-
Poster
Title: A new heuristic for fake news: Formal Language Analysis
Who: Muhiim Ali (mali37) Luoyun Wang (lwang105) David Doan(ddoan2) Indigo Funk (ifunk1)
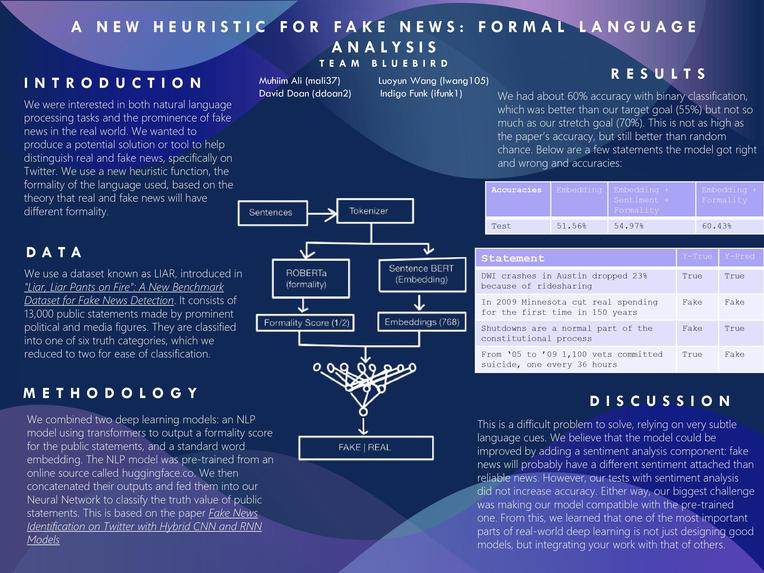
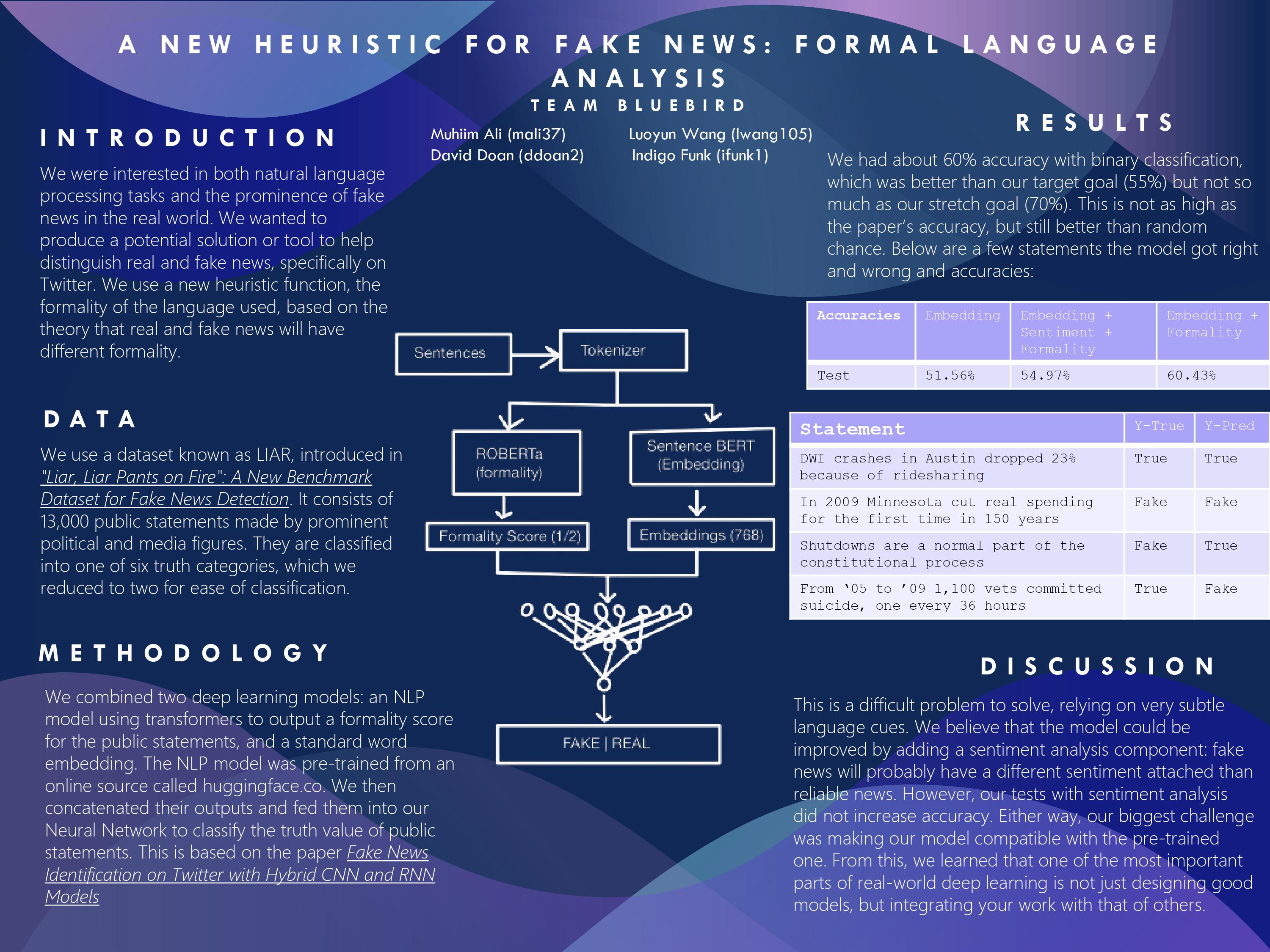
Introduction: What problem are you trying to solve and why? Being interested in natural language processing tasks and with the prominence of fake news in the real world, we wanted to come up with a potential solution or tool to help distinguish real and fake news. Intuitively, we would expect that there might be a pattern in the language used for real and fake news, and that there might exist a discrepancy between the two statements. dealing with the prominence of fake news in the real world. For our final project for Brown’s Deep Learning task, we wanted to test our theory and build a classification model to detect real news with a new heuristic function, the formality of the language used. Our model will be a supervised classification model, with news statements will be our dataset, with each statements with the truth values labels. We will then categorize out inputs into either fake or real based on the language used.
Related Work: Brief summaries of papers: We are building this project on top of two projects we read about and found interesting: One project explores the political dialogue surrounding COVID-19 on Twitter. Specifically, they sought to analyze the differences in the portrayal of COVID-19 between CNN, a liberal news outlet and Fox News, a conservative news outlet. They were also able to determine whether the sentiment of the replies to COVID news tweets changes between these two news outlets. Fake News Identification on Twitter with Hybrid CNN and RNN Models URLs to public implementations of the papers we will reference.
Dataset: "Liar, Liar Pants on Fire": A New Benchmark Dataset for Fake News Detection Fake News Identification on Twitter with Hybrid CNN and RNN Models Data: What data are you using (if any)? We will use a dataset, known as LIAR, that was introduced in "Liar, Liar Pants on Fire": A New Benchmark Dataset for Fake News Detection. The LIAR dataset consists of 13,000 public statements made by prominent political and media figures. This dataset also includes a validation and test sets, both being 10% of the total data. They are classified into one of six truth categories: true, mostly