-
-

top view
-

top view
-
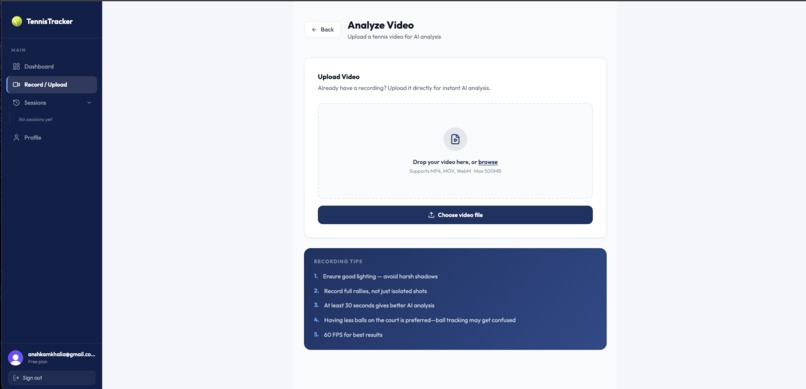
record video
-

top view
-

court level
-

court level
-

court level
-
authentication
-
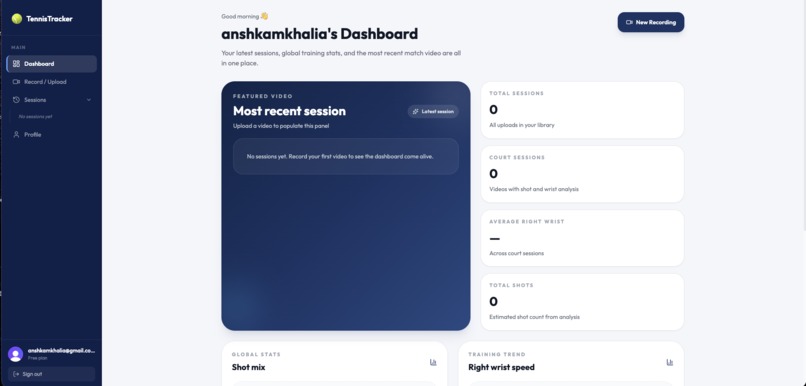
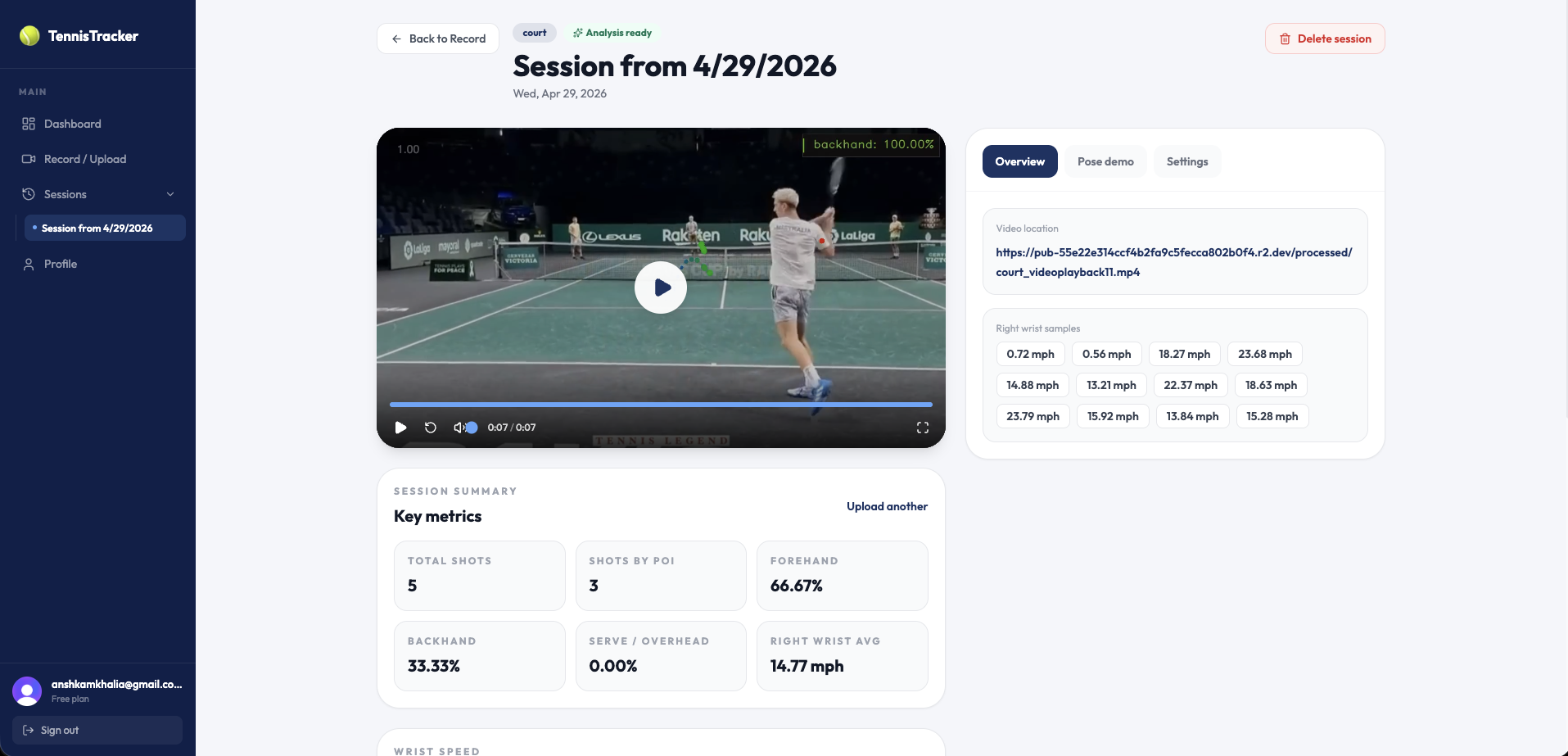
dashboard
-
landing page
-
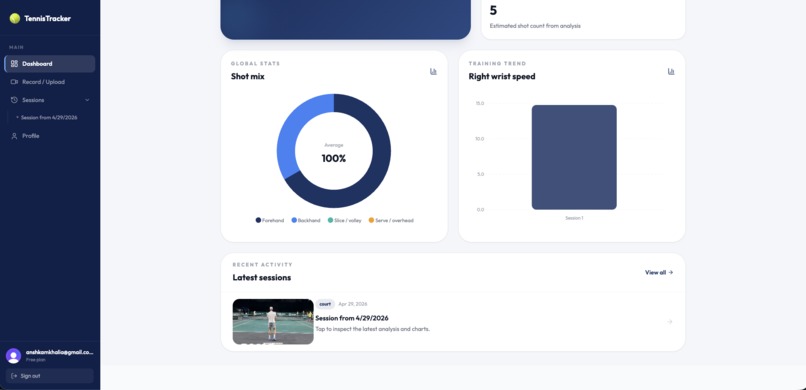
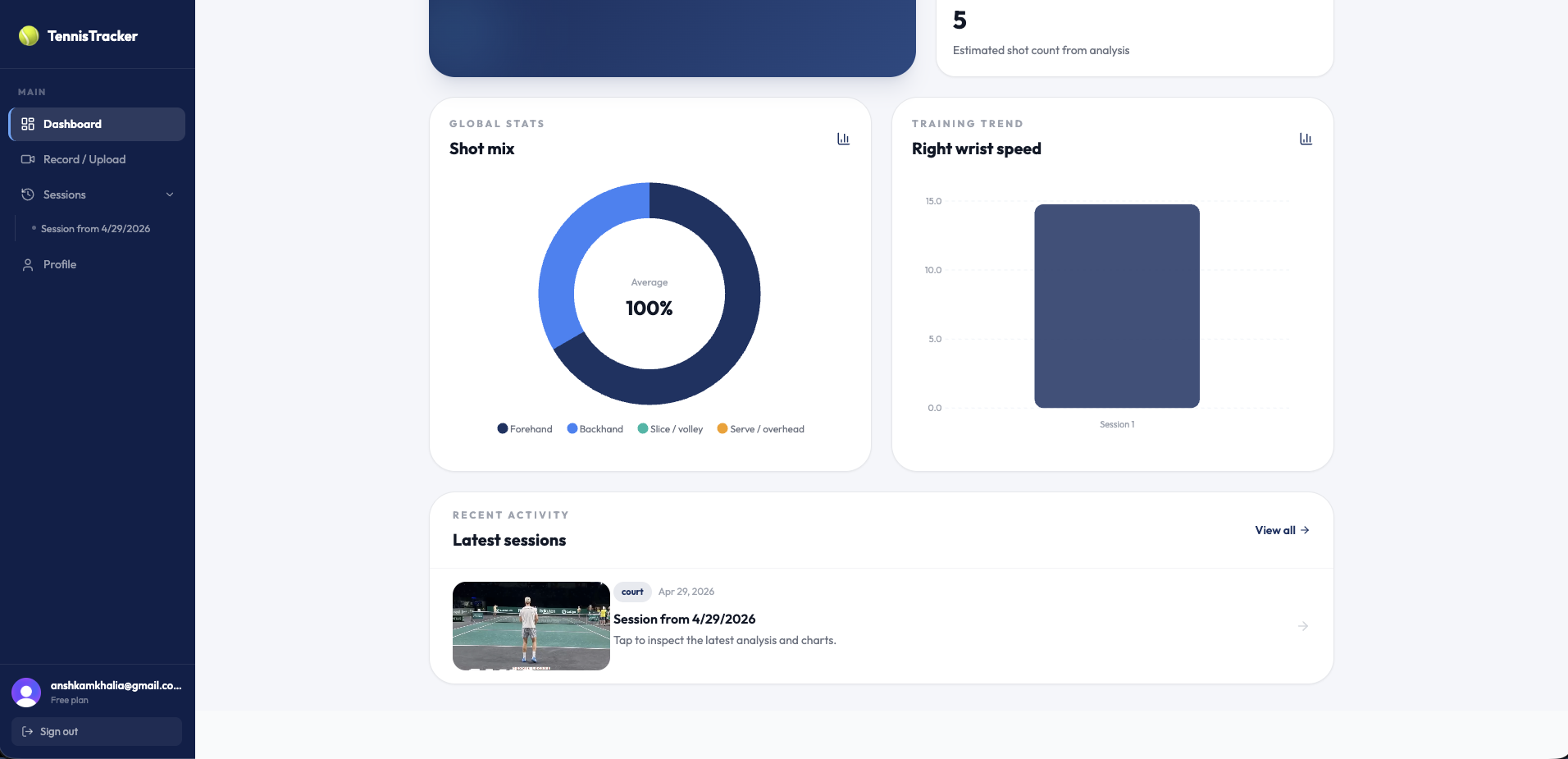
bottom part of dashboard
-
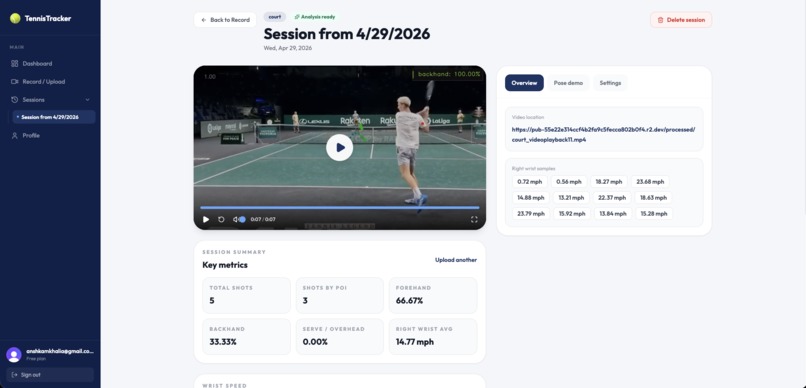
analysis complete
-
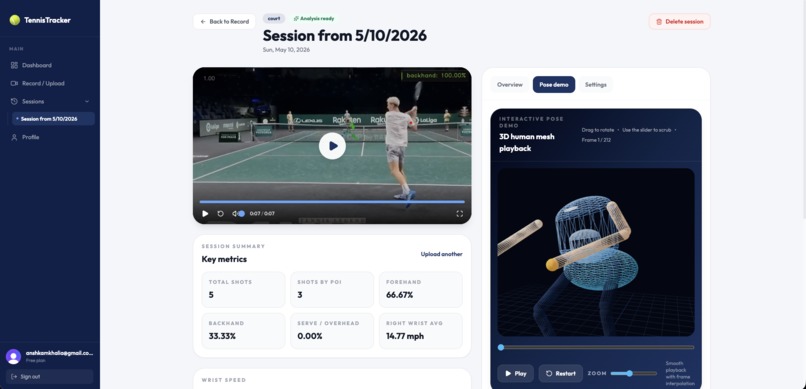
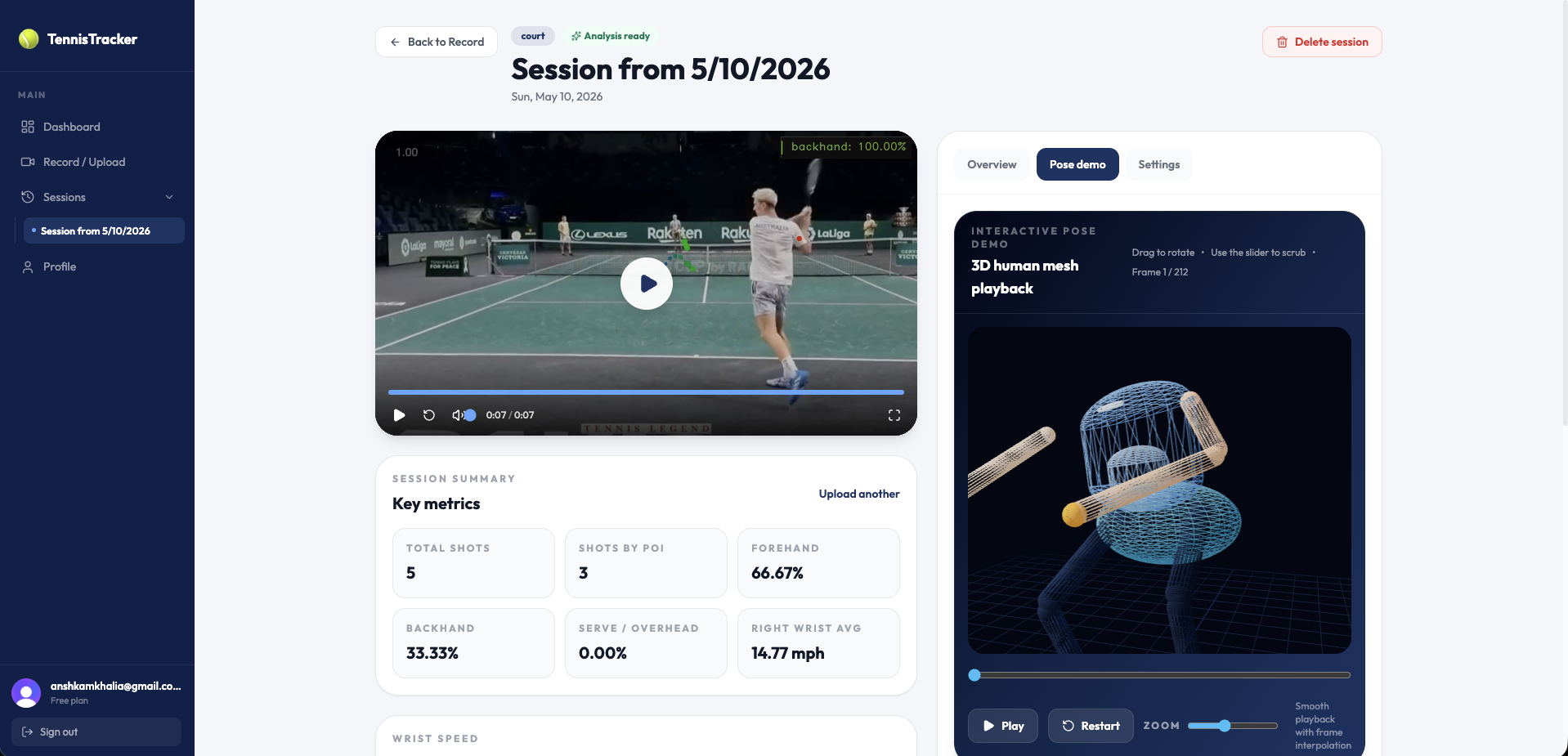
3d wireframe
-
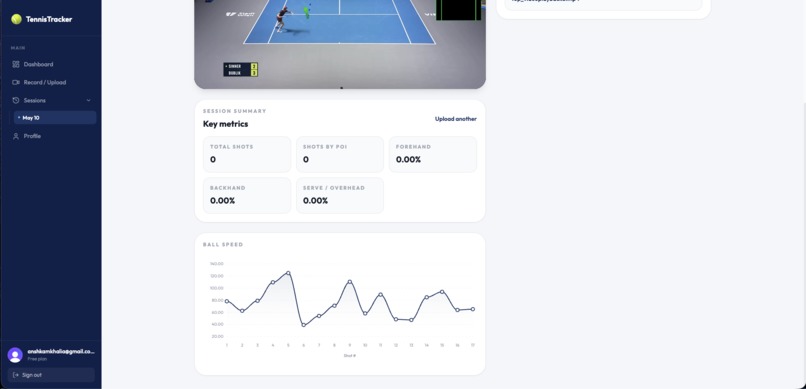
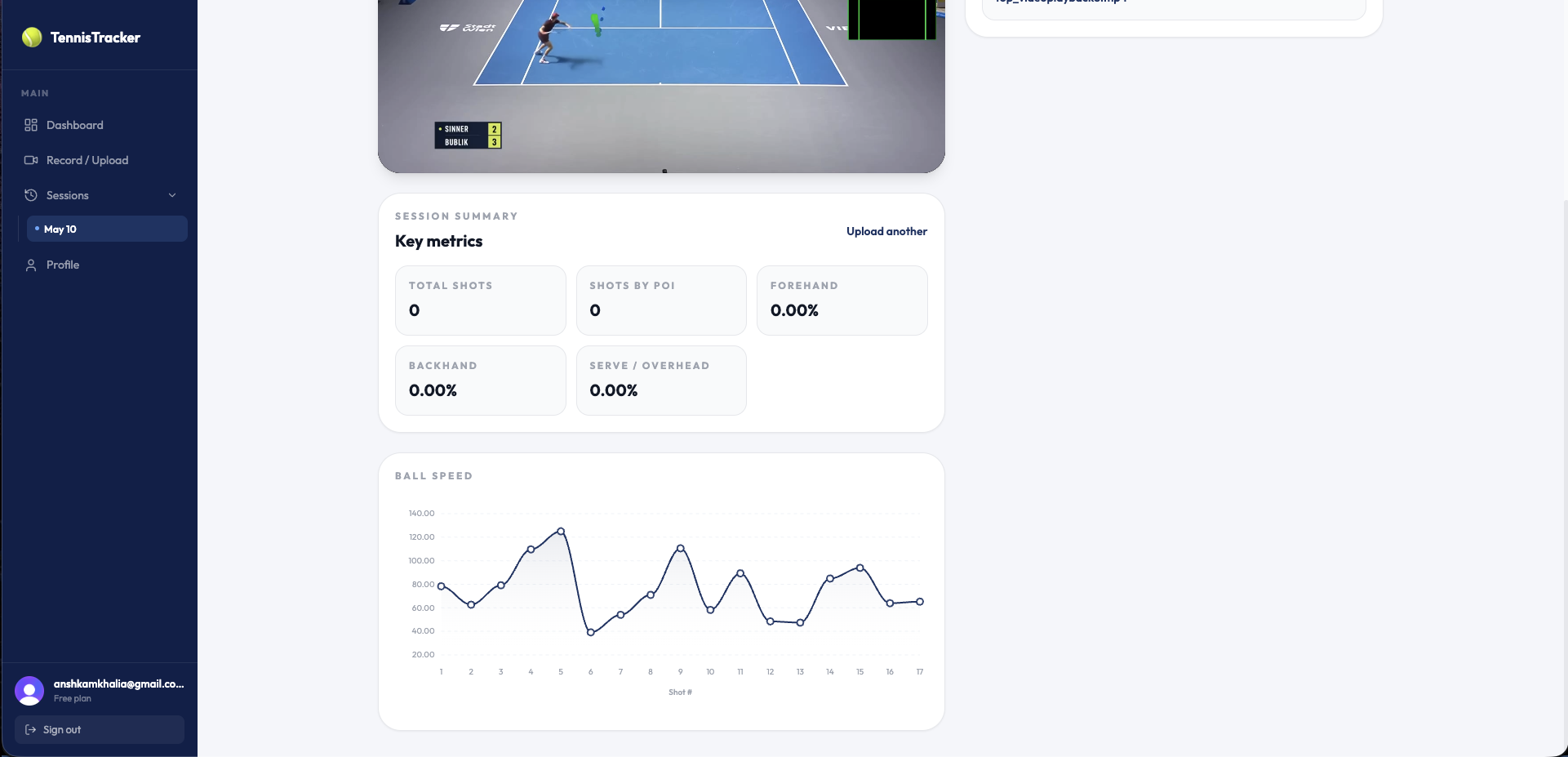
ball speed graphs
