-
-
Human frequency capture
-
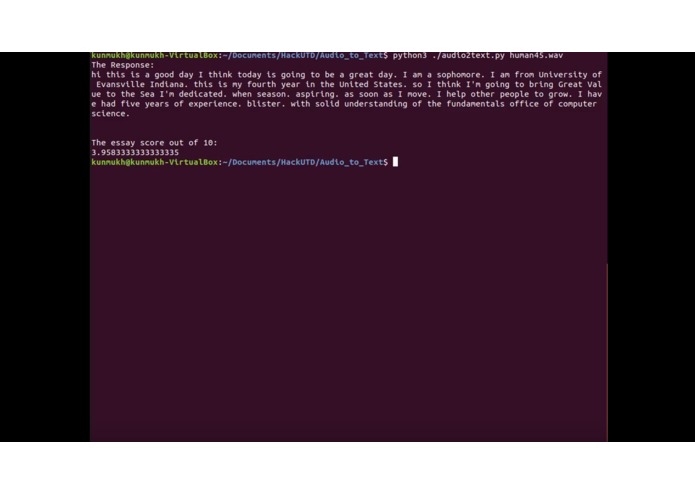
rating of text
-
playing of audio
-
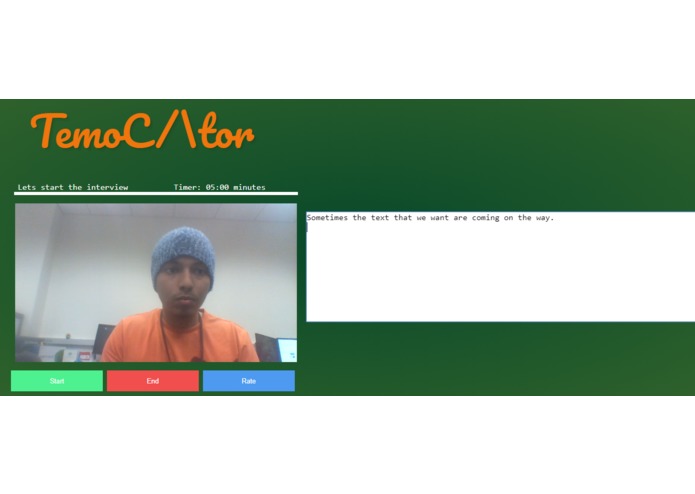
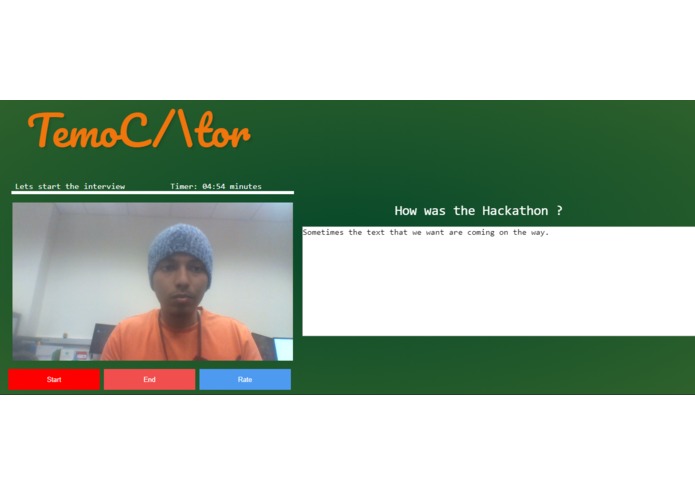
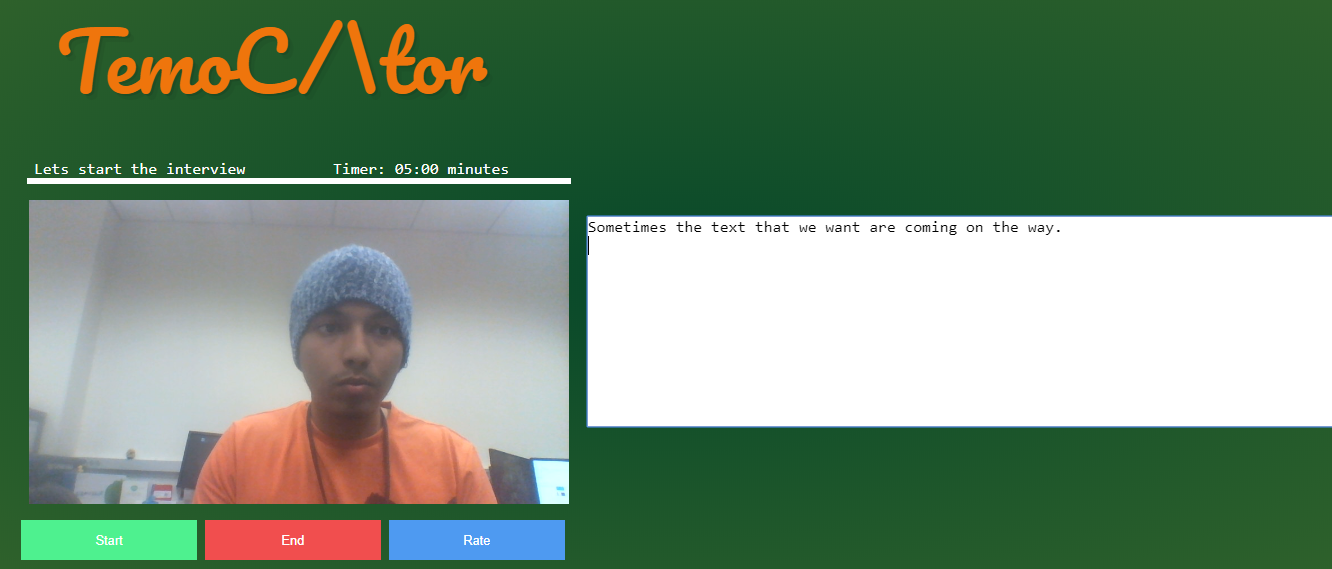
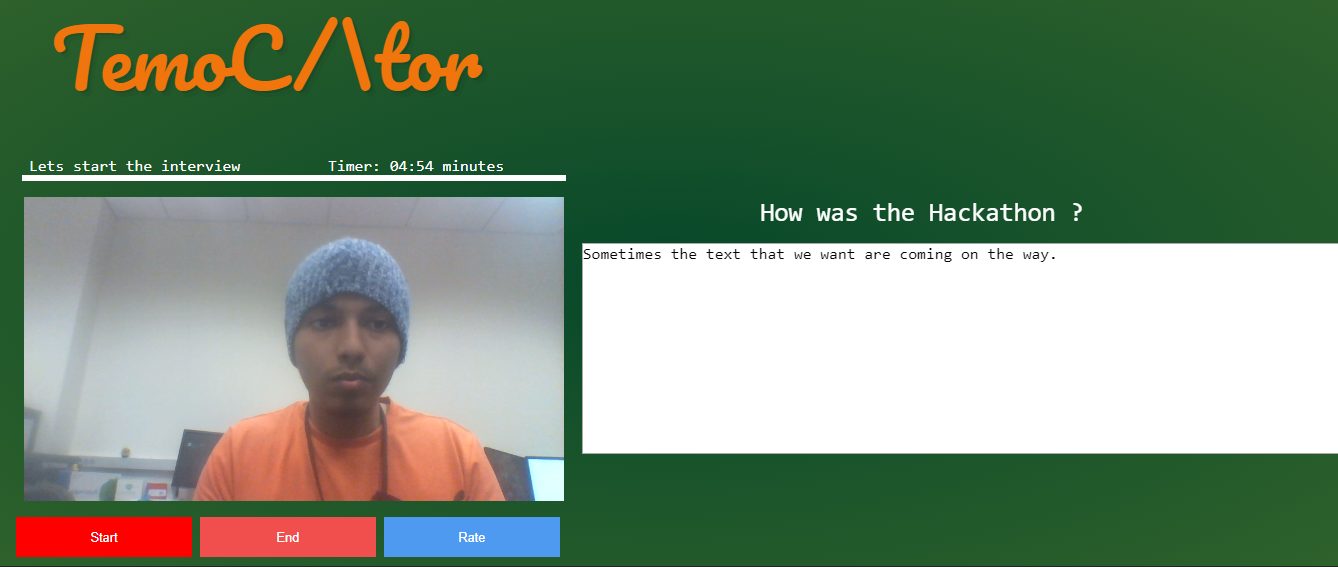
UI demo
-
-
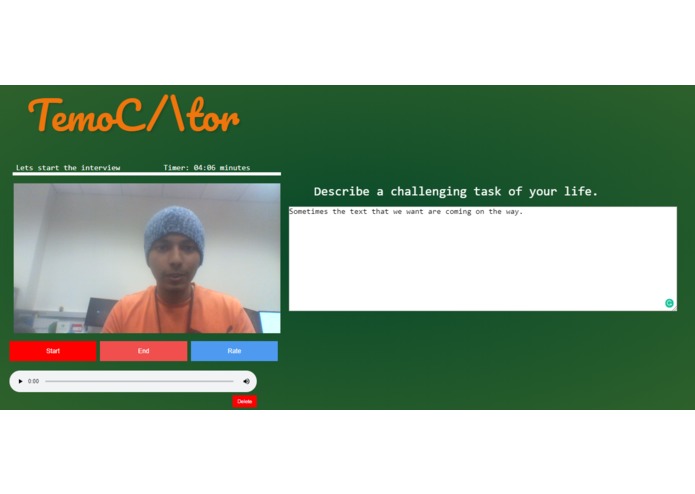
