-
-
portal_when_user_lands_on_site_1st_ss
-
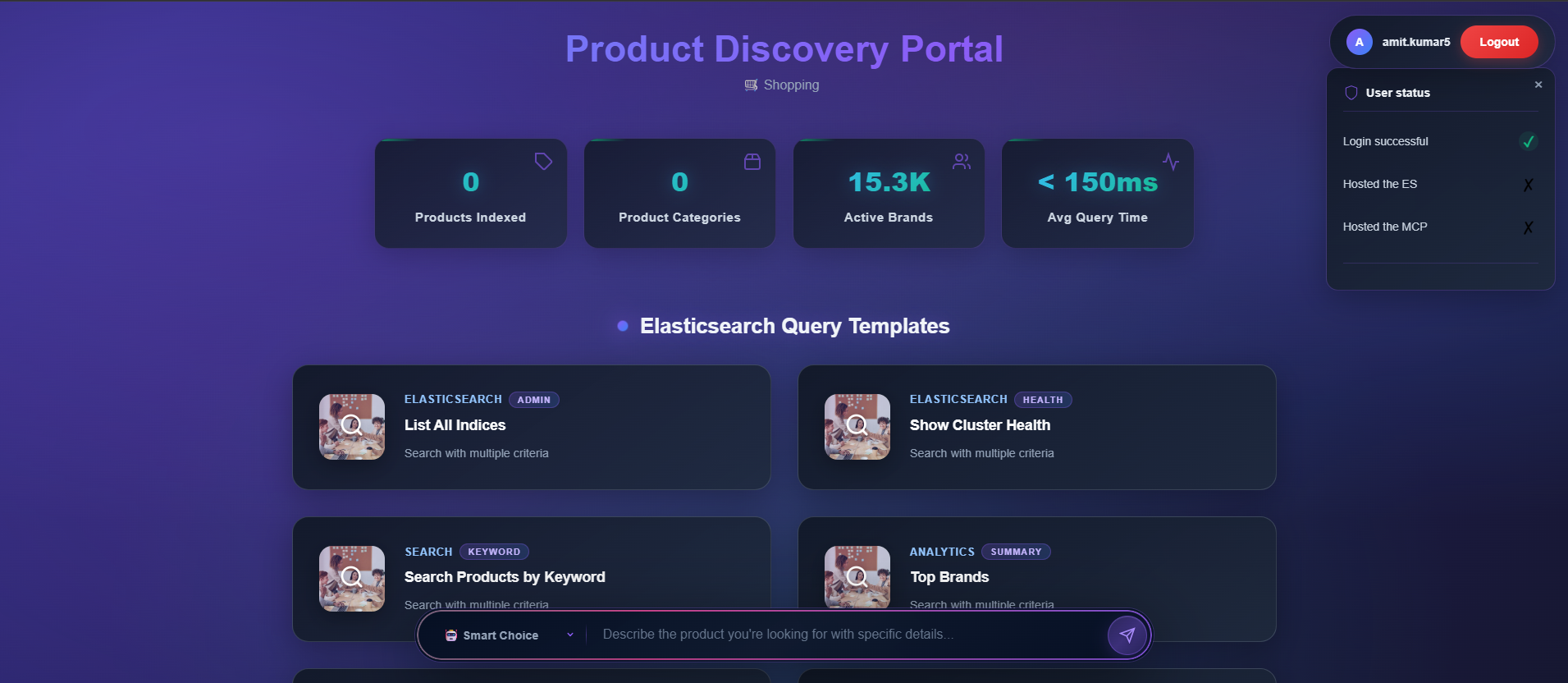
portal_when_user_lands_on_site_query_templates_2nd_ss
-

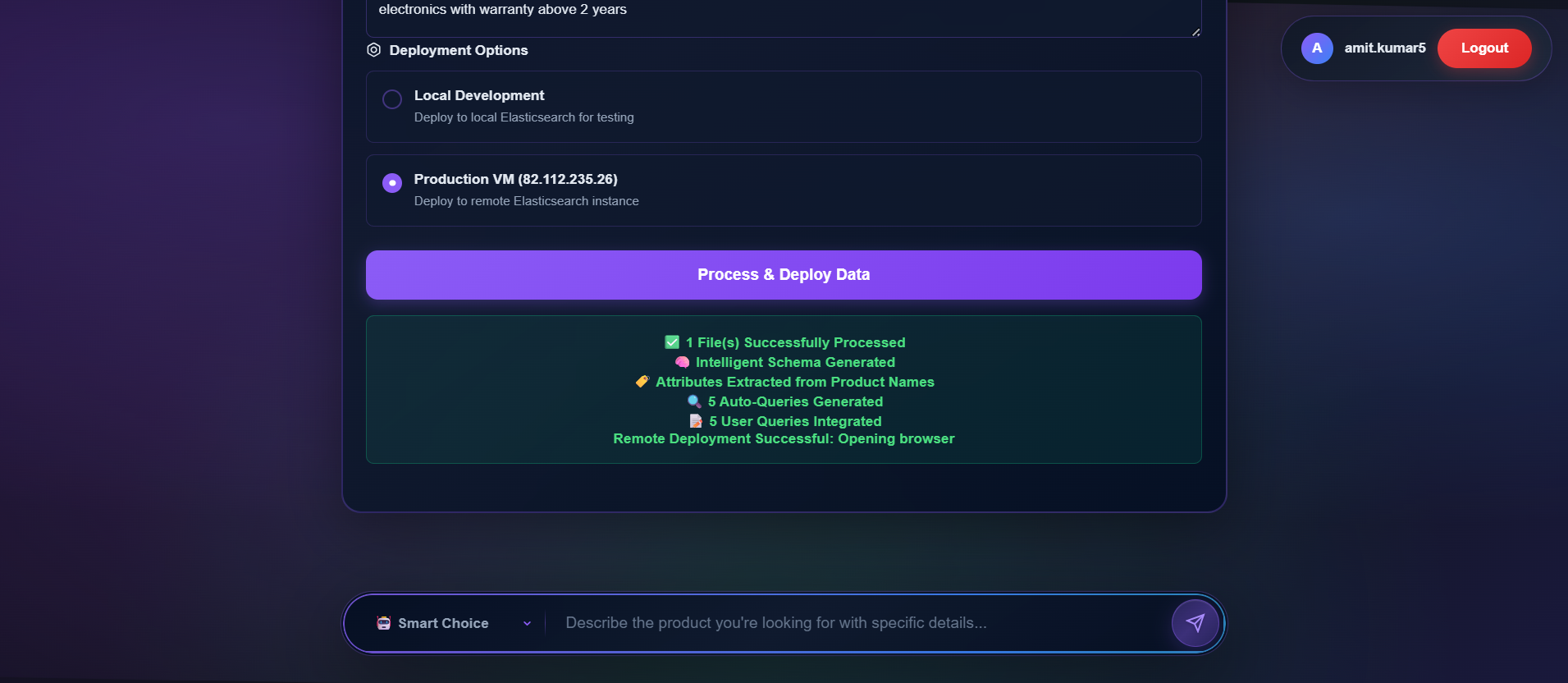
portal_when_user_lands_on_site_advanced_features_3rd_ss
-
portal_when_user_lands_on_site_upoad_section_4th_and_last_ss
-
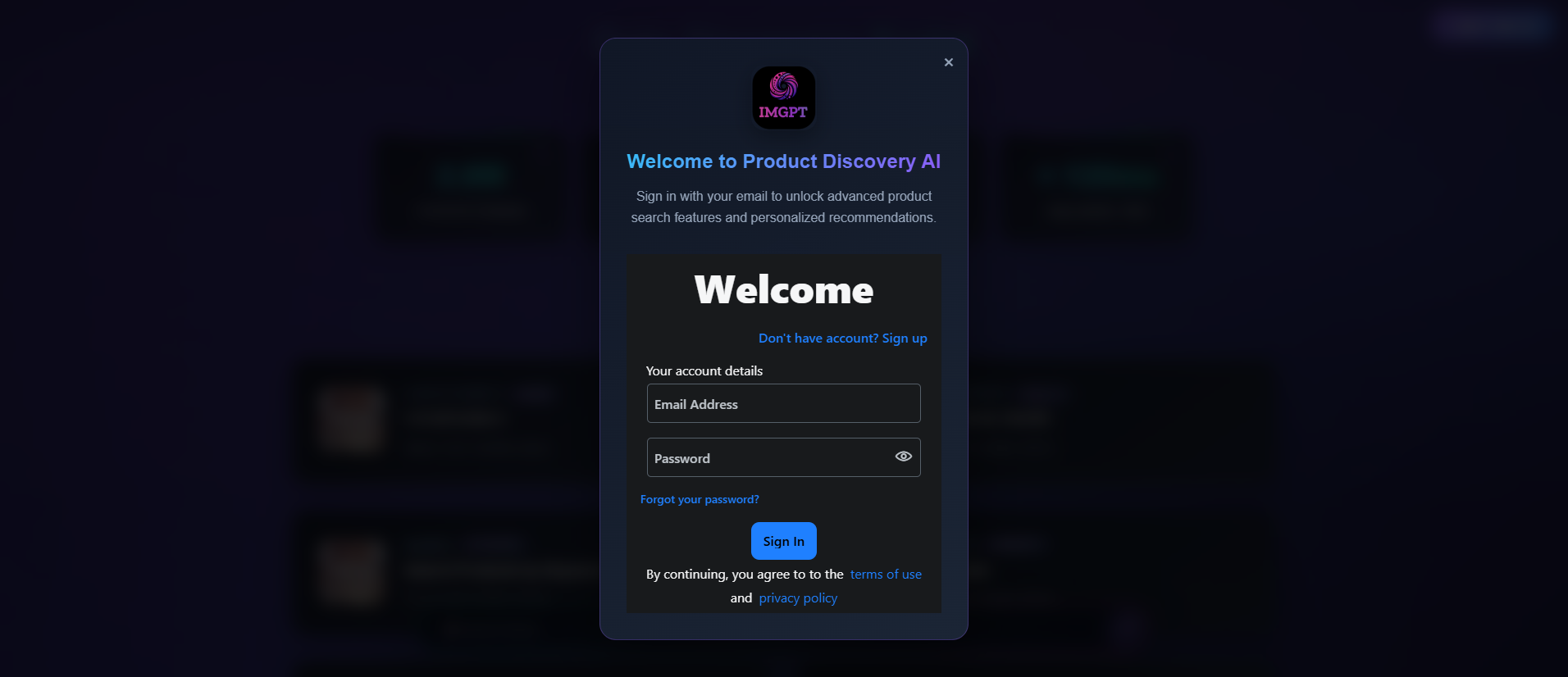
user_authentication_sign_in_and_sign_up_5th_ss
-
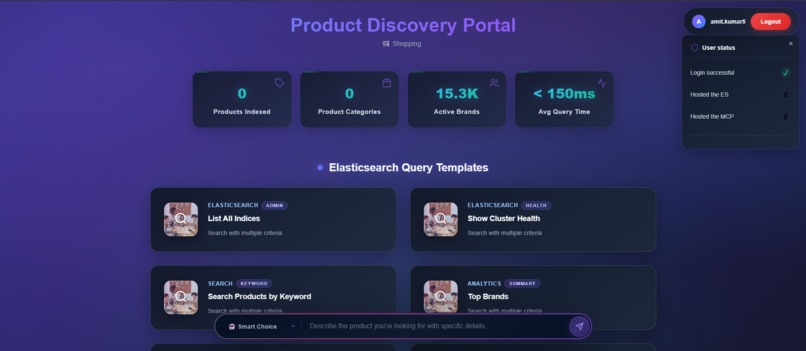
when_user_login_first_time_and_dont_have_es_and_mcp_instances_6th_ss
-
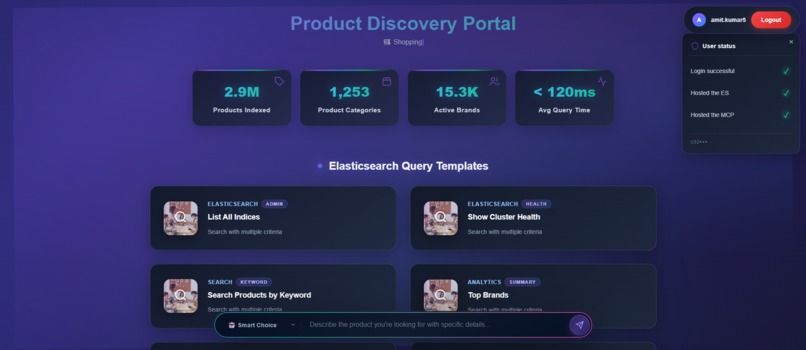
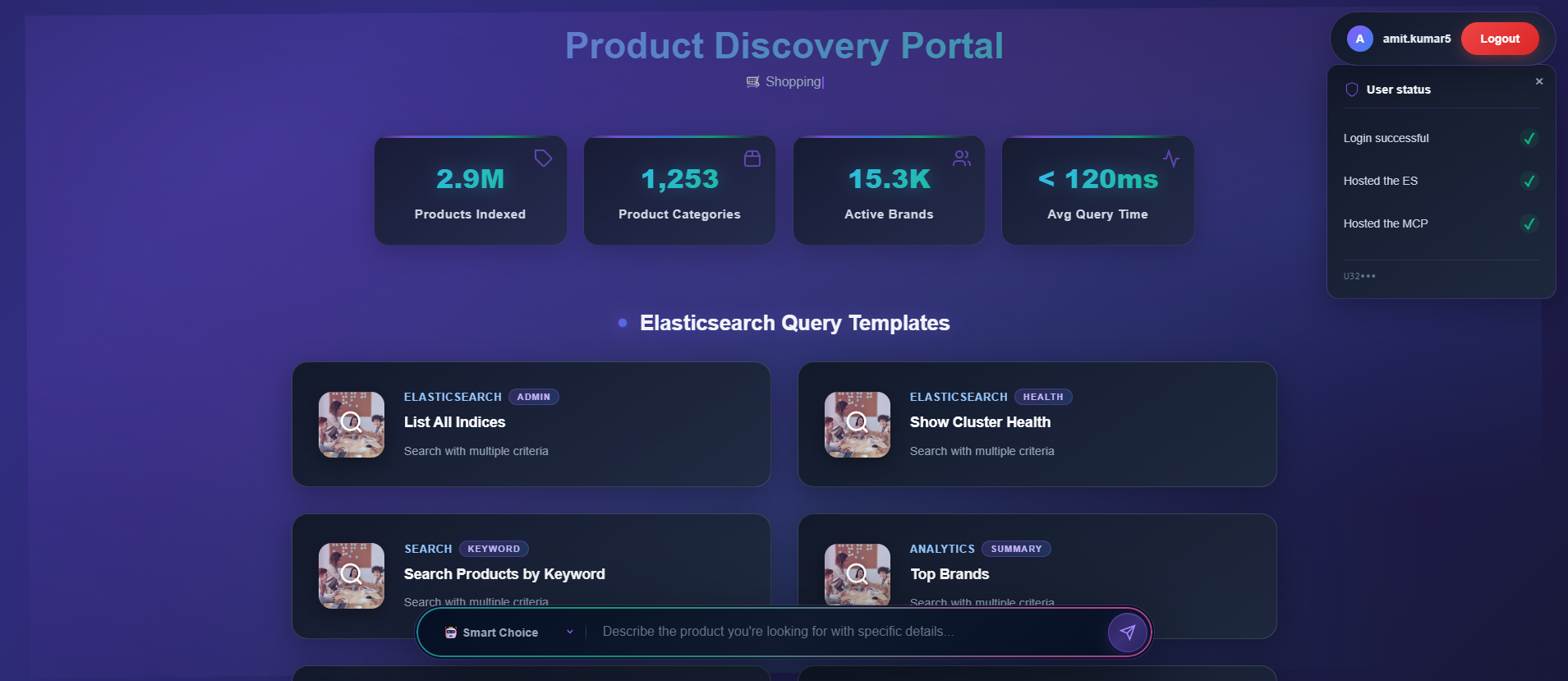
when_user_have_es_and_mcp_nodes_instantiated_green_tick_on_all_options_7th_ss
-
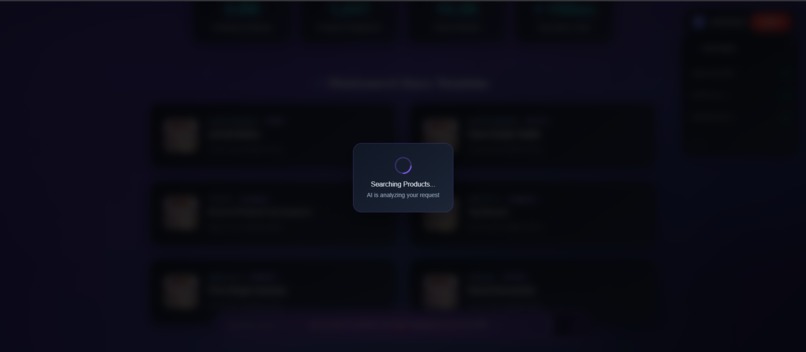
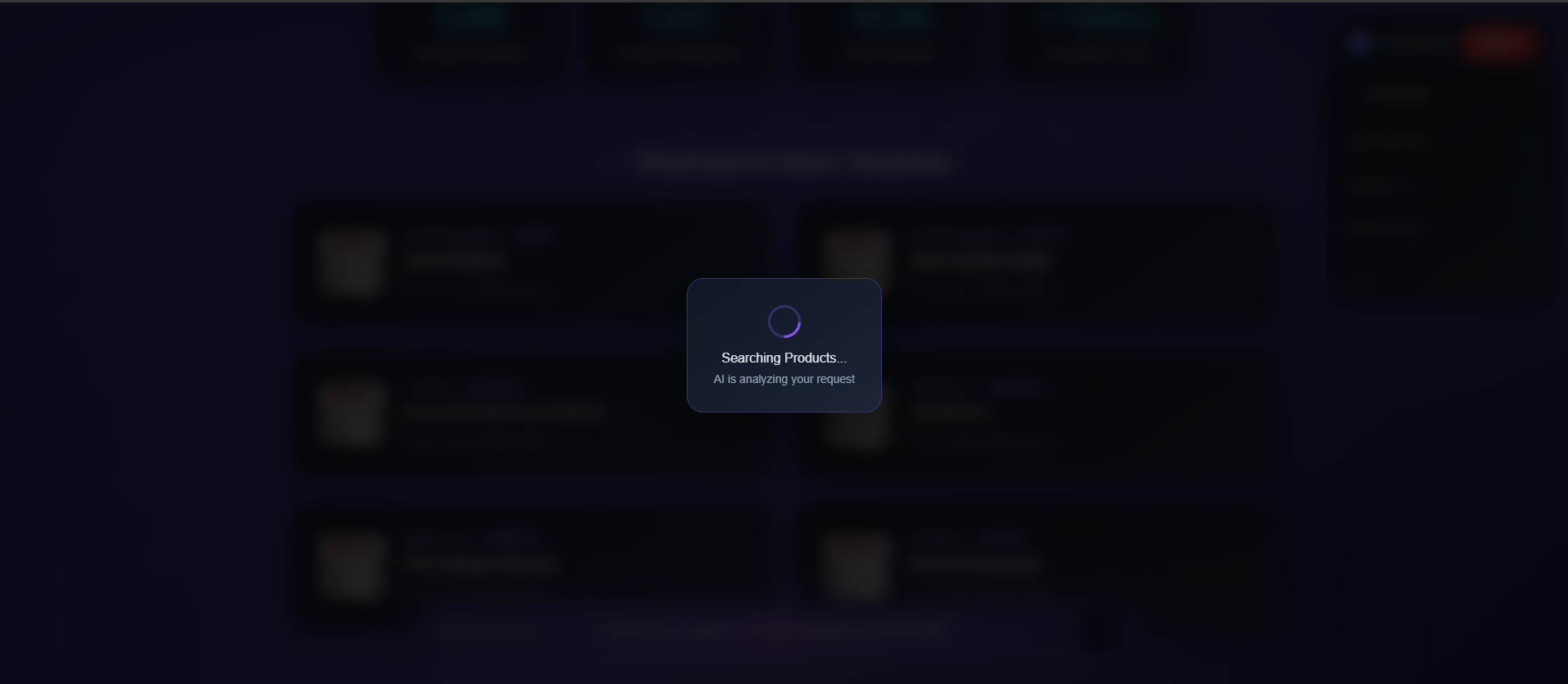
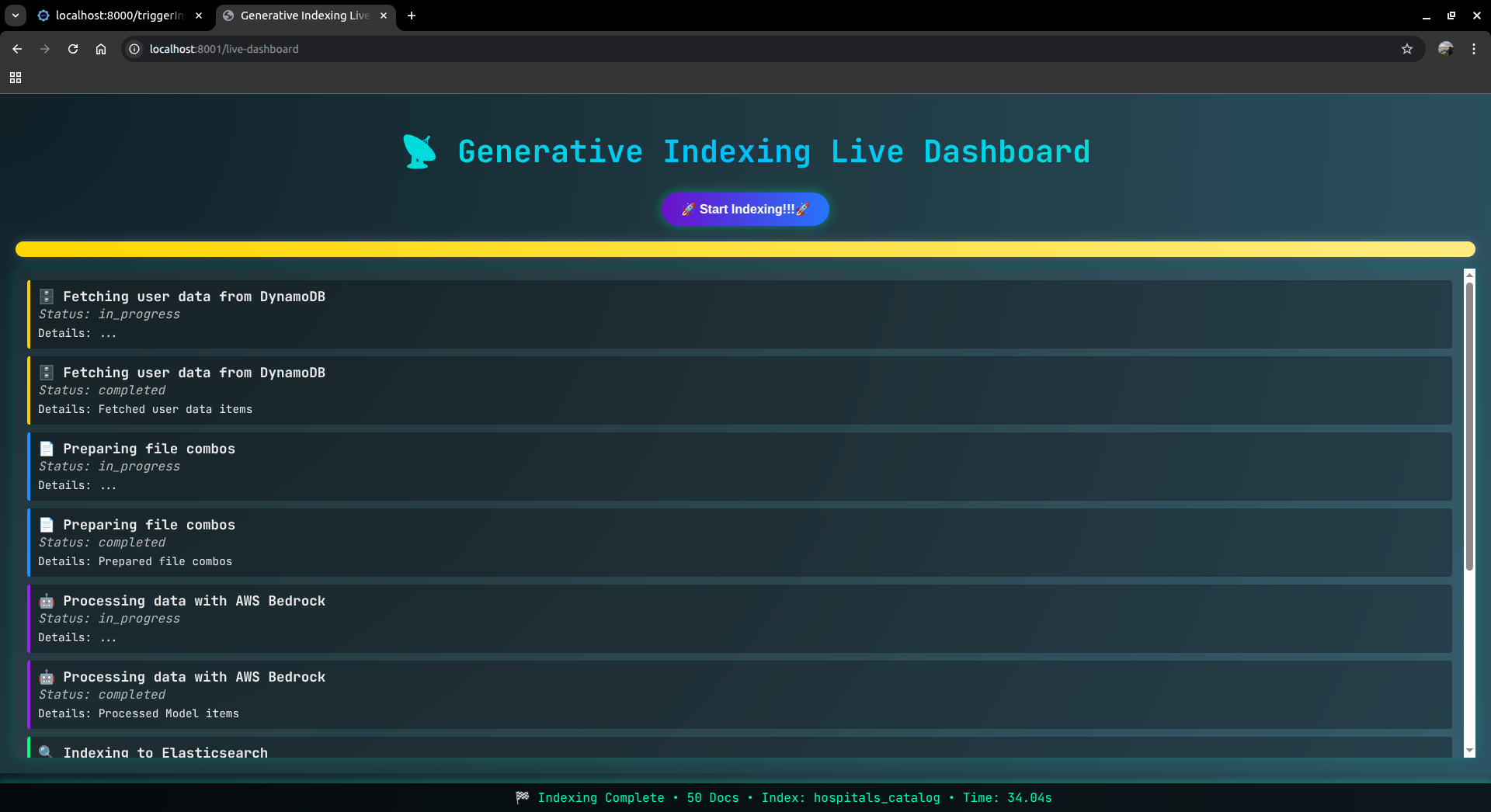
when_some_query_is_searched_then_buffering_state_8th_ss
-
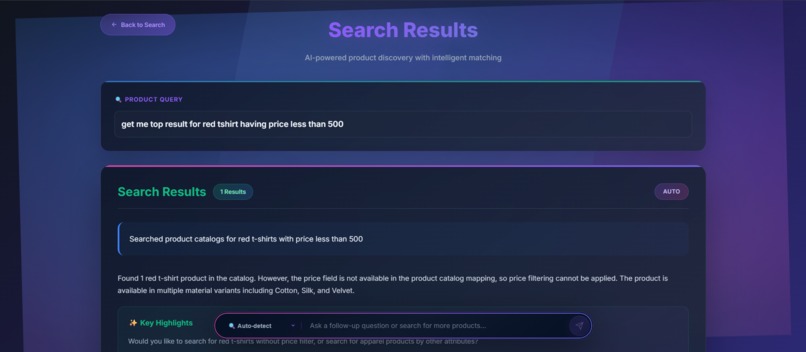
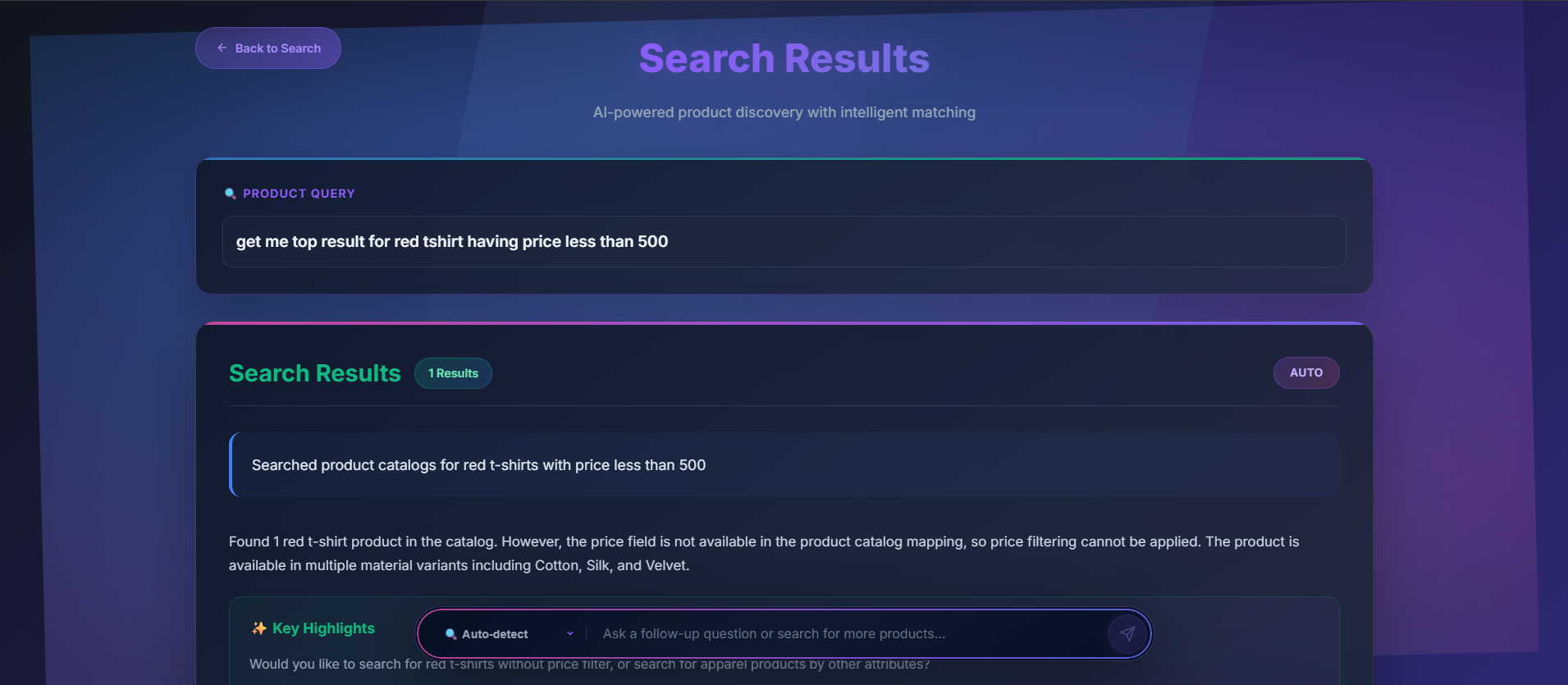
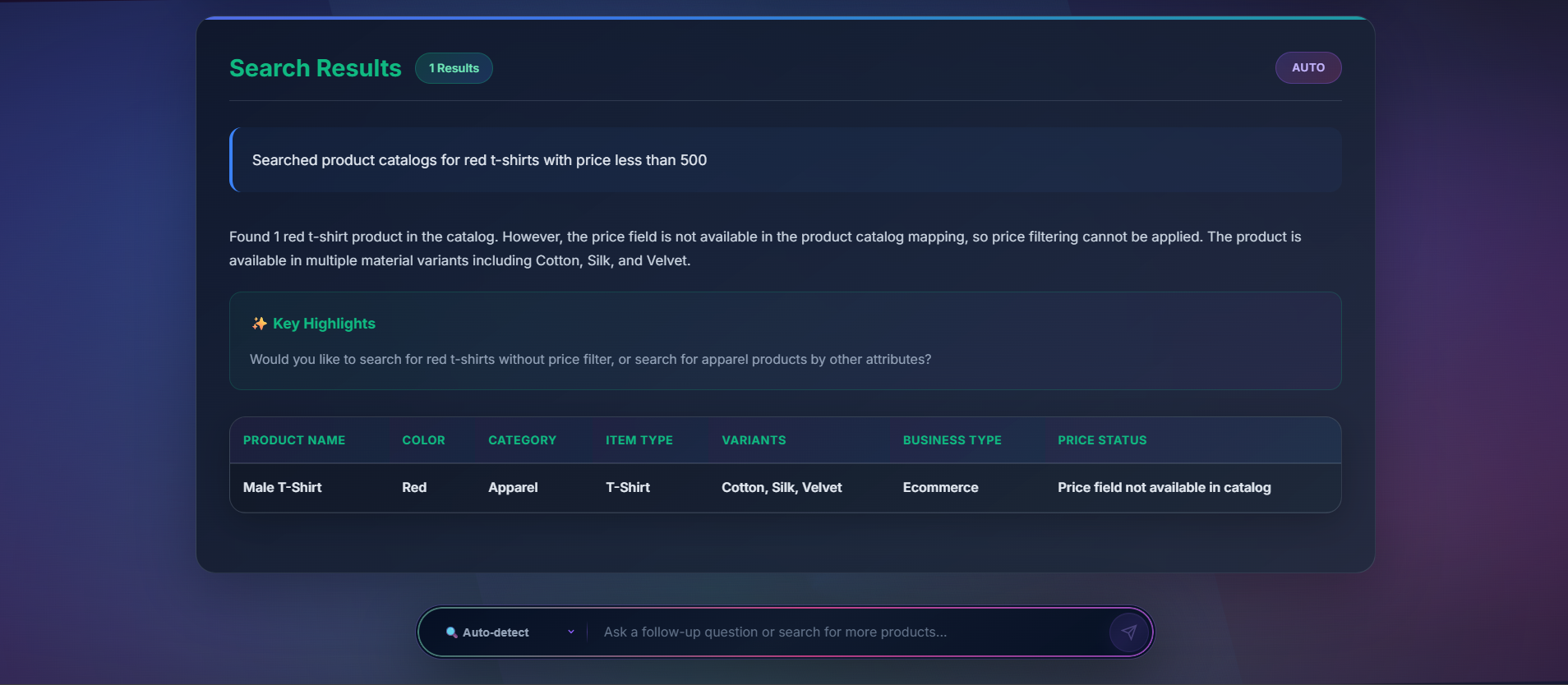
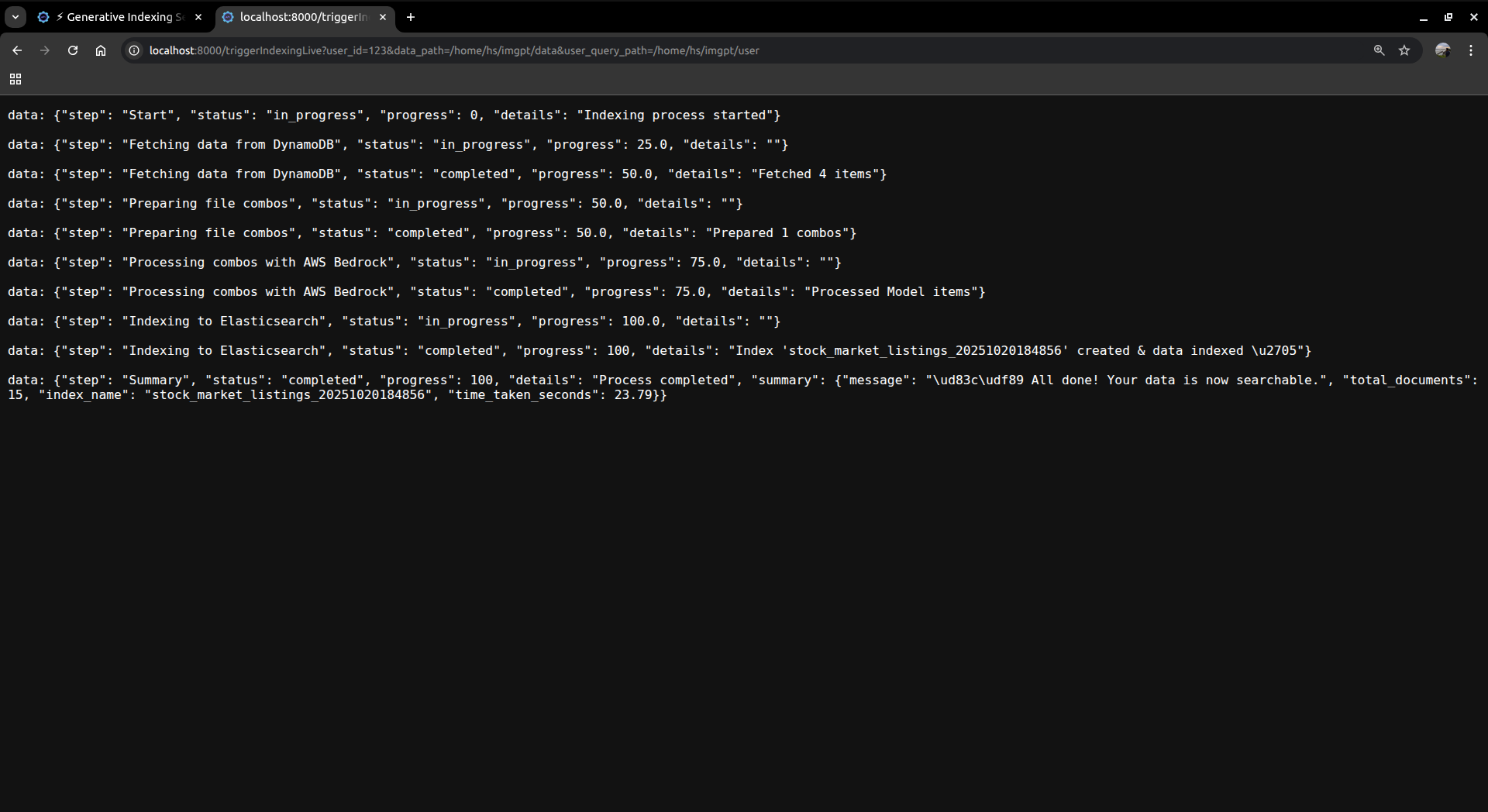
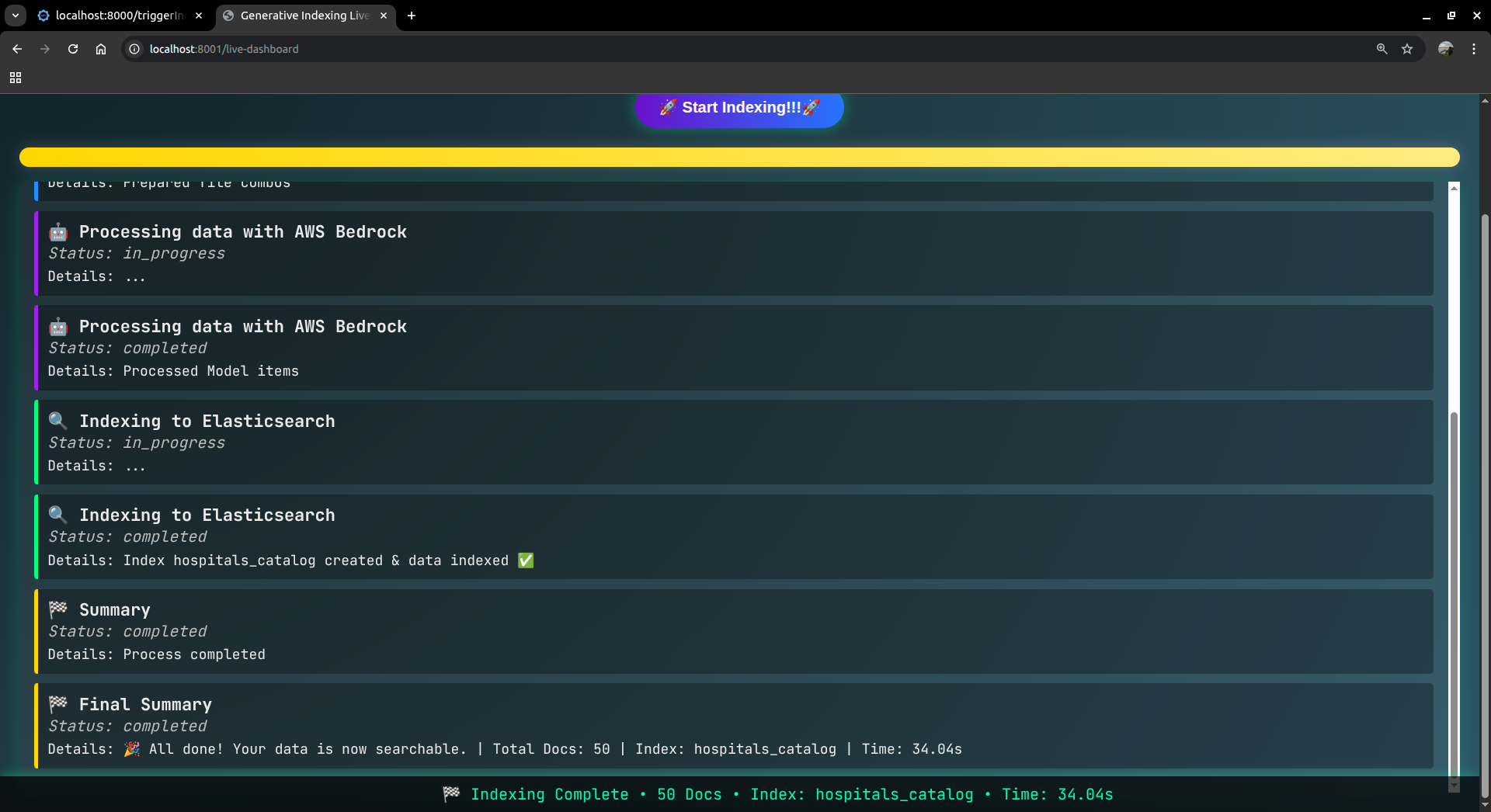
getting_result_for_the_user_query_9th_ss_portion1
-
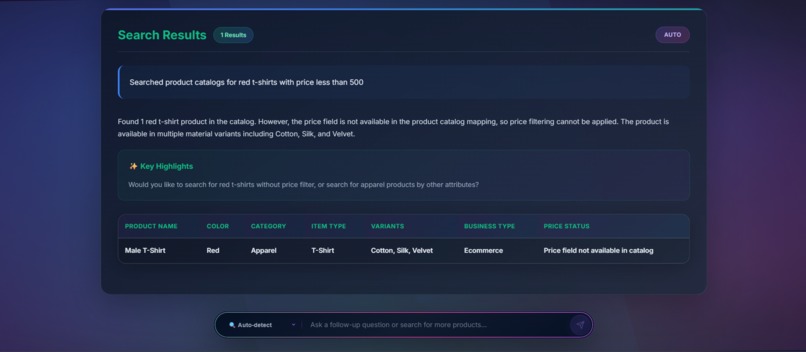
getting_result_for_the_user_query_10th_ss_portion2
-
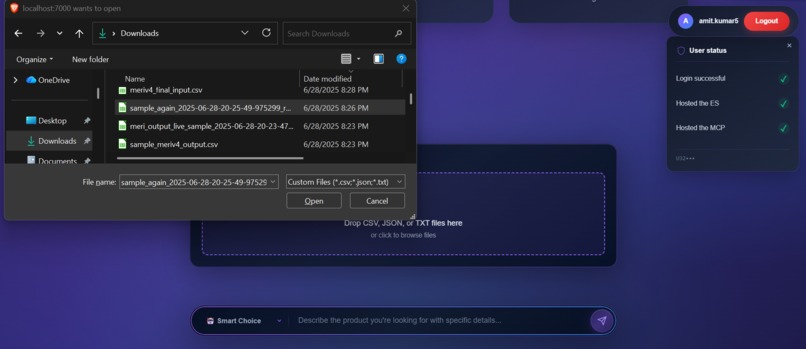
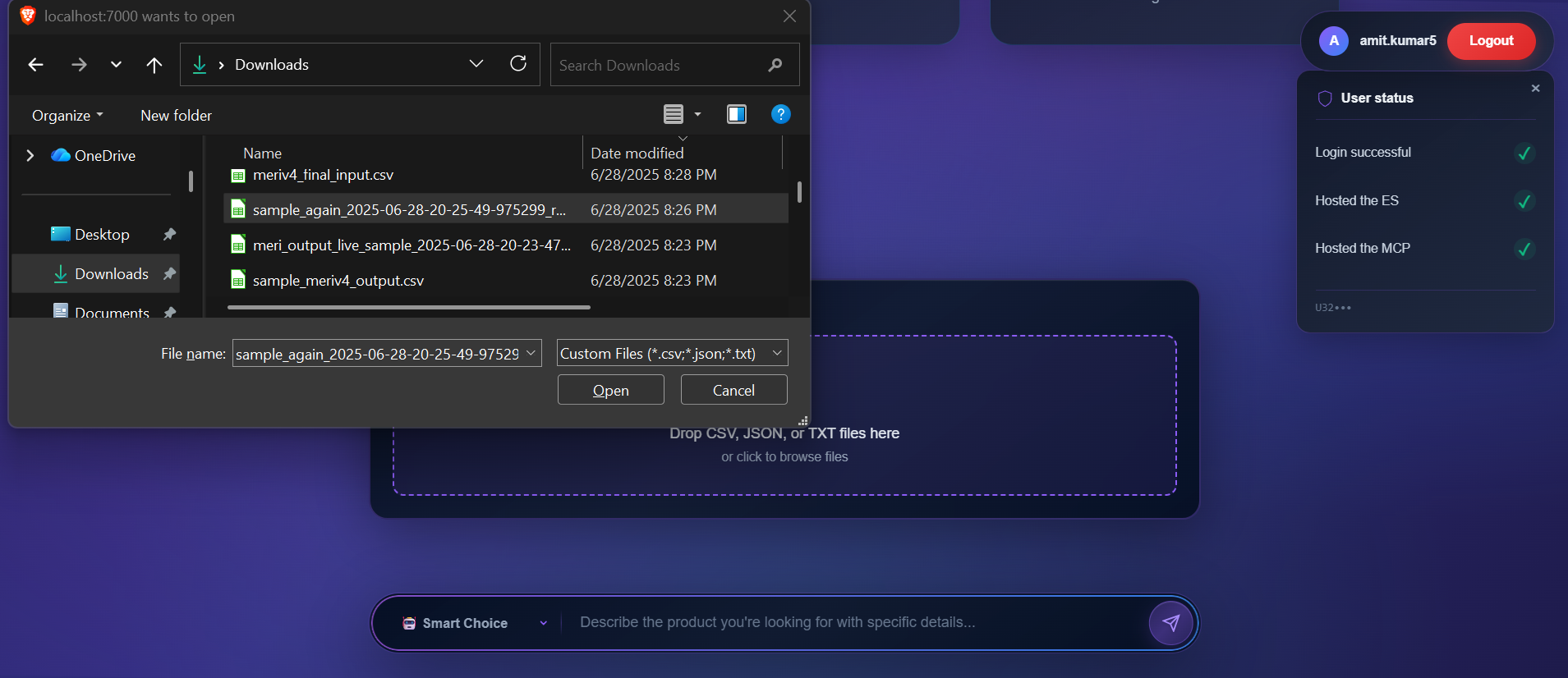
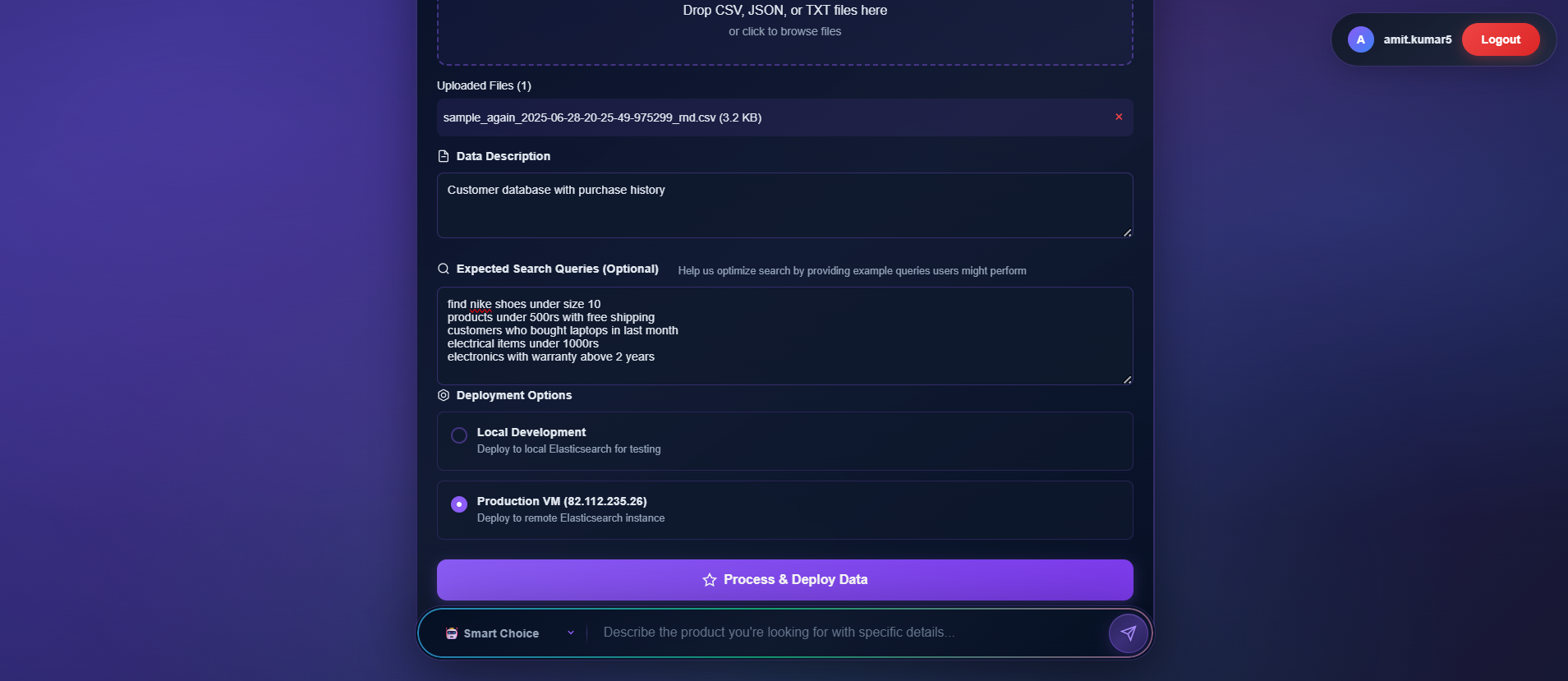
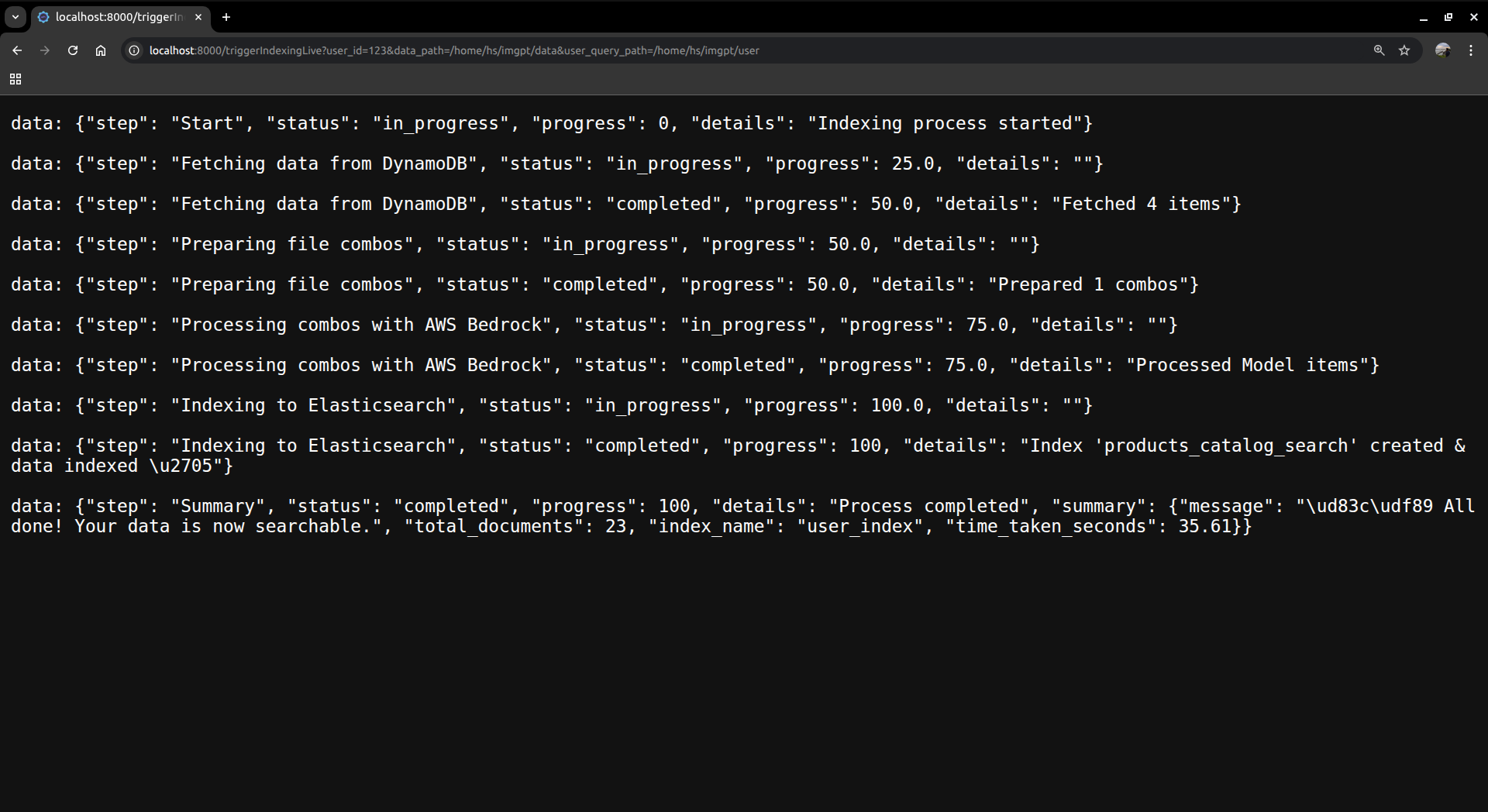
uploading_user_data_despite_of_structure_11th_ss
-
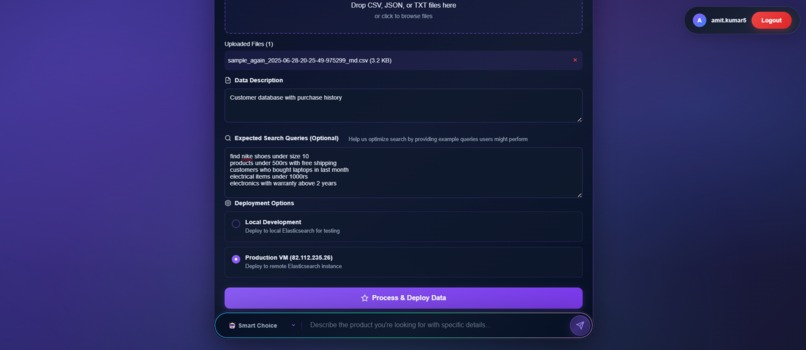
upload_and_deploy_user_database_and_having_queries_mandatory_this_will_spin_up_es_and_mcp_at_backend_12th_ss
-
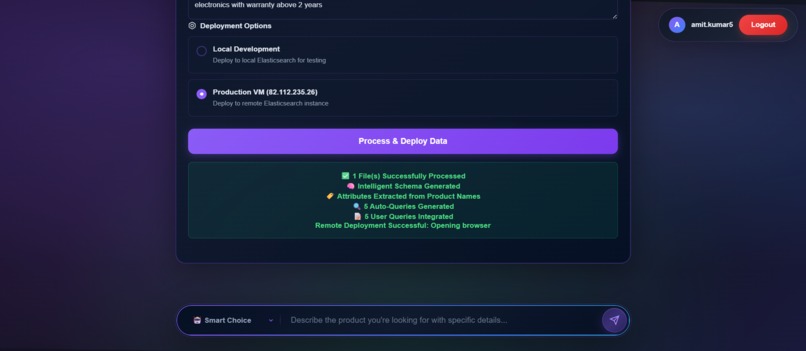
successful_es_and_mcp_spin_up_13th_ss
-
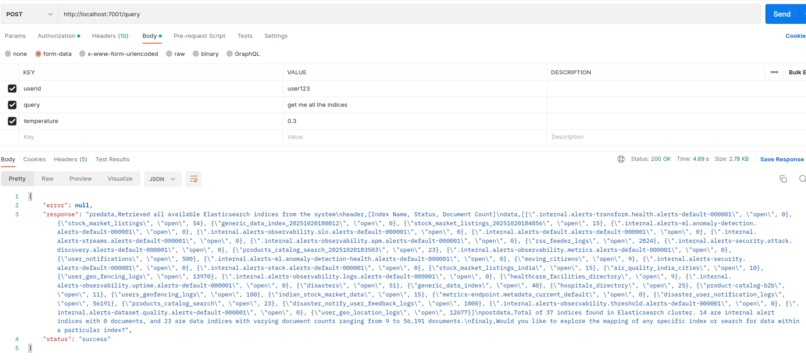
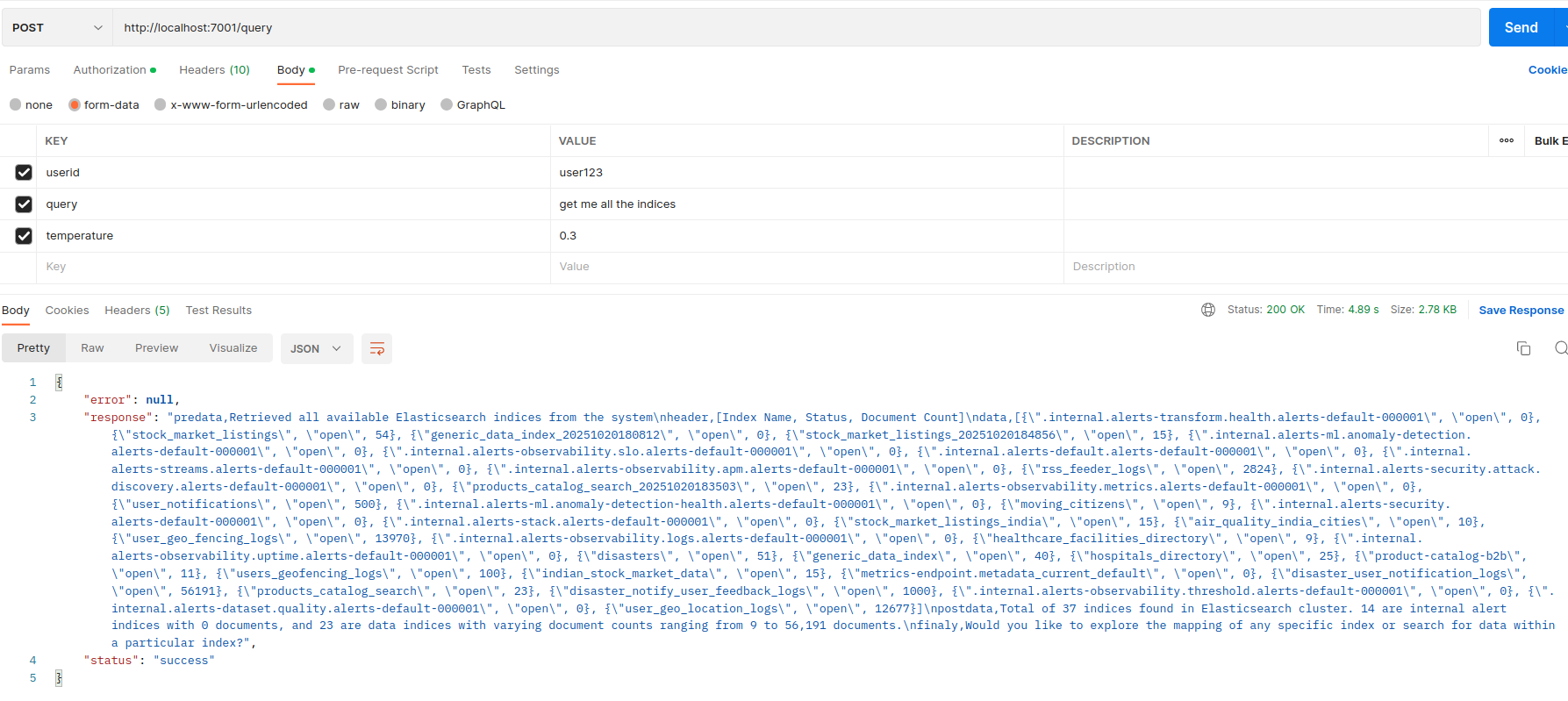
Query API
-
