-
Emotion Alert
-
Analytics
-
searchable knowledge
-
Images found
-
Enter Page

Inspiration
Students constantly find themselves overwhelmed by their course demands, this can have a negative impact on their grades and health. I wanted to design a web application to assist on both these fronts, assisting students in completing their essay assignments in the most efficient and healthy way possible.
What it does
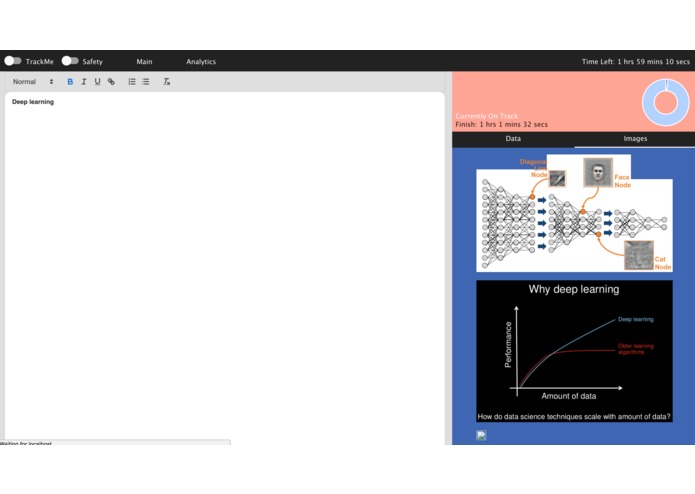
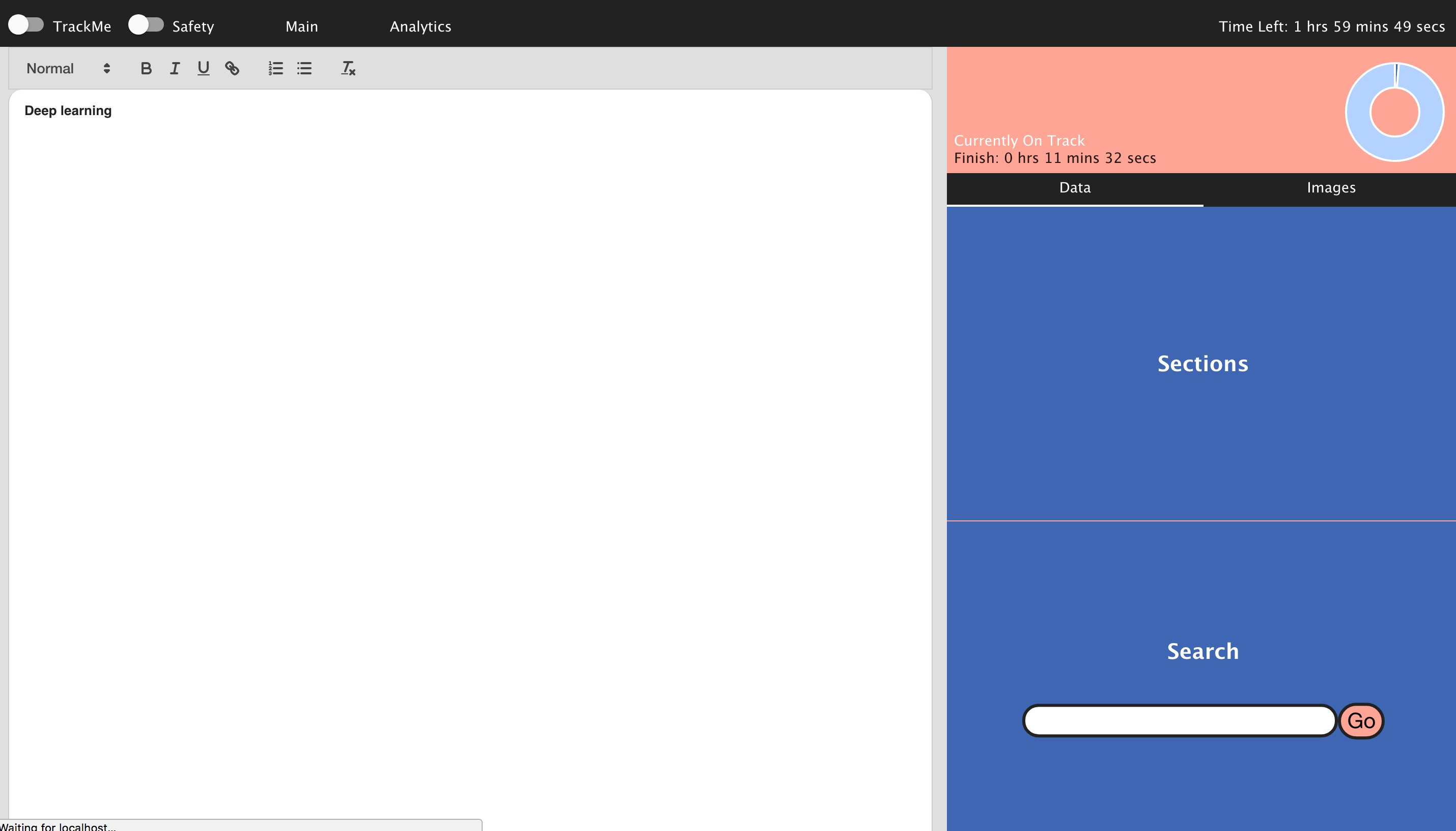
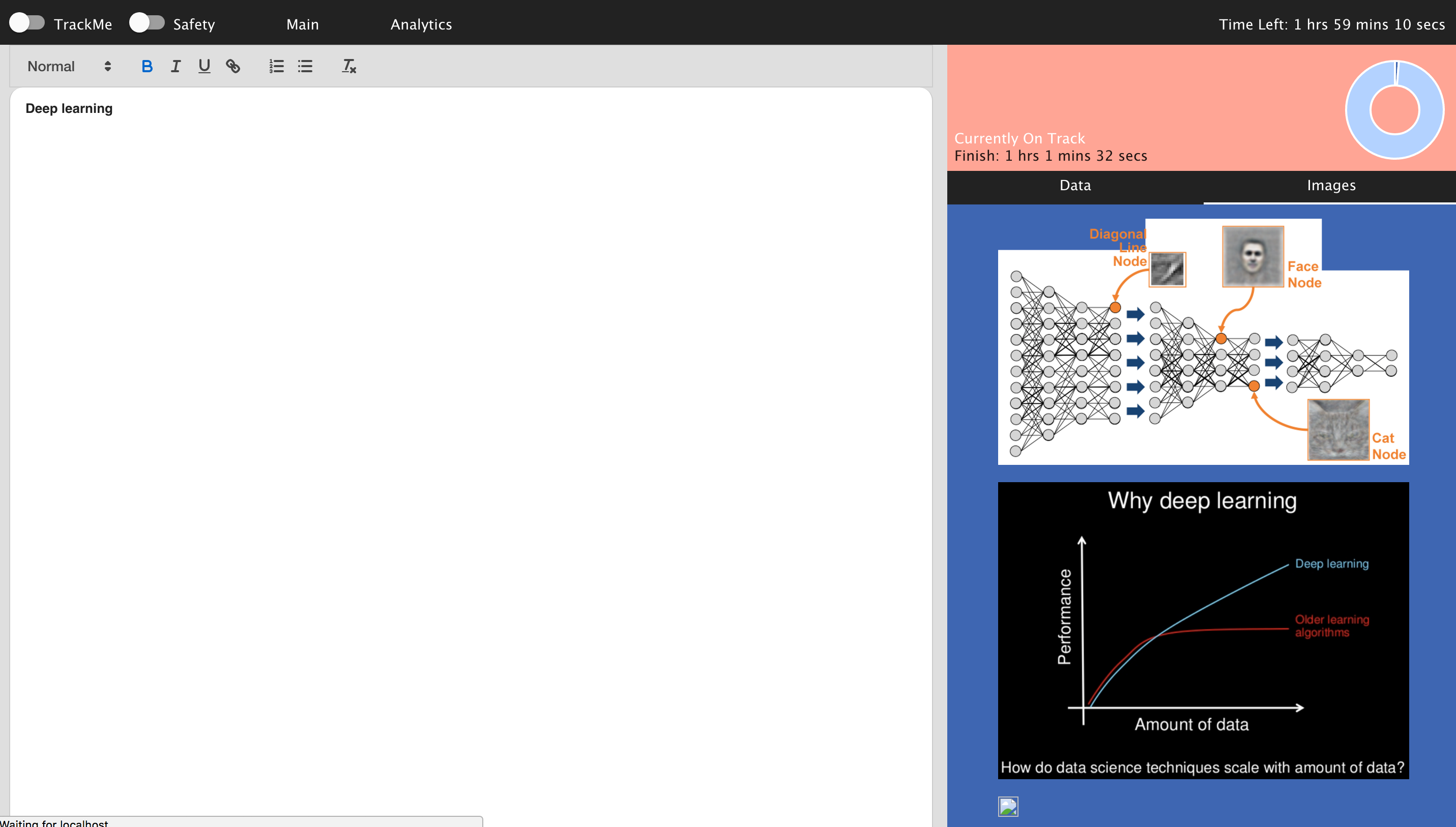
The user enters their paper topic, character count and how many hours they have to complete the paper. This