audio recording
-
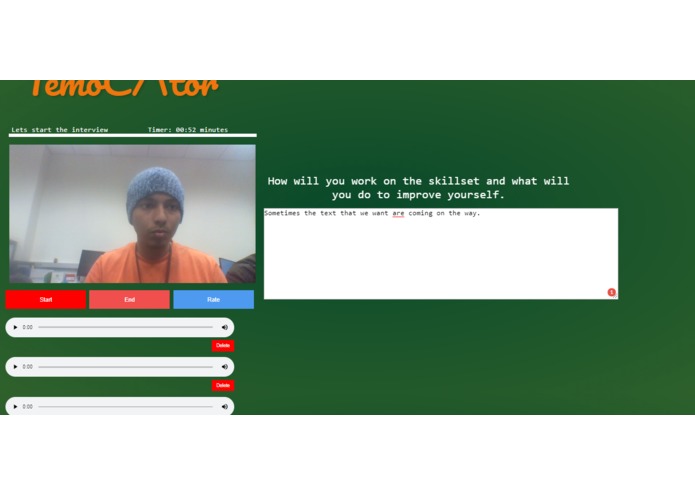
multiple audio file
Inspiration
Everyone knows that there are many ways to succeed in an interview. Every successful person knows that the most important one is practice. Properly setting up a mock interview is difficult. You must select a knowledgeable interviewer, find