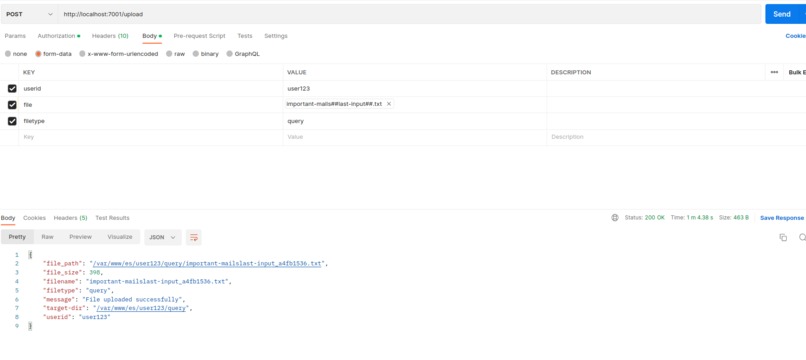
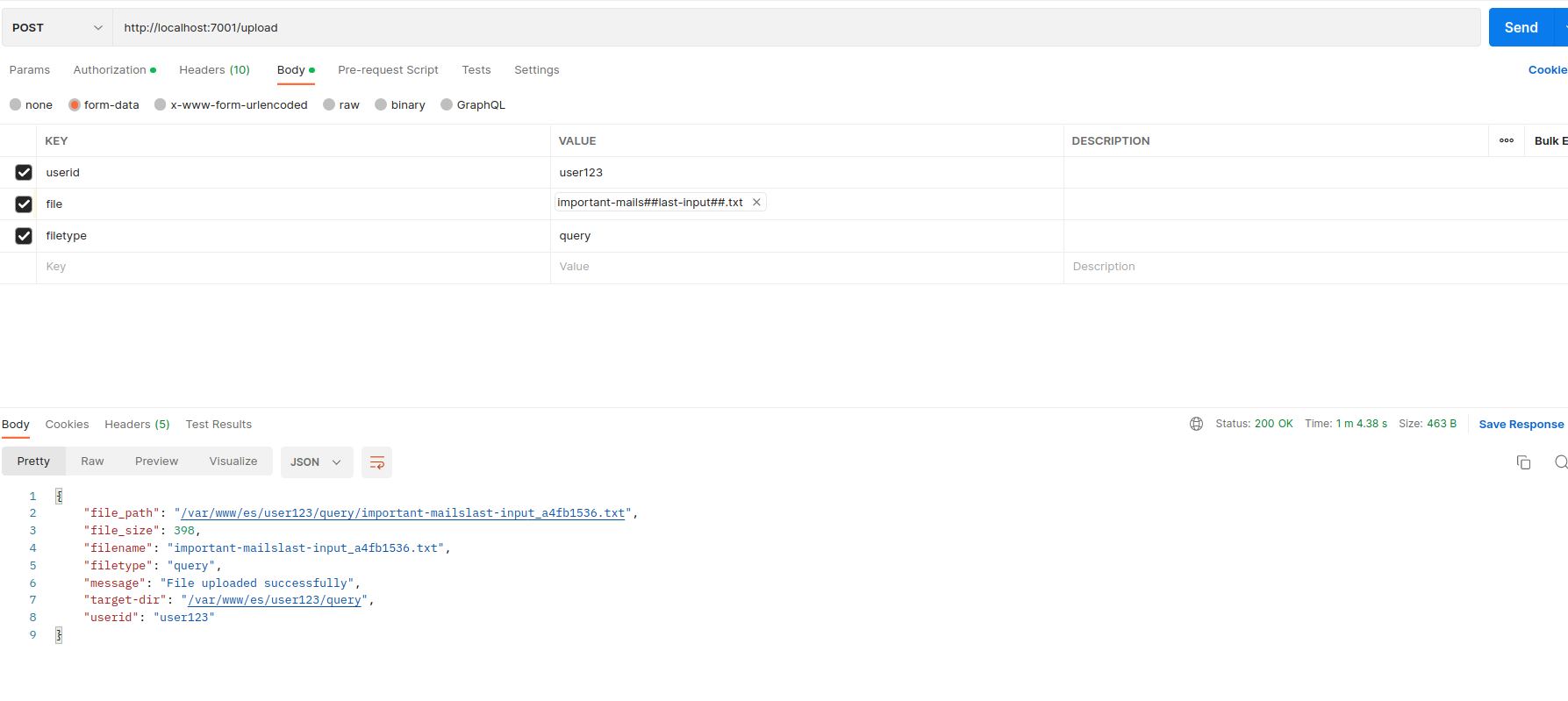
Upload API
-
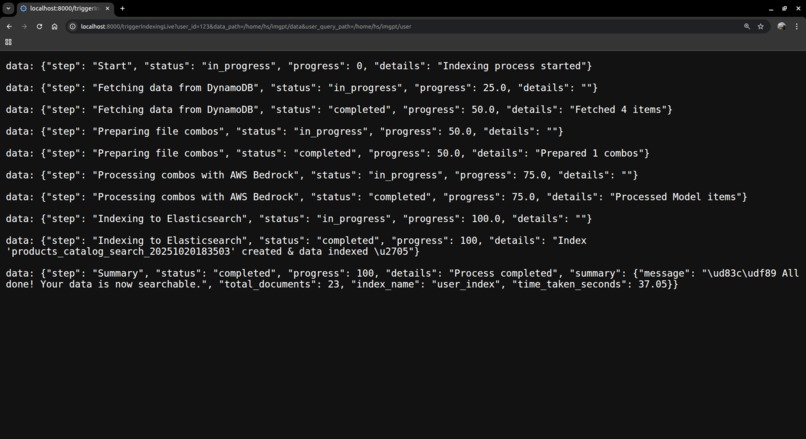
api_on_browser_completed
-
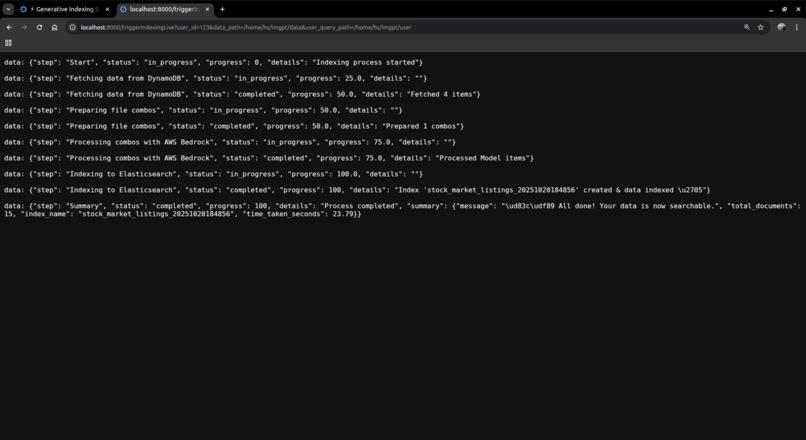
dry_run_prd_data_index_name_custom_timestamp
-
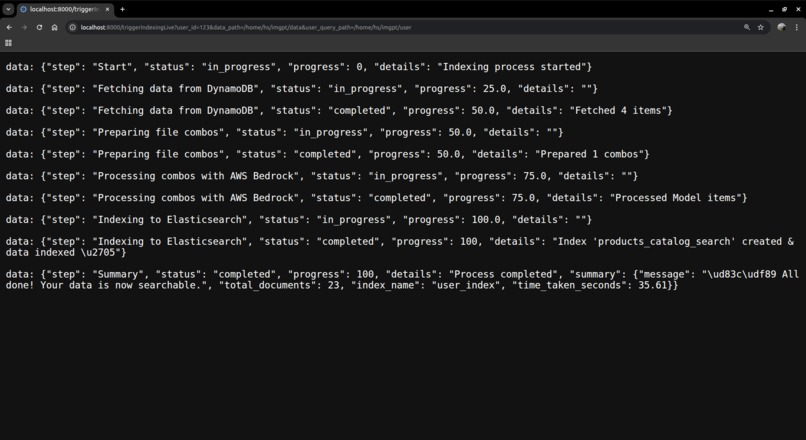
dry_run_with_stock_data
-
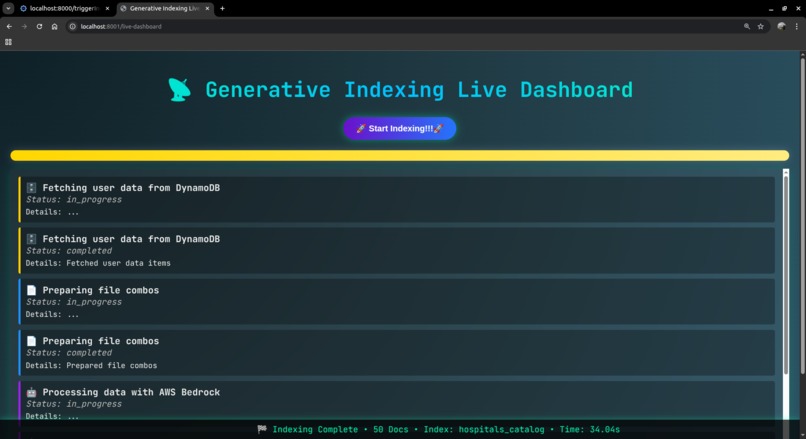
api_call_example2
-
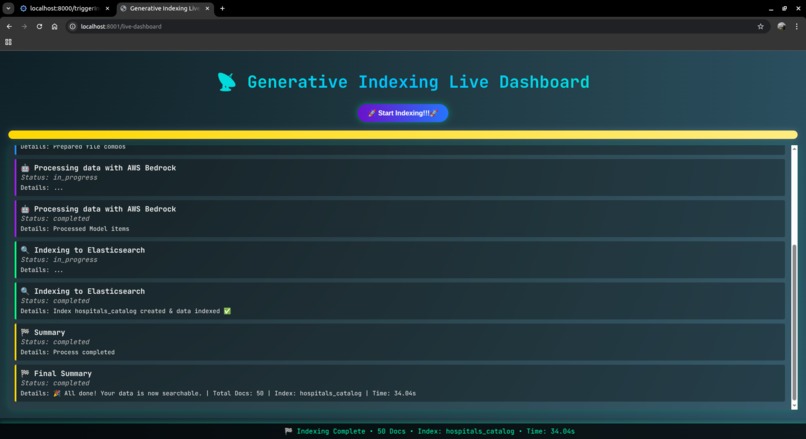
api_call_ui_example1
-
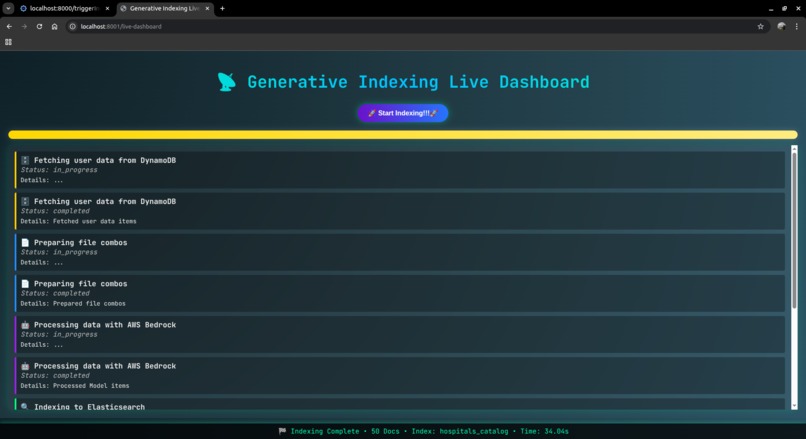
api_call_example_3
-
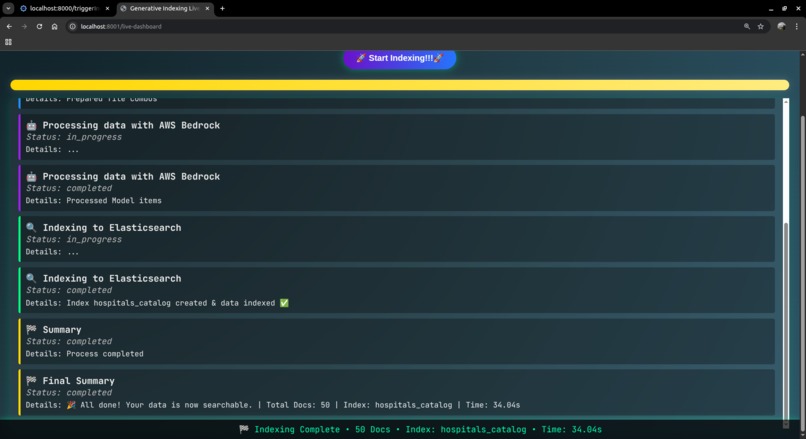
api_call_example_4
-
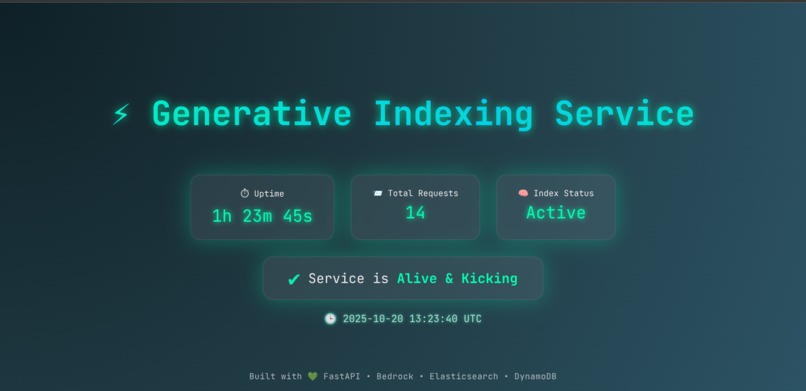
API Homepage
-
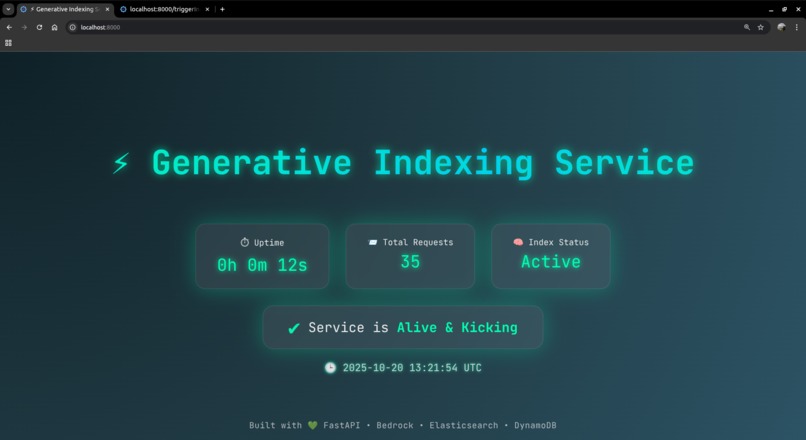
API Homepage on Local
-
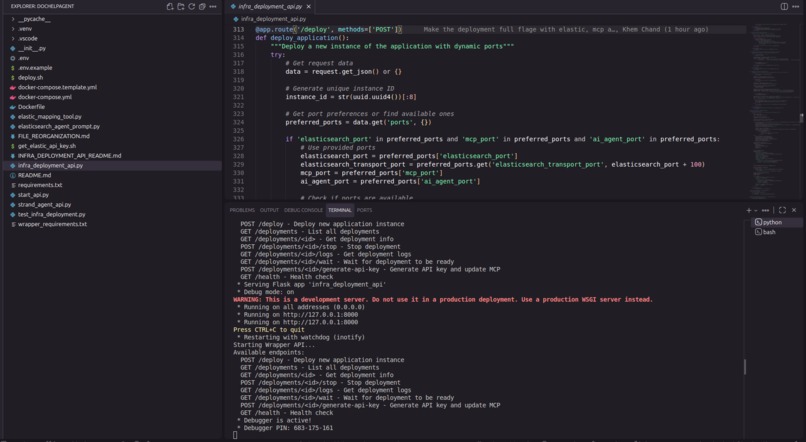
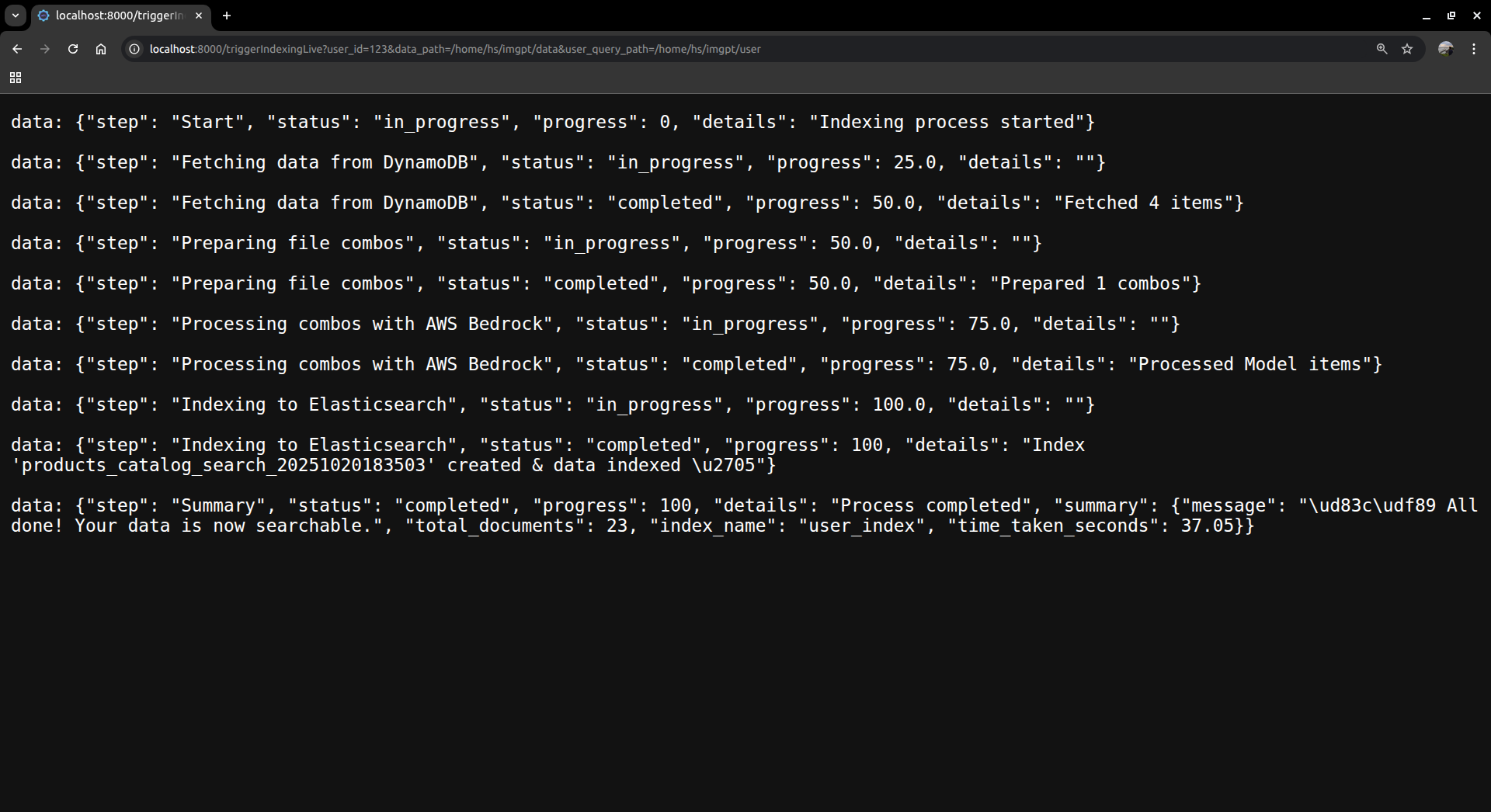
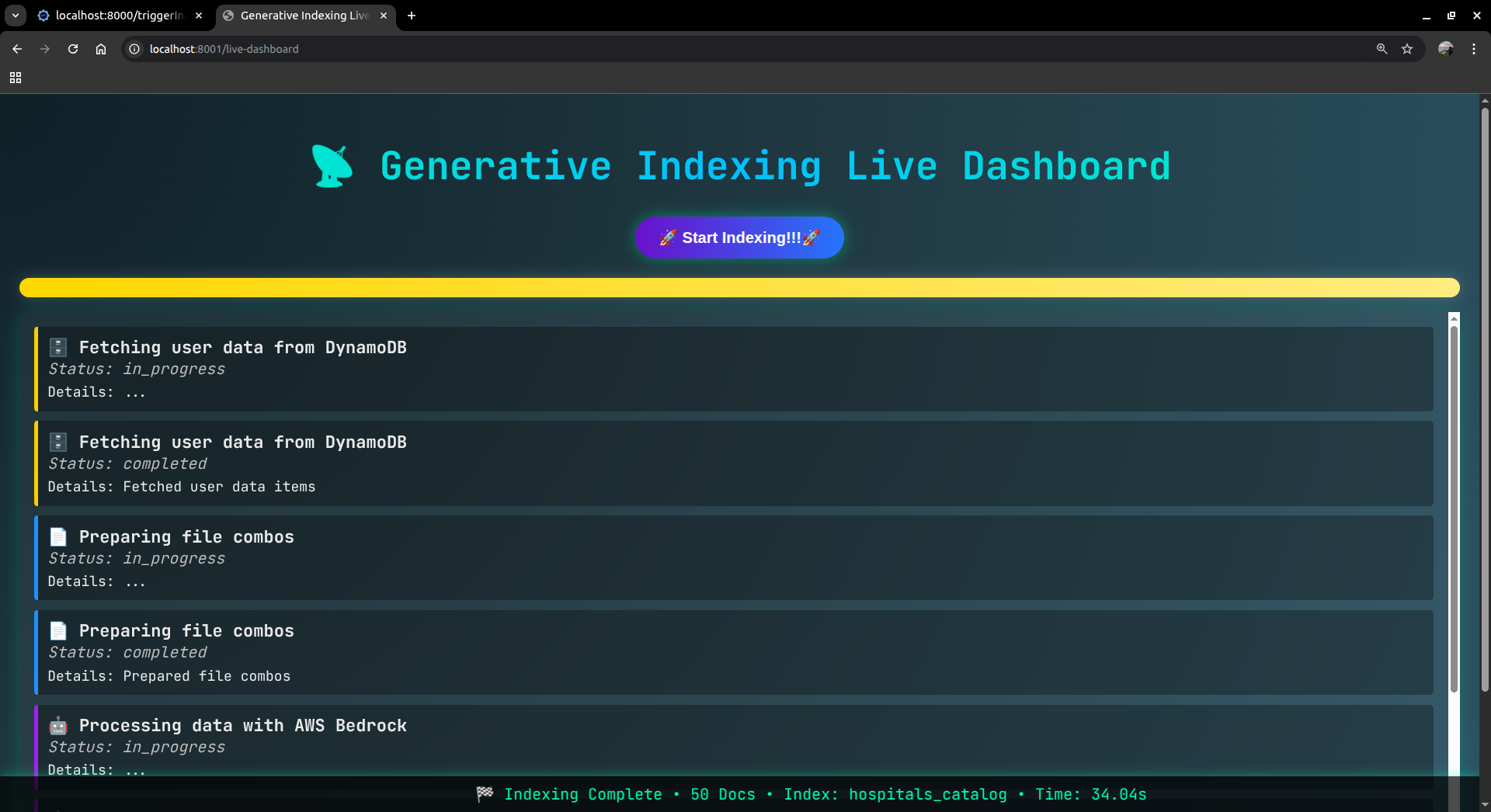
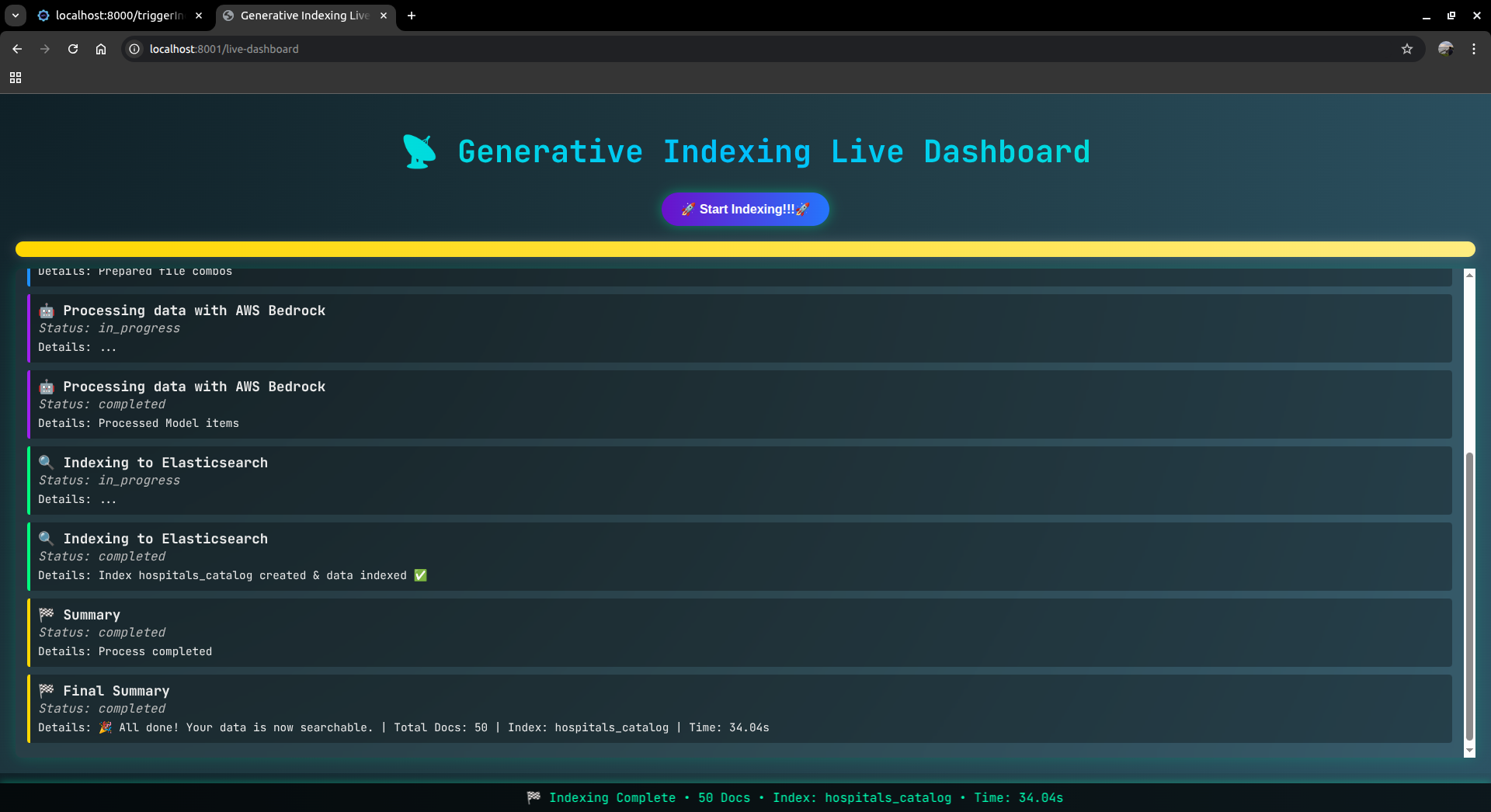
Server Running -SpinUp Search infra base on user - including elasticsearch db, elastic mcp, strand search agent
-

User Query -1 - Call go AI Strand Search Agnet - it get the details form es
-

User Query -2 - Call go AI Strand Search Agnet - it get the details form es .png
-
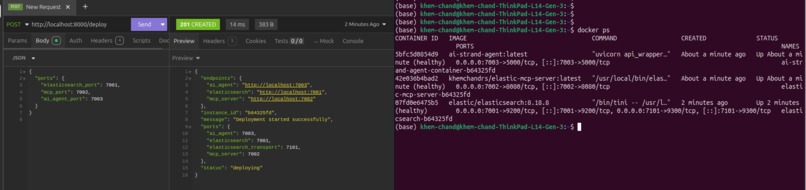
Client Request -SpinUp Search infra base on user - including elasticsearch db, elastic mcp, strand search agent.png
-
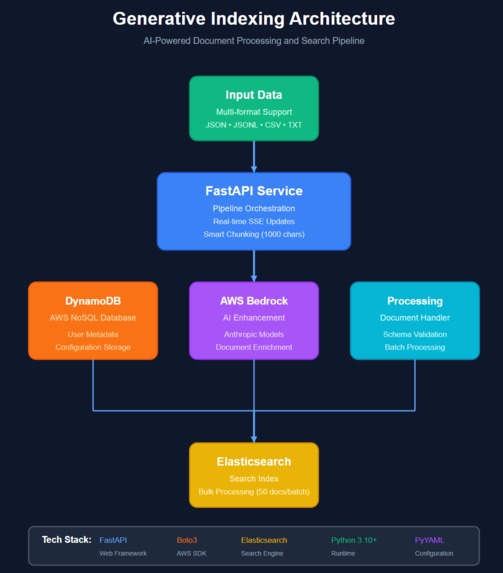
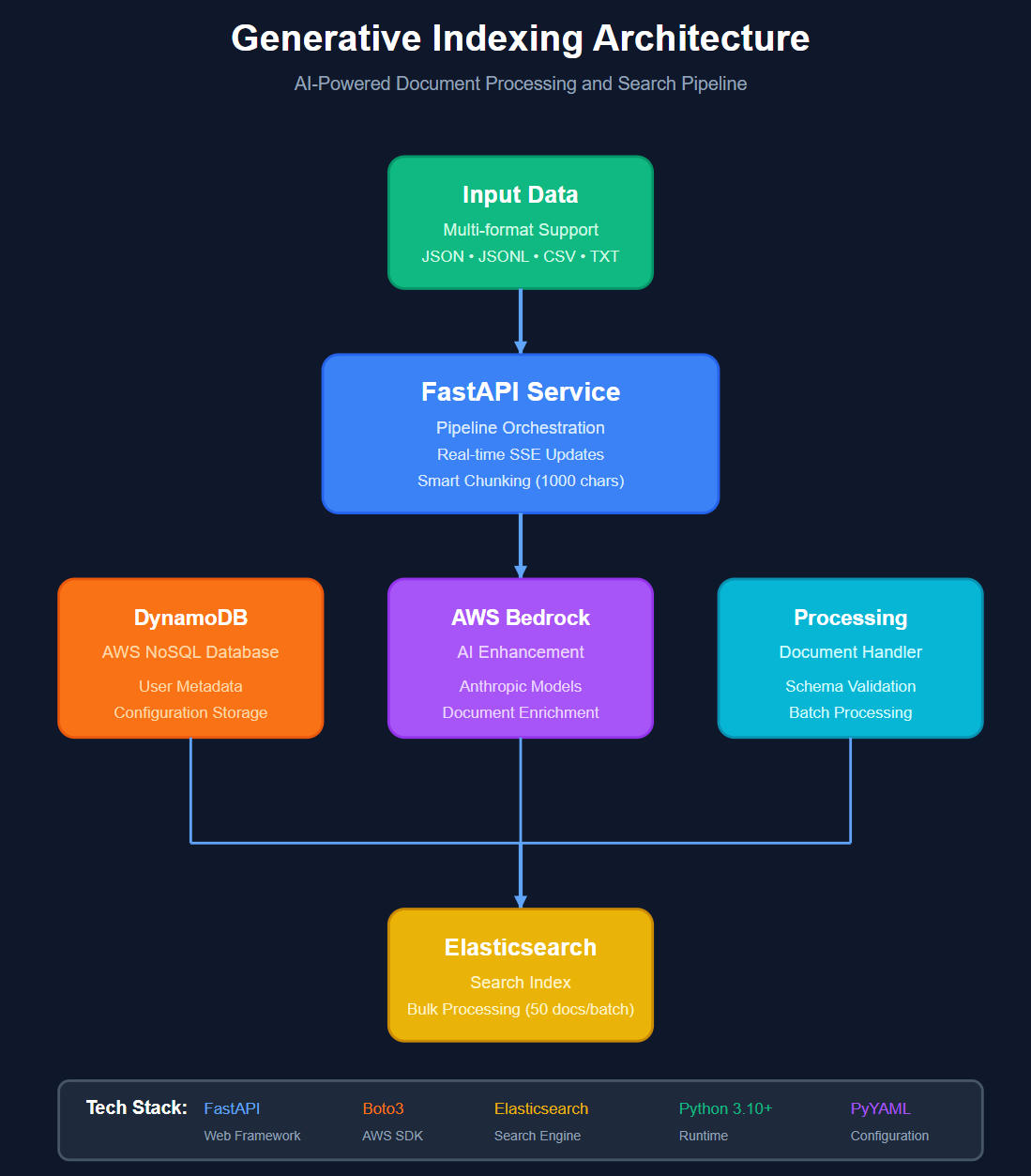
High Level Architecture Diagram
-
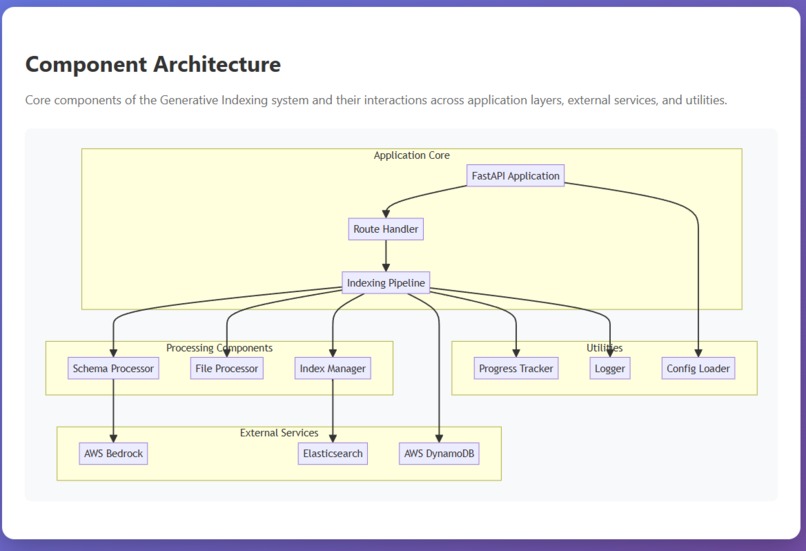
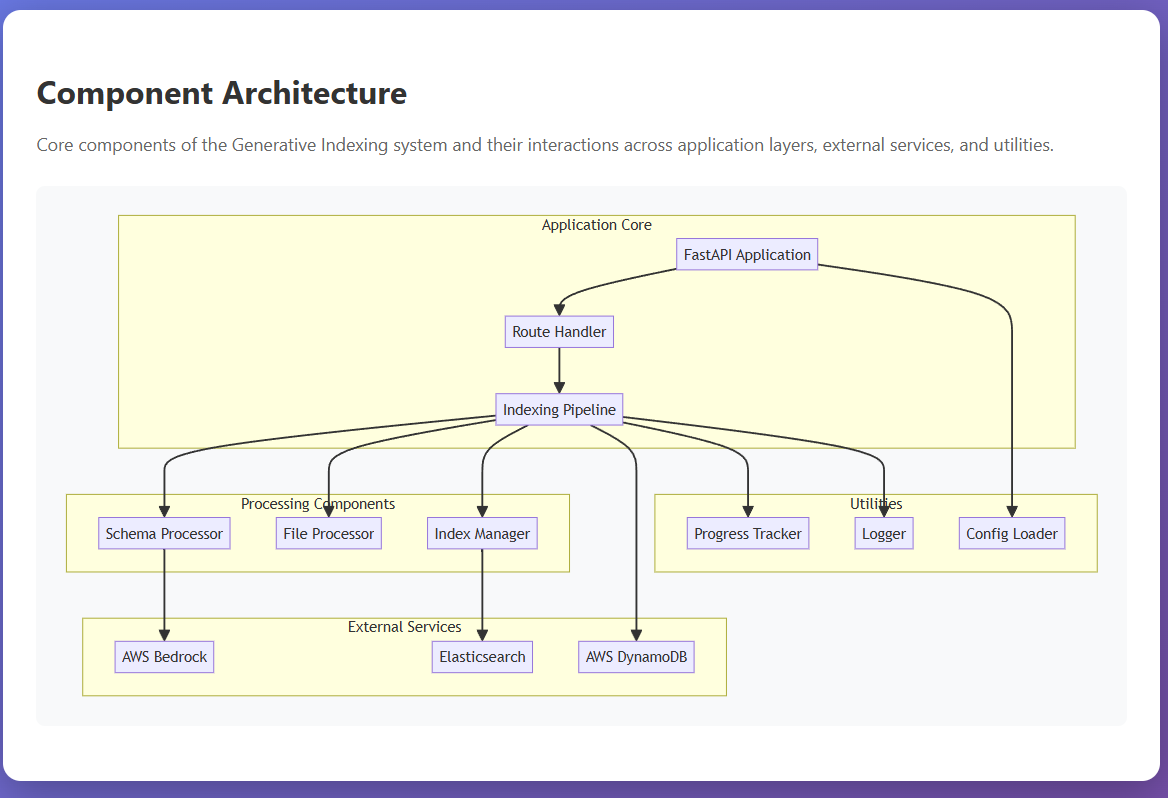
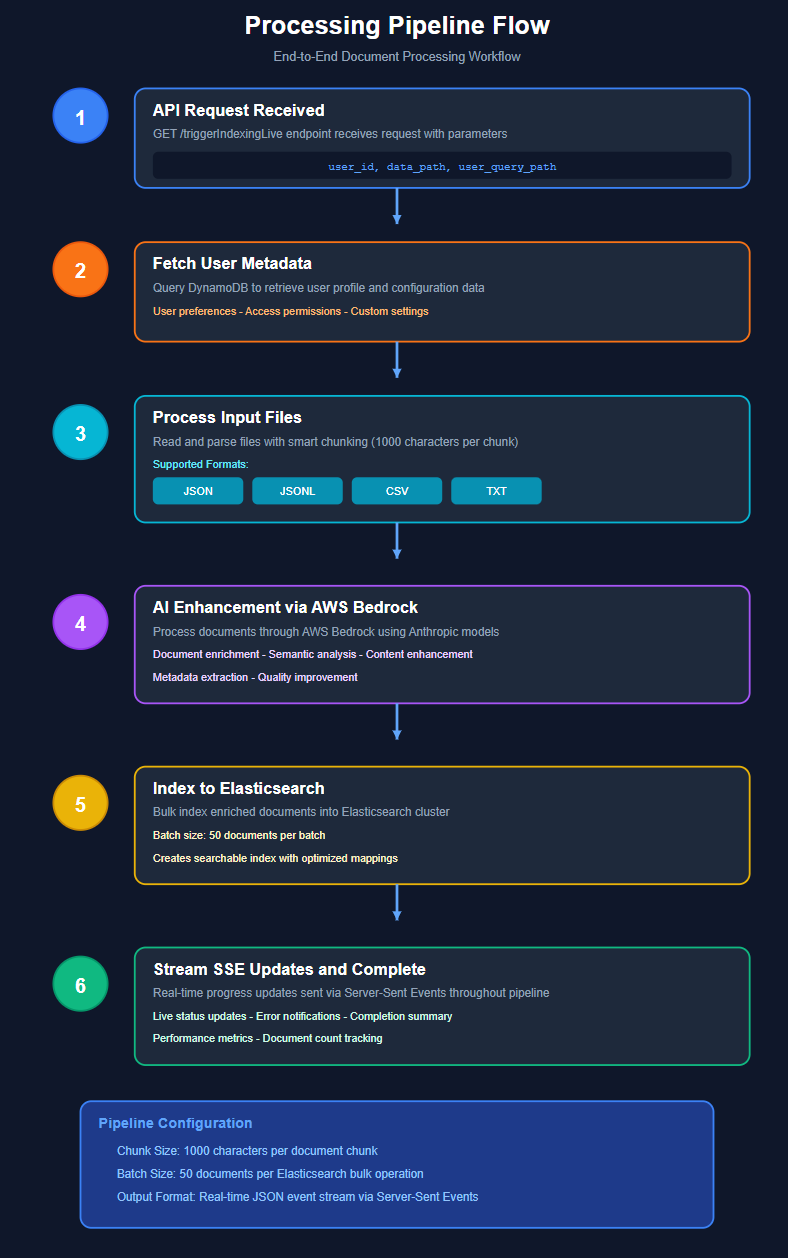
Component Flow
-
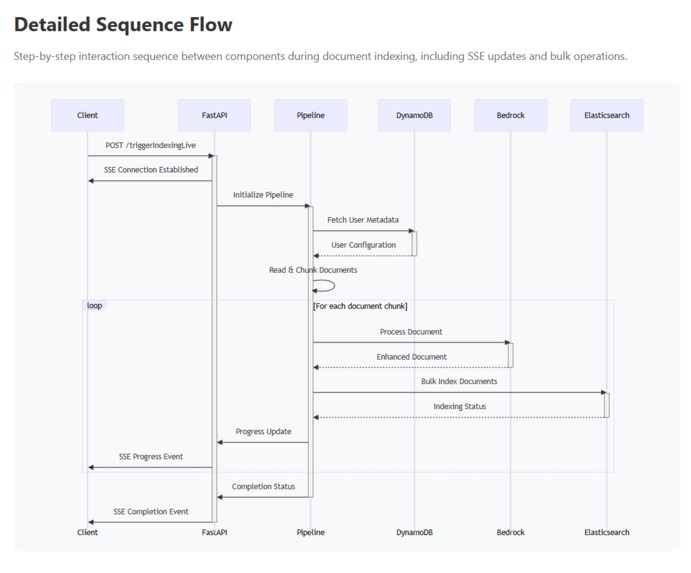
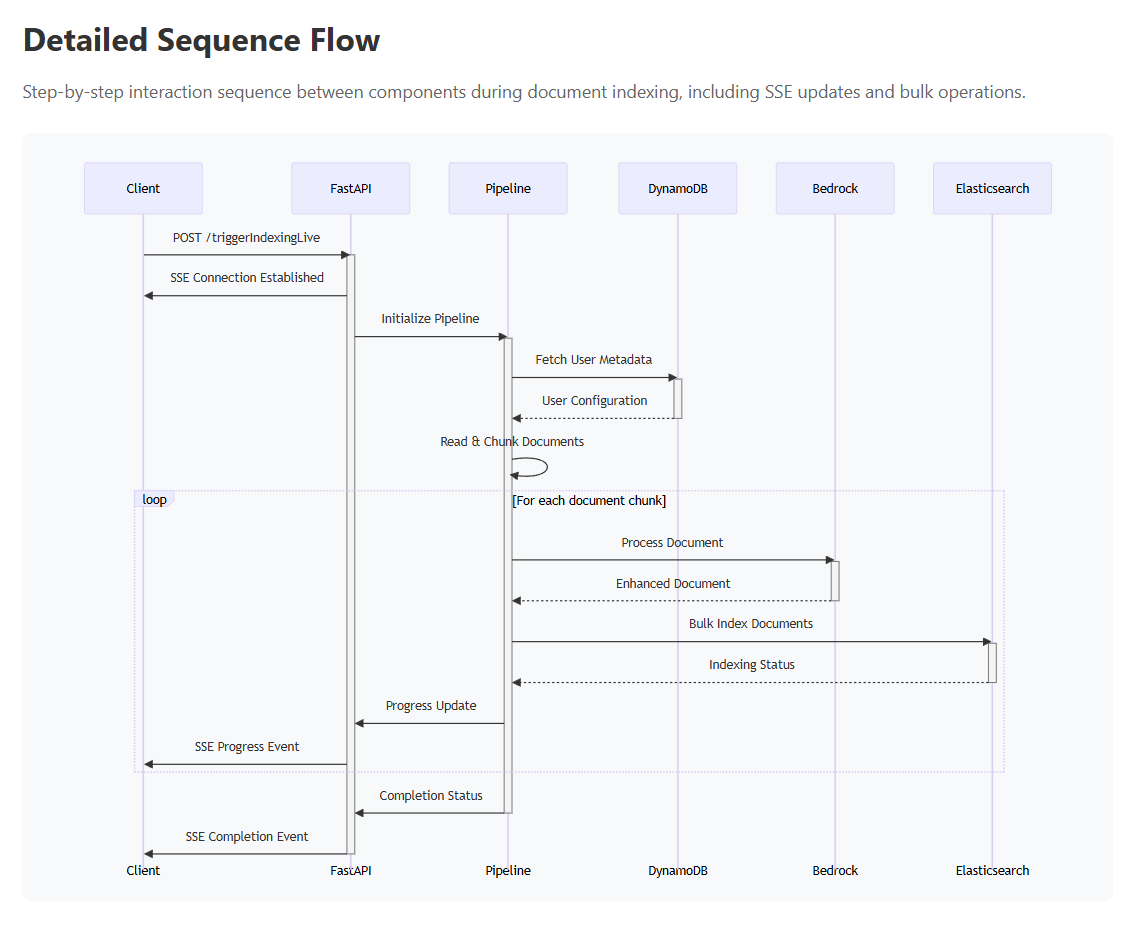
Sequence Flow
-
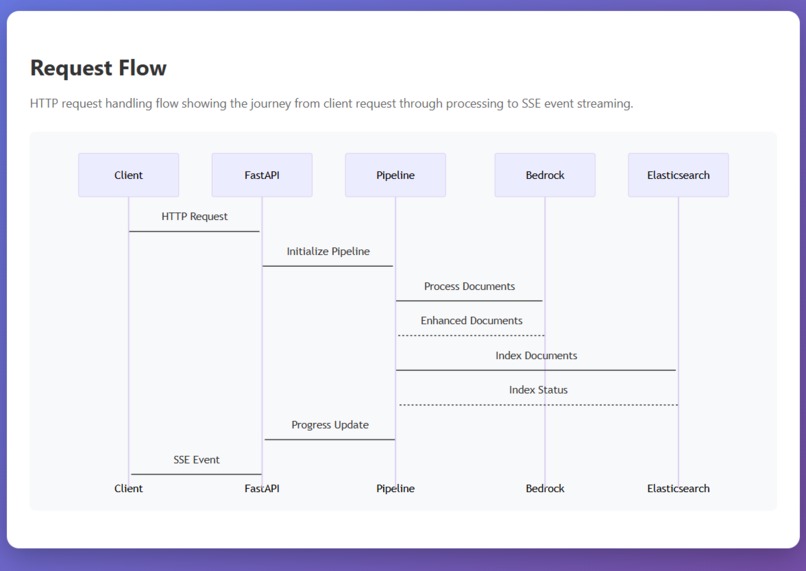
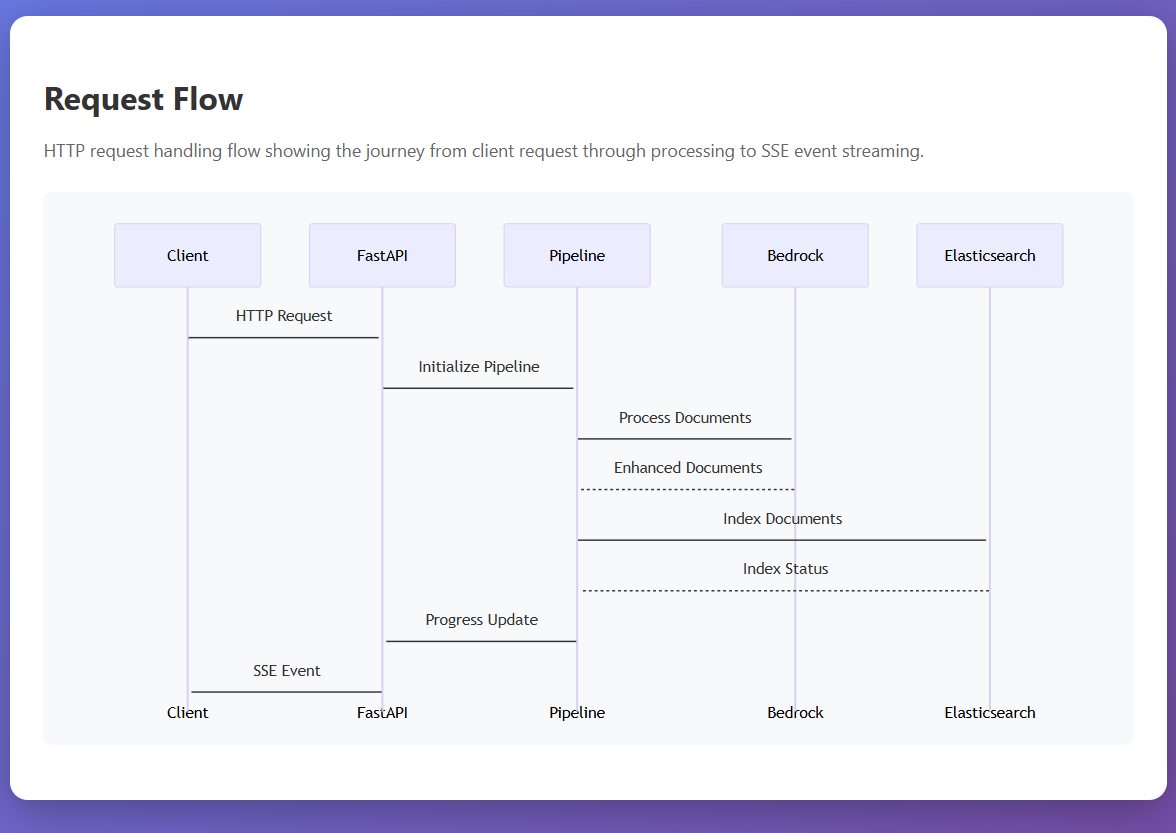
Request Flow
-

High Level Flow Diagram



