-
-
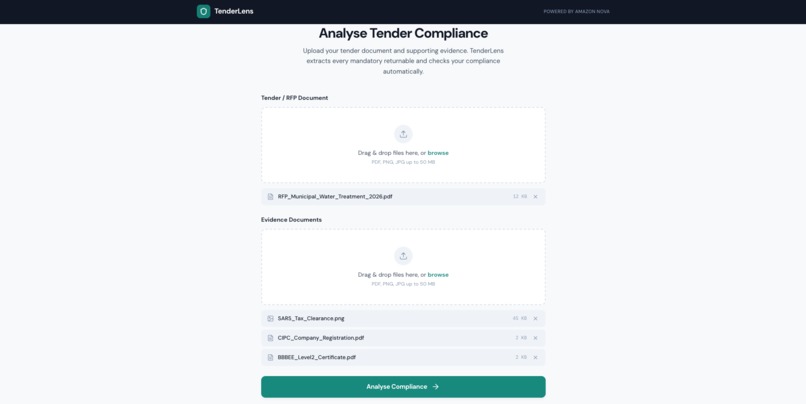
Upload a tender pack and your evidence documents — PDFs, scanned certificates, images. TenderLens handles all modalities.
-
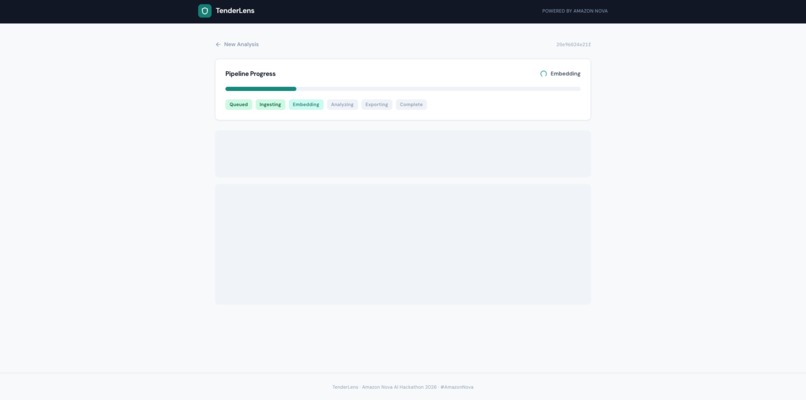
