-
-

-

Tenet Start New Chat
-
Tenet Conversation
-
Tenet Branching
-
Tenet Branching
-
Tenet Merging & Conflicts


Tenet
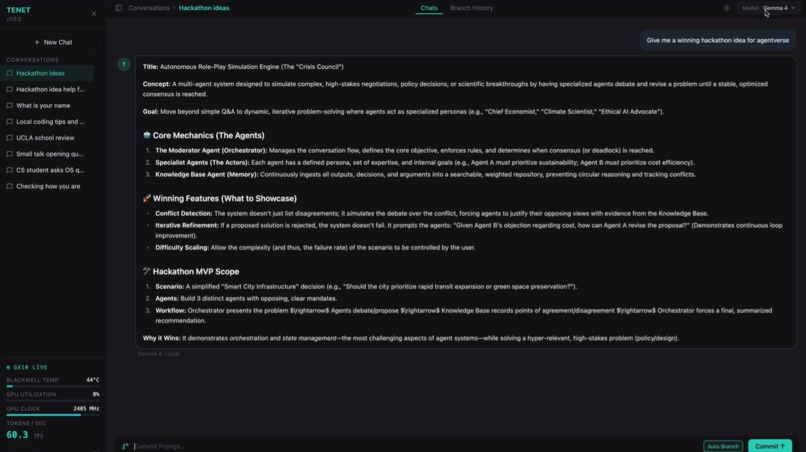
Tenet is a non-linear AI conversation platform built to solve a painful reality: one bad prompt can contaminate an entire chat. Instead of forcing users into a single fragile thread, Tenet models every conversation as a Directed Acyclic Graph (DAG), so users can safely explore ideas, isolate risky directions, preserve high-value context, and recover instantly when a branch goes off-track. With auto-branching, mergeable reasoning paths, real-time D3 graph visualization, and live inference telemetry running on the ASUS Ascent GX10 AI Supercomputer, Tenet turns AI interaction from disposable chats into a durable, high-trust workflow.
One bad prompt should not erase your best thinking.
Inspiration
We wanted to reimagine how people interact with AI. Currently, conversations with AI are linear — once you go down a path, pivoting means starting over. We asked: what if conversations worked like Git? What if you could branch, merge, and explore alternative reasoning paths? Tenet is the answer.
The deeper problem is contamination: once a response introduces noise or hallucination, the context window carries that error forward. Users spend time fighting conversation state instead of making progress. We designed Tenet so recovery is built in, not an afterthought.
What it does
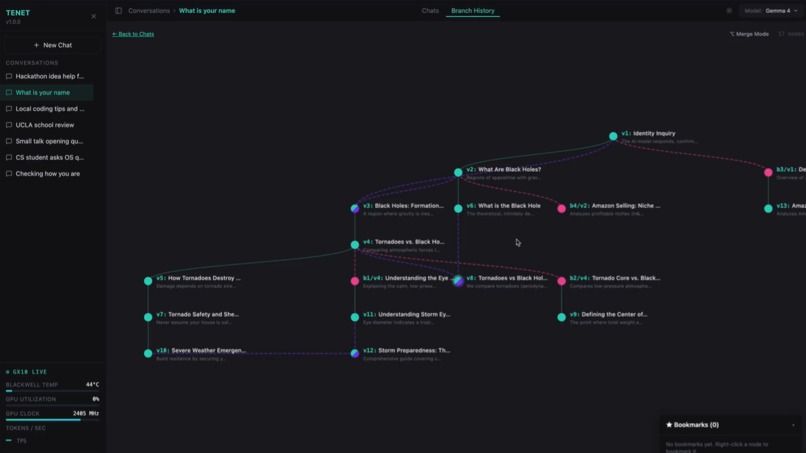
