

Inspiration
As we are going through the COVID-19 Pandemic, many people find themselves isolated from family members, friends, and critical healthcare providers. While many tools exist currently to allow for video conferencing, notably Zoom, Facetime, and Google Duo, these applications fail to be effective for a large proportion of the population. I spoke to medical professionals who are doing Telehealth in my local community and found that upwards of 30-40% of patients have trouble with the experience due to poor connection. This often results in lost calls, having to reschedule, or patients moving to cars or public locations without any privacy for a better connection. In some cases, this can lead to a complete inability to conduct Telehealth. We want to solve this problem by employing state of the art techniques for video compression coupled with hardware acceleration inside of mobile devices.
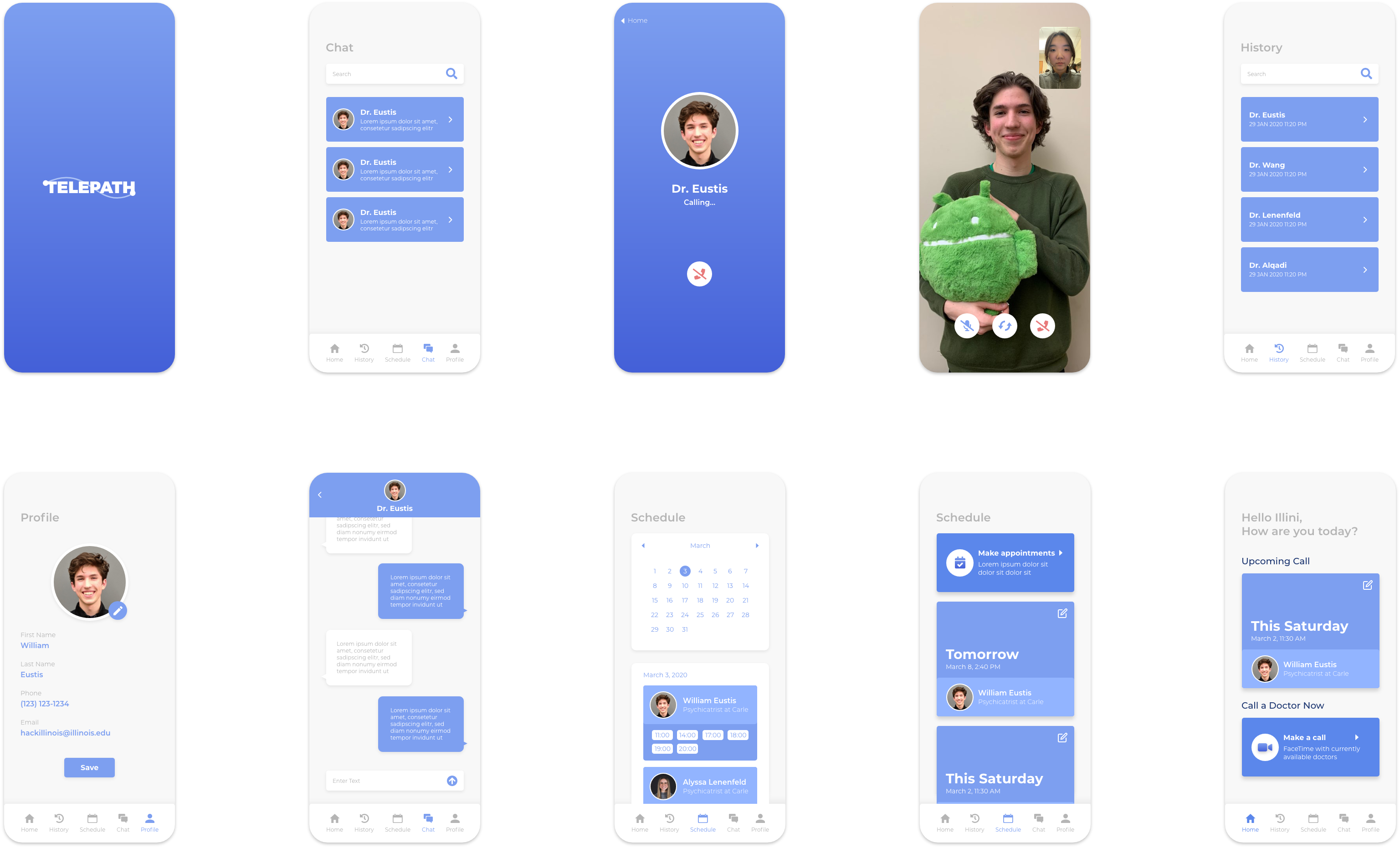
What TelePath does
Our application uses autoencoders, a deep learning architecture that learns to compress input data into a smaller representation (encoder) and then expands that input data back into its original information (decoder). Our app works by running the user's encoder locally on their video (lowering required upload speed) before transmitting as well as running the other caller's decoder (lowering required download speed).
On the user's first time using the app and each time they change environments, they are asked to record a 30 second video of themselves talking. We have the user upload this video to our servers, where we use this data to fine-tune their own personal model to work for their environment the most efficiently as possible. Models are then pruned and quantized to run more efficiently. The model is split into encoder and decoder and stored under their UID in Google Cloud.
When the end user initiates a call, the request the other participant's decoder and their own encoder, which run in parallel during the call to allow anybody to video call whenever they want and wherever they are.
How we built it
- We used Android Studio to write the app, with frameworks such as Fritz and Tensorflow. To train the models, we use Python as well as trainml.ai. We made heavy use of Tensorflow Lite (TFLite) as it accelerates inference on low resource devices and allows this to be possible.
- We built our app framework first, converting wireframes in XML documents for Android Studio. Then, we added routes between pages and the basic functionality of those pages. Next, we built the page to record video, store it as a Bitmap, run it through our models, and view the result on the screen.
- We trained, pruned, and quantized the model using Tensorflow in Python before converting to TFLite to be used on the phone.
Challenges we ran into
- We had surprising trouble converting wireframes to XML documents.
- We were unable to implement peer to peer video calls due to time constraints, so we opted to run an individual user's encoder and decoder locally to simulate the two steps and view their own input.
- We weren't able to build the UI/UX and Backend functionality for the 30-second video training scripts into the app for the final version, but we were able to send and receive pre-recorded videos from Google Cloud using the app.
- None of us were familiar with Android Studio (or Java, for that matter) so there was a significant learning curve.
- We were unable to implement the pruned and quantized models into the application.
Accomplishments that we're proud of
- We brought total inference time (compression, upload, download, decompression) down to 310ms inference and 30ms image processing time on the mobile device with an imperceptible loss. Looking at results from simulated devices, we expect the smaller (2x speedup), pruned (3x speedup), and quantized (3x speedup) models could bring the total inference time down to 34ms. With a total time of 30ms, that would allow for 30fps video.
- We are in love with our GUI! I think our team did a great job with the exception of some minor spacing bugs that are tedious to find :)
- With the above model specs, we were able to achieve 1/16 compression!
What we learned
- We learned a lot about Android Studio; we went from having zero experience (we were planning to use React Native) to building custom pages and activities from scratch.
- Implementing the model into the app was a challenge. We had to learn how to use TFLite, which works with a lot of lower-level implementations than we are used to (A major problem was converting ByteArrays to Bitmaps and vice versa). We learned much about these topics, as well as lots about memory management in Java.
What's next for TelePath
The major tasks looking forward are:
- Building user accounts, storing in Firebase.
- Optimizing model training per-user (same Architecture and training script for everyone, we can make it better)!
- Having multiple models per-user (larger ones for faster phones, smaller ones for faster internet).









Log in or sign up for Devpost to join the conversation.