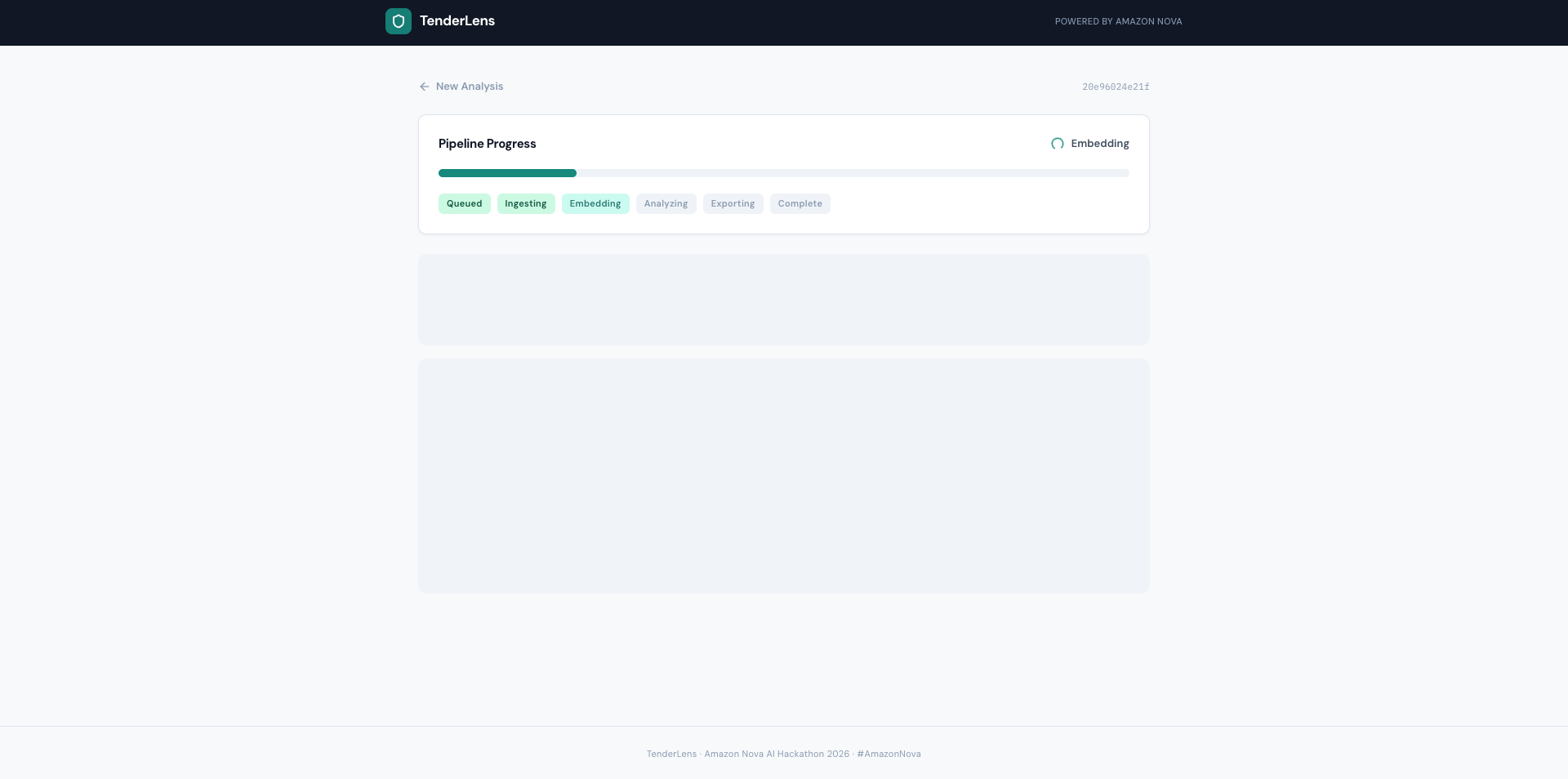
Real-time pipeline: ingesting documents, generating Nova Multimodal Embeddings, analyzing compliance with Nova 2 Lite.
-
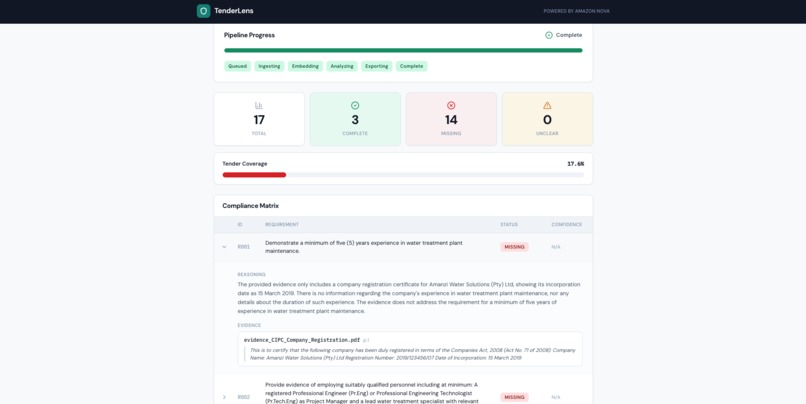