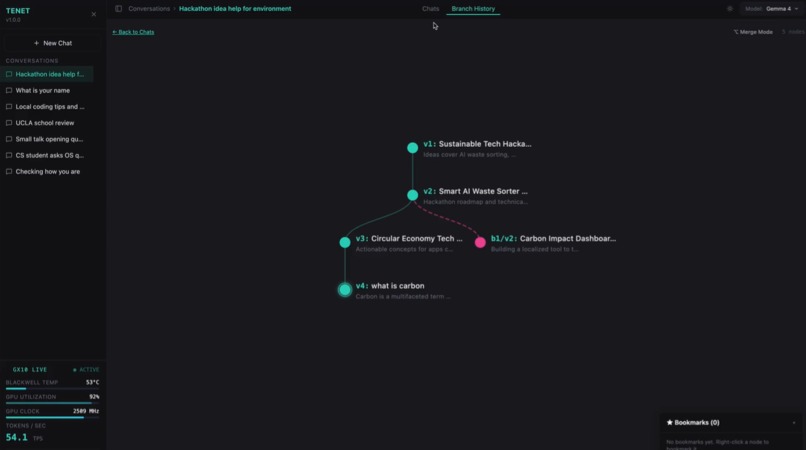
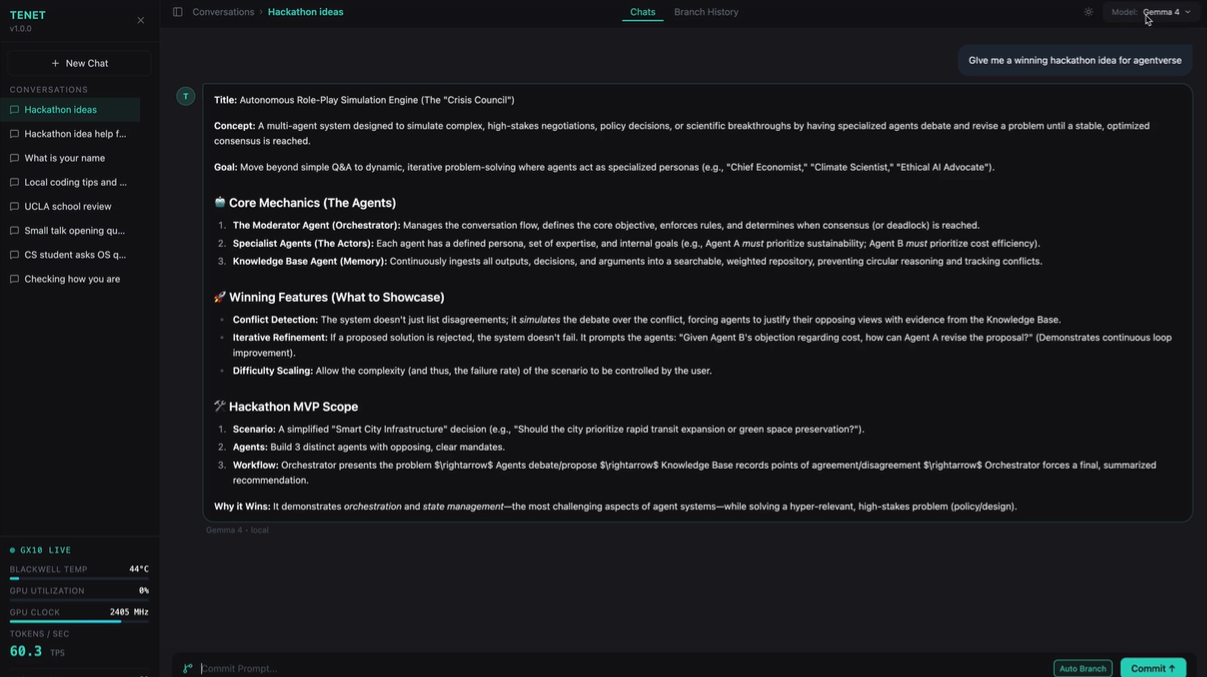
Tenet is a graph-native conversation system. It models conversations as a Directed Acyclic Graph (DAG) where each message is a node. Users can:
- Branch conversations to explore alternative prompts from any point
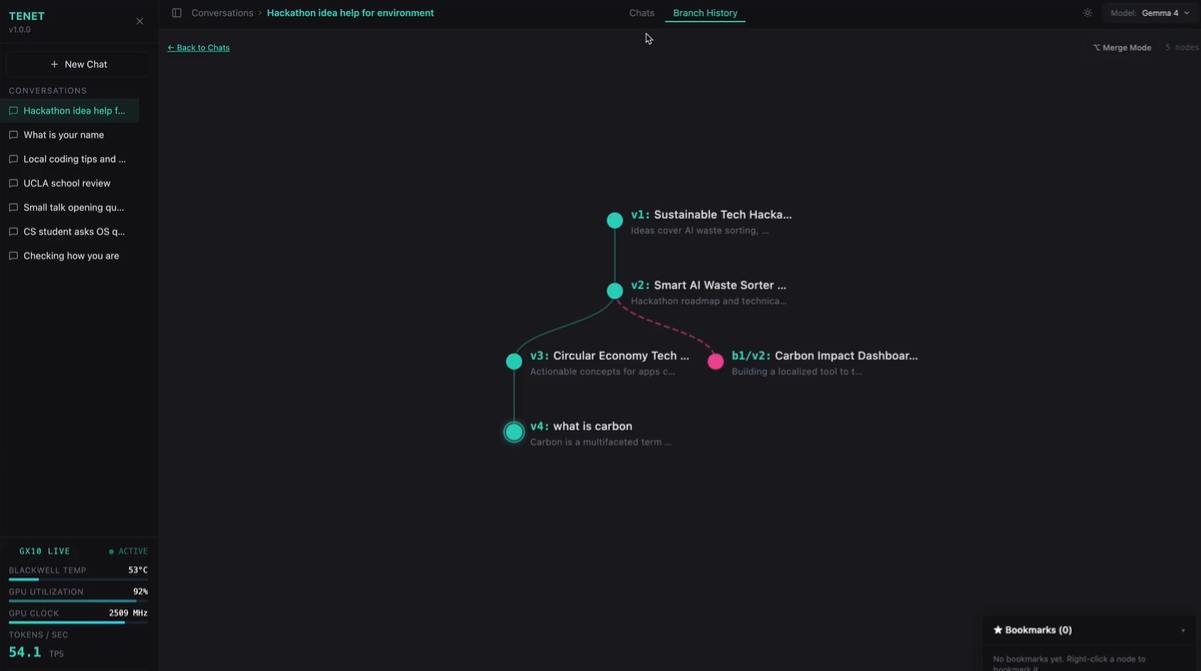
- Auto-branch new reasoning paths using a token-overlap heuristic that routes prompts to the most semantically relevant parent node — no LLM call required, no latency added
- Checkout past nodes to restore conversation context instantly
- Prune branches to remove dead ends, cascading to all descendants
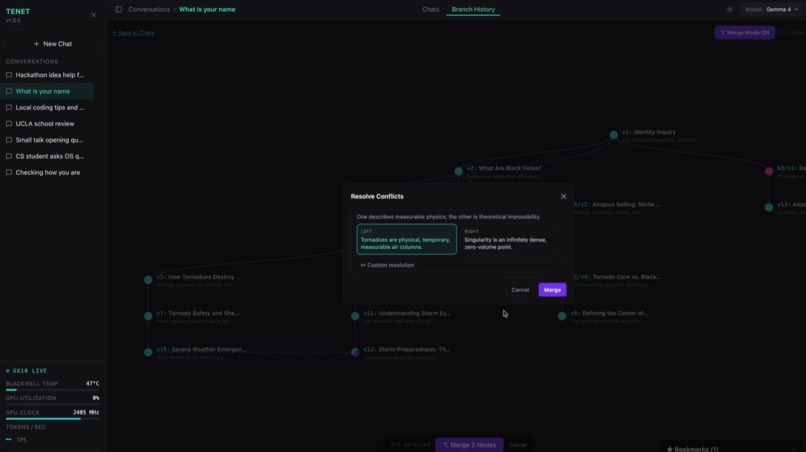
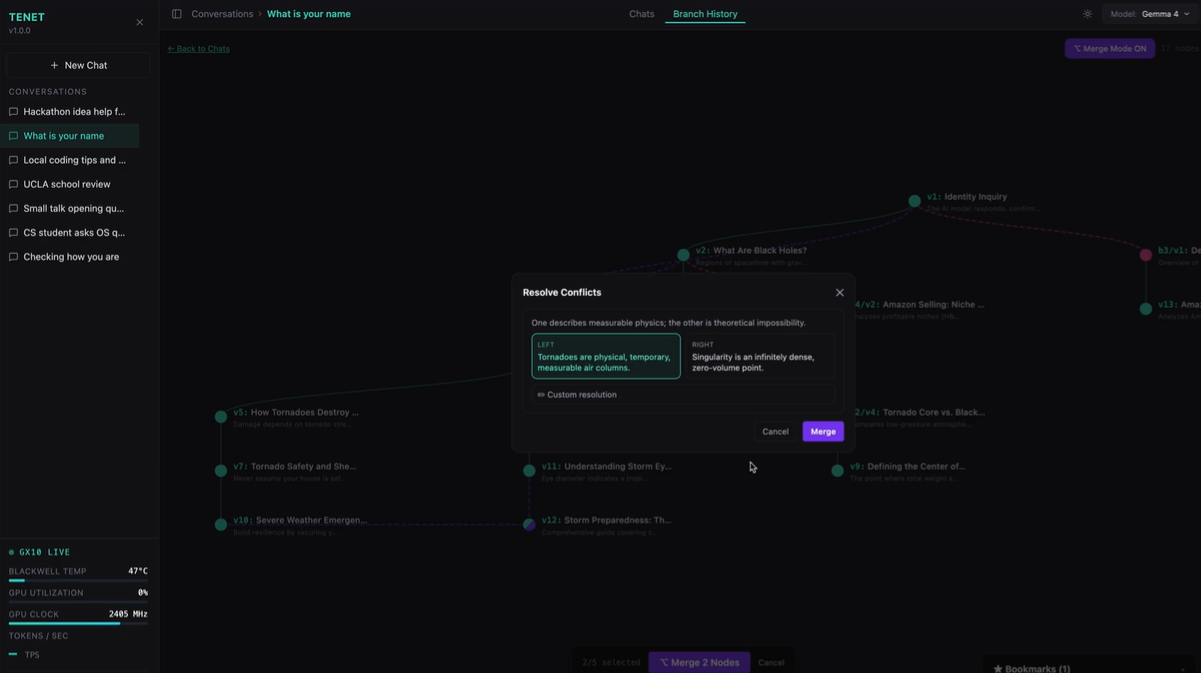
- Merge up to 5 nodes to synthesize insights across different reasoning paths
- Detect merge conflicts between contradictory branch conclusions and prompt users to resolve them before finalizing
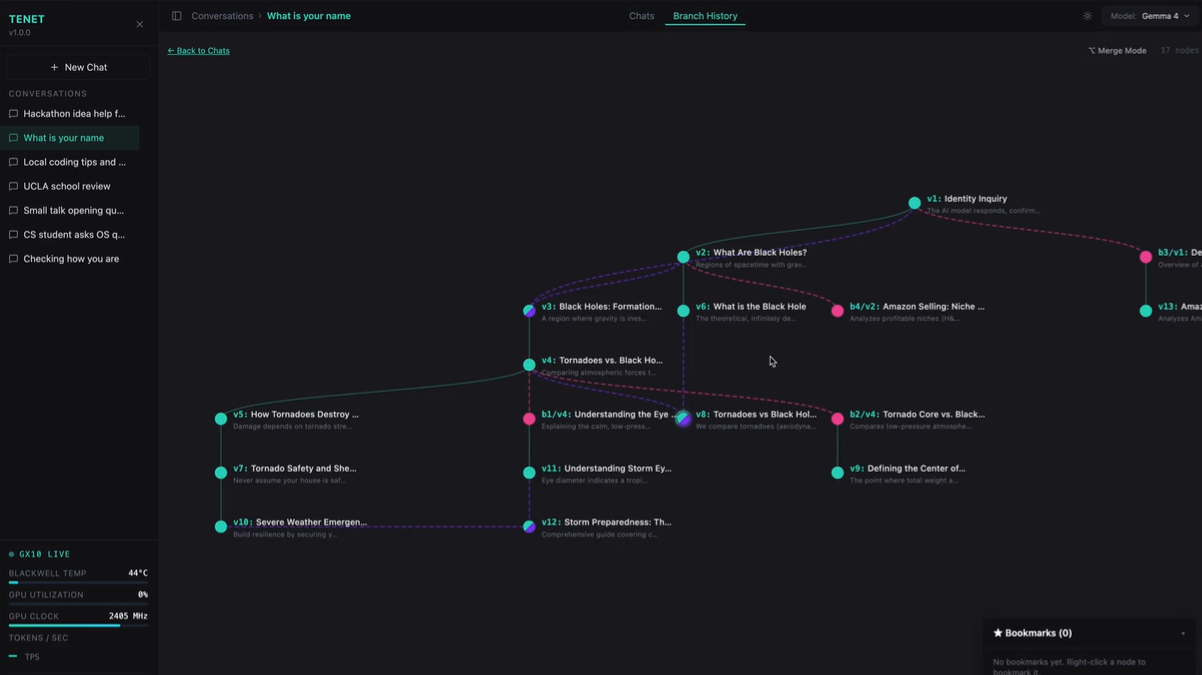
- Visualize the full conversation tree in real-time with a D3 force-directed graph that updates reactively as branches are created
- Monitor inference in real-time with live telemetry on the ASUS Ascent GX10 AI Supercomputer — GPU utilization, VRAM, tokens/sec, temperature, and currently loaded Ollama models
- Choose across 6+ LLMs running on ASUS infrastructure, routing tasks to the best-fit model
- Export conversations to JSON, Markdown, CSV, or HTML directly from the graph view
How we built it
Frontend: React + TypeScript + Vite + Zustand