-
sessions




Built by Ansh Kamkhalia (backend) and Neil Bajaj (frontend)
Stack
- Used TensorFlow for modeling creation, training, and lazy data loading for resource reduction
- Used MediaPipe for pose estimation to create tensors to feed into shot classifier models
- Used YOLO for human detection, court detection after fine tuning, and ball tracking after fine tuning
- Used Numpy for implementation complex mathematical formulas and loss functions
- Used FastAPI for fast and effective endpoints
- Used OpenCV for homography estimation and video data management
- Used Boto3 (Cloudflare) to save processed videos into the cloud for long-term saving
Inspiration
I play tennis, a lot, and it's a pretty core part of my life. Recently, I tried SwingVision, which was a tennis analytics app, and it was good. It is important to take into consideration that it's very expensive and restrictive. It is also only for iOS, meaning that the majority of Android users do not have access, and no other app exists like it. And thus we decided to take matters into our own hands by building a cross-platform, budget friendly version, complete with a lot of its core features.
How we built it + challenges we faced (frontend):
Stack:
On the Frontend: • ReactJS • Tailwind CSS (for styling) • ApexCharts.js (for graphs) • Supabase (for authentication and database)
We built the frontend using ReactJS, which helped us with routing and communicating with the Python-based backend. The UI is styled with Tailwind CSS and was designed around making it as easy as possible to both (a) access the app behind the landing page, and (b) easily upload and save their tennis recording statistics. We additionally used Supabase to authenticate users and as a database to save their videos and statistics. These statistics are shown in interactive graphs made with ApexCharts.js.
Design-wise, the user interface was generally simple to make. However, we faced issues sending response data from our backend to the database, and then having that data sent to the user when they open a video. Although Supabase made it easier, my unfamiliarity with SQL made it slightly more challenging. After the client received the data, some of it wasn’t loading correctly on the result page (shown after the video finishes processing). Additionally, many of the values were displayed in graphs, which we didn’t want to look unpolished, tweaking these took some extra time.
How we built it + challenges we faced (backend)
Views:
The pipeline is split into two different paths. This being court-level videos as well as top-level videos. Most projects that are similar to this only support top-level videos as it provides more spatial information. I took into account that most people don't have access to such a high camera angle, and focused most of the features into working with court-level videos. I attempted to train a YOLOv11 model to detect courts, but I realized that it turned into a natural filter that could identify whether a video was shot at a high or low view. If the model detects a court, it's a top angle, but if it doesn't its a court angle.