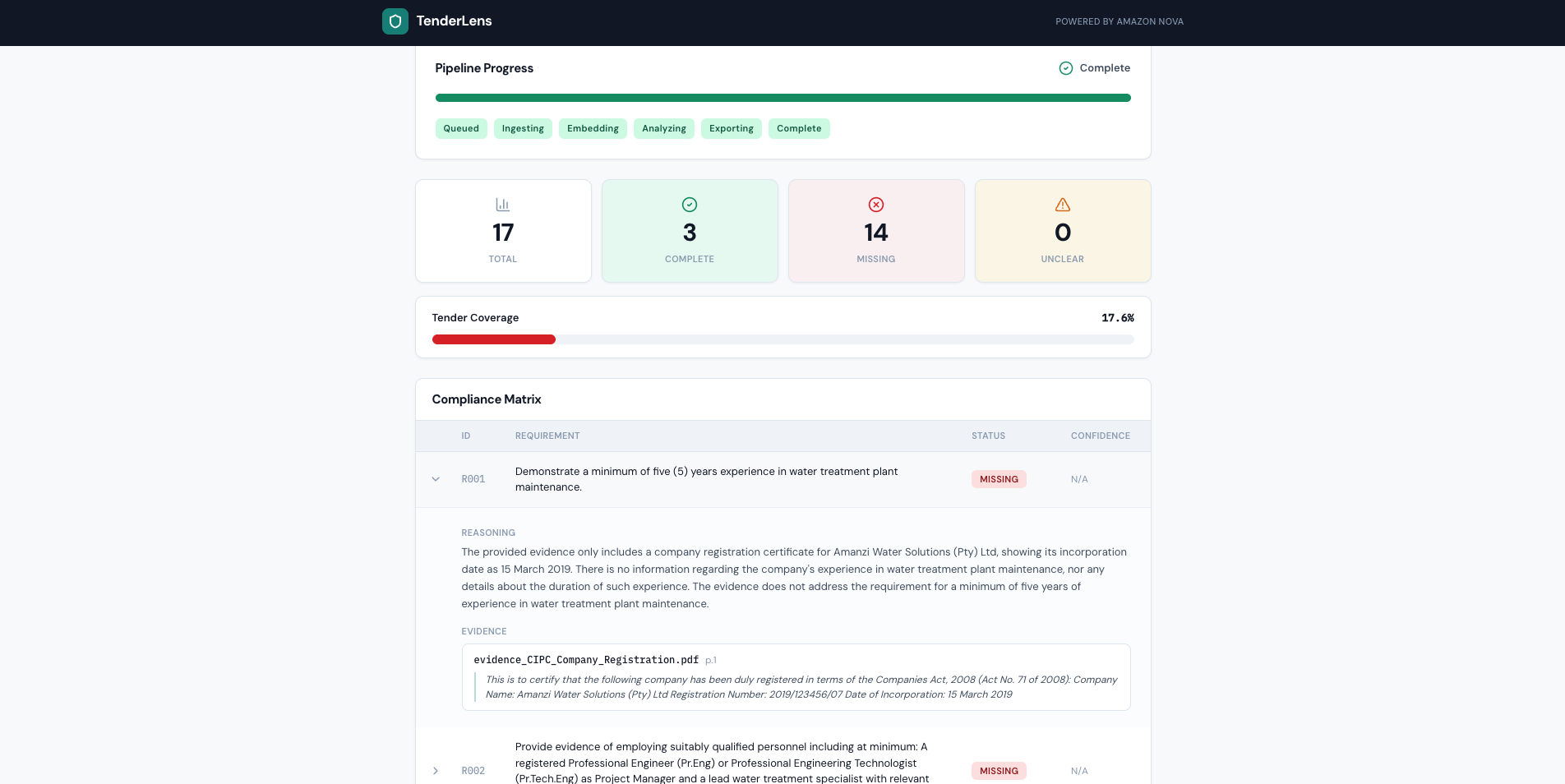
Evidence-backed compliance matrix: 3 complete, 14 missing, 0 unclear — each decision grounded in Nova's cross-modal document analysis.