- DAG state management with Zustand, reconstructing
children_idsand branch labels client-side from flat MongoDB node lists - D3-based tree visualization for branch history with merge edge rendering for multi-parent nodes
- Real-time telemetry widget polling
/agent-telemetry— GPU stats from pynvml merged with Ollama's/api/psmodel list, cached server-side to avoid per-poll overhead - Responsive UI with Tailwind CSS
Backend: FastAPI + MongoDB + Fetch.ai uAgents
- Server-Sent Events (SSE) streaming for token-by-token feedback via Ollama's
/api/chat - Endpoints for chat, branching, auto-branching, merging (2–5 nodes), conflict detection, pruning, restore, reparent, and export
- Token-overlap auto-branch selector that scores all candidate nodes by prompt/response content match and recency — runs in-process with no Ollama dependency
- Node summary generation with
summary_failedbackoff to avoid hammering Ollama during active inference - Persistent conversation graph storage with MongoDB
Infrastructure: ASUS Ascent GX10 AI Supercomputer
- Native inference on Blackwell GPUs with real-time performance monitoring via pynvml
- 6+ available LLM choices (DeepSeek, Gemma, Ministral, Qwen, and others)
- Live hardware telemetry: temperature, utilization, VRAM used/total, clock speed, tokens/sec
Agent Layer: Fetch.ai Agentverse
- 4 Fetch.ai uAgents fully connected to live MongoDB data via a