the questions, review your answers, and much more. So to help ourselves and others we decided to make an AI which could do this entire process for us and highlight areas of improvement.
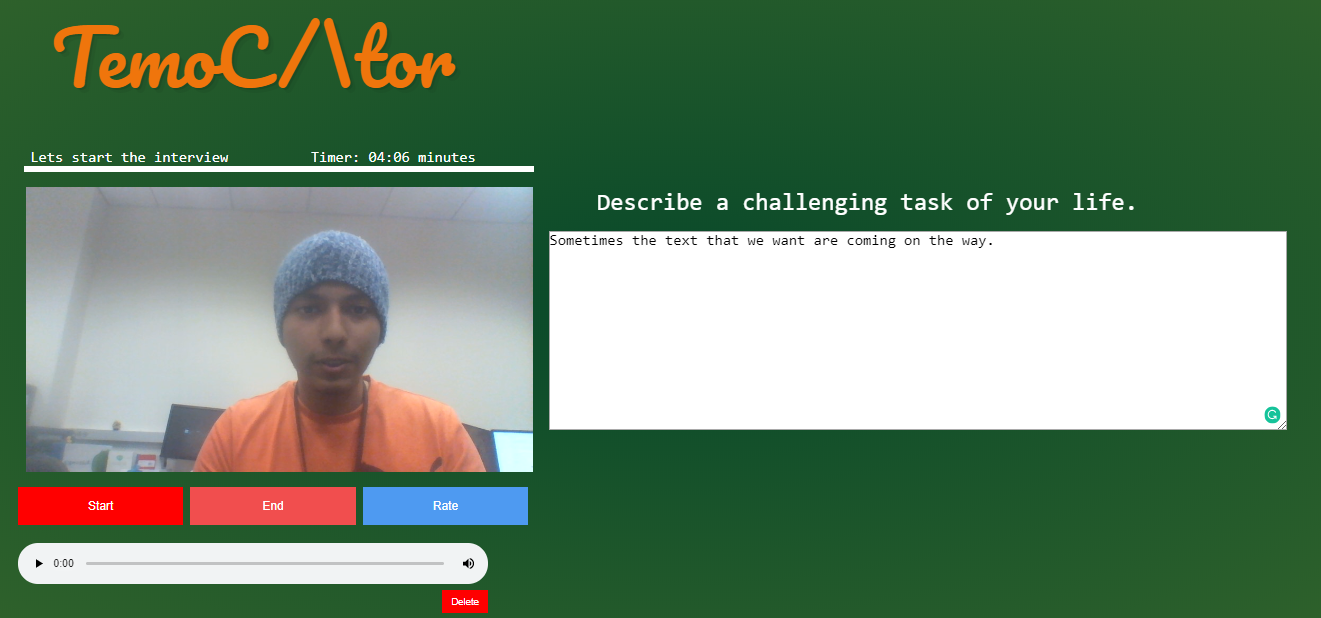
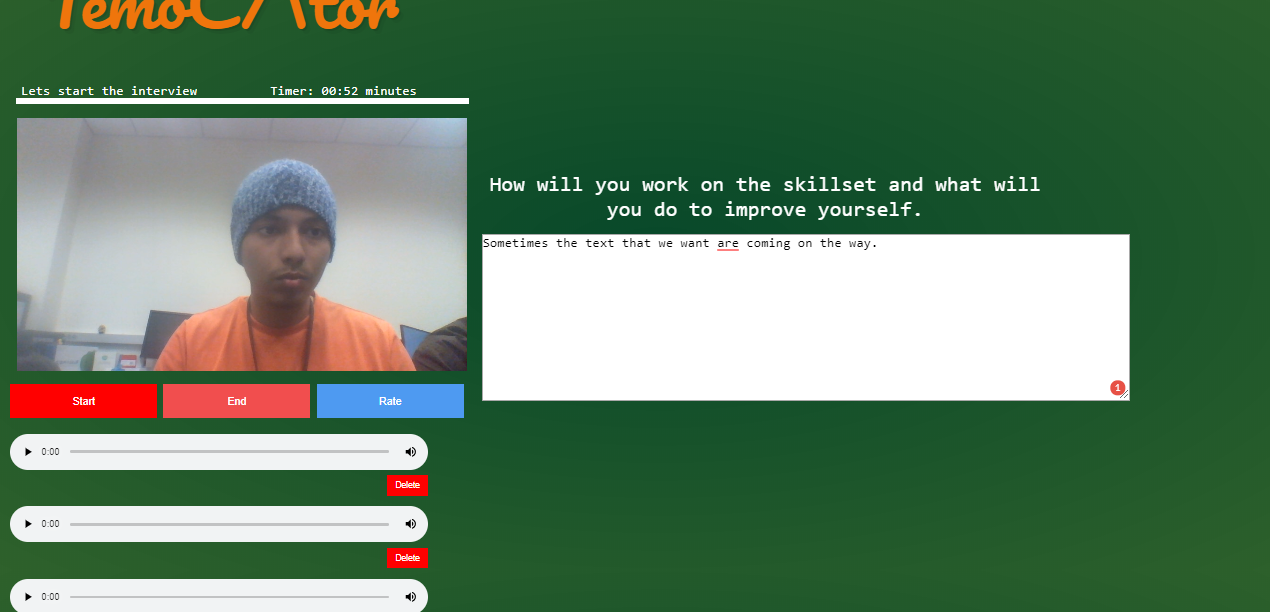
What it does
TemoCtor is an interview preparation AI. Which uses keywords to grade responses to select questions which are likely to be used in an actual interview for a real life position. It provides interviewees with critical question by question grading which signify areas of improvement. This improvement can significantly impact the outcome of the real interview.
