-
-
Let's talk a bit about AI text detection...
-

This is TELL: The AI Text Detector You Don't Have To Trust
-
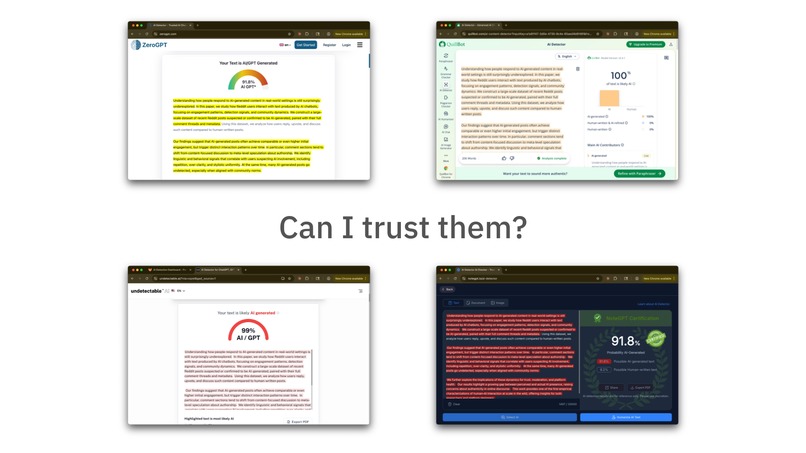
