Inspiration
The e-commerce experience today is often impersonal. A 5-star rating from a 20-year-old can mean something completely different to a 60-year-old because expectations around fabric quality, fit, comfort, and style vary across age groups. We wanted to build a system that goes beyond generic averages and predicts how you specifically might feel about a garment by learning from the collective voice of your own demographic “neighborhood.”
We were also heavily inspired by MyFitnessPal’s barcode scanning experience for quick product lookup. The app’s layout and “For You” style discovery feed were influenced by platforms like Instagram, TikTok, and Depop.
What it does
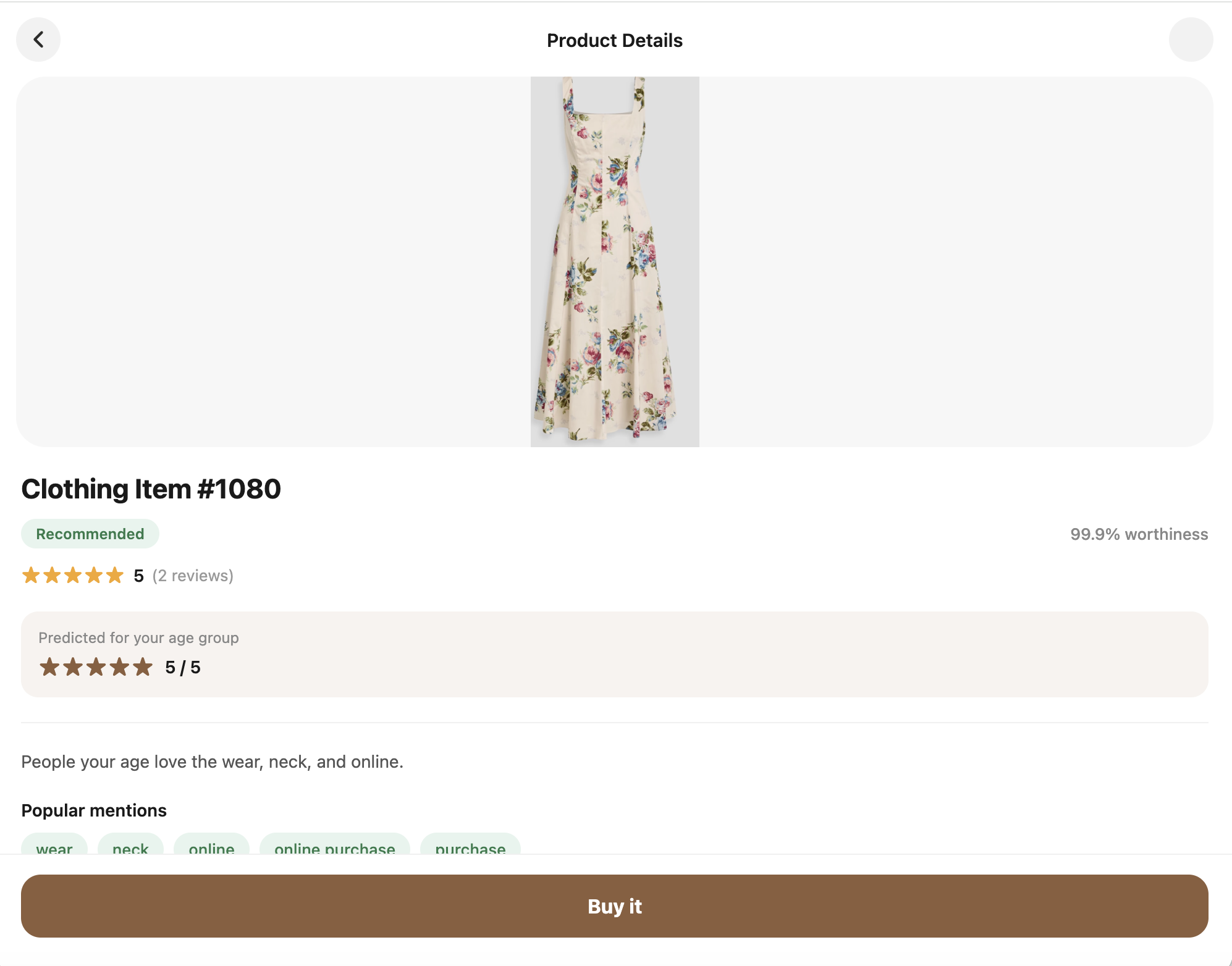
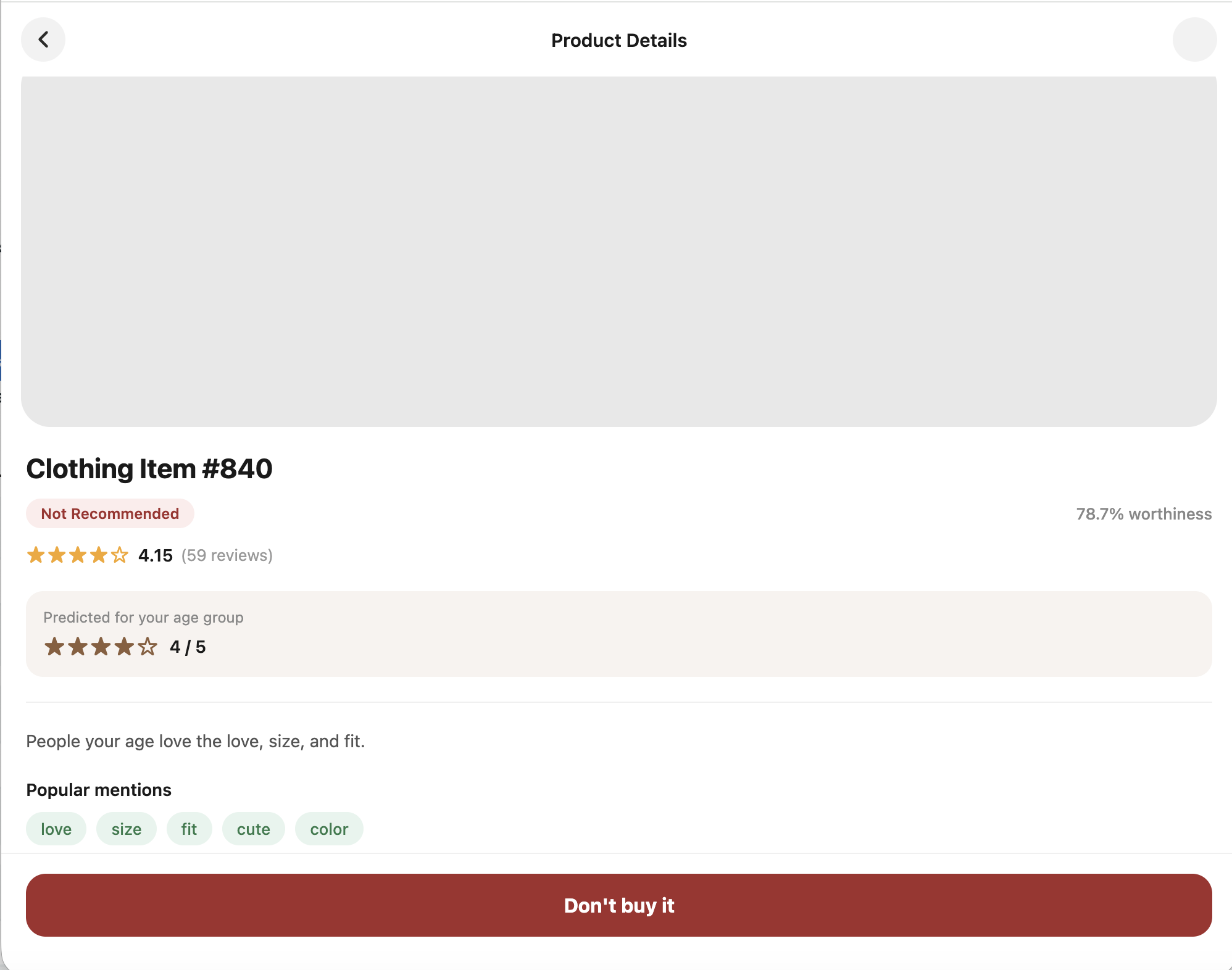
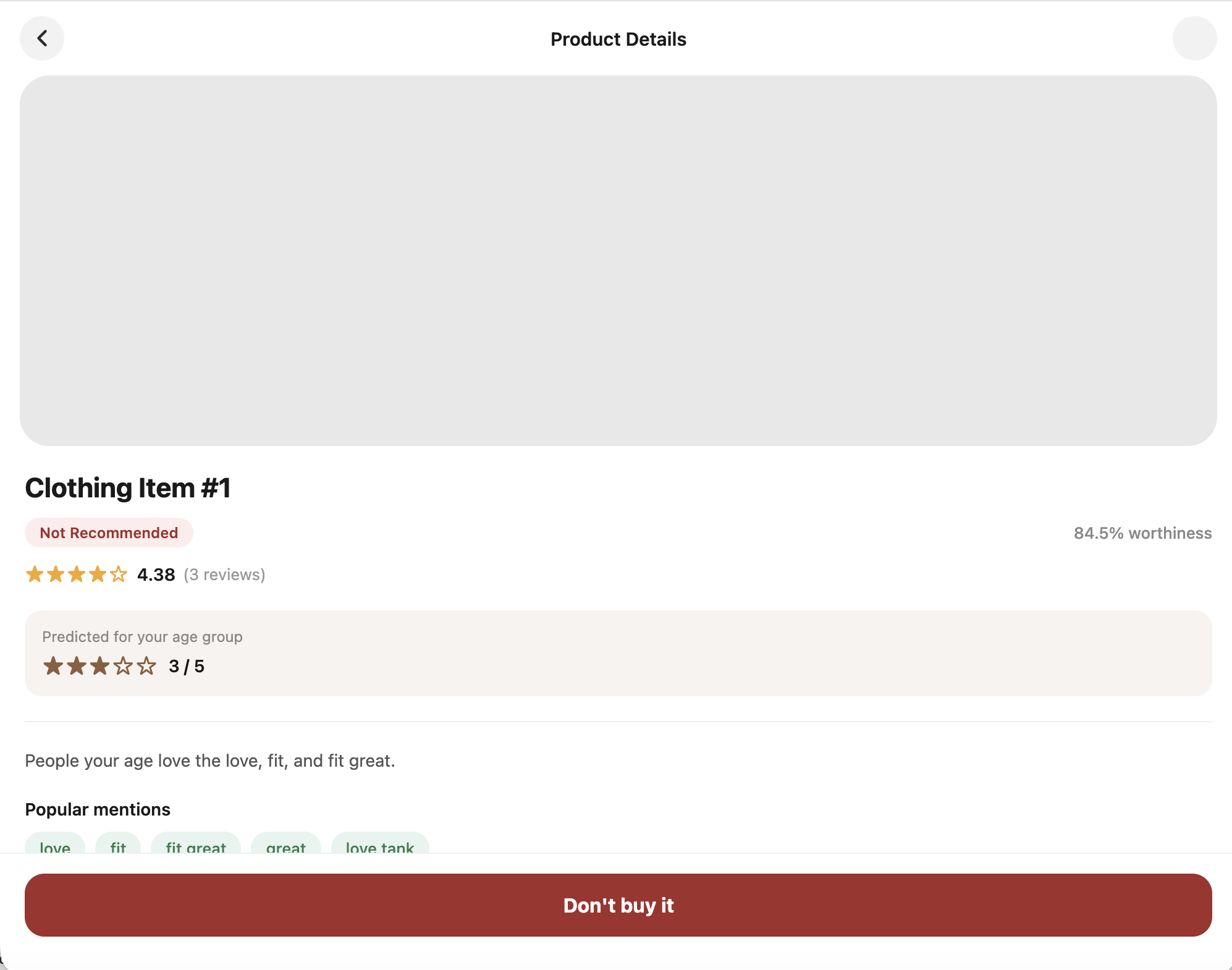
Our app uses a large database of clothing reviews to extract key insights about products and predict how much a user is likely to enjoy an item. It estimates:
- The likelihood a user will enjoy the product
- How strong of a connection they may have with it
- The user’s predicted rating
Users can also scan product barcodes directly from their phone camera to instantly access personalized product insights tailored to their age demographic.
