-
-
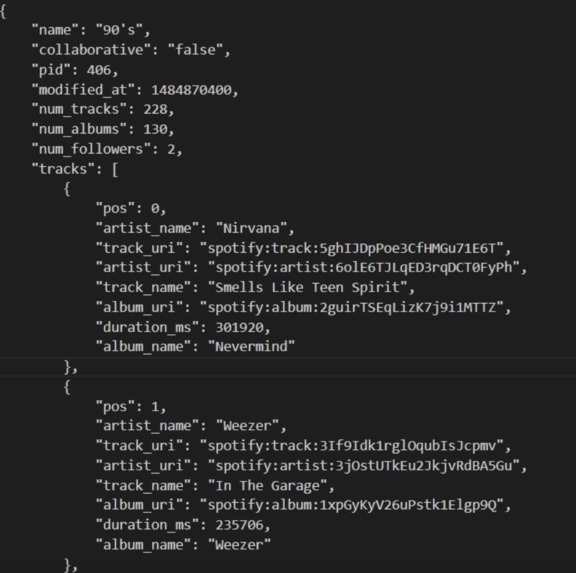
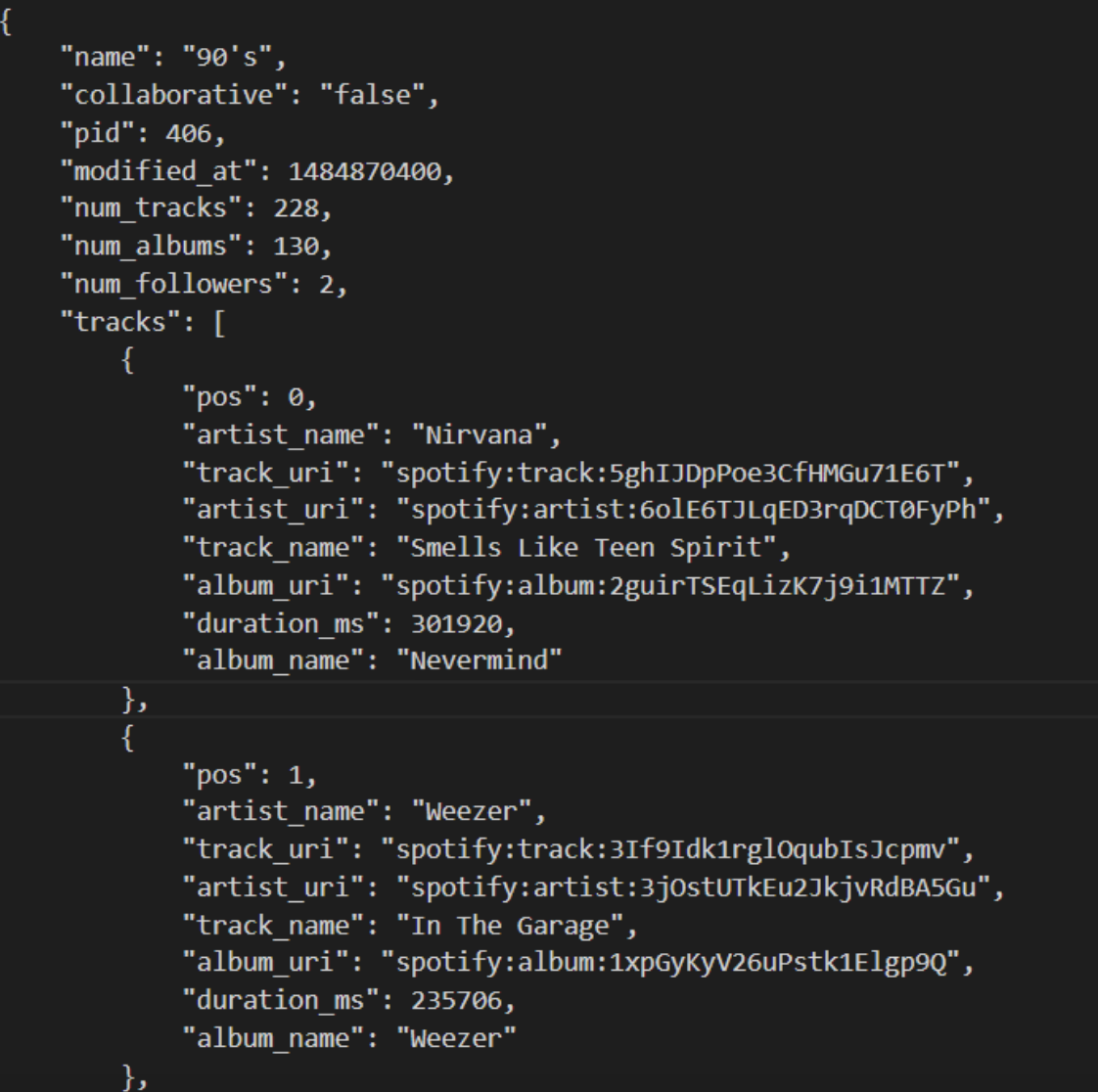
Figure 1. A sample snippet of information provided for one playlist in the dataset.