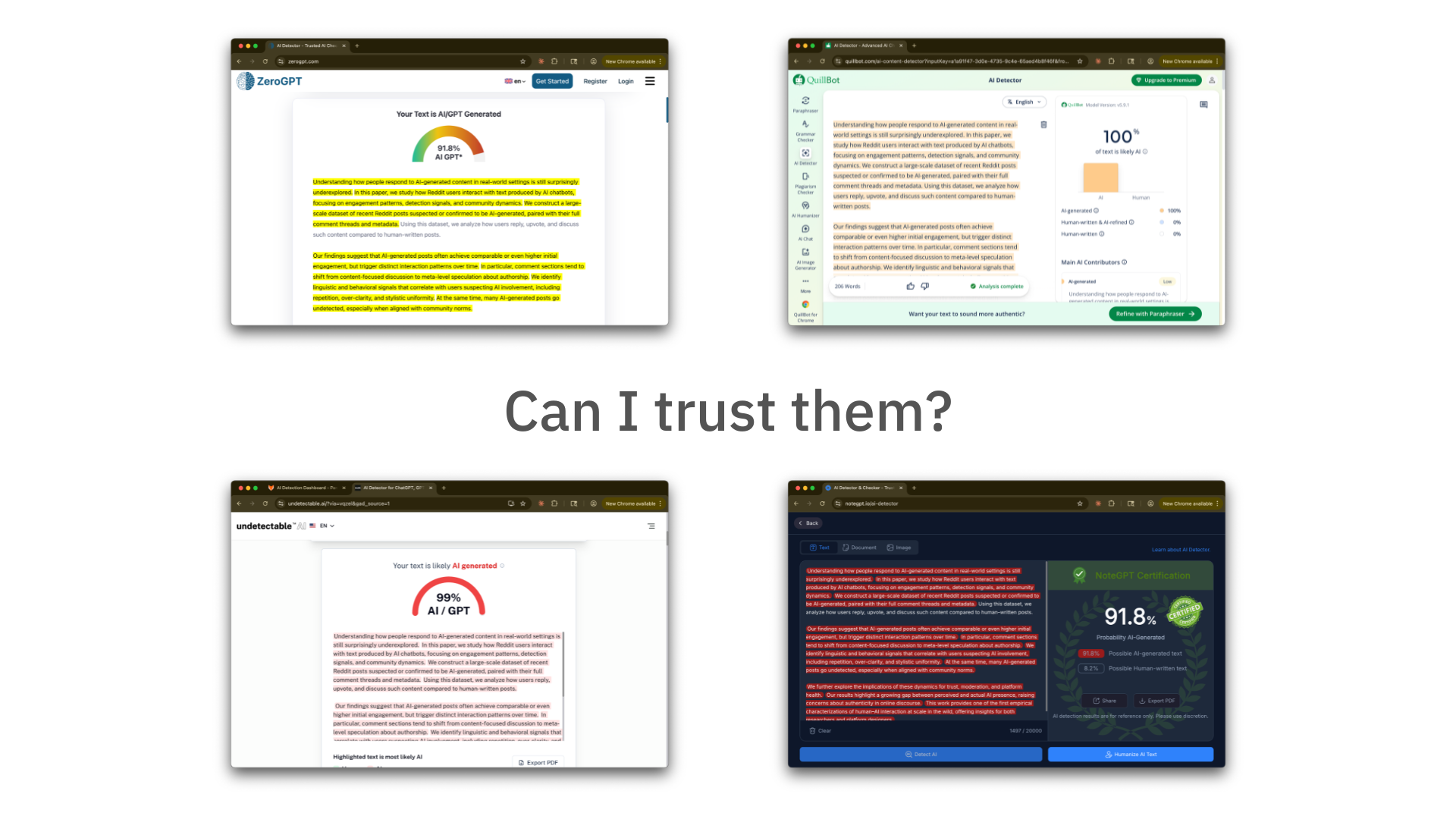
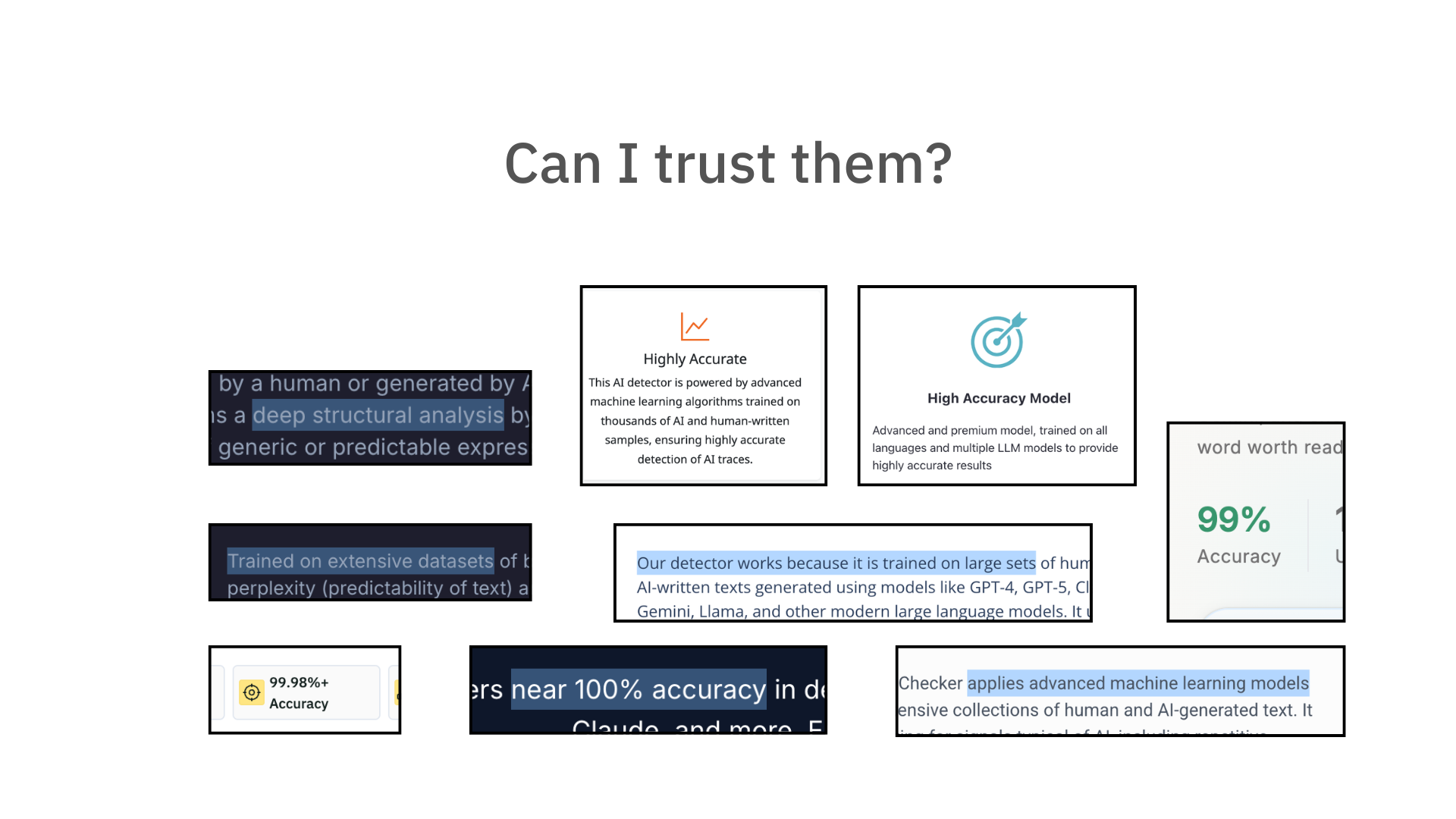
Take a look at most AI Text detectors: they give you a score...