-
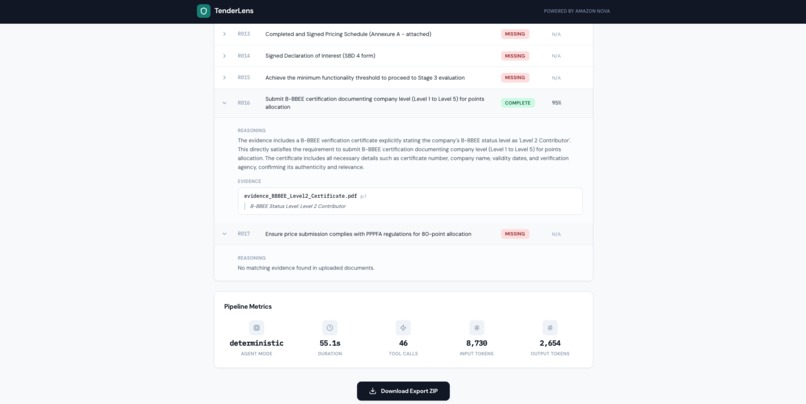
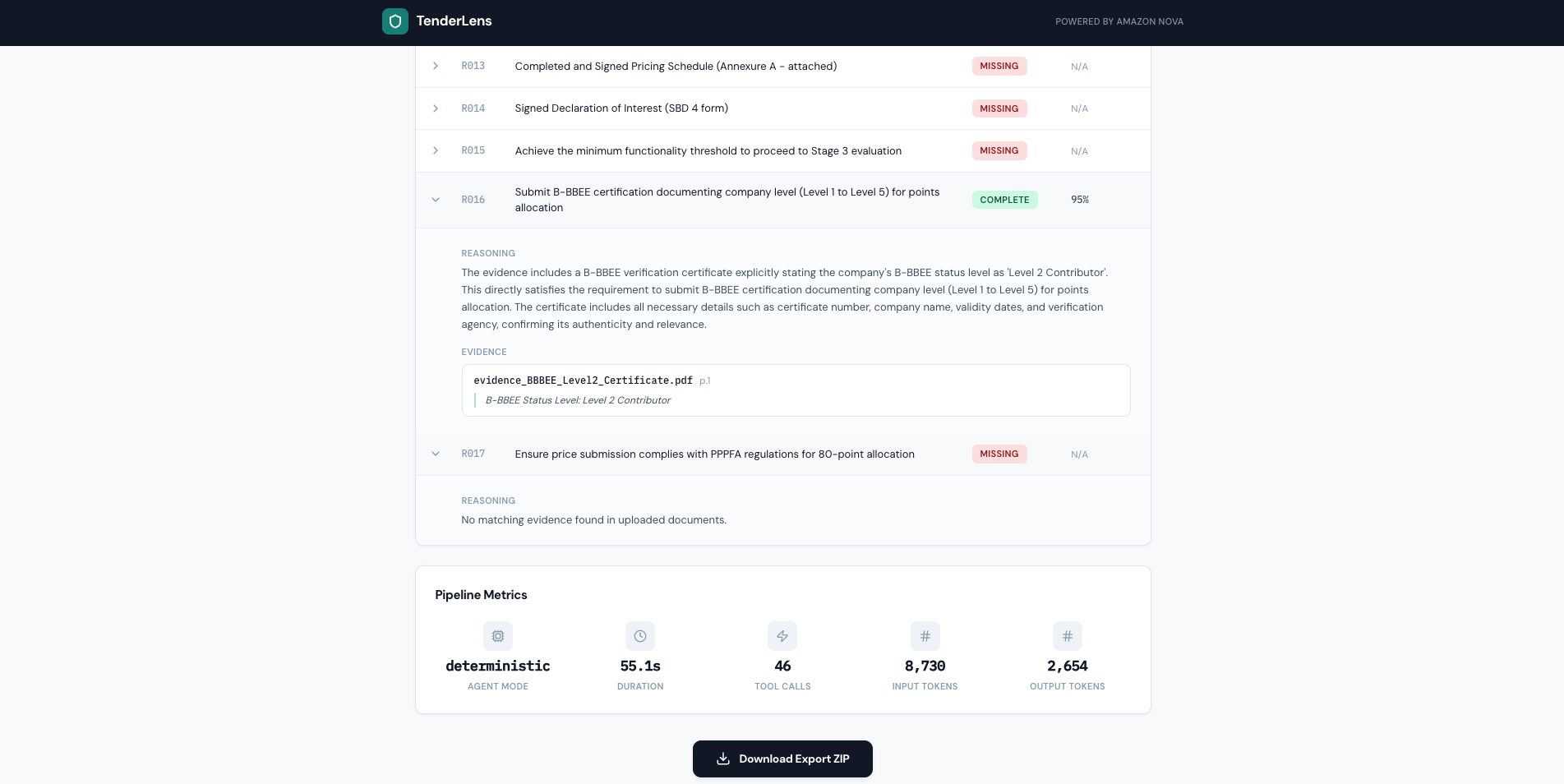
Every decision includes reasoning and citations to specific evidence files and pages — fully traceable, no black-box outputs.