-

-

-


Spotify Song Recommender
by VaDeep CUDAlay: Calvin Will (cwill1), Eric Han (ehan31), Hunter Zonnenberg (hzonnenb), Mason Stang (mstang1).
Introduction
In recent years, content recommendation algorithms have become increasingly utilized by streaming services to deliver specialized content to their user bases and increase user engagement. Additionally, the issue has served as a topic of great interest in the Machine Learning community. In 2018, Spotify and several prominent universities jointly initiated the RecSys challenge, in which a training dataset of one million playlists were provided and a series of content-recommendation challenges were given to contestants. The primary focus of the challenge was determining an effective methodology for playlist continuation. This contest was reinitiated in 2020 and is judged on an ongoing basis to this day. We sought to build a model that would, given a song or a set of songs, be able to provide songs similar to the given inputs based on relative frequency and position of songs in the same playlists as the given songs. We did not base our model off of any existing implementation of this problem, but rather created our own model using our knowledge of Language Modeling RNNs.
Methodology
We based our model loosely off of our implementation of our construction of a Recurrent Neural Network used for Language Modeling in Homework 4. After preprocessing slices of the Million Playlist Dataset to compute relevance scores between each song and every other song that they share a playlist with, we implemented a LSTM RNN using a word embedding layer, followed by a LSTM, and finally by a sequence of dense output layers ending with softmax activation. We determined the number of epochs for training by observing manual when the RPrecision stopped increasing. Our Loss function was sparse categorical crossentropy.
Data
The dataset used in our model consisted of one million Spotify user playlists, separated into slices of 1000 playlists. Although we had access to one million playlists, we ran our model with only one hundred thousand playlists to keep the project computationally feasible. These playlists were given in the JSON format, and ranged in size from less than 10 songs to over 100. The dataset is publicly available for research purposes such as our efforts, but not for commercial purposes. The dataset, and further information about its use can be found at https://www.aicrowd.com/challenges/spotify-million-playlist-dataset-challenge.
Metrics
A metric known as r-precision is utilized to determine the “accuracy” of song recommendations by determining the number of relevant songs in the selection generated by the model. The best model in the initial RecSys challenge achieved r-precision of 0.2241[1], and other top quality models achieved r-precision in the 0.17-0.20 range. We don’t expect our model to do that well, but we would like our model to have an r-precision that is distinctly and consistently greater than 0. To calculate relevance, we count the number of times two songs appear in a playlist together, then generate an ordered set of songs that are relevant to a target song.
Discussion of Assumptions made in the Model
Note that by using an LSTM, we’ve made the assumption that playlists are sequences. While this may be partially correct, in hindsight we realize that many people construct playlists not as a sequence, but as a multiset of songs. One worry is that by using an LSTM, we’ve inaccurately prescribed an ordering to songs that is not reflective of a song’s overall relevance. Moreover, using an LSTM led us to make several additional decisions about the format of our inputs. For example, we chose between padding playlists so that they are all the same size, or just sending in playlists as is. We added a song in between playlists to help the model train. We also tried padding our input playlists so that they were all of equal length. We then set the window size to be the length of the playlists. However, we found that this gave lower RPrecision values than the RPrecision value.
