-
-
breaking news, but this time, it's actually factual
-

alerts when important news stories become available
-

ability to search through articles to find exactly what you're looking for
-

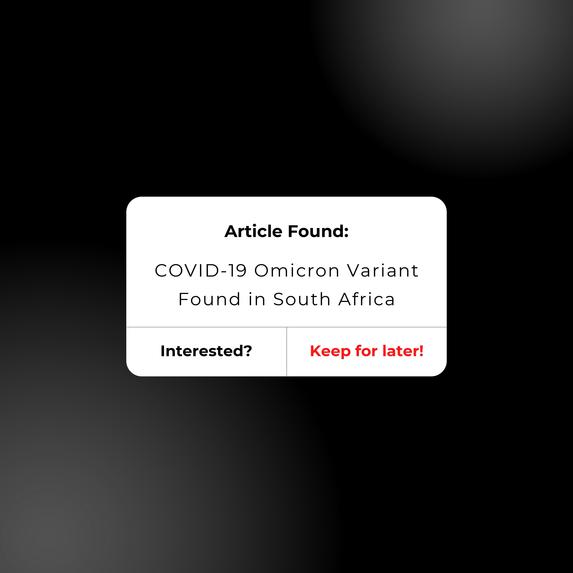
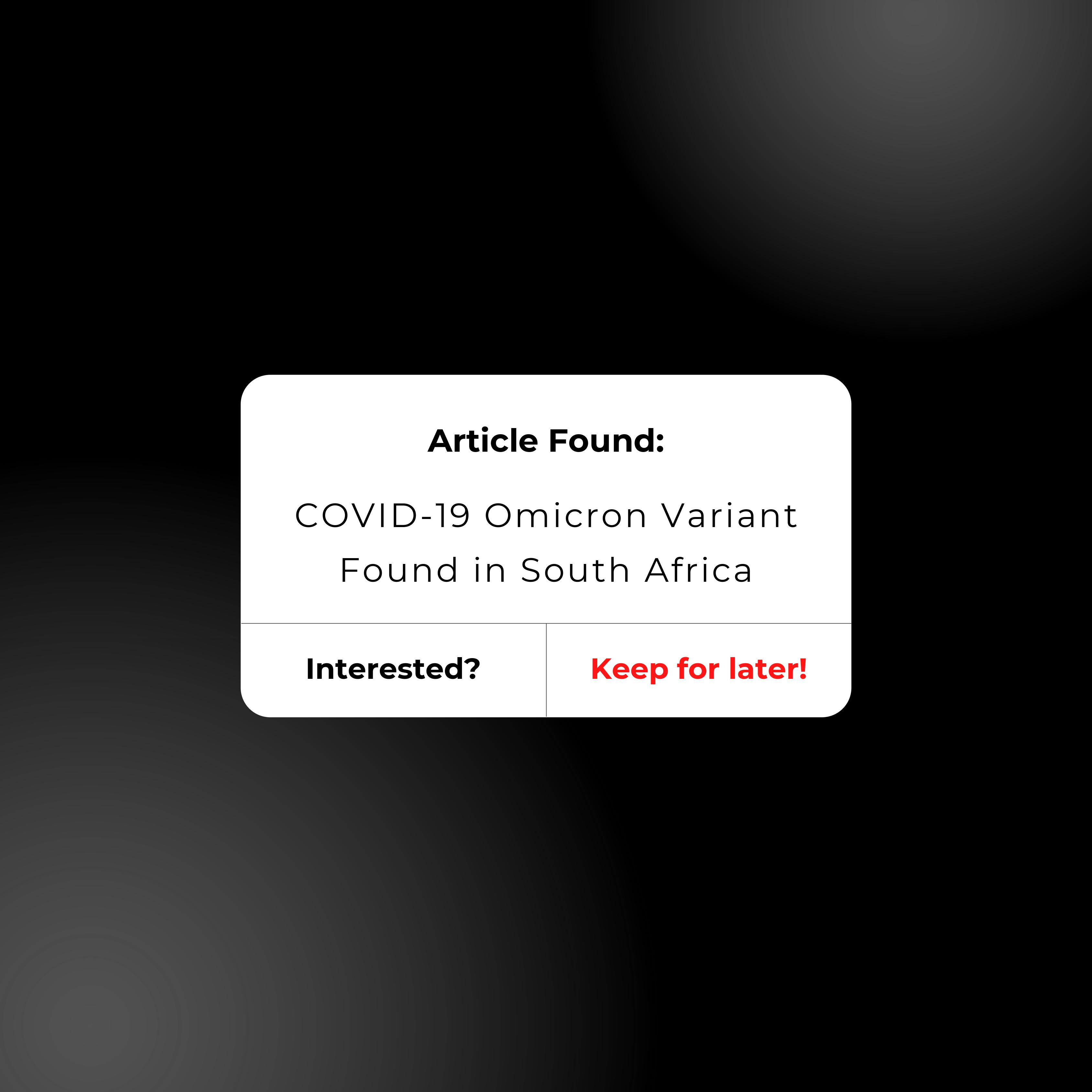
example of a personalized COVID-19 dashboard