Inspiration
In South Africa, government tenders are the lifeblood of small businesses. Every year, billions of rands flow through public procurement — and for many SMEs, winning a single tender can mean the difference between growth and closure.
But here's what I've seen firsthand: small business owners don't lose tenders because they can't do the work. They lose because they submit incomplete bids. A missing B-BBEE certificate. A tax clearance that was scanned but never attached. A declaration form they didn't know existed. One missing document = automatic disqualification. No second chances.
The tender packs themselves are often 30+ page PDFs filled with legal language, scattered requirements, and annexures that reference other annexures. For a small business owner without a dedicated bid team, just figuring out what to submit is a full day's work — before they've even started gathering evidence.
I wanted to build something that turns that overwhelming process into a clear, actionable checklist — powered by AI that can actually read the documents, match them cross-modally, and tell you exactly what's missing before you submit.
What it does
TenderLens is an agentic multimodal tender compliance copilot. You upload two things:
- A tender pack (the RFP/bid document as a PDF)
- Your evidence documents (certificates, registrations, scanned paperwork — PDFs and images)
TenderLens then:
- Ingests and segments every page, extracting text and rendering page images — automatically detecting scanned documents vs. text-based PDFs
- Embeds everything into a unified vector space using Amazon Nova Multimodal Embeddings, so text requirements can be matched against scanned certificates across modalities
- Extracts mandatory returnables from the tender pack using Amazon Nova 2 Lite, identifying every document and compliance requirement the bidder must submit
- Searches your evidence for each requirement using cross-modal vector retrieval — a text requirement like "Valid B-BBEE Certificate" gets matched against your uploaded scanned certificate image
- Decides compliance status for each requirement: Complete (with citations to the exact file and page), Missing, or Unclear — with reasoning explaining every decision
- Exports a submission-ready ZIP with organised folders per requirement, a CSV checklist, and a prioritised missing-items roadmap
The result is an evidence-backed compliance matrix that takes minutes instead of hours, with citations you can verify and a clear action list of what's still needed.
How I built it
AI Core (Amazon Nova on AWS Bedrock):
- Nova Multimodal Embeddings (
amazon.nova-2-multimodal-embeddings-v1:0) — the foundation of the cross-modal retrieval system. Every tender page and evidence document gets embedded into a unified 1024-dimensional vector space. This is what enables matching a text requirement against a scanned image of a certificate — the key differentiator of the multimodal approach. - Nova 2 Lite (
us.amazon.nova-2-lite-v1:0) via the Converse API with tool use — handles requirement extraction, compliance decisions, and structured JSON output generation. The agentic workflow uses Bedrock's native tool-calling protocol: the model decides which tool to invoke, the system executes it, and the result feeds back into the next decision.
Agentic Architecture:
The system implements a genuine tool-calling loop using the Bedrock Converse API. Four tools are defined — extract_requirements, search_evidence, decide_compliance, and generate_export — and the pipeline orchestrates them sequentially with full logging of every model invocation (tokens, latency, reasoning). A deterministic fallback ensures reliability if the agentic loop encounters issues.