WebappDagStoreREST proxy: graph integrity validator, resource monitor, branch summarizer, and conversation exporter - Each agent reads and writes through the webapp's REST API, ensuring they operate on the same live data the frontend sees — not an isolated in-memory store
- Graph integrity agent validates the DAG for cycles, orphan nodes, and parent-child mismatches on demand
- Resource monitor merges pynvml GPU telemetry with Ollama's loaded model state into a unified hardware snapshot
- Branch summarizer delegates to the webapp's summary endpoint so results are persisted to MongoDB and shared across sessions
- Conversation exporter produces JSON, Markdown, CSV, and HTML from live node data
Accomplishments that we're proud of
- Full-stack implementation of a DAG-based conversation system with N-way merge semantics (up to 5 nodes)
- Auto-branching that works entirely on token-overlap scoring — no LLM call, no timeout risk, runs before the chat stream starts
- AI-assisted conflict detection during merges, prompting users to resolve contradictory ideas before they propagate
- 4 Fetch.ai Agentverse agents wired to live MongoDB data via a REST-proxy DAG store — agents and frontend share the same ground truth
- Streaming chat with real-time token feedback via SSE on ASUS Ascent GX10 infrastructure
- D3 tree visualization that correctly renders multi-parent merge nodes with purple convergence edges from all source nodes
- Multi-model support with 6+ LLM choices with intelligent routing
