-
-
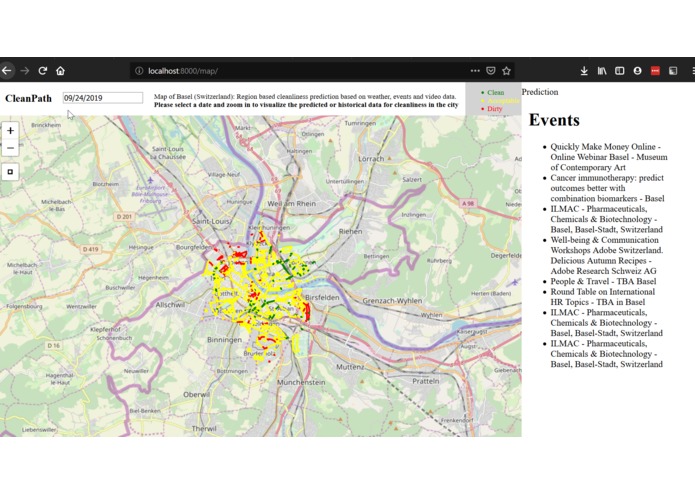
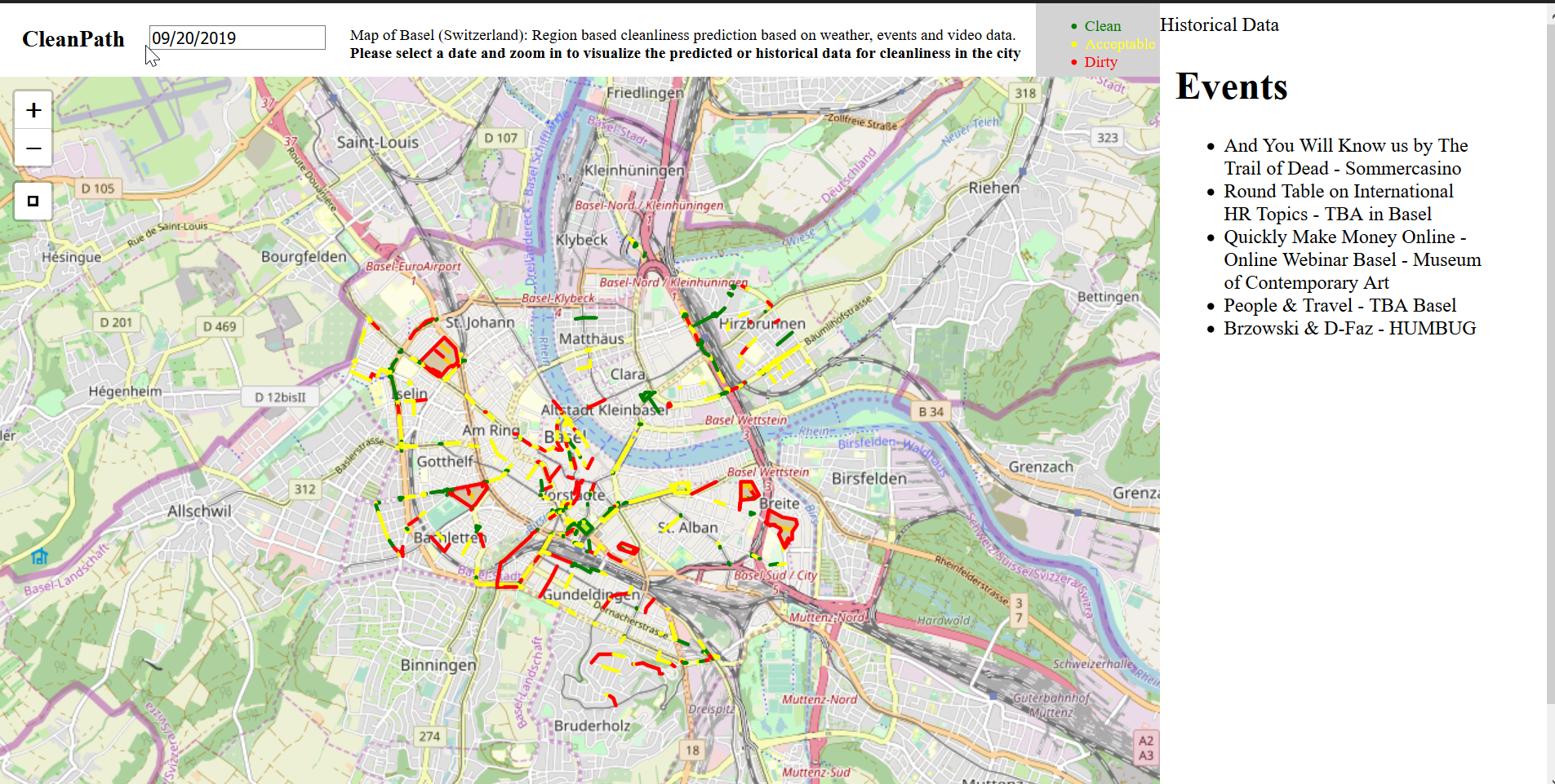
Visualization of the predicted Clean City Index (CCI) values for Basel.