true, half true, barely true, false, or pants on fire. This dataset contains additional information such as the speaker and the occasion of the statements, but this will not be used within our project. https://paperswithcode.com/dataset/gyafc Grammarly’s Yahoo Answers Formality Corpus (GYAFC) is the largest dataset for any style containing a total of 110K informal / formal sentence pairs.
Methodology: What is the architecture of your model? The idea for our model is essentially the combination of two deep learning models. We will create a NLP model, usings Transformers, to output a formality score for the public statements. We will then use this within our Neural Network that will be trained to classify the truth value of public statements. We would then implement the scores as part of our Neural Network, using the formality score as an extra feature we would add weight to, to help our model in its classification How are you training the model? Using the google credits, training our NLP on our formal/informal language database. Using the trained NLP model, we would then train our model with the our public statement database We are using the NLP model as a heuristic function to help our neural network to determine real or fake statements. This would add extra weight to the statements and if a pattern exists, helps our model to make its classification decision.
Metrics: What constitutes “success?” What experiments do you plan to run? We plan to employ k-fold cross-validation and run our model on the test data (10%) and evaluate its performance In addition, given the nature of our model, we plan to add human evaluation to manually assess the model accuracy. We are going to evaluate the performance of our model using accuracy. Because we are trying something new, or at least that we are aware of, we would like to see a performance accuracy of >55% as this is something that intuitively makes sense but may hold little significance. However, there is potential for our model to learn features not apparent to humans such that we achieve a heuristic function that achieves a better accuracy than guessing, signifying that some relationships exist.
What are your base, target, and stretch goals? Base goal: 45% Target goal: 55% Stretch goal: 70%
Check-In #3 Reflection link
Final Writeup/Reflection link


Log in or sign up for Devpost to join the conversation.