Inspiration
The motivation for this project came from the contant bombardment of misinformation and misrepresentation of valuable information surrounding the COVID-19 pandemic. As we go deeper into the third consecutive year of the pandemic, the pressures of dealing with this sort of rhetoric on a constant basis should really not have to be an issue. Over the course of the pandemic, it's been largely been noticed how easy it can be to be dissuaded to believe something because it seems to be coming from a credible source. Testing each others' trust is definitely not something that we should have to go through and that is exactly where Teenfaucis comes in. Teenfaucis wants to become a singular source for information surrounding the COVID-19 pandemic and as it gets its information from websites with high scientific credibility, as verified by a third-party non-partisan website, there is no need to worry about information being misleading. There is no reason to not trust Teenfaucis as the information that Teenfaucis obtains is itself coming from elsewhere and that too, a scientifically well-seated source.
Quite frankly, especially given we're in the third year of the pandemic, it's time for something like Teenfaucis to be out there helping people navigate the pandemic!
What it does
Teenfaucis is a proposed application that uses a python script on the backend to locate scientifically accurate information and news about the COVID-19 pandemic from various reputed sources on the web and relay this to users in one place.
Essentially, we hope to create a platform that can be used on its own to be an up-to-date beacon of information about the COVID-19 pandemic. Teenfauci’s python script forms the backbone of such a platform as it obtains the news headlines and relevant links to be displayed to the end user. The UI, as proposed in the UI-Beta.pdf file, which is located in the Teenfaucis github repository, resembles the end result of Teenfaucis.
Teenfaucis collects updated data from mediabiasfactcheck.com on reputed sites that publish scientifically accurate and verifiable content and then uses these websites to find COVID-19 articles to display to the end user.
main.py is the primary program that contains import statements to bring in the contents of the other files into this file. In this file, we call two custom functions from two different files, namely the crawl() function from crawler.py and the find_articles() function from finder.py.
crawler.py performs the task of obtaining information from 130 different websites classified under the pro-science category on mediabiasfactcheck.com and makes these accessible to the rest of the program. The goal of choosing these pro-science websites was to ensure the scientific accuracy of the news headlines and information.
Building on the information collected by the crawl function, the find_articles function located in finder.py, parses through each of the websites home pages using python’s BeautifulSoup library and then it maintains a list of articles that are related to the COVID-19 pandemic by searching for particular keywords in the news articles’ headlines.
This function returns a list containing all the articles related to the COVID-19 pandemic and this is relayed to the end user, ultimately through the proposed application.
How we built it
Our approach to building this project was sort of modular. Instead of stressing over the details of the entire project at all times, what we did was split the larger task into smaller tasks. For example, in our case, this would mean attempting to crawl and obtain the HTML text for the webpages we wanted to, parsing through the webpages we had collected to locate relevant news headlines and articles, and design the UI to give a freshing and soothing feeling to resemble a sort of stress-releaser.
The benefit of this modular approach was that whenever we got stuck, it never felt like the entire project was bottlenecked. It was imperative to us that we focus our energies on the modules that we were currently worked on and so any errors or gridlock we had forced us to throw our collective energy at a small problem and because of that, we resolved any problems that came our way.