-
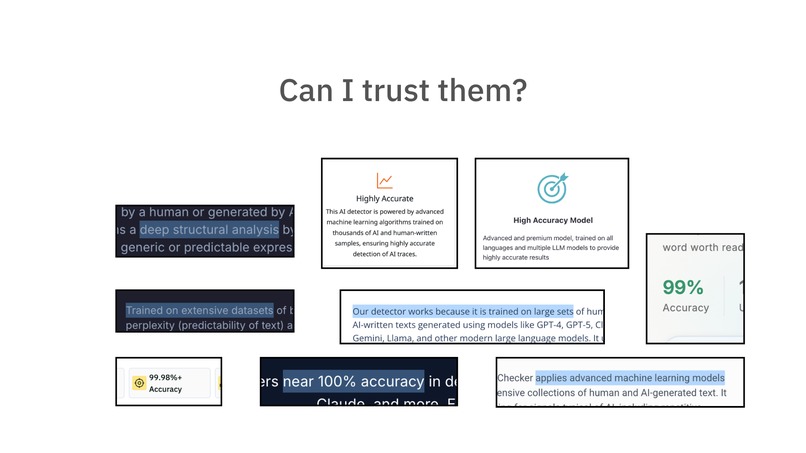
...so you have to trust that their score is "reliable"
-

Problem is, it's not - it fails. And now people think that detectors don't work at all.
-
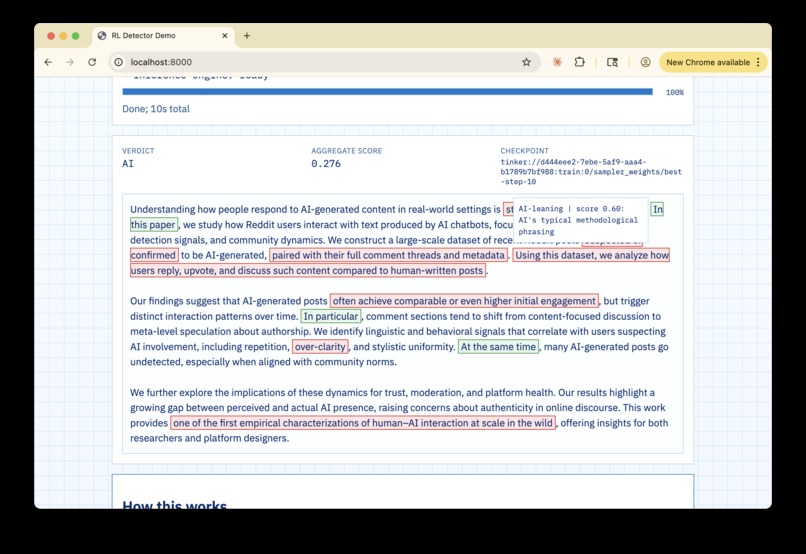
TELL does things differently. It doesn't focus on a score; instead, it focuses on you coming up with your own conclusions.
