


TellMe
Inspiration
Running a small e-commerce business shouldn't require a data science degree. While helping a friend manage their online store, I watched them struggle with analytics dashboards - revenue trends, ROAS percentages, conversion funnels. The numbers were all there, but what did they mean?
Most business owners don't have time to decode metrics. They need answers, not charts. That's why I built TellMe: an AI voice agent that doesn't just show you your numbers - it explains them to you, in plain English, like having a data analyst on speed dial.
What it does
TellMe transforms your business metrics into conversational insights:
Click. Listen. Understand.
- Voice-Powered Analytics: Click any metric card, and TellMe narrates what's happening with your data
- Context-Aware Explanations: Not generic responses - actual analysis of YOUR numbers and trends
- Instant Understanding: Revenue up 12%? ROAS at 5.0? TellMe explains what that means for your business
- Built for Busy Founders: Access insights while driving, cooking, or away from your desk
Real-World Example
Instead of staring at: Revenue: $125,000 | ROAS: 5.0 | Conv: 3.2%
You hear: "Your revenue hit $125,000 this month, up 12% from last period. Your return on ad spend of 5.0 means you're getting five dollars back for every dollar spent on marketing - that's excellent performance. Your conversion rate of 3.2% is strong and consistent with last month's trends."
How we ( Me and my AI buddies) built it
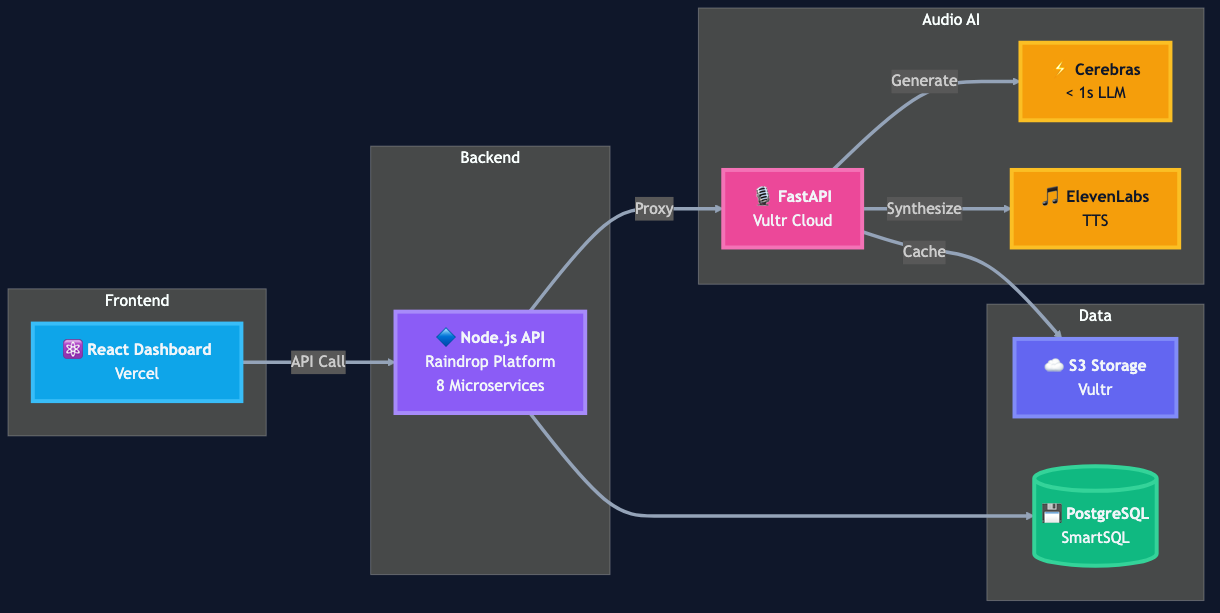
Architecture
Frontend (Vercel):
- React 18 + TypeScript + Vite
- TailwindCSS for responsive design
- Recharts for data visualization
- Global Audio Manager for seamless playback
Backend API (Raindrop Platform):
- Node.js/Express microservices architecture