How we built it
We used python Flask framework for the web application and streaming media files into the server. Natural Language Processing to tap in tokenization into the text grading section. Our grading data set was prepared from collecting various Q&A session from various sources like Kaggle. The grading system along with the whole interview process is pipeplined using various API's like speech to text.
Challenges we ran into
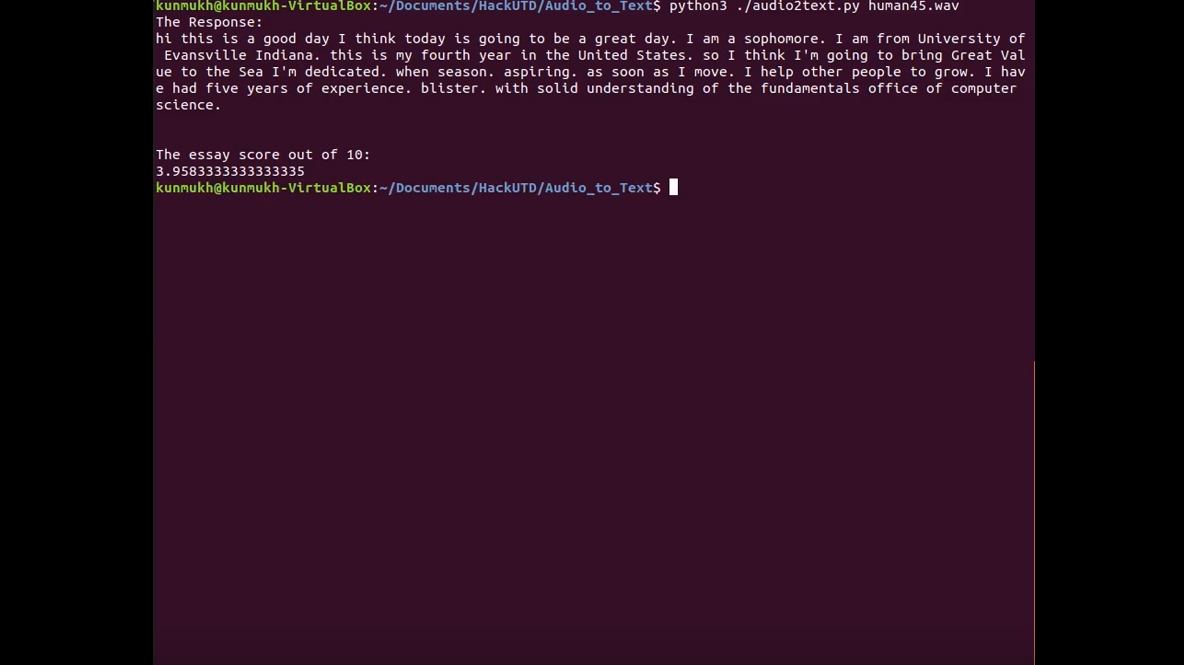
Mastering new techniques and expending many hours in a single stretch were some small problems.The major ones were creating and processing a data set of over 3000 entries and converting human voices, recorded in a 45 second audio file, into text.
Accomplishments that we're proud of
We successfully stepped up interview preparation by creating a testing ground to hone your interview prowess. We have effectively created a service for the students to help them prepare for the future. We meticulously inetgratd the google cloud api to recognize human voice as well as process larger files. Successfully trained LSTM model on our own dataset. Using this procedure we were able to get a rating.
What we learned
We learned that the application has numerous use-cases one of which is speech to text and automated grading using a NLP corpus. We learned the inter-connectivity between the different front end api's with a working deep learning model in the backend. We learned how to convert large audio files into smaller audio files for processing as well as recognize machine voice which are devoid of human language frequency.
What's next for TemoCtor
We want to add more functionality to proctor. This would include complete automation of the interview process which would allow companies to rely only on proctor to pick recruits. We would also include modified interviews for language barriers, and accents.
Built With
- bootstrap
- css
- flask
- gensim
- google-cloud
- google-web-speech-api
- html
- javascript
- keras
- nltk
- pydub
- restapi
- sklearn
- tensorflow
- websockets



Log in or sign up for Devpost to join the conversation.