How it works/how we built it
Raw review text is messy. Reviews contain punctuation, filler words, capitalization differences, and unnecessary characters, so before any analysis can happen, the text must be cleaned and simplified. For example, a review like:
“These pants fit really nice. The fabric material is soft and breathable”
would be reduced to keywords such as:
- “really nice”
- “soft”
- “breathable”
Common stopwords like “the” and “is” are removed entirely.
We then use TF-IDF (Term Frequency–Inverse Document Frequency) to measure how important certain words are within a review compared to the rest of the dataset. Term frequency measures how often a word appears in a review, while inverse document frequency measures how rare that word is across all reviews. Combining these values allows the model to identify words that are especially meaningful or distinctive.
These processed text scores are then fed into our machine learning models. Products are classified as either “buy” or “skip,” and the models learn which word patterns most accurately predict those outcomes. Different features are assigned different internal weights based on their predictive value.
After training, the models are tested on unseen product reviews to determine whether they generalize well or simply memorize the training data. Strong performance on training data but poor performance on new data is a sign of overfitting, which we worked to avoid.
- Preprocessing Pipeline: Built a custom NLTK pipeline to clean and lemmatize thousands of clothing reviews.
- Feature Engineering: Combined high-dimensional TF-IDF text vectors with demographic signals using sparse matrix stacking (
hstack). - Model Architecture: Developed multiple models, including Logistic Regression for classification and Linear Regression for predicting nuanced rating behavior.
- Categorical Binning: Grouped users into age categories such as “Young Adult,” “Middle Age,” and “Senior” to capture life-stage sentiment trends.
We built the frontend using Expo, which provided convenient tools like camera integration for barcode scanning and rapid mobile development.
Challenges we ran into
One of our biggest challenges was improving performance on our age-based prediction system, specifically our Demographic Sentiment Synthesis feature. Initially, we believed that an NLP model trained on peer demographic text would outperform a simple product average. However, validation testing showed an improvement of -48.33%, suggesting that overall product quality often outweighs demographic-specific sentiment patterns.
We also ran into technical issues during mobile development. Expo SDK 56 was not fully supported on our test devices, so we had to downgrade to SDK 54. Figuring that out took much longer than expected.
Accomplishments we’re proud of
- Achieving over 98% accuracy in binary sentiment detection (Positive vs. Negative)
- Creating a “Cascading Fallback” recommendation system that still provides useful suggestions even when demographic-specific data is limited
- Identifying and removing suspected bad or noisy data from the dataset
- Successfully building and deploying a functional mobile app
What we learned
We learned that data science is just as much about disproving hypotheses as it is about confirming them. While our NLP model performed extremely well at understanding individual review sentiment, we discovered that simple averages are surprisingly difficult to outperform when predicting general product quality.
We also learned that demographics do matter in subtle ways. “Senior” and “Young Adult” groups showed statistically significant differences in how they discussed topics like fabric quality and fit, reinforcing the idea that shopping preferences vary meaningfully across age groups.


Log in or sign up for Devpost to join the conversation.