-
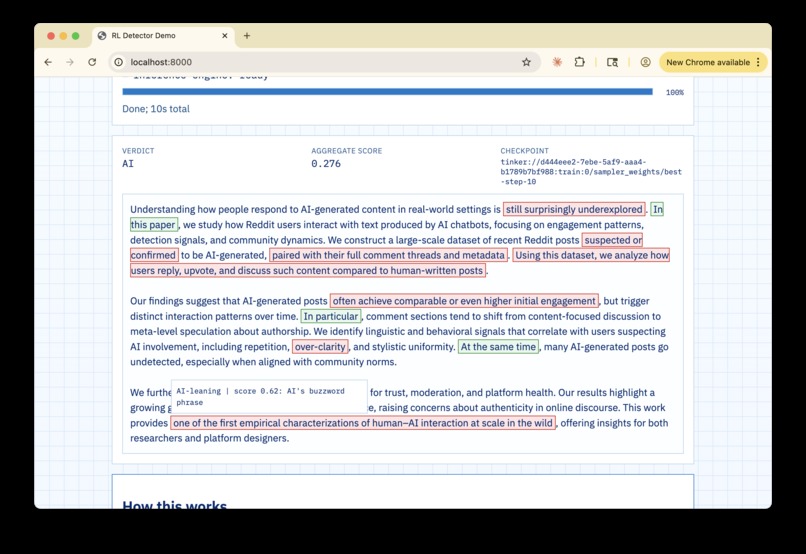
That how you can trust TELL: because you never actually have to.
-
(For technical details, refer to the GitHub repo)


Inspiration
Why should we trust a detector that doesn't explain itself?
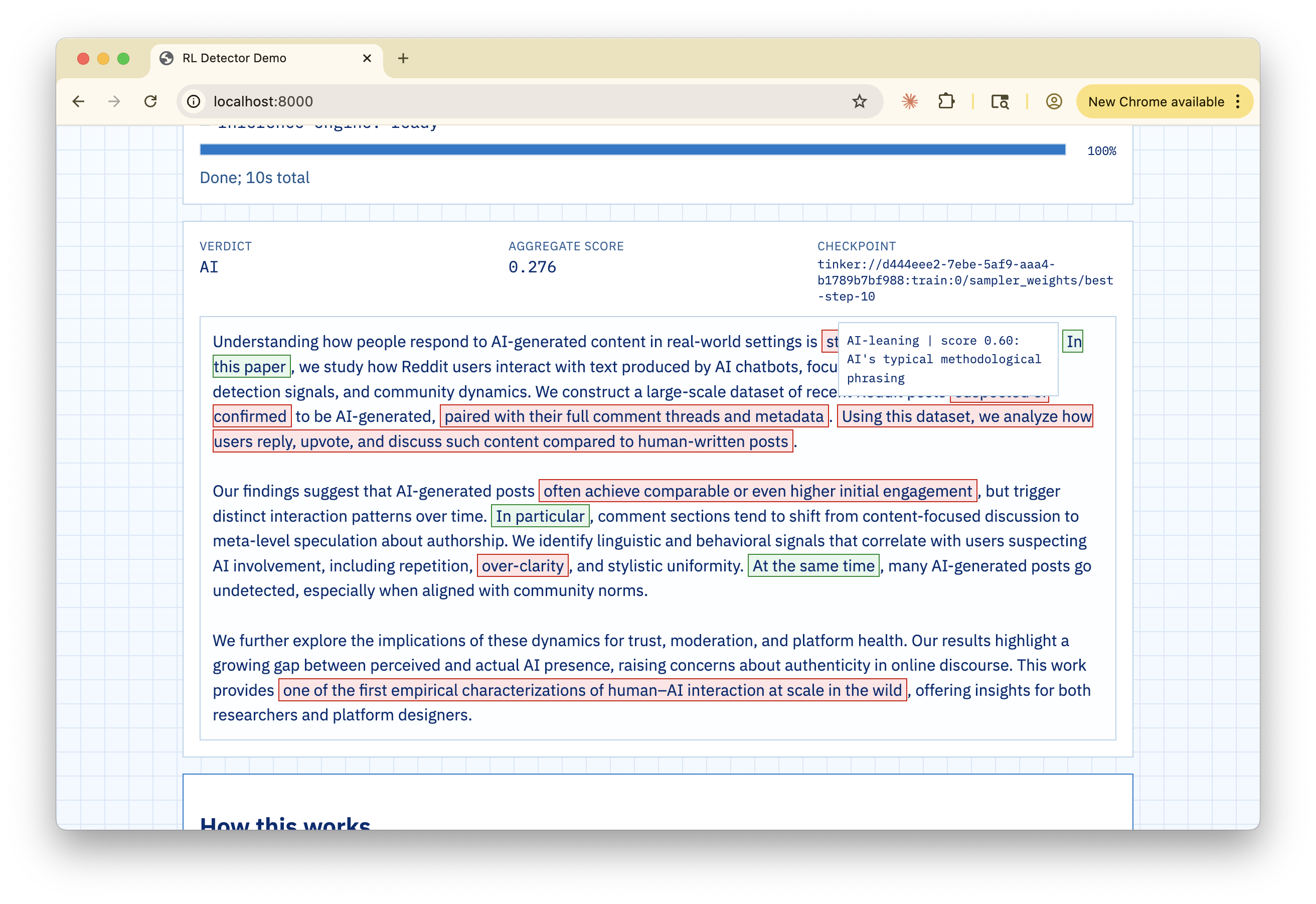