- 8 integrated services: analytics, API gateway, auth, insights, user management
- PostgreSQL via SmartSQL
- WorkOS authentication
Audio Intelligence Service (Vultr Cloud):
- Python FastAPI application
- Dockerized deployment on Ubuntu Server
- Exposed securely to the internet via Cloudflare Tunnel
- Intelligent caching layer
- Health monitoring
AI Pipeline:
- Cerebras Inference: Ultra-low latency LLM narration (<1s)
- ElevenLabs: Professional text-to-speech synthesis
- Optimized workflow: Cerebras generates text fast enough for ElevenLabs to synthesize without perceived delay
Storage (Vultr Object Storage):
- S3-compatible storage for audio files
- Fixed narrations (pre-generated)
- Dynamic narrations (on-demand)
- Instant retrieval on repeated requests
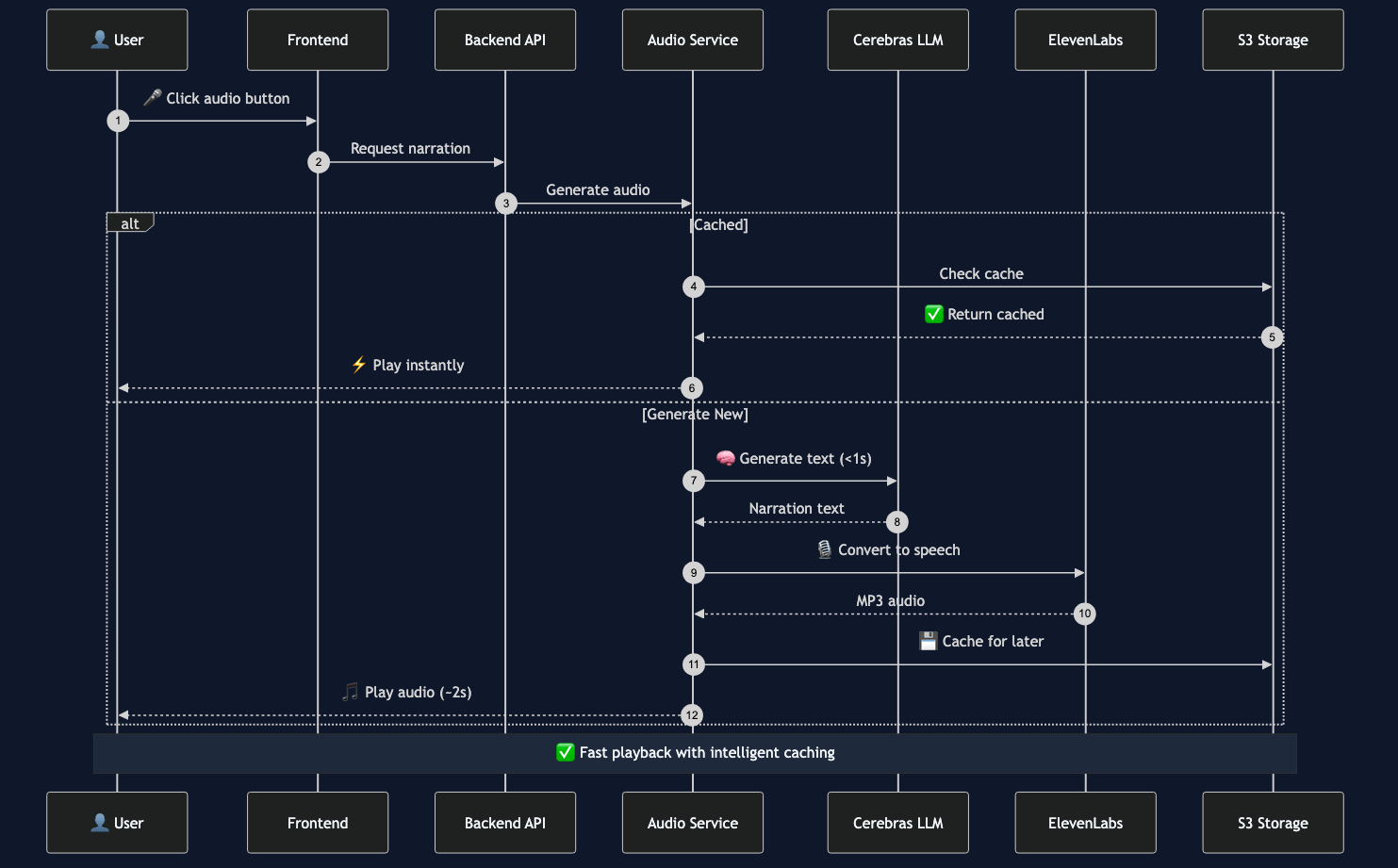
Technical Flow
User clicks audio button
↓
Frontend → Backend API Gateway (Raindrop)
↓
Backend → Audio Service (Vultr)
↓
Cerebras generates contextual narration (<1s)
↓
ElevenLabs synthesizes speech
↓
Cached in Vultr Object Storage
↓
Streamed to user
Challenges we ran into
Latency Management: Getting audio generation fast enough for real-time use
- Solution: Cerebras ultra-low latency inference + intelligent caching
Context Awareness: Making narrations relevant to specific data, not generic
- Solution: Structured prompts with component-specific context
Audio State Management: Preventing overlapping narrations across components
- Solution: Global Audio Manager with centralized playback control
Multi-Cloud Coordination: Orchestrating Vercel, Raindrop, and Vultr
- Solution: Clear separation of concerns with API gateway pattern
Storage Optimization: Balancing storage costs vs. generation speed
- Solution: Hybrid approach with fixed + dynamic audio caching
Accomplishments.