Inspiration
Simple frustration: A startup lists itself on the internet. Search? They don't know how to implement, they use simple DB, JS, or maybe they were offered solutions by Elastic or even AWS.
BUT! How do they honour queries like "red or orange LED from Syska or better brands under 10 watts" which even big marketplaces fail to solve. And for smaller startups, even simple issues like synonyms, translations, and stemming won't work if they lack expertise.
In the era of AI, do we still need experts to perform a basic search on our website? This solution can even be offered by AWS, fully deployed, with zero-code search. No expertise needed, just any unstructured data, say their products, and their search is ready without assigning experts to them.
Traditional e-commerce search falls flat on complex queries, while modern AI solutions drown in hallucinations or get lost in context windows. We built a search solution for the Elastic hackathon that proved something revolutionary—what if we could combine the precision of Elasticsearch with the intelligence of LLMs, without the black-box problems?
Watching developers struggle to adopt Elasticsearch due to its steep learning curve, and seeing small startups unable to leverage its power, we realised: the future isn't about replacing databases; it's about making databases as intelligent as AI. That's when TensileSearch was born—to make enterprise-grade search accessible to everyone, with zero code required.
You say, Why not just have an LLM here? They will fail with 10K documents, still cost a fortune, and be very slow. Not even going into black-box and data pollution issues with RAG.
What it does
TensileSearch is an intelligent, dual-agent system that transforms any data into a production-ready search engine in minutes:
Index Agent: Takes any structured or unstructured data and intelligently breaks it down. Whether you provide potential search queries, it analyses your data (using the top 100 rows for structure understanding), extracts features and attributes using LLM reasoning, and optimises an Elasticsearch schema. The magic? A "6W red Syska LED bulb" automatically becomes {title: "led bulb", power_watt: 6, brand: "syska", color: "red"} without you defining a single specification. It even normalises values (2KW → 2000 watts) for perfect range filtering.
Search Agent: PowAgent by Elasticsearch MCP (Model Context Protocol) understands natural language queries and translates them into precise Elasticsearch queries. When a user asks for "red or orange LED from Syska or better brands under 10 watts," it intelligently knows: this is an LED bulb (not a TV), 9 watts works (under 10), red or orange (not blue), Syska is preferred but better brands are acceptable.
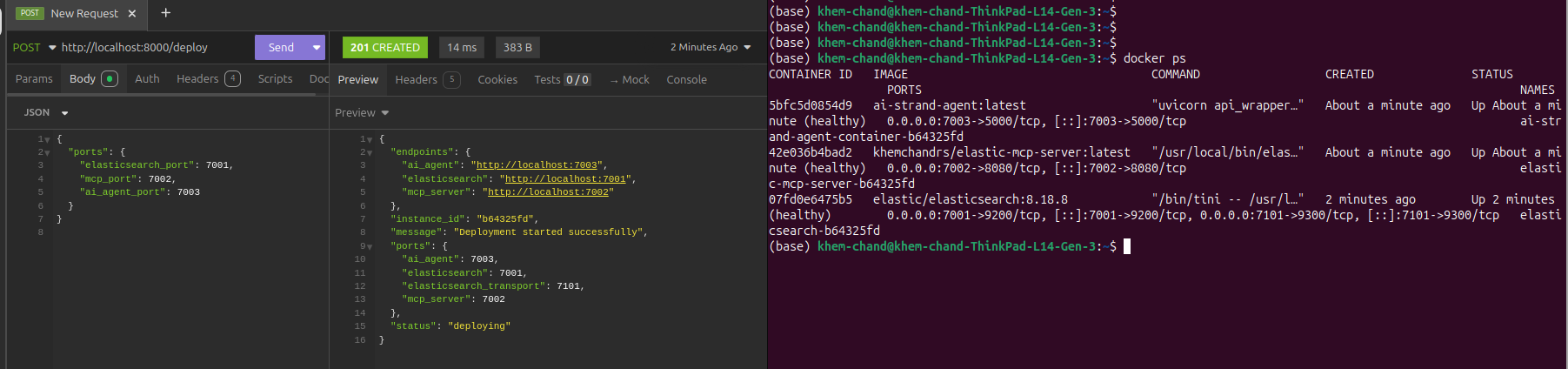
Full-Stack Deployment: For each user, we spin up an isolated Elasticsearch instance via Docker with ES MCP configuration, providing a shareable link to try their custom search immediately.
Key Differentiators:
- No hallucinations: Data is precisely indexed in Elasticsearch, not floating in LLM memory
- No context limits: Index billions of documents, not just what fits in a context window
- Full transparency: Debug exactly what's indexed and how queries are executed—no black boxes
- Blazing fast: Elasticsearch speed for retrieval, LLM intelligence for understanding
- Truly zero-code: Works with ANY data across ANY use-case without writing a single line
How we built it
Architecture:
