-
-
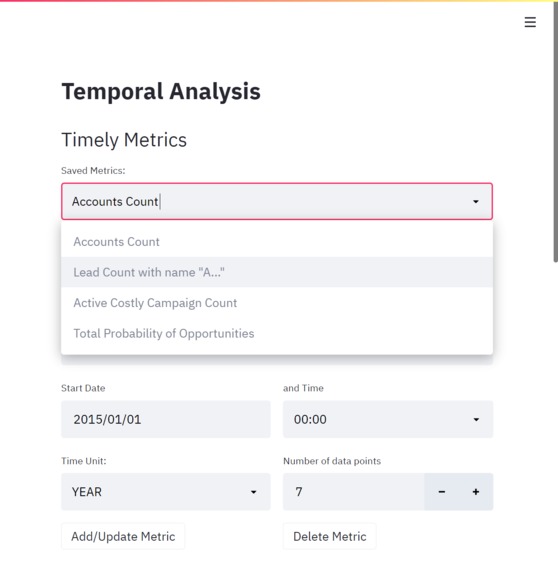
Ability to save and use multiple metrics
-
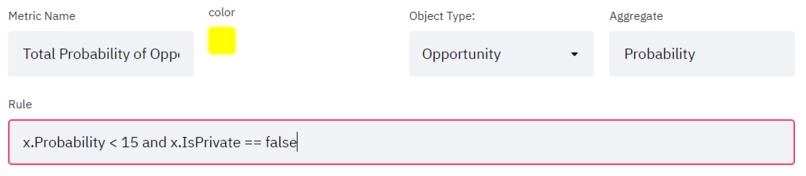
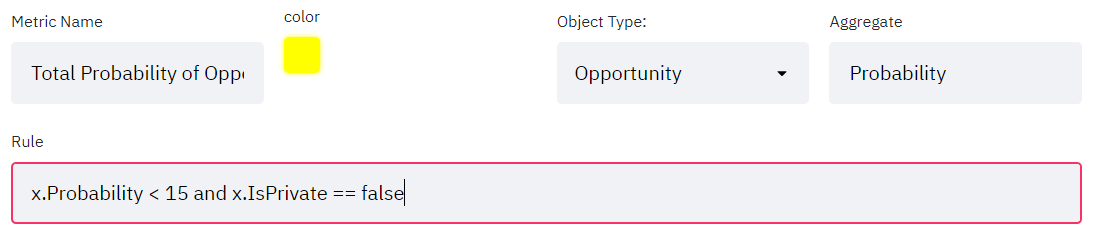
Custom conditions with simple GSQL and basic inputs
-
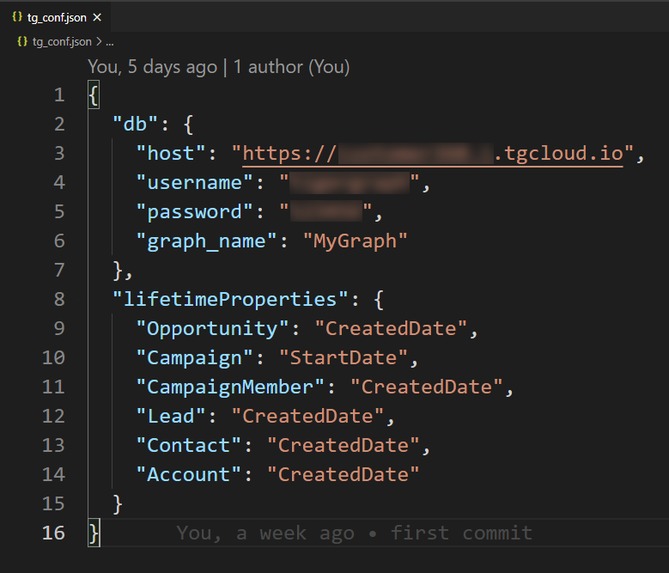
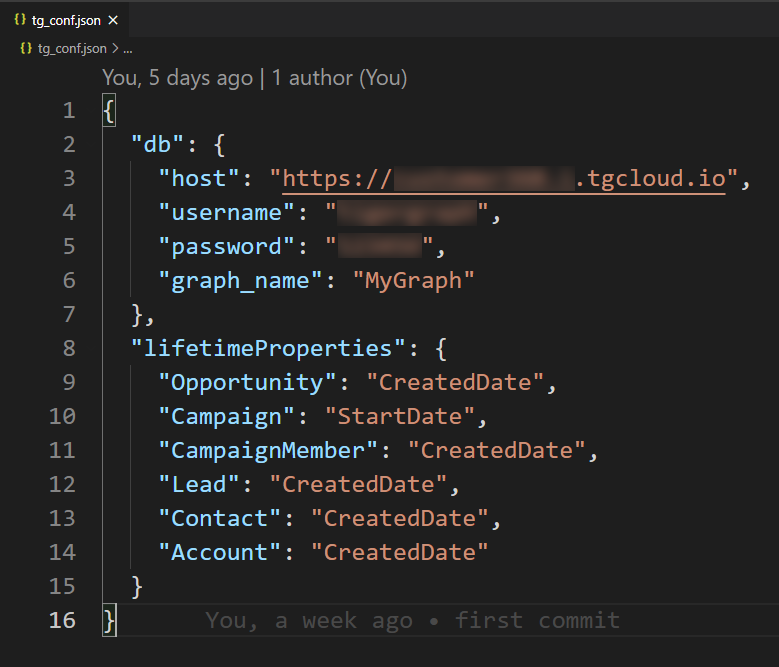
Ready to jumpstart with a short config file
-
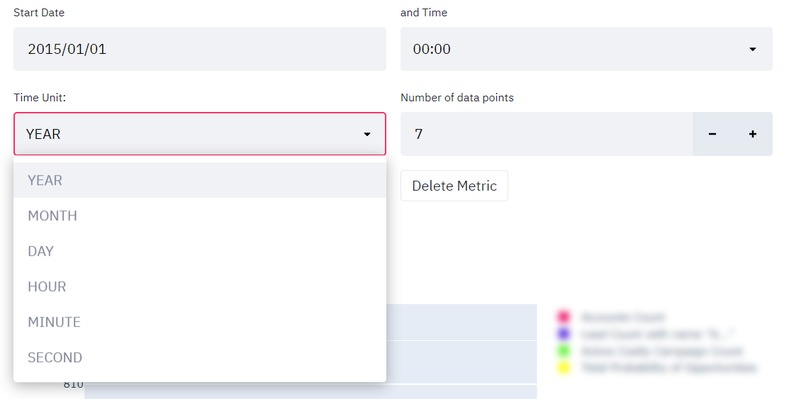
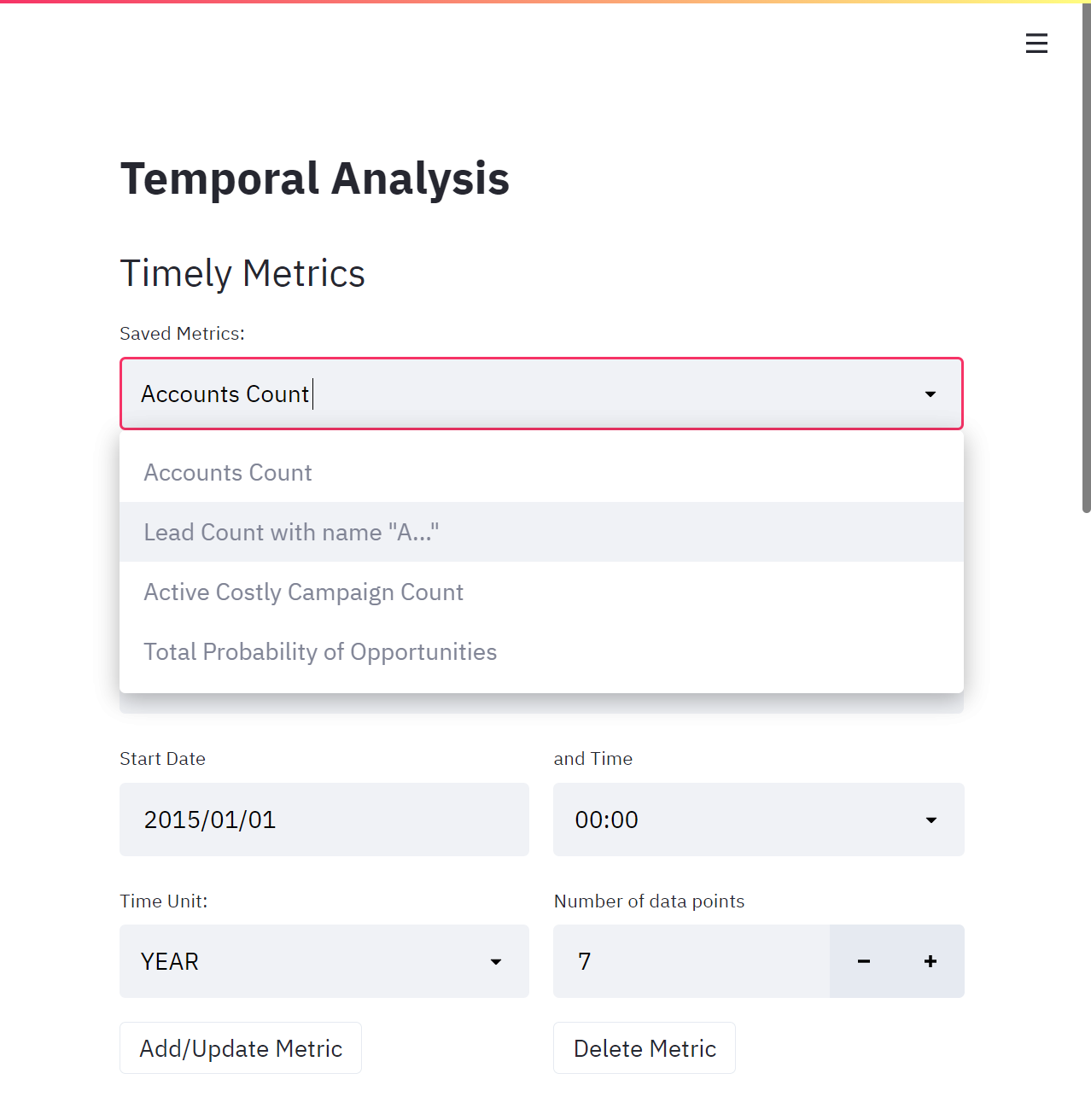
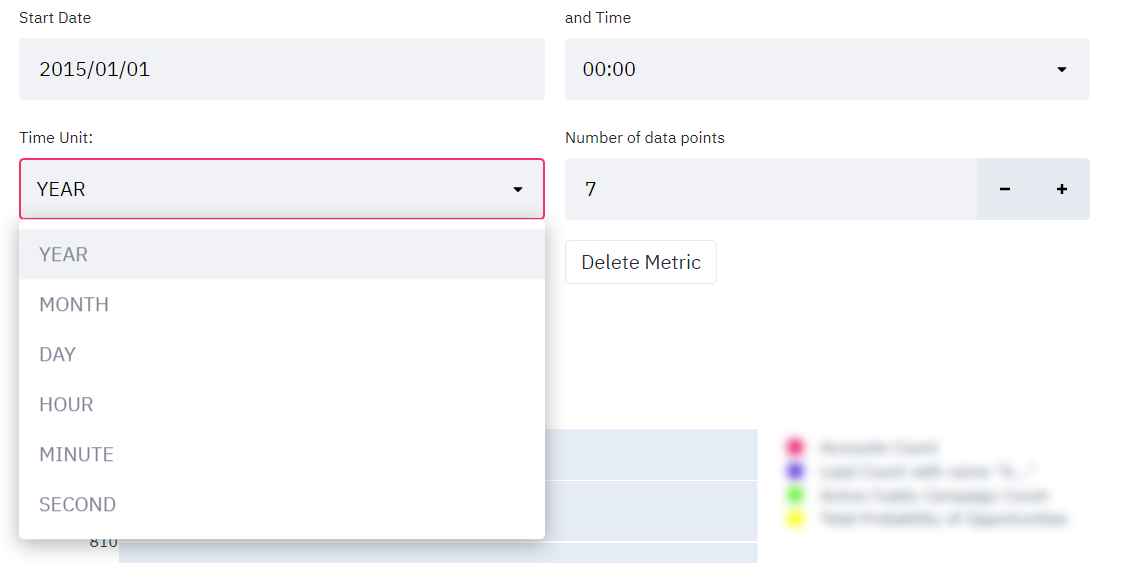
Set the time unit, number of points and start date for metrics