- Sub-Second Latency: From click to narration in under 2 seconds (including TTS)
- Context-Aware AI: Each narration is tailored to the specific metric and data
- Production-Ready: Full authentication, error handling, monitoring
- Multi-Cloud Excellence: Seamlessly integrated Raindrop, Vultr, ElevenLabs, and Cerebras
- Solo Development: Entire full-stack application built by one developer
- Real-World Impact: Solving an actual problem I witnessed firsthand
Thoughts on the whole Process
- Cerebras is FAST: The low-latency inference made real-time narration possible
- Voice changes everything: Audio makes complex data accessible to non-technical users
- Caching matters: Smart caching turns slow operations into instant responses
- Architecture scales: Microservices approach allowed independent optimization
- User experience over features: One well-executed feature beats ten mediocre ones
- MCP is powerful: Model Context Protocol enabled seamless integration of multiple AI tools
What's next for TellMe
Short-term (Next 30 days)
- Interactive conversations: "Tell me more about that trend"
- Custom voice selection
- Multi-language support
- Mobile app (iOS/Android)
Long-term Vision
- Predictive insights: "Based on trends, expect X next month"
- Anomaly detection: "This metric is unusual - here's why"
- Integration with Shopify, WooCommerce, Google Analytics
- Team collaboration features
- Voice-first business intelligence platform
- Industry-specific agents (e-commerce, SaaS, content)
- API for developers to add voice narration to their apps
- Enterprise features: custom models, on-premise deployment
Try it out
Live Demo: https://tell-me-raindrop.vercel.app
GitHub: https://github.com/anush-data-portfolio/Tellme
Tech Stack
- Frontend: React, TypeScript, Vite, TailwindCSS
- Backend: Node.js, Express, PostgreSQL
- Audio Service: Python, FastAPI
- AI/ML: Cerebras Inference, ElevenLabs TTS
- Infrastructure: Raindrop Platform, Vultr Cloud, Vercel
- Auth: WorkOS
- Storage: Vultr S3-Compatible Object Storage
- Development Tools: Copilot Code (AI), Metabob MCP (Code Quality)
Development Quality Assurance
Throughout the development of TellMe, I used Metabob MCP (Model Context Protocol) for AI-powered code analysis:
- Static Code Analysis: Continuous scanning for potential bugs and issues
- Security Scanning: Identification of security vulnerabilities
- Code Quality Metrics: Maintaining high standards across the codebase
- Best Practices: Automated recommendations for code improvements
This combination of Copilot for development and Metabob for quality assurance ensured a robust, secure, and maintainable codebase throughout the hackathon.
Built by
Anush Krishna V (@anushkrishnav)
Solo developer | Full-stack engineer | AI enthusiast
Built for The AI Champion Ship Hackathon 2025
Competition Categories
- Best Voice Agent (ElevenLabs): Professional voice narration for business analytics
- Best Ultra-Low Latency App (Cerebras): Sub-second LLM response times
- Best AI App by a Solopreneur: Complete full-stack development by one person
- Best Small Startup Agents: Specifically designed to help small business owners
TellMe: Because your data should speak to you, not just at you.
Built With
- elevenlabs
- vultr


Log in or sign up for Devpost to join the conversation.