- Live hardware telemetry widget showing GPU temperature, utilization, VRAM, clock speed, tokens/sec, and currently loaded models — with server-side caching to keep Ollama polling efficient
- MongoDB-backed persistent conversation graph with
summary_failedbackoff for graceful degradation under inference load - Export pipeline supporting JSON, Markdown, CSV, and HTML
Challenges we ran into
- DAG complexity: Modeling multi-parent nodes (merges) and efficiently reconstructing
children_idsand branch labels client-side from a flat node list - Real-time streaming: Implementing SSE to stream tokens from Ollama without buffering, while correctly parsing
node_savedevents to sync frontend state with backend node IDs - State synchronization: Keeping the Zustand store in sync with backend DAG mutations, especially for merge nodes with multiple parents
- Agent/webapp data isolation: The Fetch.ai agents originally used an in-memory
LocalDagStorecompletely disconnected from MongoDB. We built aWebappDagStoreREST proxy so the connected agents operate on live data - Telemetry efficiency: Avoiding per-request Ollama
/api/pscalls by adding a 10-second server-side TTL cache - Auto-branch reliability: The original LLM-based selector timed out whenever Ollama was busy with inference. Replaced with a pure heuristic that scores nodes by token overlap — faster, deterministic, and never blocks the chat stream
- Summary generation under load: Node summaries timed out when Ollama was mid-inference. Added
summary_failedflag with per-session retry logic and reduced timeout from 30s to 12s
What we learned
- DAG data structures require careful handling of ancestry and multi-parent relationships — especially when the frontend reconstructs graph topology from a flat list
- Server-Sent Events are elegant for streaming but require careful
node_savedevent parsing to keep frontend node IDs in sync with MongoDB - Multi-agent systems need a shared data layer — isolated in-memory stores per agent make the system look connected but behave disconnected
- Token-overlap heuristics can outperform LLM-based routing when the LLM is already under load — reliability beats marginal accuracy gains
- Graceful degradation matters:
summary_failedbackoff, cached telemetry, and heuristic fallbacks keep the UI responsive even when Ollama is saturated - ASUS Ascent GX10's Blackwell architecture delivers the throughput needed for multi-model switching and real-time telemetry without thermal throttling
What's next for Tenet
- Collaboration: Multi-user branching, shared workspaces, and conflict-aware merge workflows for teams
- Outward dispatch + listening mode: Tenet acts as a background listener across web AI tools to auto-branch conversations in real time
- Advanced synthesis: Stronger merge intelligence with cross-model voting and contradiction-aware resolution suggestions
- Hardware-aware routing: Deeper ASUS telemetry-driven model selection based on current VRAM headroom, thermal state, and per-model throughput history









Log in or sign up for Devpost to join the conversation.