-
-
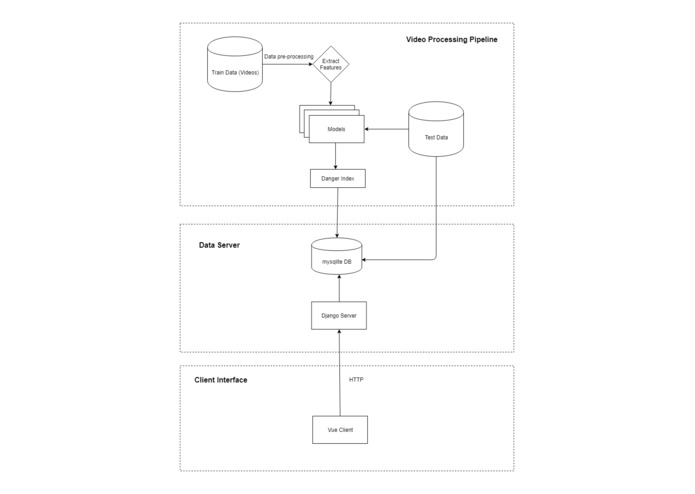
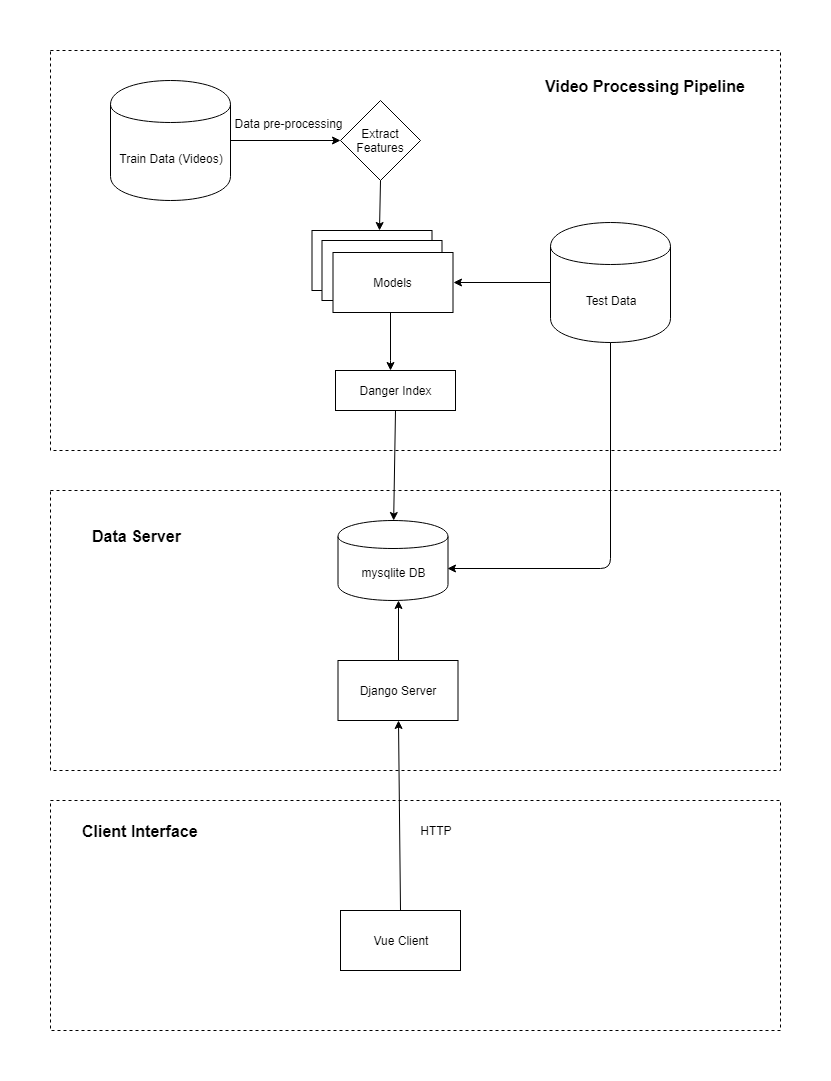
Model Workflow
Inspiration
With the rising of importance in the security field, street corners, blind spots, alleys, hallways, etc.. have never been as tightly monitored as today. As the number screens and cameras increase, security employees have more and more to look at. Staring at a dozen of dull footage for over a long period of time can become tiring and increases the chances of missing little details. Our goal is to bring attention to security guards/ policemen/ law enforcers where needed the most to decrease intervention latency and increase the chances to prevent incidents.