- Dual-Agent System: Built two specialised agents using AWS Bedrock for LLM reasoning—one for intelligent indexing, one for query understanding
- Elasticsearch Integration: Leveraged Elasticsearch MCP (Model Context Protocol) to give agents direct, controlled access to ES operations while maintaining schema awareness
- Docker Orchestration: Created containerised ES deployments for isolated, per-user search instances with pre-configured MCP settings
- Intelligent Indexing Pipeline:
- Sample analysis (top 100 rows) to understand data structure
- LLM-powered attribute extraction and normalisation
- Dynamic field mapping generation
- Batch processing to optimise context usage and costs
- Query Translation Layer: Built sophisticated prompt engineering to convert natural language into precise Elasticsearch DSL queries with proper filters, ranges, and boosting
- AWS Infrastructure: Deployed on AWS using EC2 for compute, S3 for data storage, and Bedrock for LLM capabilities
Technology Stack:
- AWS Bedrock (Claude) for intelligent reasoning
- Elasticsearch with MCP for data storage and retrieval
- Docker for containerisation and deployment
- Python for agent orchestration
- REST APIs for integration endpoints
Challenges we ran into
The Context Window Trap: Early iterations tried to pass entire datasets to the LLM for indexing. We hit context limits immediately with even moderate datasets. Solution: Intelligent batching and schema inference from samples, processing rows in groups while maintaining consistency.Consistency Nightmare**: Getting the LLM to consistently normalise attributes (2KW vs 2000W vs 2 kilowatts) was more intricate than expected. We built a multi-pass system: first extract, then normalise with validation rules, ensuring "6W" and "6 watts" both become power_watt: 6.
