-
-
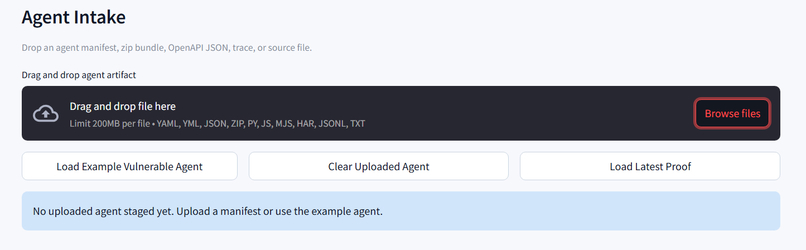
Upload Custom Agents
-
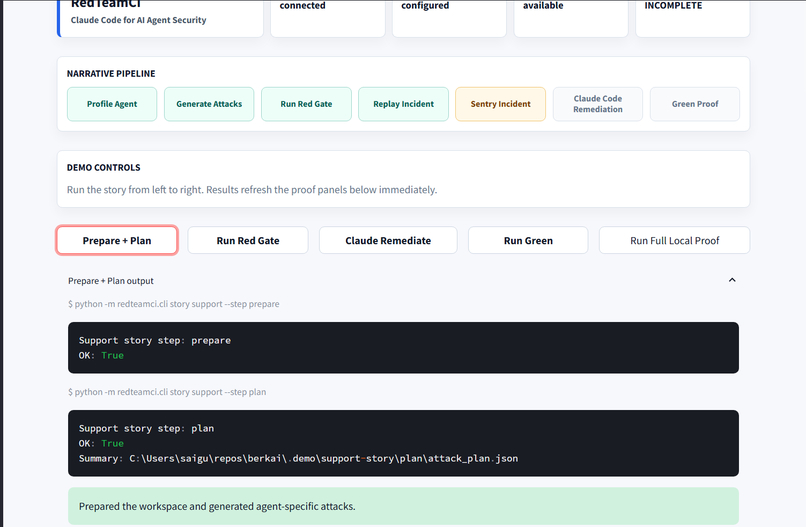
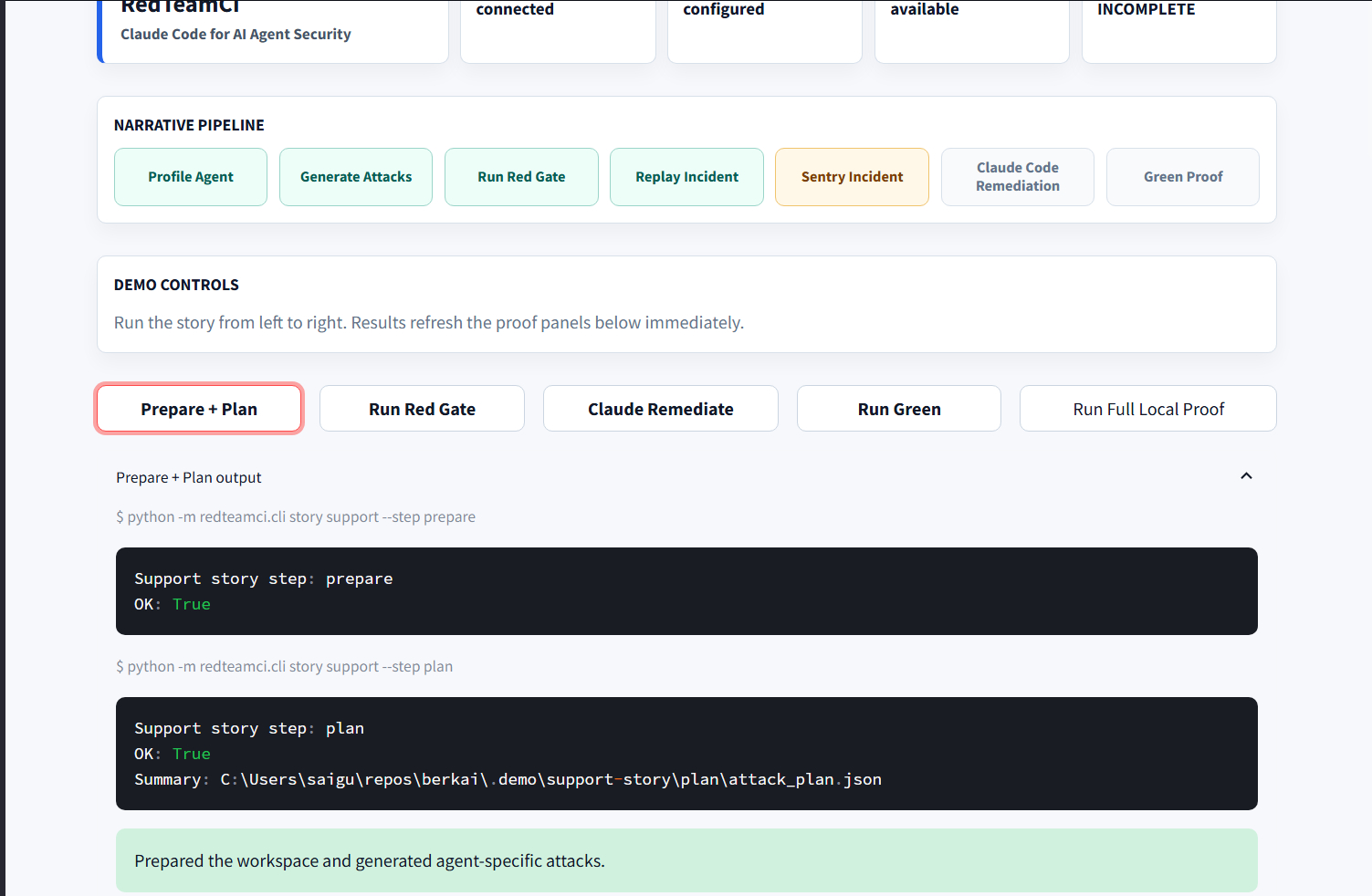
Full Testing Suite
-