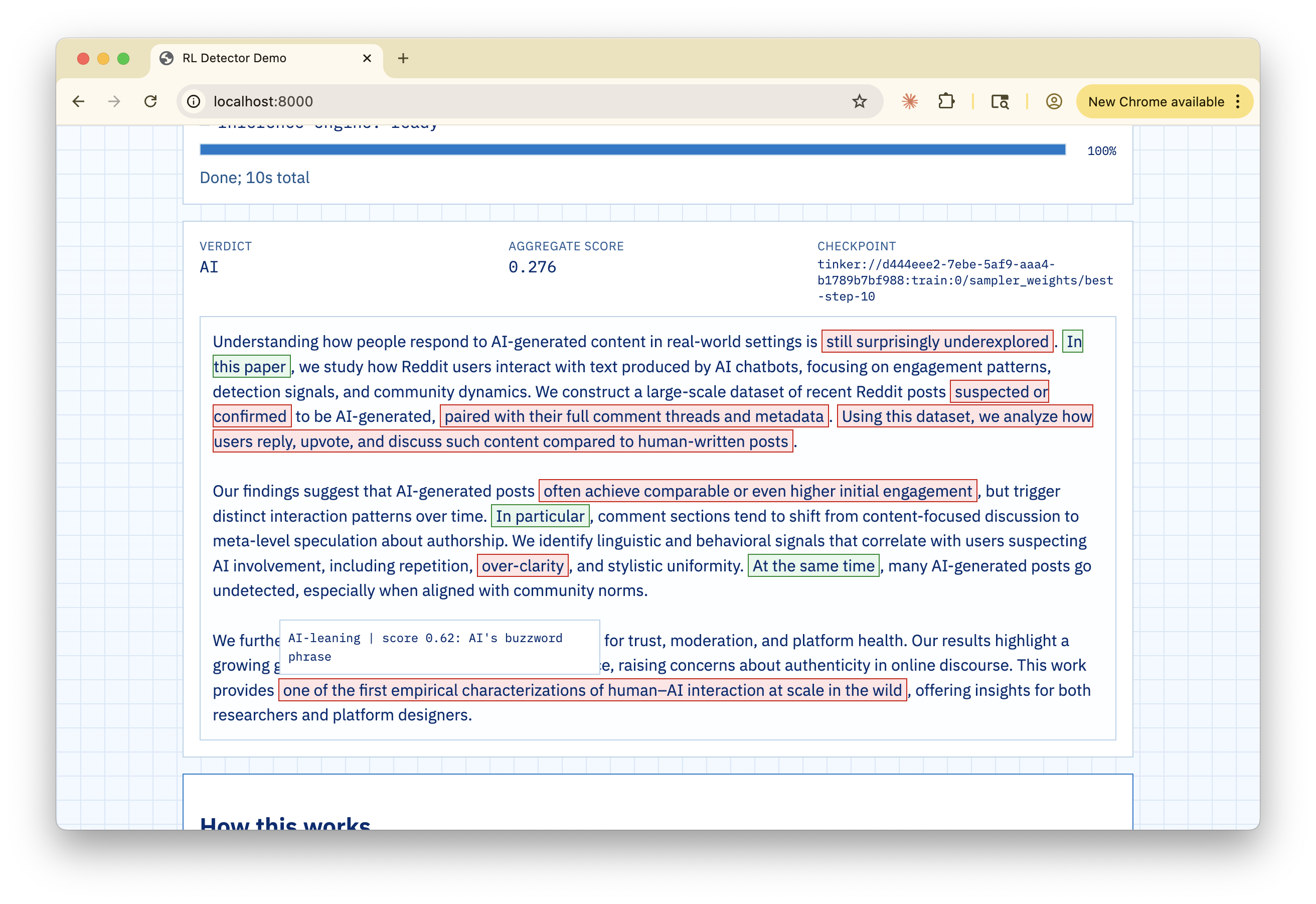
My idea for TELL came because I'm frustrated that AI detectors are just "black boxes." They tell you "this is AI" or "this is human," but they never tell you why (which is the most important part because you can't accuse anyone without a reason!).