MCP Learning Curve: Elasticsearch MCP was new territory. Understanding how to structure prompts so the agent uses MAgentfectively—knowing when to query, what filters to apply, how to interpret results—required extensive experimentation and prompt engineering.
Schema Consistency: Consistency creates schemas that the Search Agent can intelligently interpret, which also enhances its performance. We implemented a schema documentation step where indexing metadata is stored and made available to the search agent.
Resource Management: Spinning up individual ES instances per user while managing costs and performance required careful Docker resource limits and cleanup automation.
Query Ambiguity: Handling vague queries like "good brands" or "better than X" required building a knowledge layer where the LLM could make reasonable brand comparisons based on common knowledge while staying grounded in actual indexed data.
Accomplishments that we're proud of
Zero to Search in Minutes: We actually achieved true zero-code deployment. Any developer can throw CSV, JSON, or unstructured data at TensileSearch and get a production-ready search API without understanding Elasticsearch at all.
Solving the E-commerce Problem: Our LED bulb example isn't hypothetical—we built this because existing solutions can't handle it. TensileSearch nails complex, multi-attribute queries that stump traditional search engines.
No Hallucinations: Unlike pure RAG or LLM solutions, we eliminated hallucinations entirely for search. The LLM understands intent, but Elasticsearch returns facts.
Elastic Hackathon Success: Our initial submission proved the concept worked. Now with AWS Global Hackathon, we've evolved it into a full-stack, deployable solution.