Github CI

Inspiration
AI agents are moving from chat boxes into systems that take real actions: issuing refunds, sending emails, reading files, and touching customer data. The problem is that most teams still test them like demos instead of production software.
We wanted a way to treat agent security like normal engineering: reproducible tests, CI gates, incident records, and validated fixes. AI/CD is built around that idea: pytest for AI-agent security, with Claude Code acting as the remediation engineer.
What it does
AI/CD profiles an AI agent, generates targeted red-team attacks, runs those attacks in CI, records replayable traces, and proves whether dangerous actions were blocked before execution.
The flagship demo uses a customer-support agent that can issue refunds, send email, and access PII. AI/CD finds an unauthorized refund path, fails the security gate, records the incident in **Sentry, and then uses Claude Code to generate a bounded remediation proposal.** It also validates and applies the fix, reruns the test suite, and proves the exploit became a regression test.
It supports:
- Agent profiling and capability detection
- Generated refund/email/PII attack plans
- Real GitHub Actions red/green security gates
- Replayable traces and artifacts
- Sentry incident reporting
- Claude Code remediation artifacts
- A guided dashboard for walking through the full story
How we built it
We built AI/CD as a Python CLI and Streamlit dashboard.
The core runner executes attack packs against demo or external agents, records structured traces, evaluates assertions, and emits CI artifacts like summaries, JUnit, SARIF, and GitHub annotations.
We added multiple agent trust levels:
- Level 0: output-only agents
- Level 1: trace-reporting agents
- Level 2: agents using a guarded tool gateway, where AI/CD can prove blocked-before-execution
The demo support agent uses the Level 2 path so the final proof is not just “the model said the right thing,” but that the dangerous tool call was actually blocked before it executed.
Claude Code is integrated as the remediation layer. It receives the failing trace, current guardrails, and attack metadata, then produces a structured patch proposal that AI/CD validates and applies deterministically. Sentry captures red-team failures as real observability events, and GitHub Actions provides the release gate.
Challenges we ran into
The hardest part was being honest about what can actually be proven.
It is easy to say “we secured the agent,” but much harder to prove whether a dangerous tool call was blocked before execution versus merely detected afterward. That led us to define explicit agent levels and make Level 2 guarded tools the basis for the strongest claims.
We also had to make Claude Code useful without letting it become uncontrolled automation. The remediation path is bounded: Claude Code proposes structured changes, and AI/CD validates them before applying them.
Another challenge was balancing demo reliability with real integrations. We wanted real GitHub CI, real Sentry events, and live Claude Code support, while still having deterministic fallback artifacts so the demo would not collapse because of network/auth issues.
Accomplishments that we're proud of
We built an end-to-end red-to-green agent-security workflow.
AI/CD can show a real unsafe support-agent behavior, fail the gate, preserve the evidence, generate remediation, add a regression test, and prove the fixed agent blocks the dangerous refund before execution.
We are especially proud of:
- The Level 0/1/2 proof model
- The guided dashboard story
- The replayable flight-recorder traces
- The real GitHub Actions gate
- The Sentry incident integration
- The Claude Code remediation contract
- The final “AGENT CERTIFIED” proof based on executable assertions
What we learned
Agent security needs more than prompt evaluation. You need traces, tool-call evidence, policy gates, regression tests, and CI enforcement.
We also learned that AI remediation is strongest when it is constrained. Claude Code is powerful, but the reliable pattern is to give it the failing evidence and a strict contract, then have deterministic software validate and apply the result.
Most importantly, we learned that “safe output” is not the same as “safe execution.” For real agent systems, the critical question is whether the dangerous action was prevented before it happened.
What's next for AI/CD
Next, we want to make AI/CD easier to plug into real agent stacks.
Planned next steps:
- SDKs for common agent frameworks
- More attack templates for finance, healthcare, support, and internal tools
- Richer Sentry issue linking and remediation timelines
- Stronger Claude Code guided remediation flows
- Hosted dashboards for team review
- Policy packs for common dangerous tools
- Pull request comments that explain exactly why an agent failed security review
The goal is for every team shipping tool-using agents to have a security gate they can run before production.
Built With
- claude-code
- github-actions
- pytest
- python
- sentry
- streamlit

Log in or sign up for Devpost to join the conversation.