takes the user to the main page of the application, which includes a main text editor, a resources finder, and analytics so they are kept aware of their progress. Here the user can access related images and paper conclusions, introductions and searchable paper subsections, which can be copied into the text container. These resources are loaded using Microsoft Knowledge Cognitive Services Api, Microsoft bing/image search. The downloaded papers are then parsed to raw text using a pdf2json library then a custom made function that finds introductions, conclusions and topics to search,
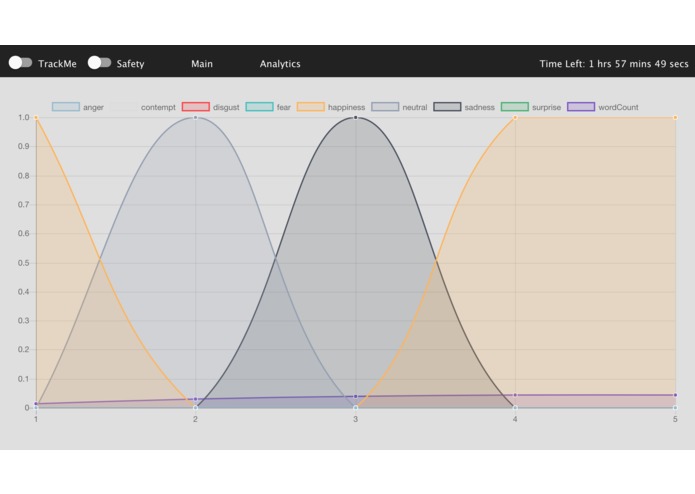