Generalisation: We proved this works beyond product search—documents, logs, customer data, content libraries—any dataset can be intelligently indexed and searched.
Making Elasticsearch Accessible: We've removed the expertise barrier. Small startups and individual developers can now leverage enterprise-grade search without months of learning.
What we learned
LLMs as Orchestrators, Not Databases: The revelation that LLMs should understand and translate, while letting specialised systems (like Elasticsearch) handle storage and retrieval. This hybrid approach gives us the best of both worlds.
MCP is Revolutionary: Model Context Protocol opens up possibilities we hadn't imagined. Giving LLMs structured access to tools while maintaining control is the future of agentic systems.
Sampling is Sufficient: You don't need to analyse entire datasets to understand structure. Smart sampling (top 100 rows with diversity checks) provides enough signal for accurate schema generation.
Schema Awareness is Critical: The Index Agent documenting what it created and the Search Agent having access to that documentation was the key to making queries work reliably.
Docker + MCP + Bedrock: This stack is incredibly powerful for building isolated, intelligent search systems quickly.
Normalisation is Hard: Attribute extraction is one thing, but consistent normalisation across units, formats, and representations is a deep problem that requires careful, prompt engineering and validation.
What's next for TensileSearch - Zero Code Search Deployment
Multi-Modal Search: Extending beyond text to handle images, videos, and audio. Imagine searching products by uploading a photo: "find me this lamp but in blue and cheaper."