-
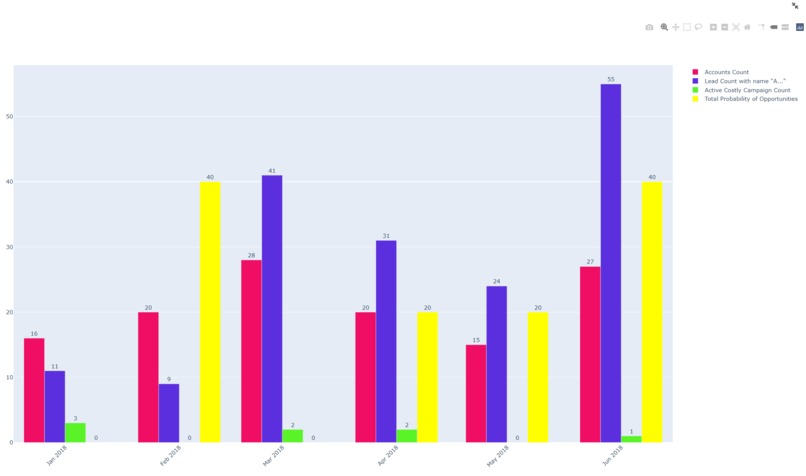
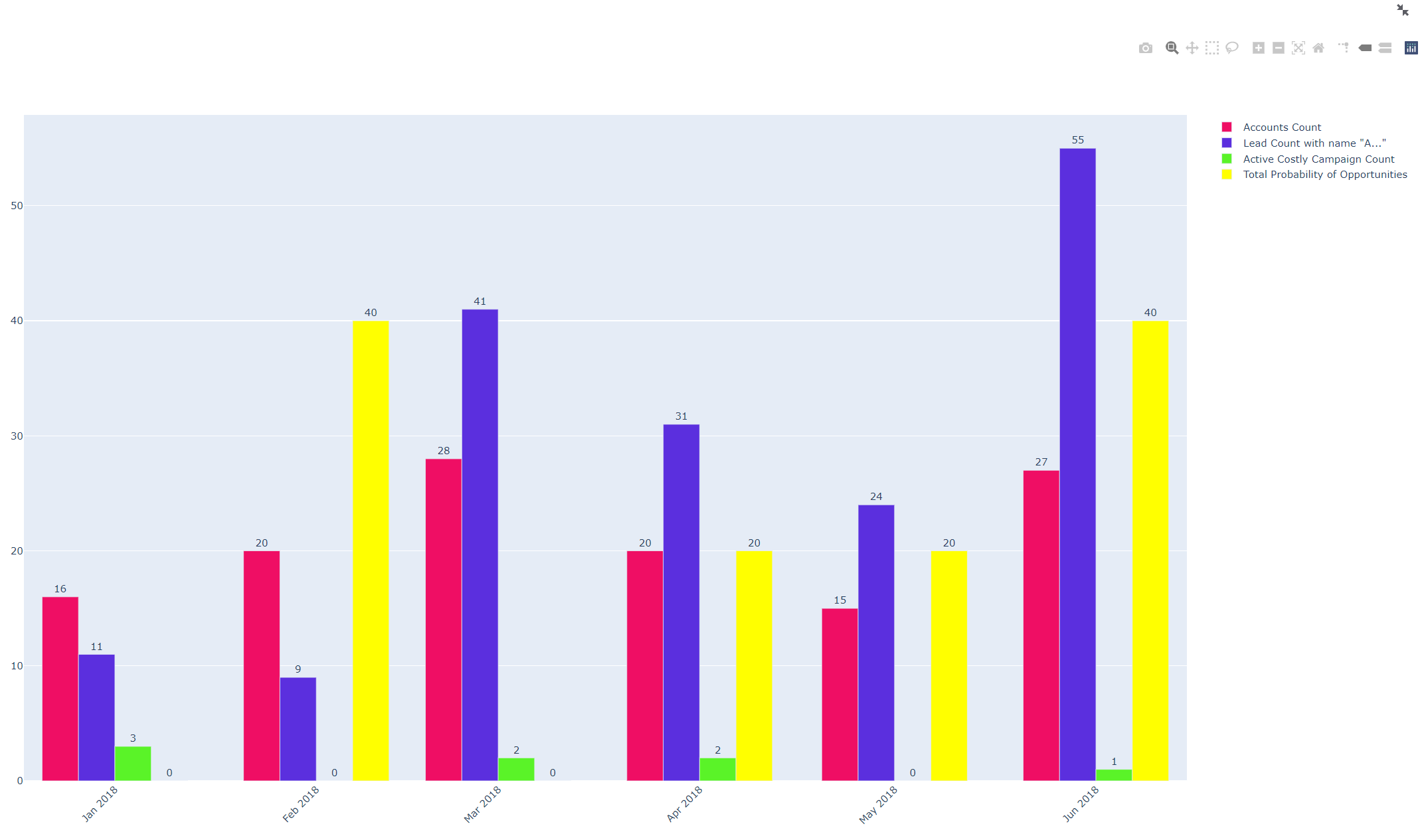
Show multiple metrics as chart
-
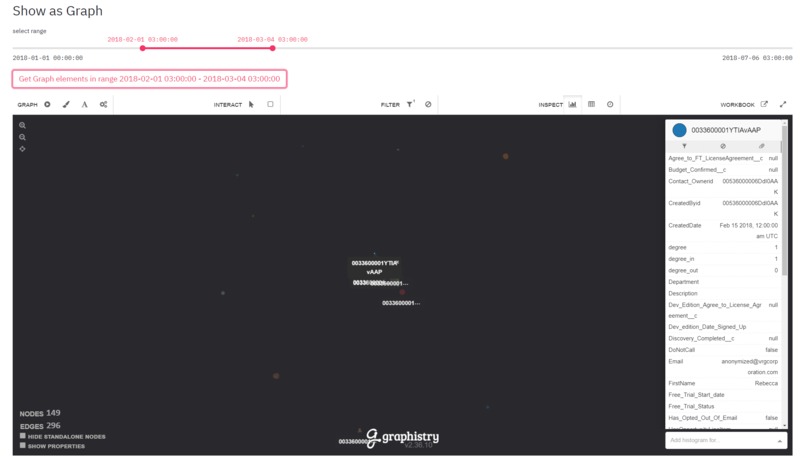
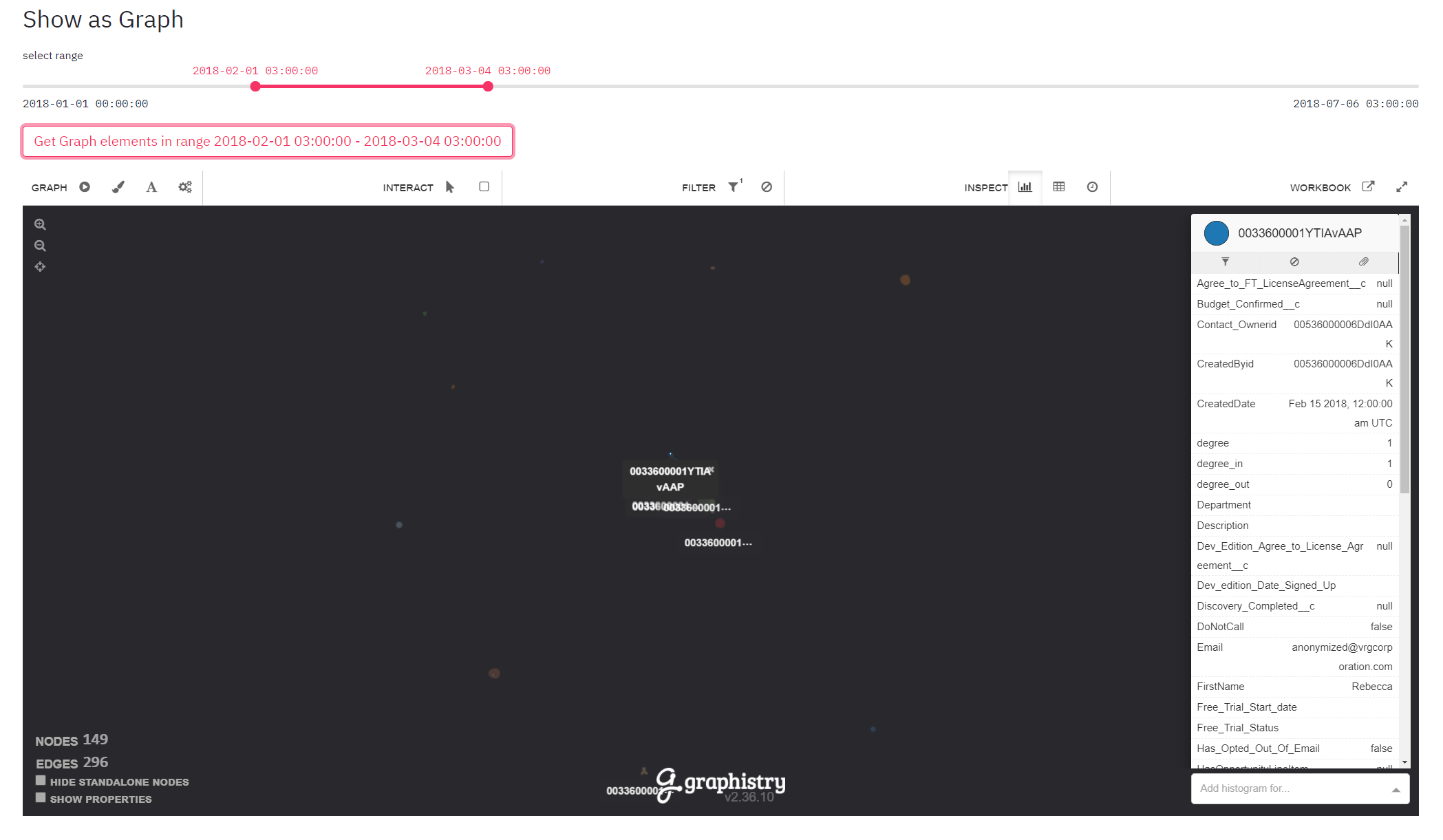
Show related objects as a graph and inspect them
-
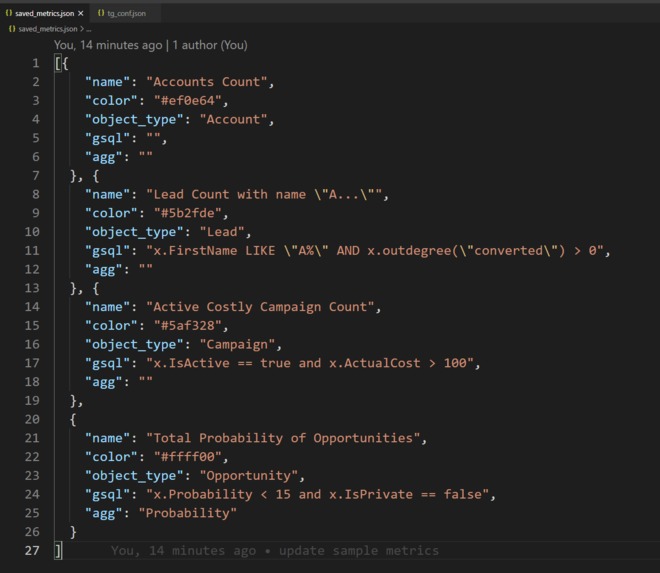
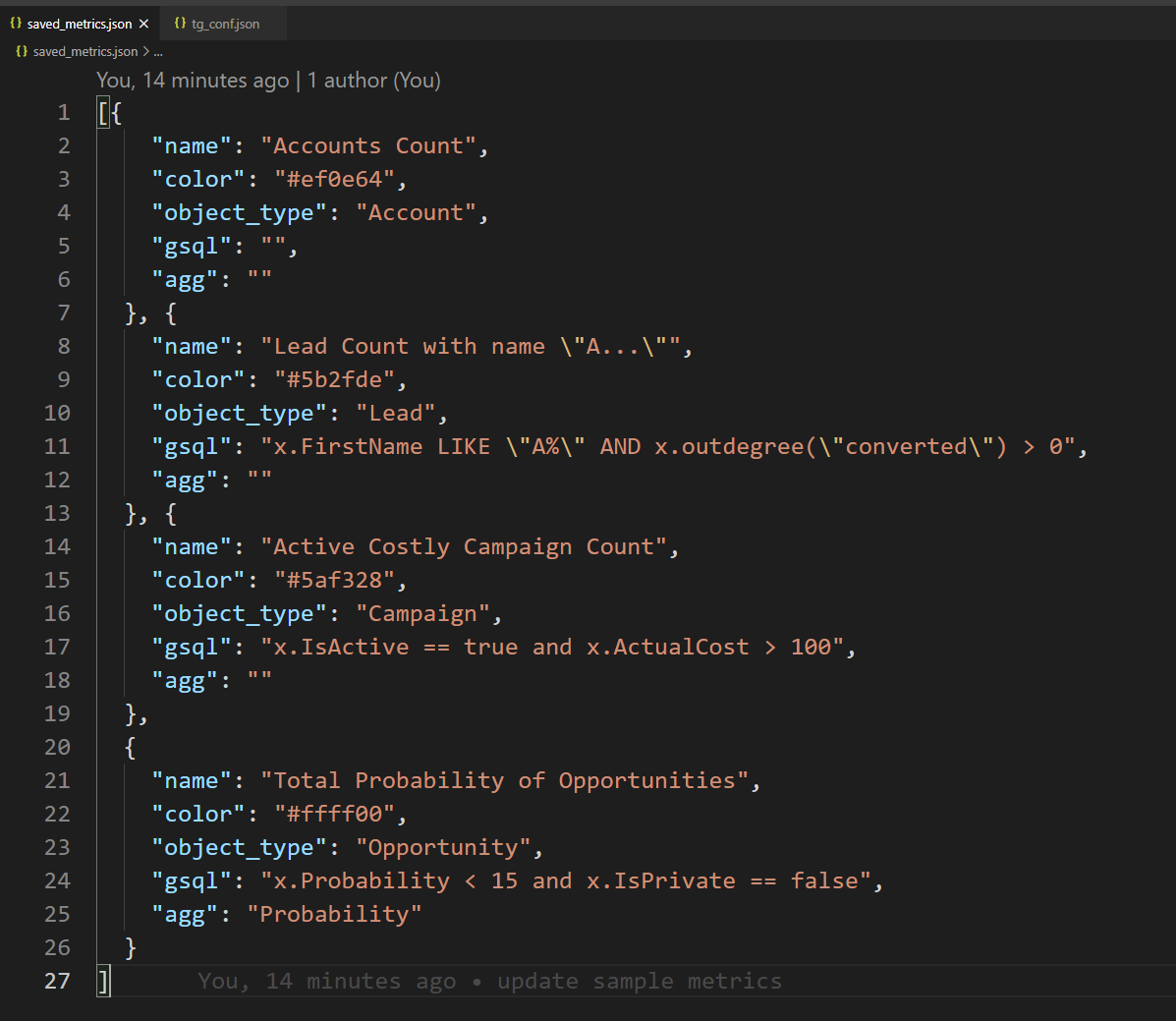
View/edit the metrics directly from its JSON file
Inspiration
Time-based filtering is usually the de-facto standard way of dealing with large databases. The data simply pile up as time