For a student, being accused by a machine without proof is a nightmare because you can't even defend yourself (it happened to me). So I wanted to build something that acts more like a teacher, pointing at specific phrases and saying "this looks formulaic" or "this transition is too perfect."
Basically, I wanted to move from "trust me" to "here is the evidence, now you decide."
How TELL works
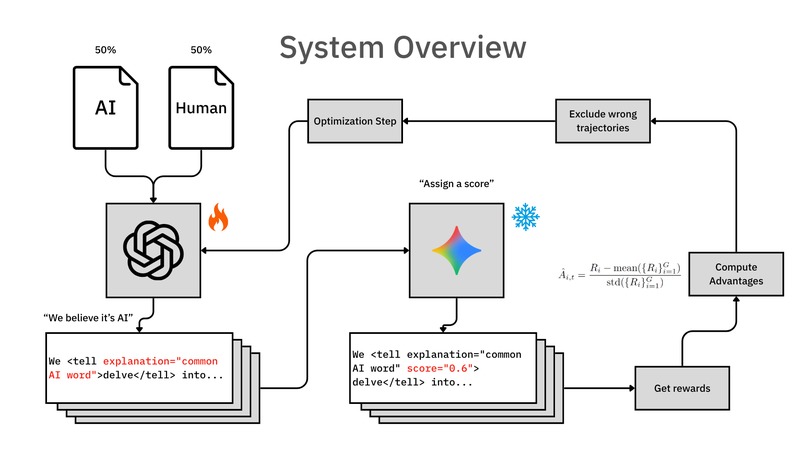
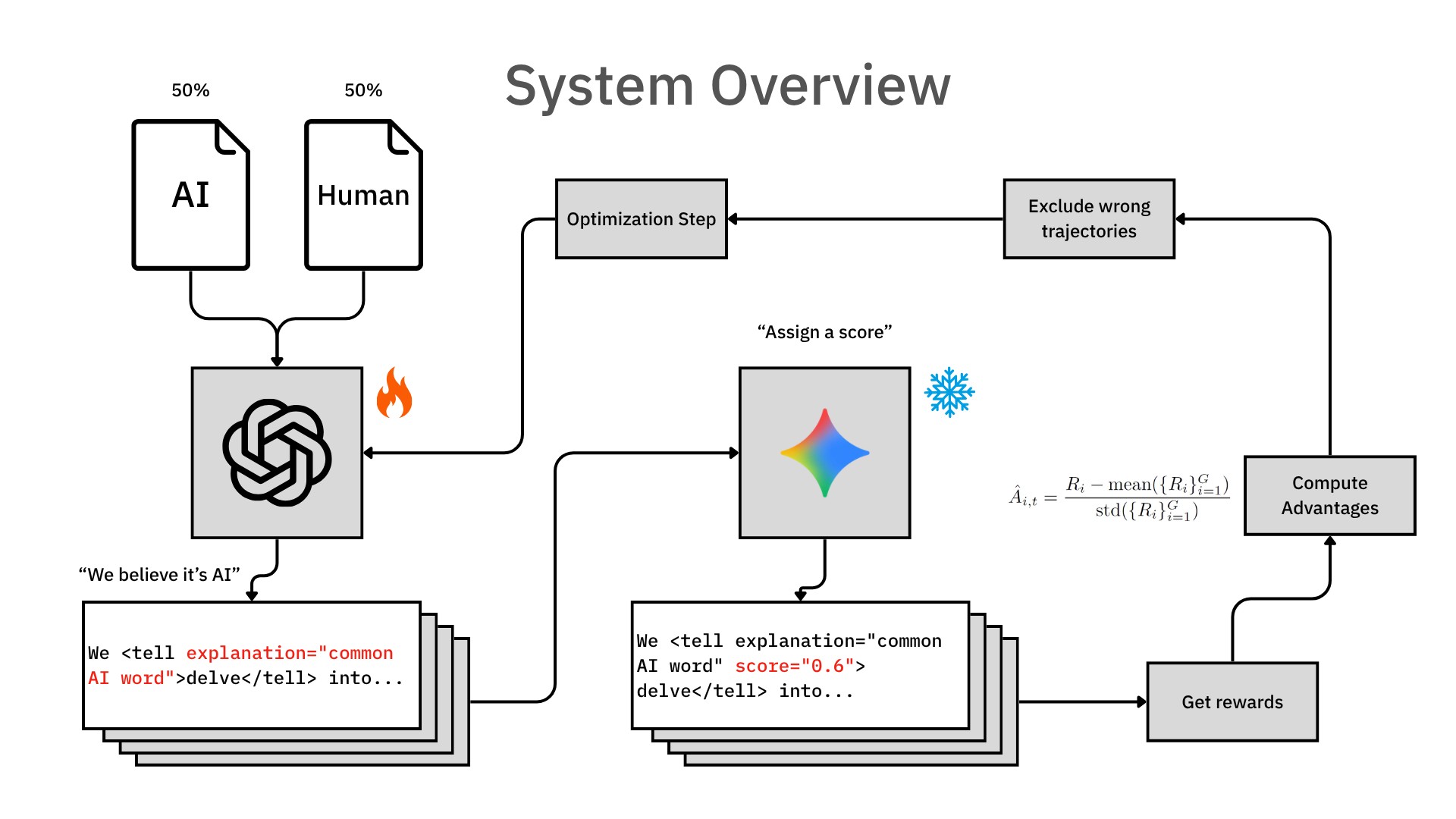
I designed a pipeline that focuses on learning "what's an AI tell". Giving a score is secondary. Current systems try to guess the label directly, but I decided to break it down into two steps:
- The Policy Model (The "Writer"): I trained a model that acts like a highlighter. It reads the raw text and wraps specific spans in
<tell>tags. It also writes a short explanation for each one. This was the hardest part because the model has to reproduce the original text exactly while adding the tags; if it changes even one letter, the whole thing fails. - The Frozen Scorer (The "Judge"): After the tags are in place, we use a separate, frozen model to score them. A score of
1means it's definitely AI, and-1means it's definitely human. By separating the "tagging" from the "scoring," I make the system much more reliable and harder to reward hack (if the tagger also scored, then it could produce bullsh*t reasons and still get high rewards).
So how do I train this? I use a reward system with a "format gate." If the model messes up the tags or changes the text, it gets zero reward. But if it follows the rules, I reward it based on how well its average score matches the real label. This creates a pressure to be both acurate and honest.
The Technical Stack
The project is built using Python 3.11 and managed with uv (which is much faster than pip, honestly).
- Training: I used GRPO for the training loop, pulling data from a dataset of annotated scientific and human abstracts.