Another benefit of this modular approach is the idea of localized damage control. If we were doing everything in one file and sort of together, whenever a certain error or problem occured, there would be many different individual parts of the project that could be contributing to that particular error. Instead, the way we approached the project, any problems that did occur would be localized to a small section of the project and damage control and identification of what exactly was the problem would be much much easier.
At the end, we put all of these modules together to make a cohesive product and fortunately, everything went quite well!
Challenges we ran into
Our goal from the beginning was to use a list of websites that mediabiasfactcheck.com gave us the green light for. For this reason, we were sure that we, as a team, wanted to pursue some sort of scraping methodology on the proscience page on https://mediabiasfactcheck.com/pro-science/ itself to get those particular links.
In the process of trying to pursue this is where we ran into some issues. Initially, we were set on making use of an existing repository that already exists for this explicit purpose - crawling through MBFC (mediabiasfactcheck.com). For this purpose, many of us explored ruby, a programming language that the majority of us had never touched in our lives. Even then, we tried and tried but were unable to get the crawler to work (this has to somewhat do with the fact that the crawler is archived and hasn't been updated in over 2 years). Finally, out of any ideas to get our program to work, we resorted to writing our own crawler and to do that, we had to learn about the requests library in order to facilitate our homemade crawler.
This is one example of many similar challenges we faced, but in all of them, with the help of powerful tools like Stack Overflow and persistence, we were able to face all of the challenges thrown at our way and were successfully able to build a working final product!
Accomplishments that we're proud of
As a team, we're really happy with the way our idea fructified into something that can actually be used by someone! Teenfaucis is at a point where the current product can be turned into something much grander and the number of avenues to do such a thing in are endless!
Initially, we weren't really sure if our idea was any good. Nonetheless, we took it upon ourselves to give it a go and see how far we could go with our current skill set. As expected, what we knew at the time just didn't really cut it. Learning things about the BeautifulSoup library and string manipulation became needs and those satisfy those needs, we ended up gaining knowledge about those knowledge domains!
What we learned
We learned that its always important to have a Plan B in case Plan A doesn't go as you want it to. In the case of the crawler issue we ran into, it was sort of a blessing in disguise to how it can be easy to have really high confidence about the potential success of one thing and how that's not necessarily the best mentality to have in the long run. Because of the issues we had with our crawlers, a key lesson our team learned was persistence. The crawler we had initially didn't work and we were hesitant to go out and attempt to write out our own crawler because of all of the complications and all of the new packages and functionality we have would have to hustle with. Eventually, we were left with no choice but to pursue that option and so we went with that - we wrote our own crawler from scratch! Had our needs been satisfied with the existing repository, we would never have dared to venture out of our comfort zone and try to build our own crawler! This is why, as a team, we are ironically collectively grateful that the respository didn't work because it not working gave us the opportunity to do the heavy-lifting ourselves.
What's next for Teenfaucis! - A Revolutionary Way to Navigate the Pandemic
We've outlined what we intend to do in terms of the desired application that we wish to create. Our next steps will be to bring that particular prototype that was shown (Beta UI) and try to convert this into an actual application that can be used in the real world. Furthermore, the current python script can also be inculcated into a webpage of its own that can act as a page with links to websites where COVID stories can be followed. Another possibility is creating some sort of API that returns lists of news articles to users.
Truly speaking, the boundaries are endless and we hope to extend this project because there would be absolutely no reason not to! :D

Log in or sign up for Devpost to join the conversation.