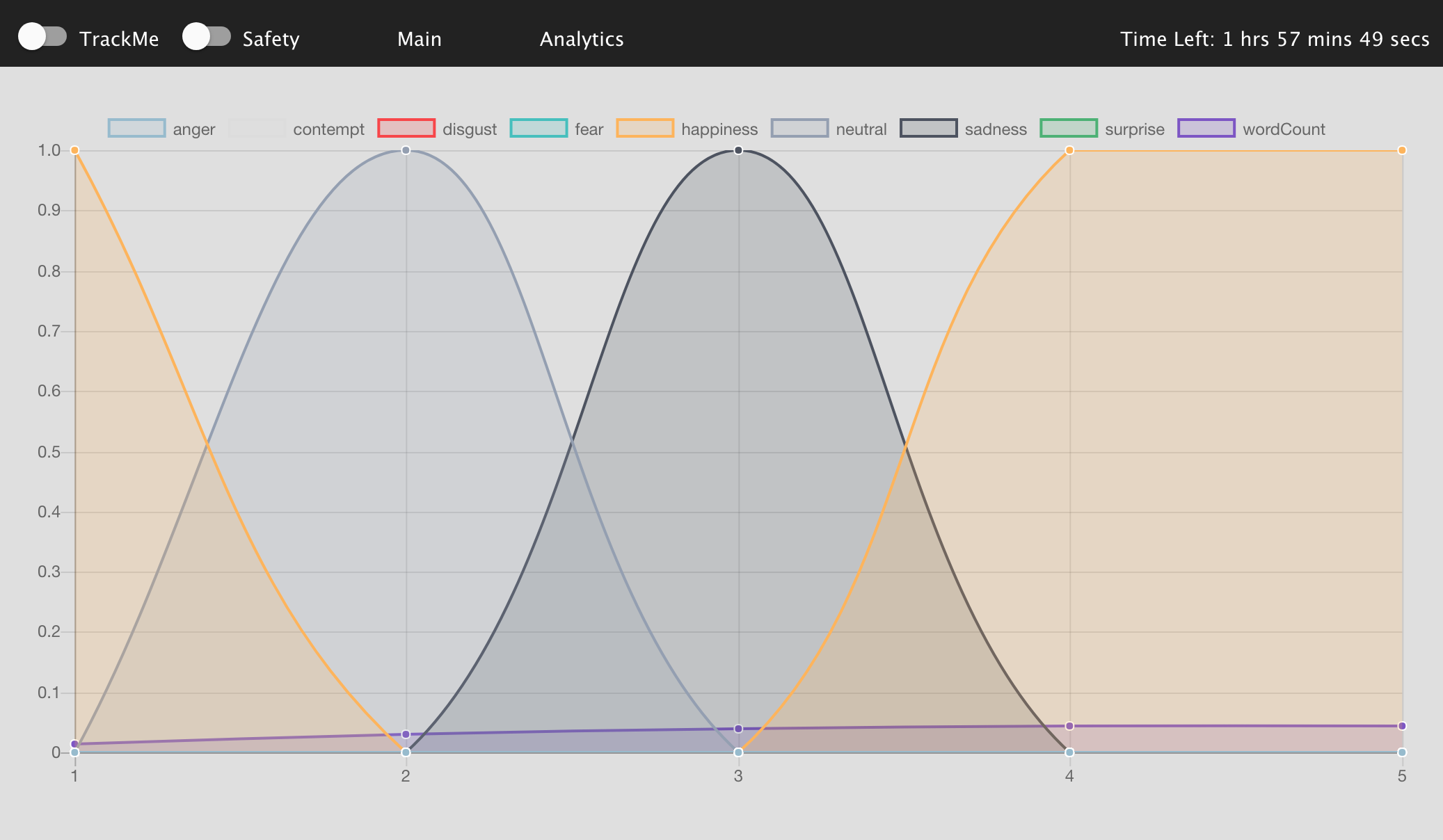
Users can track their progress with estimated complete times, total characters written so far and time remaining. The web app also has two modes "trackme" and "safety", both use the microsoft cognitive visual services. Trackme records the users emotions over time as they complete their essay, it also calls a custom vision search model, that returns whether the user is focused looking at the screen or not, if they are not paying attention an alert is sent. The users emotions over time can then be viewed on the analytics page, this shows a graph of the users emotions vs their word count progress over time. This is meant to help students understand how their emotions relate to their efficiency.