Backend: Python/FastAPI with PyMuPDF for PDF processing, Pillow for image preprocessing, NumPy for in-memory vector similarity search, and structured logging of every Bedrock API call.
Frontend: React + TypeScript + Vite + Tailwind CSS — a clean compliance dashboard with real-time pipeline progress, expandable requirement rows with citations, and one-click ZIP export.
Infrastructure: Designed serverless-first for AWS (Fargate + S3 + DynamoDB), but runs entirely locally for the demo with graceful fallbacks — local file storage, in-memory job state, and in-memory vector search.
Challenges I faced
Session credentials expiring mid-pipeline. AWS SSO session tokens expire after a few hours. During development, I'd start a pipeline run and have credentials expire halfway through embedding 29 document chunks. The retry logic with exponential backoff I built into the embeddings client turned out to be essential — not just for rate limiting, but for surviving credential rotations.
S3 Vectors blocked by SCP. My hackathon AWS account had a Service Control Policy that blocked S3 Vectors API calls. Rather than fighting infrastructure, I pivoted to an in-memory NumPy-based vector store with cosine similarity. For a hackathon-scale dataset (~500 vectors), it performs identically — and eliminated an entire infrastructure dependency.
Nova 2 Lite's JSON formatting. The model sometimes wraps JSON output in markdown code fences, or appends conversational text after valid JSON. I built a robust _safe_json_loads() parser that strips fences, finds the first balanced JSON structure in the response, and retries with a correction prompt if parsing fails. Getting structured output from LLMs reliably is an underappreciated engineering challenge.
Cross-modal retrieval quality. Matching text requirements against scanned document images isn't trivial — embedding a text description of "SARS Tax Clearance Certificate" and a noisy photograph of that certificate produces vectors that are related but not identical. Tuning the similarity threshold (settling on 0.2 minimum) and using Nova's DOCUMENT_IMAGE detail level for page embeddings significantly improved retrieval quality.
Building solo under time pressure. As a solo participant, every architectural decision had to balance quality against time. I chose a deterministic pipeline as the default (reliable for demos) with the agentic loop as an enhancement, in-memory stores over managed infrastructure (zero setup time), and local-first development with cloud deployment as a stretch goal. The lesson: in a hackathon, a working demo beats a perfect architecture.
What I learned
- Multimodal embeddings are transformative for document processing. Being able to embed a scanned certificate and a text requirement into the same vector space — and have them actually match — felt like a breakthrough moment. Nova Multimodal Embeddings makes cross-modal retrieval accessible without building separate OCR → text → embedding pipelines.
- The Bedrock Converse API's tool-use protocol is production-ready. Defining tools as JSON schemas and letting the model decide invocation order creates genuinely agentic behaviour with minimal framework overhead — no external agent SDK needed.
- South African procurement is a massive unsolved problem. The eTenders portal lists thousands of active tenders, and the SMEs competing for them are often one-person operations. The gap between "AI that can read documents" and "a tool that actually helps someone submit a complete bid" is mostly UX and workflow design, not model capability.
What's next for TenderLens
- eTenders portal integration — automatically fetch tender metadata and downloadable packs from South Africa's public procurement portal
- Audio note support — using Nova Multimodal Embeddings' audio modality to let SME owners record voice memos as supplementary evidence
- Verification pass — a second-opinion analysis using Nova Pro for "unclear" items, with extended thinking enabled
- Submission deadline tracking — extract closing dates from tender packs and send reminders
- Multi-tender management — track compliance across multiple active bids simultaneously
Built With
- amazon-bedrock
- amazon-nova-2-lite
- amazon-nova-multimodal-embeddings
- amazon-web-services
- boto3
- fastapi
- numpy
- pillow
- pydantic
- pymupdf
- python
- react
- tailwind-css
- typescript
- vite

Log in or sign up for Devpost to join the conversation.