pasts. Enterprises heavily rely on date/time-based filtering for focusing on a specific part of the data. Also, time-based statistics/metrics could be very useful to get some insights into the data.
What it does
It provides the ability to make time-based filtering. To make time-based filtering more advanced, the user can generate their own filtering conditions (metrics) with simple GSQL statements. You can set the starting date-time value and the number of data points. And then you can simply bring the related data as a graph.
You might want to make your custom metrics. For example, for each year you can see the count of "Customers" whose name starts with the letter 'A' and bought more than 1 "Product". Here instead of just counting the customers, you can also aggregate on some other attribute of "Customers". For example, instead of counting, you can get sum of the "age" attribute of "Customers".
Let's say you want to focus on a specific year. You can set the time unit to month and you can see the count of customers month by month. In a relational database system, a metric that gets the counts of "Customers" whose name starts with the letter 'A' is easy. But if "Customer" and "Product" are 2 different tables in the database, this might be time-consuming. You might need to join the tables and this might take a long time. In contrast, this can be a lot faster in a graph database. In GSQL, outdegree function is used here.
You can create multiple metrics and see them on a single graph. The app saves your metrics as a JSON file so that you can use them later.
Let's say after playing with metrics, you see that there are 10 "Customers" in March 2017. These 10 "Customers" are the ones who satisfy the conditions that you created (e.g. name starts with the letter 'A' and bought more than 1 "Product".) You might want to see them as a graph just like in the TigerGraph database. You can do that also. You can visualize these nodes and their neighbors as a graph.
How we built it
I mainly used Streamlit, for running the application. I used Plotly for drawing charts. I made HTTP requests to tigergraph cloud instance for getting graph data and chart data.
Basically, I injected some user input into GSQL codes and then executed them for drawing charts.
Challenges we ran into
Streamlit pretty new for me. It is good for building fast prototypes but I wanted to make a little more complex UX and UI functionality. It was challenging to build complex user experiences. Also, I don't want the user to write GSQL. I wanted to build a complex UI component for generating GSQL code from purely user-interface components but I couldn't do it.