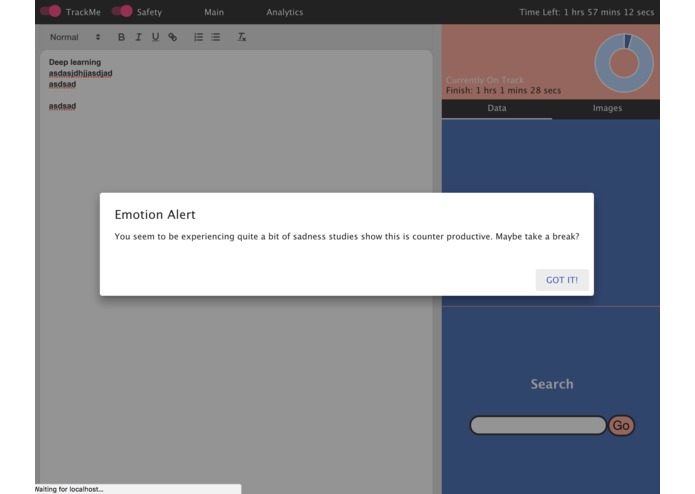
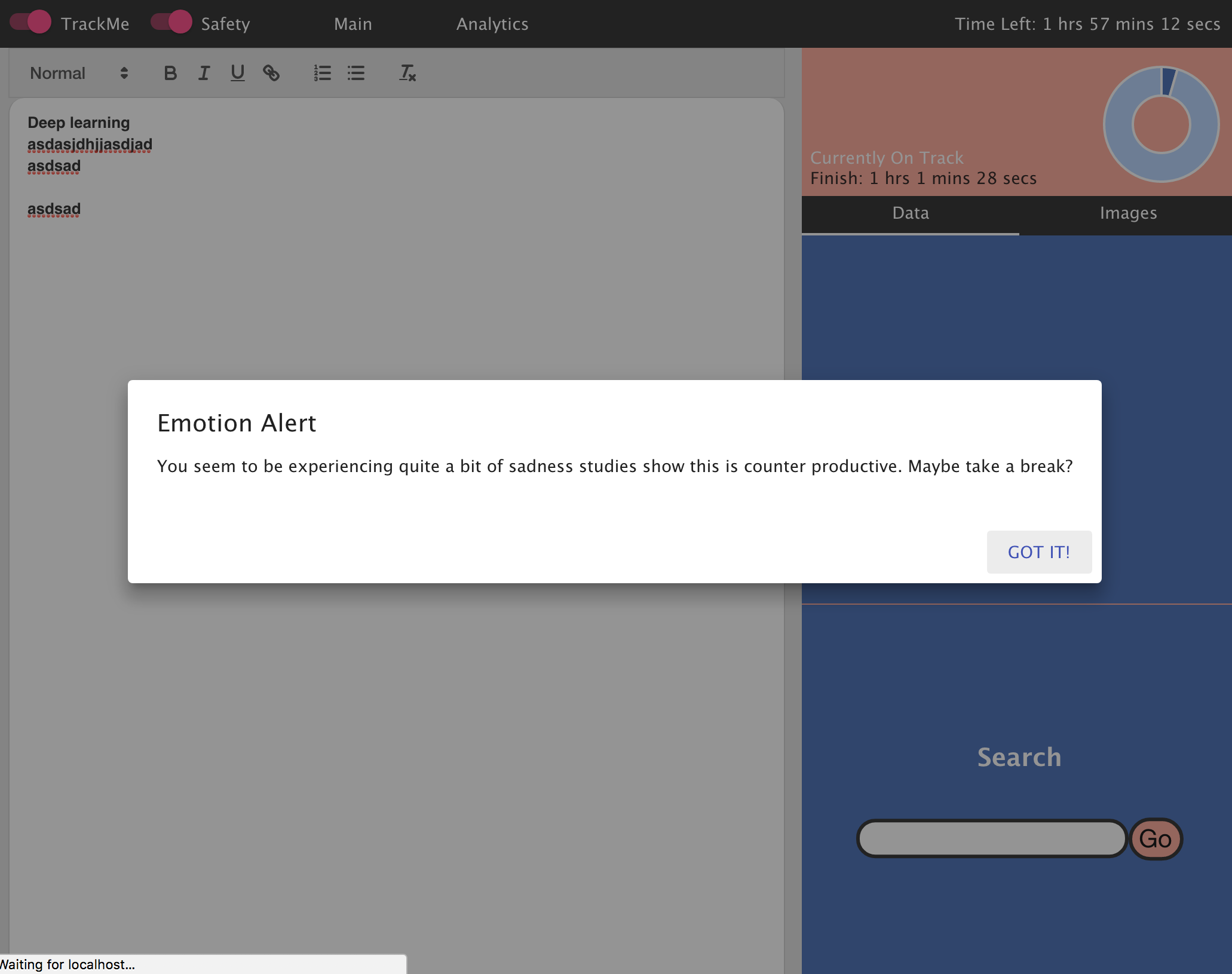
The safety mode, checks the users latest emotions, if they are distressing above a threshold, an alert is sent urging the user to take a break.
How I built it
The web application is served from a node.js server.
Challenges I ran into
Microsoft Knowledge APIs can only return the title, date, abstract of the papers it finds. Therefore to access the paper contents I had to then use the title and date information to perform a microsoft cognitve services bing search. The first pdf link was then downloaded, it was then saved and parsed using a pdf2json library. Unfortunately this only outputs raw text, therefore I had to create a custom parser that attempted to find introductions, conclusions and enable efficient searching.
What I learned
I learned how to create a microsoft cognitive services custom vision model.
What's next for teamLastMinute
I want to host it and see what my friends think. Also the custom raw text parser needs to be improved in accuracy.
Built With
- css3
- html5
- javascript
- microsoft-cognitive-services
- node.js


Log in or sign up for Devpost to join the conversation.