I'll give an explanation of each feature and how it works:
Shot classification:
I recorded a few hundred videos of me doing various shots in my basement. I created a dataset using these videos by utilizing YOLO to crop out the player, then using mediapipe to extract pose keypoints, and then feeding that into the model with it outputting either forehand, backhand, slice/volley, or serve/overhead. Each stroke is represented as a temporal tensor in ℝ^(T × 33 × 3), where T is the number of frames, 33 is the number of pose landmarks, and each landmark contains (x, y, z) coordinates. This allows the model to learn motion dynamics rather than static poses. Instead of averaging frames uniformly, I used an attention-based temporal model to learn which moments in a stroke contribute most to classification. This improves robustness against noisy keypoints and partial occlusions. This can easily generalize due to the fact that the main features of these groundstrokes are different from stroke to stroke, but similar from person to person. This also solves the issue of mediapipe producing incorrect keypoints as a result of an obscured/tiny player, especially in high pixel resolutions. I originally attempted to find online datasets, but was met with poor quality and no luck. To train both models, I utilized the ADAM optimizer as well as SCCE (sparse categorical cross entropy) loss to ensure that the model isn't just right, it's confident. These hyperparams paired with shuffling, batching, and L2 (ridge) regularization, the model has exceptional performance.
Stroke representation
Ball tracking:
I originally attempted to use a TrackNet architecture, but I ran into issues with empty heatmaps and OOM errors due to sheer data size and model complexity. Instead, I went online and found a fine-tuned YOLO model from HuggingFace which I upgraded using a Savitzky-Golay filter and a gradient trail to smoothen it out. The Savitzky–Golay filter fits a low-degree polynomial over a sliding window via least-squares regression, reducing high-frequency noise while preserving trajectory curvature. This was critical for maintaining realistic ball motion without phase distortion. Raw detection outputs produce volatile jitter due to bounding box variance. By minimizing local regression error over time, trajectory stability improved significantly. This was definitely one of the most important parts, as it opens up a whole array of new features.
Savitzky-Golay filter
- Court detection: I first attempted to use the hough transform along with a canny edge detector to be able to detect the major court lines, but it was extremely crude and was not generalizable. Instead, I fine-tuned a YOLO model using images of tennis courts, getting very promising results. However, there was an issue here, and that being that YOLO can only output rectangles, not trapezoids, as often seen in tennis matchplay. Because YOLO outputs axis-aligned bounding boxes, I derived a geometric scaling factor based on height-to-width ratios to approximate projective compression of the far baseline. This allowed approximate correction of perspective distortion without requiring full homography estimation.
Homography
2D Court modeling:
True homography requires accurate planar correspondence, but monocular depth ambiguity introduced instability in real-world footage. Instead, I constructed a normalized coordinate mapping from detected court vertices into a fixed minimap coordinate system. Using the positions of the ball and having all 4 court vertices, I created a "minimap" of the court with the ball traveling in it. I first attempted to use homography and manual court labeling, but it caused a huge array of problems due to the underlying issue of depth perception. After coming to a stark realization, I decided I would attempt homography one more time, as I now have dynamically found court coordinates, and my ball tracking was much smoother. This ended up working quite well in my favor, as perspective warps caused by using plain ratios were almost nonexistent. This drastically increased the accuracy of the ball position on the minimap.
