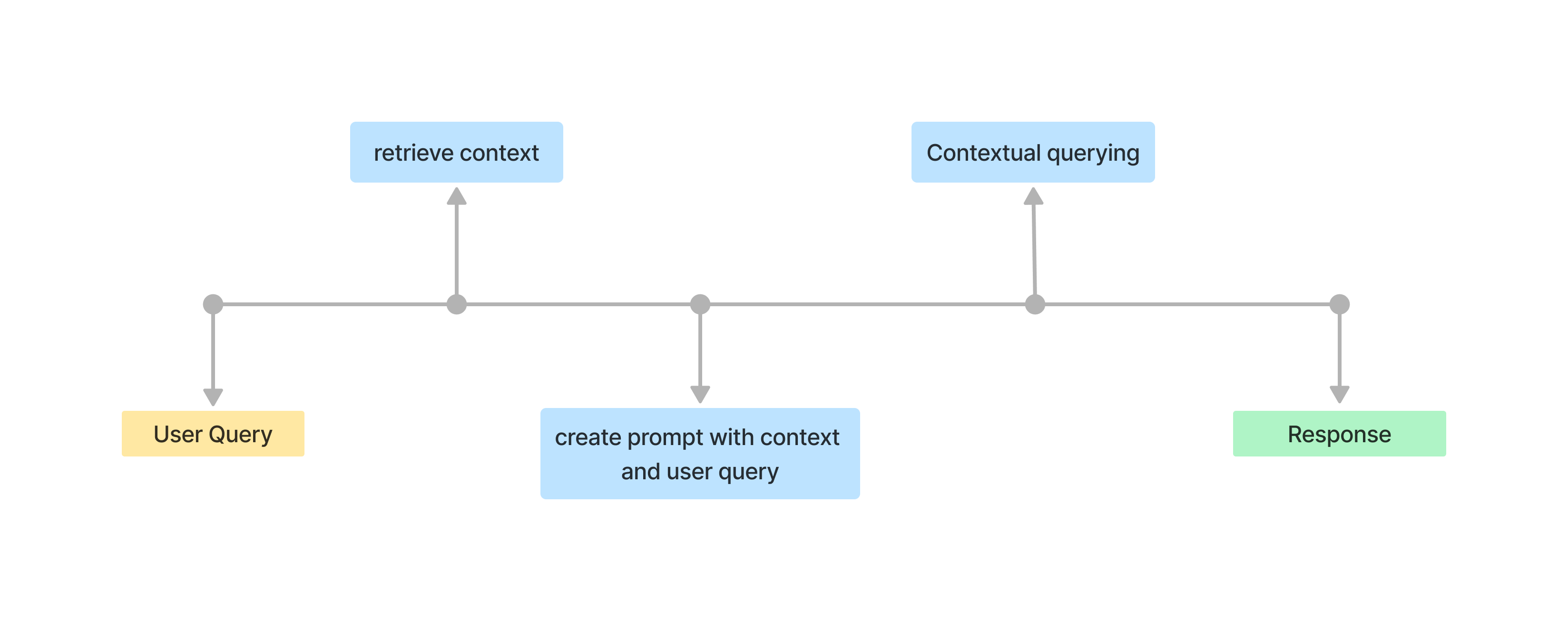
Application Layer
This layer handles user input processing and orchestrates context-based retrieval and response generation.
Key Steps:
- User Input: Captures and processes the input query from the user.
- Context Retrieval: Utilizes Cortex Search to retrieve relevant context from stored data.
- Prompt Creation: Combines the input query and retrieved context to form a complete and meaningful prompt.
- Response Generation: Sends the prompt to the LLM (Mistral-large2) to generate clear, accurate, and concise responses.
Refer to the architecture diagram for a detailed depiction of the interaction flow within this layer.
Fig2: Application Layer
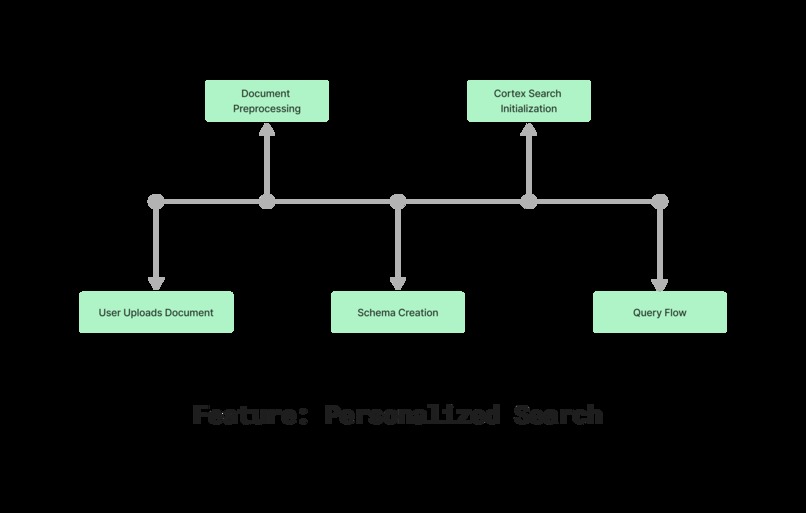
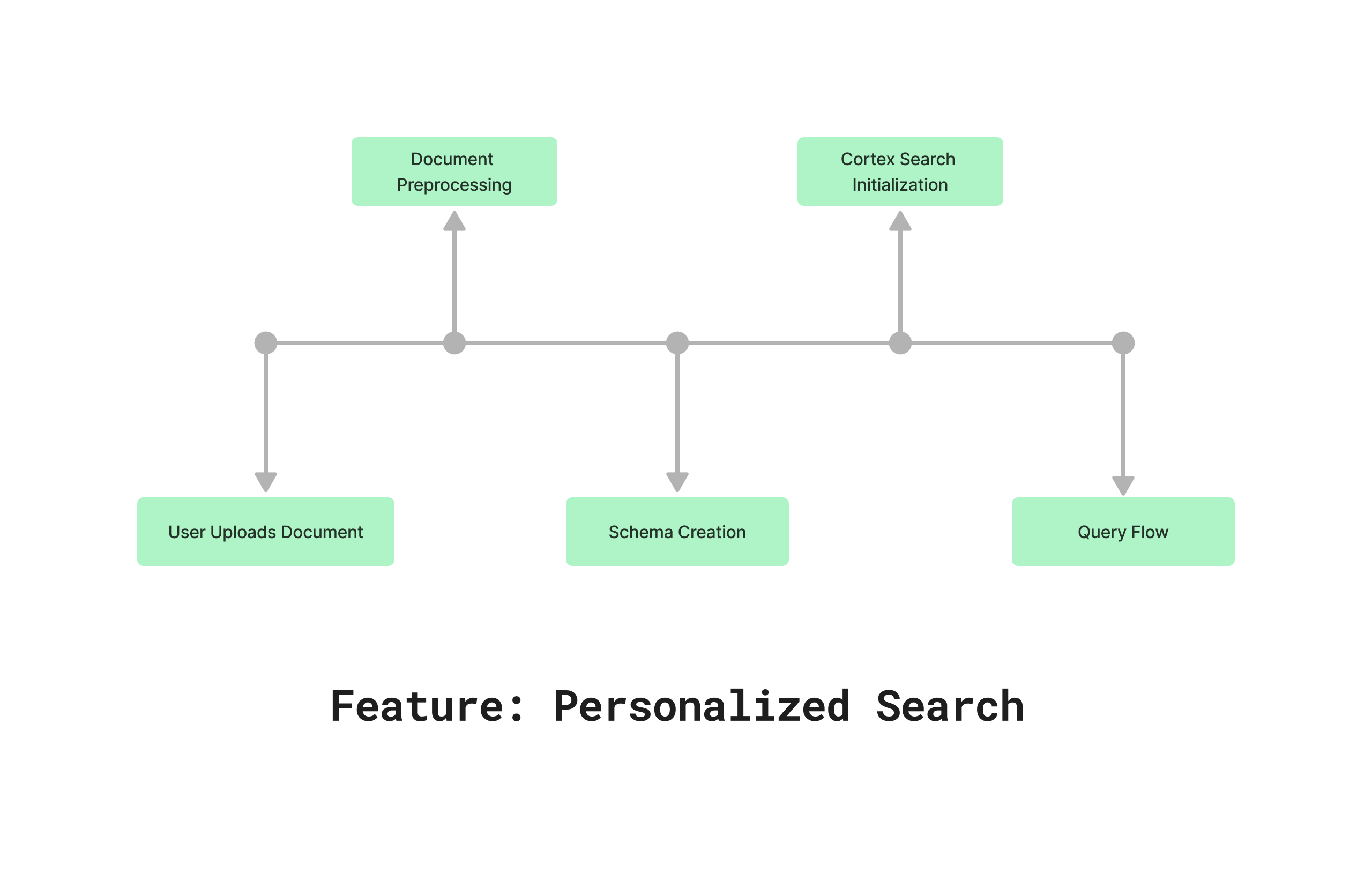
Feature: Personalized Search
This feature gives users the ability to upload their own documents, offering greater flexibility and control. Once uploaded, the documents are preprocessed and stored in a unique schema within the database, ensuring secure and personalized data management. A new Cortex Search service is initialized specifically for the user’s data, enabling efficient and accurate retrieval. This allows users to query their own documents and receive precise responses powered by the LLM, without being limited to predefined datasets. Ultimately, this feature enhances the user experience by providing a fully customizable and scalable solution for document querying.
Fig3: Personalized Search
Trulens Evaluation
We evaluated our model using Trulens, conducting assessments across four versions of our application. During this evaluation, we focused on three key metrics:
- Answer Relevance: Measures the accuracy and pertinence of the response to the user’s query.
- Context Relevance: Assesses how well the retrieved context supports the given query.
- Coherence: Evaluates the logical flow and clarity of the response.
Through these evaluations, we observed significant improvements in both response quality and response time across the different versions. Below is the graph comparing the performance of these versions based on the evaluation metrics.
Fig4: Trulens
What we learned
- Snowflake helped us manage large datasets effortlessly, offering a scalable and secure solution that performs well even under heavy loads.
- With Cortex Search, we were able to quickly and accurately retrieve data, improving the efficiency of our search capabilities.
- Using LLM from Cortex allowed us to deliver responses that are context-aware and precise, making the user experience much more intuitive and relevant.
- Streamlit made it easy to get our app up and running, offering an intuitive interface that allows users to interact with the app smoothly and without hassle.
By putting all these technologies together, we were able to create a robust and scalable solution that can grow with the needs of our users.






Log in or sign up for Devpost to join the conversation.