Challenges
Besides unceasing issues with our kernels, our challenges existed primarily in determining how we should determine the relevance between two songs and what model architecture we ought to use. As we were able to easily access a useful and widespread dataset for this type of problem, there was little challenge in data acquisition. Preprocessing the dataset proved more challenging, but the data was, at large, in a form that proved fairly easy to access. Our primary challenges were conceptual in nature, consisting of how we ought to address this data, and in what form we should shape it such that a neural network of our design could effectively consider whether a song is similar enough to another song to be recommended. In the end, another challenge was in evaluating the effect of changes to our model. Since the r-precision tended to be a relatively small number and vary slightly between training instances, it was difficult to draw conclusions about the utility of modifications to the model.
Our largest challenge was integrating our custom accuracy function, RPrecision, into keras. Because RPrecision does not take a universal ‘y_true’ argument, but instead ‘y_true’ is dependent on each individual song’s relevance, we could not fit RPrecision into the context of keras. Therefore, we evaluated our results after the model was trained, so we could not see a running tally of change in accuracy. Therefore, much of our analysis relies on the changing loss function instead.
Results
Our model was somewhat effective in giving song recommendations for input songs. While it tended to be biased towards more popular songs, we were able to reach a general R-Precision of 0.02. We trained over three thousand-playlist slices, since any larger amount caused memory issues and unreasonably long training times.
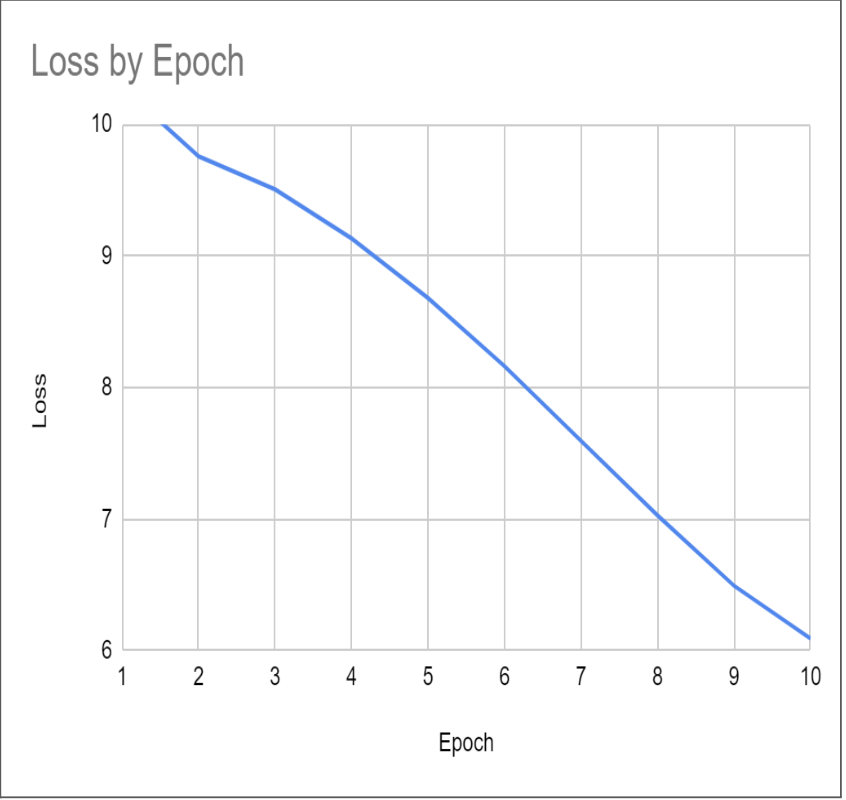
The graph models our model’s loss relative to the training epoch. As expected, the loss decreases with each epoch. However, the RPrecision has no significant change. This indicates our loss function choice may not have been the strongest choice.