What it does
Pre-processing multiple videos in order to extract their violence flag (1: violent, 0: non-violent) on intervals of 0.5 seconds. This pre-processing consists of a mix of multiple machine learning algorithms such as: K-Nearest Neighbors and n-decision trees.
How we built it
The project consists of two major parts:
Presentation
- Frontend VueJs was used as the framework for the frontend (HTML/CSS/Javascript)
- Backend Django was used for the backend (Python) for setting up endpoints from the database. SQlite was used as database to store the results of all videos incremented by 0.5s.
Machine Learning A set of 6 hand labeled "bad/violent" clips and 9 hand labeled "good/non-violent" clips to train our ML model. Each of the clips are analyzed at intervals of 0.5s to extract all necessary data to determine violence/non-violence according to the following criteria
Brightness Here we are allocating a danger/violence value to the brightness of a scene. Though there is no direct correlation between the two, we noticed that a violent scene is most likely to appear in a darker environment - ie at night.
- Tech used:
- OpenCV - Python: The OpenCV library was used to convert an image to gray scale then parse out each pixel's brightness level to come to a total sum of a frame's brightness.
- Tech used:
Pixel Motion Motion detection in a scene help us make the following correlation: the more motion there is in a scene, the more likely violent action is occurring. Of course, we understand that this is not necessarily always the case, and there are noise in the background such as clouds moving, or cars moving that could create false positives, but generally, in a static environment if there are lots of movement, we can assume that the chances of violence occurrence is higher.
- Tech used:
- OpenCV: Used by taking two frames and subtracting the level of brightness between each pixel to determine how much it has changed, then summing the total amount of pixels changed.
- Tech used:
Number of People in the Frame The more people there are in a frame, the more likely a violence occurrence to happen. This is targeted towards detecting large masses of bodies crowding around a center - most likely fighting.
- Tech used:
- OpenPose: One of OpenPose's features is their 2D real-time multi-person keypoint detection. This feature allowed us to determine the number of people in one scene.
- Tech used:
Velocity The velocity mentioned here is the velocity a figure has, that is, how much a datapoint displaced from a 0 to 0.5s interval. Here, we make the assumption that the more velocity present in a frame, the more likely violence is occurring. Here we used a decision tree algorithm.
- Tech used:
- OpenPose: Data points taken from OpenPose allow us to map data points to a skeleton on a person's figure (left arm, right arm, left foot, right foot, head) This helps us determining the vector by subtracting the same data points from one frame to another.
- Tech used:
Vocabulary Knowing what objects were detected in a clip/video, we can associate their connotation with violence level. For example, the word "knife" would more likely correlate to violence/danger than "flower".
Tech used:
- Google Cloud Video Intelligence API: Extracting the objects detected in a video for its entire length.
- Word2Vector: By training a the Word2Vector model with a dataset, we can estimate in which octant and which area the words parsed out by Google API belong to. The closer they are to the 'danger' or 'violent' zone, the more likely the word parsed out has the same connotation.
Upon gathering all the data, for each video for each 0.5s interval, we ran a simple (...) to train our dataset with pre-determined (using a decision tree based model), hand labeled violent/ non-violent tags. The model was then applied on arbitrary videos.
For a more general model of the workflow, please consult the Figure: Model Workflow
In summary, this project made use of 3 pretrained models and 3 self trained models
- Pretrained
- Google Cloud Video Intelligence API
- Word2Vector
- OpenPose
- Self Trained
- Decision tree - For Velocity
- Decision tree - Envrionment (brightness, number of people) not incorporated in final version
- KNN - For vocabulary
Challenges we ran into
- Building our own dataset is challenging: We had to find a list of violent/danger representing videos and isolate the frames where there were occurences of violence.
- Implementing 6 ML models is challenging - a lot of organization was implemented and followed.
- Because of the GPU given, the processing speed was a little slow, hence data collection took a long time (~30min - 1hour)
What we learned
Members of the team that had no previous knowledge of Machine Learning algorithms had the opportunity to get some experience with how Ml works. We also learned how to use Google APIs
What's next for @tencion
The ML model and prediction model needs fine tuning, afterwards, the next step would be to have live feed. As mentioned before, the videos displayed are pre-processed. Live feeding video would take more processing power.
We quickly realized that our project can be applied to a broad spectrum of fields. This includes video games, movie monitoring, valet system for cars and security cameras. This software could give an edge over preventing dangerous events such as foreseeing terrorism attacks, natural disasters, robberies, etc...
Built With
- ai
- django
- machine-learning
- openpose
- python
- vuejs










Log in or sign up for Devpost to join the conversation.