- Infrastructure: I use Tinker for sampling and Google AI Studio/DeepInfra (as a backup) to run the frozen scoring model.
- UI: I built a small web interface using FastAPI so you can see the highlighted HTML in real time instead of just reading JSON in a terminal.
Challenges I ran into
- Text Fidelity: In the beginning, the model kept "hallucinating" small changes in the sentences when it added the tags. It took many iterations to get the reward function right so the model learned that keeping the original text is the most important thing.
- OOD Generalization: Detectors usually fail when they see a new language. I'm working on using Z-scoring to normalize results, but this is still a work in progress. Also, finding the right "reasoning effort" for the sampling was a bit of a trial and error process.
Accomplishments that I'm proud of
- It is actually interpretable: You can click on a sentence and see exactly why the model thinks a human wrote it.
- The "Frozen" Logic: Using a separate model for scoring prevents the policy from "cheating" by just picking words that it knows will trigger a high score.
- It actually works: While no AI detector is perfect, the system that I built is actually able to learn what is an AI tell completely on its own (I didn't tell it anything). And the predictions that it generates actually make intuitive sense.
- It solves a real issue: I see lots of talk about how AI text detection is broken but nobody does anything to fix it. I think this is a step in the right direction.
What's next
I want to expand this to more languages and domains. Right now it works best in English scientific abstracts, but since I'm Spanish, I really want to see how it handles translated text or non-native writing styles. And I expect that most of the tells it's learned are about the scientific abstracts because it's the data that used, so I want to increase generalization.
In short: if a machine is going to judge our writing, the least it can do is explain why.

Log in or sign up for Devpost to join the conversation.