Also attached is an image that shows our model’s output when given the song “Californication”. The top list shows our model’s recommendations for similar songs, while the bottom list is our calculated “relevance” – the songs that we have determined are most relevant to “Californication” because we have manually counted the frequency with which they appear in the same playlist as “Californication”. You can see that there is significant overlap between our model’s recommendations and the calculated most “relevant” songs, a good sign for our model. The R-precision calculation for this single test is 0.5.
Overall, we are somewhat satisfied with our model’s performance. It could often provide good song recommendations such as we see in the image above, especially when prompted with a popular song. Additionally, we were happy to see relatively good loss values, and the loss decreasing with each epoch. However, we wish we achieved a higher R-Precision accuracy. The highest performing model in Spotify’s challenge, for example, had an R-Precision of 0.2241, while ours only achieved 0.02. If we had more time to fine-tune our R-Precision metric, and if we were running our model on a system that could work with a larger dataset, we believe we could improve our R-Precision result.
Reflection and Discussion
There exists, without a doubt, a multitude of already existing solutions to the problem of playlist generation. A majority of publicly available implementations of this practice are in all truthfulness more complex and effective than anything we could reasonably create or even conceive of at this point. It proved very interesting getting to view a small number of approaches to this problem, and was particularly engaging and fun. Our solution may not be the most elegant or competent, but we are fairly happy with its ability to recommend a list of relevant songs from an input song. Our original base and target goals focused primarily on returning songs of similar genres, which was accomplished, but after determining those goals we pivoted towards the more nebulous quantity of “relevant” songs, which was based on commonality of songs in playlists and their relative distances. Overall, our model did not work quite as we expected. We were able to make a model that could make objectively good recommendations on popular songs, but our R-Precision values were not as good as we would have liked.
Our approach to this problem varied greatly over time. In the beginning, we could not decide whether we intended to implement an existing paper’s model or work to create our own. After viewing a number of models, we determined that we would rather work on our own solution. At that point substantial discussion began about our model architecture. Whether we ought to use a Transformer was an issue of serious contention, but in the end we decided to instead use a LSTM, as we collectively felt more confident in their creation and use. After that, we were able to proceed more or less as we intended. If we had the chance to begin this project again, perhaps with more knowledge, we would likely attempt to use a Transformer as the primary component for our model architecture, or work to re-implement a fascinating existing model that utilized matrix factorization – a strategy that most of the top performing models used but which we did not cover in class.
If we had more time, we would work to fix our R-Precision. Since R-Precision is an accuracy metric that is called by Keras, we were unable to pass some of the information we needed (such as inputted song), and so our calculation was not as good as it could have been. Integrating our accuracy metric with Keras’s implementation indeed proved a challenge. Furthermore, with more time we could have further fine-tuned our layers to maximize accuracy. With many minutes required to run and test each iteration, the iterative approach to development we found to be very time consuming.. We would also integrate Normalized Discount Cumulative Gain (NDCG) as an accuracy function. NDCG is very similar to R-precision but takes into account the relative order of relevant songs in calculating a final score.
From this project, we learned a great deal about preprocessing data so that we could apply a standard accuracy metric to it. We attempted many methods to measure relationships between two songs, and determining the optimal methodology was one of the most difficult issues we faced. R-precision is an interesting accuracy metric that requires us to determine whether songs are relevant to each other, which can be considered fairly subjective. In the end, we did measure the importance of relationships between songs during preprocessing with a map of song ids to every song they appear in a playlist with, which in turn are mapped to the number of times they appear together. From a deep learning standpoint, we learned about the importance of which assumptions we make about our data, because those assumptions influence decisions about model architecture. In this respect, we learned the value of truly knowing the data you’re working with.
Code Repository
Our codebase is accessible on GitHub at: https://github.com/SppEric/spotify-recommender
References
[1] Zamani, H., Schedl, M., Lamere, P., & Chen, C.W. (2019). An Analysis of Approaches Taken in the ACM RecSys Challenge 2018 for Automatic Music Playlist Continuation. ACM Trans. Intell. Syst. Technol., 10(5).


Log in or sign up for Devpost to join the conversation.