Projection transformation
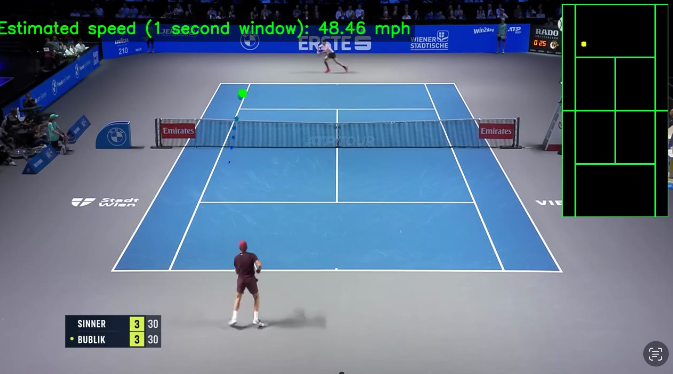
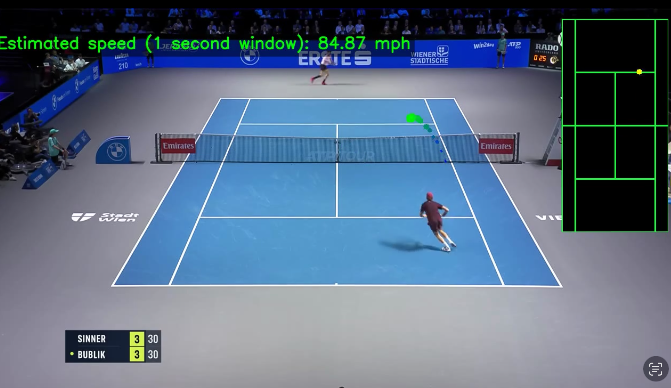
Ball speed estimation:
The biggest problem with estimating ball speed is the fact that the computer sees 2D motion, not 3D. To approach this problem, I first found the pixels-to-meters using the length of the baseline in pixels and the actual dimensions. I then kept a 60 frame buffer and evaluated velocity on it, cleared the buffer, and repeated the process. This actually worked extremely well compared to my earlier approaches of just using V = final - initial / time.
Pixel to meter conversion
Velocity approximation
Contact detection:
Contact detection is one of the crucial aspects of tennis, but also one of the most difficult. Before my current solution, I had experimented with using ML models, then switching to velocity spikes, and then trying direction changes. Absolutely none of these worked. Instead, I tried a more unorthodox method: audio spikes. In most environments, the ball making contact with the racket produces a loud sound. By taking the RMS energy of a specific audio sample matched with the frame, we can add a threshold and detect loud spikes. This turned out to be extremely effective, and only missed a few shots out of 25-30.
Wrist velocity:
The wrist is a key body part in tennis. It controls almost everything about the shot, and insights into how fast one's wrist is moving can be extremely useful. By using our previously computer pose coordinates, we can store our location of the right wrist over many frames. This introduces a small problem though, if we just look at wrist positions in respect to the entire frame and attempt to use velocity formulas, we'll get insanely high numbers due to the actual player moving around. We need it in respect to the player. Instead, we localize the player before computing the pose in that cropped section. This ensures that no matter how much the player moves, our wrist positions will be with respect to the player, not the entire frame. From then, we perform velocity calculations and store them to be returned to the frontend.
Pose visualization:
By recycling our pose coordinates again, we can utilize the z-axis of mediapipe's BlazePose and create a 3D wireframe interactive model.
What's next
I have been working on 3D reconstruction, but it has proved to be extremely difficult, as only a few research papers have successfully pulled it off, that too, with powerful hardware and teams of PhDs. Monocular 3D reconstruction is fundamentally ill-posed due to depth ambiguity: a 2D trajectory corresponds to infinitely many 3D trajectories without additional constraints. Solving this reliably requires multi-camera systems, stereo vision, or learned depth priors.
What we learned
I learned a great deal about how CV systems work in production. They need to be able to handle bad lighting, weird camera angles, and a variety of different test cases. I learned about the necessity of speed over pure performance, as well as the security checks needed, especially when working with providers like Cloudflare which are notorious for high bills if limits are exceeded.
How it could be developed
Due to the fact that the backend is complete (uses FastAPI), all thats left to do would be a create a visually appealing UI. The larger problem at hand is the issue of servers. Most basic webapps don't require extensive processing, but my pipeline runs multiple YOLO instances, mediapipe nets, and neural networks, while also processing 720p footage at 60fps. Most free-tier website hosters have extremely limited RAM, and an even slower CPU, bottlenecking performance, and decreasing UX quality. There are alternatives that can easily handle this, but it would require a lot of money.
Targeted users
Anyone could use TennisTracker, from complete beginners to seasoned professionals.


Log in or sign up for Devpost to join the conversation.