Collaborative Filtering: Integrating user behaviour and preferences to personalise search results while maintaining the precision of our current approach.
Auto-Scaling Infrastructure: Moving from per-user Docker containers to a shared, multi-tenant Elasticsearch cluster with intelligent index isolation and auto-scaling on AWS.
Search Analytics Dashboard: Building insights into what users search for, what works, and what doesn't—helpingbusinesses optimise their cataloguess and search experience.
API Marketplace: Creating pre-configured search solutions for common use-cases (e-commerce, documentation, logs, customer support) that can be deployed with one click.
Fine-Tuned Models: Training domain-specific models on top of Bedrock for even better attribute extraction in specialised industries (automotive, real estate, healthcare).
Real-Time Indexing: Supporting streaming data sources with continuous indexing pipelines for up-to-the-second search freshness.
Open Source Core: Making the core indexing and search agent framework open source to build a community around intelligent search, while offering managed hosting on AWS as our business model.
Enterprise Features: RBAC, audit logs, compliance certifications, SLAs—everything needed for enterprises to adopt TensileSearch at scale.
The Vision: Make searching data as natural as asking a question, as precise as writing SQL, and as accessible as deploying a website. TensileSearch is here to prove that AI doesn't replace databases—it makes them magical.
Built With
- agentcore
- amazon-web-services
- bedrock
- claude
- cloudsearch
- descope
- dynamodb
- ec2
- elasticsearch
- genai
- javascript
- n8n
- opensearch
- python
- server
- strands
- vercel


Log in or sign up for Devpost to join the conversation.