Accomplishments that we're proud of
- Without writing any code, the user can see the number of objects for each time unit.
- The user can select the time unit as year, month, day, hour, minute, or second.
- The user can select the number of points in the graph.
- The user can show the objects as a graph.
- The user can save their metrics as JSON.
- The user can view multiple metrics at the same time.
- By writing simple GSQL statements like
x.price > 50, the user can make their own filtering rules (I call them "metric")
What we learned
- I learned GSQL a lot more. It looks powerful
- I learned streamlit and graphisty a bit. ## What's next for Temporal Analysis
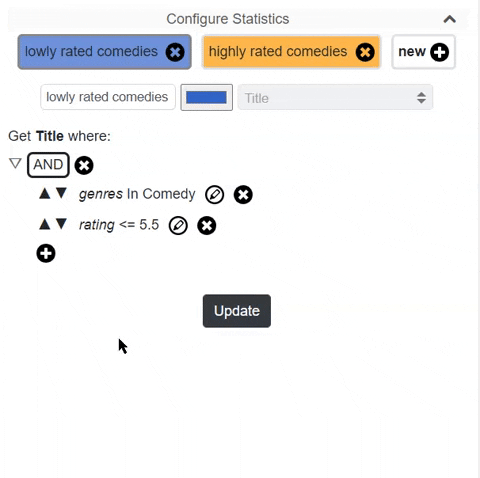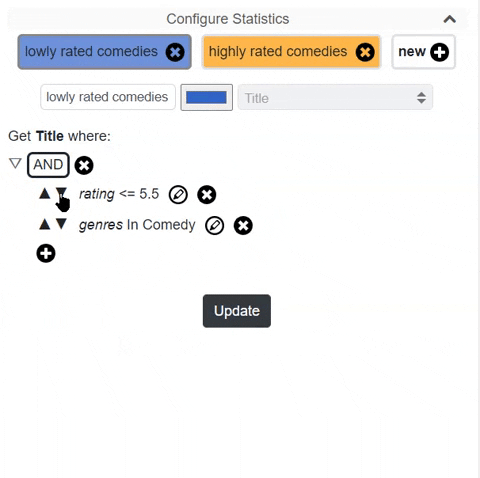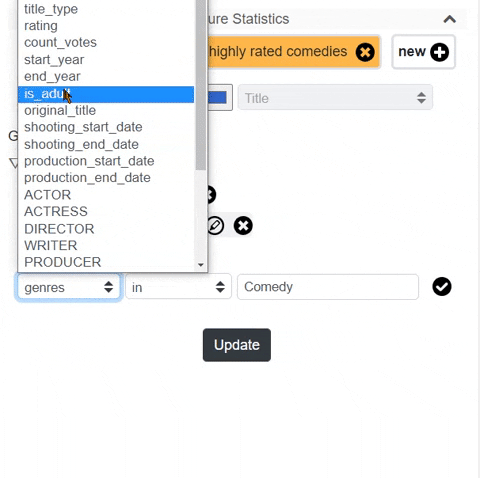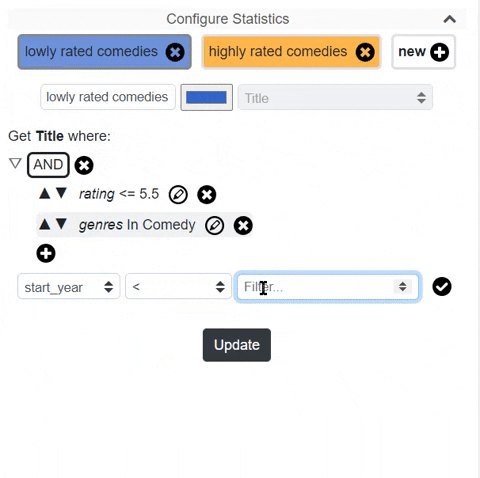
- Firstly by building a streamlit component I want to remove writing GSQL. I would like the user to build very complex rules with simple buttons and input. In fact, I already did such a thing with angular before like the below image.
- Actually in a chart any attribute which has a type as a number can be put to the horizontal axis. For example, if "id" is a number, we can also do id-based filtering, and basically, the horizontal axis in our charts can be "id". So even if the dataset doesn't contain any DateTime, you can just use numbers










Log in or sign up for Devpost to join the conversation.