-
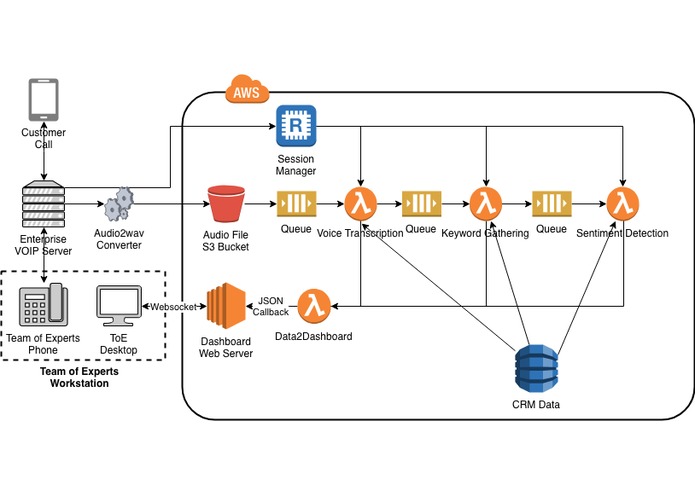
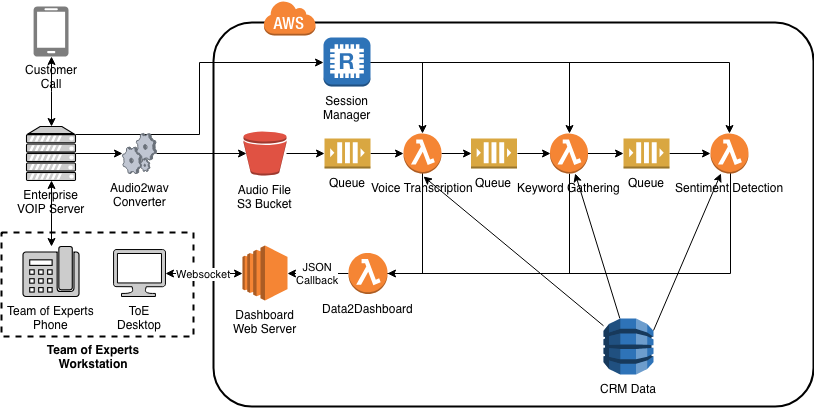
Network Architecture Map
-
Wireframing UX
Inspiration
Listening to the description of the T-mobile call flow, we felt that having team members asking other team members question would be a pain point for both customers and team members. we think that without specialization, team members would be force to frequently put the customer on hold to work with team members with specialized knowledge to help resolve the issue. These wait times lower customers' confidence and lead to increased call time. By bringing knowledge base articles that an AI thinks are relevant into the call dashboard we believe that it will cut down on the time to resolution and boost customer's confidence in their service.
What it does
TeamExpert Dashboard ingests live call audio and provides relevant information to the support representative in order to help find a resolution for customers quicker.
Live audio is spliced up approximately every thirty seconds on a word bound and uploaded to an s3 bucket. An AWS lambda function will then start an AWS Transcribe job on the call segment and pipes the data to the customer rep in real time. Then, a second lambda function takes the transcription and pipes it into AWS comprehend for natural language processing. Comprehend then parses out key words and gets the verbal sentiment of the segment. This data and the transcript is passed to a PHP Laravel server for further processing and dashboard updates.
On the server, we pass the transcript directly to the dashboard and is displayed near the bottom with opacity based on the confidence of the transcribed word. When the server gets the keywords it runs filtering to remove irrelevant key words. The filtered keywords and confidence values are again passed to the dashboard. On the dashboard they are used to highlight the words in the transcript, again the opacity is based on confidence values. Then, the keywords are used to find potentially relevant knowledge base articles.
Since we have 30 second segments of audio, we can use the positive, negative and neutral sentiment from AWS Comprehend as another metric to judge the quality of the service from individual support reps. Plotting the three confidence values from Comprehend, we can come up with the overall trends during the duration of the call. If the trend of the call is towards a more positive sentiment overall, we can determine that the call had a positive resolution.
How we built it
We broke the task into several pieces:
- The audio ingestion - handled with Python scripts
- Audio transcriptions - set up with AWS Lambdas and the AWS AI Suite
- Demo support conversations and knowledge base articles
- Front-end in React
- Real-Time data web server in PHP server
Challenges we ran into
- VOIP Server - we wanted to stick to authenticity but after looking at the shear amount of time it would take we opted to just create a simple "audio2wav" python script that could simulate a phone call.
- Transcription - Turns out, AI is hard... and cumbersome. Who knew? In our tests with AWS transcribe, a three second audio clip took the same amount of time (sometimes more) then a 30 second clip. Our original plan was to upload transcript snippets after after every ten seconds when a .02 second pause was detected. However, when we were blindsided by AWS Transcribe's long processing times, we decided to send chunks of audio no shorter than thirty seconds long. This helped us cut down on our processing time.
Accomplishments that we're proud of
We're proud of our pipeline that takes raw audio from a microphone source and takes it all the way to rich-text data that is actually relevant to the support representative.
What we learned
Dealing with real-time information and event-based systems is very hard. It was a learning curve for all of us but we're excited to have gotten a hands-on experience.
What's next for TeamExpert Dashboard
The next steps to to finish out the soft-phone interface and focus on ways to improve our AI. With better keyword detection and filtering algorithms, we could improve our systems ability to pinpoint relevant knowledge base articles.




Log in or sign up for Devpost to join the conversation.