-
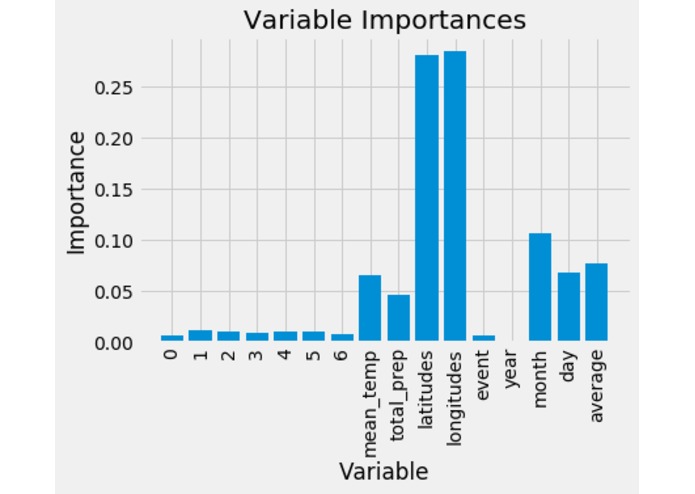
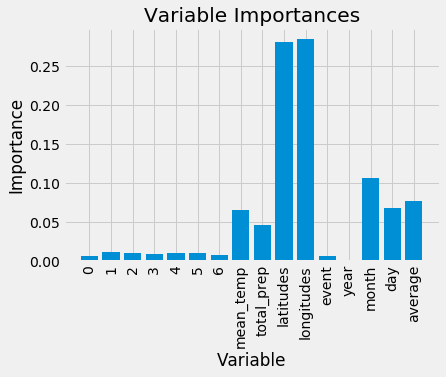
Most important variables: latitudes, longitudes, month, average-cci-rating-in-neighborhood, mean-temperature, day, total-precipitation
-
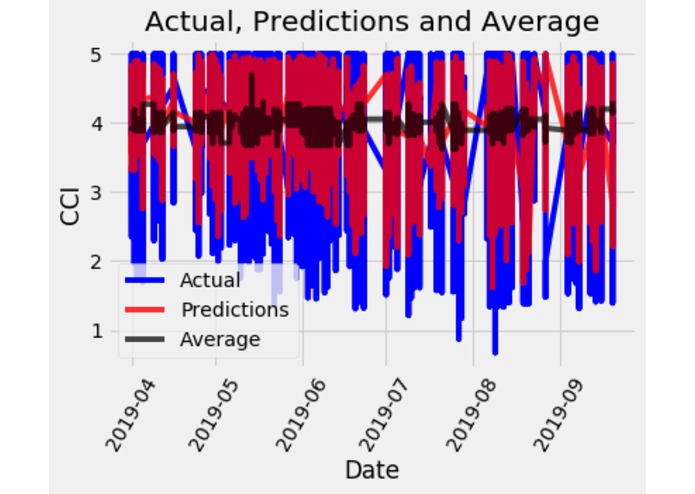
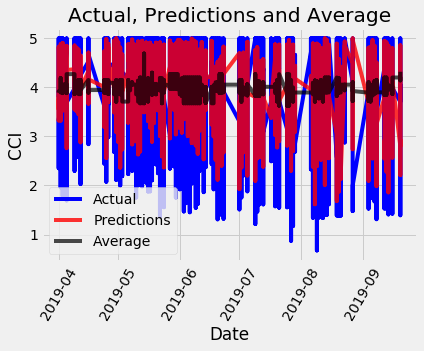
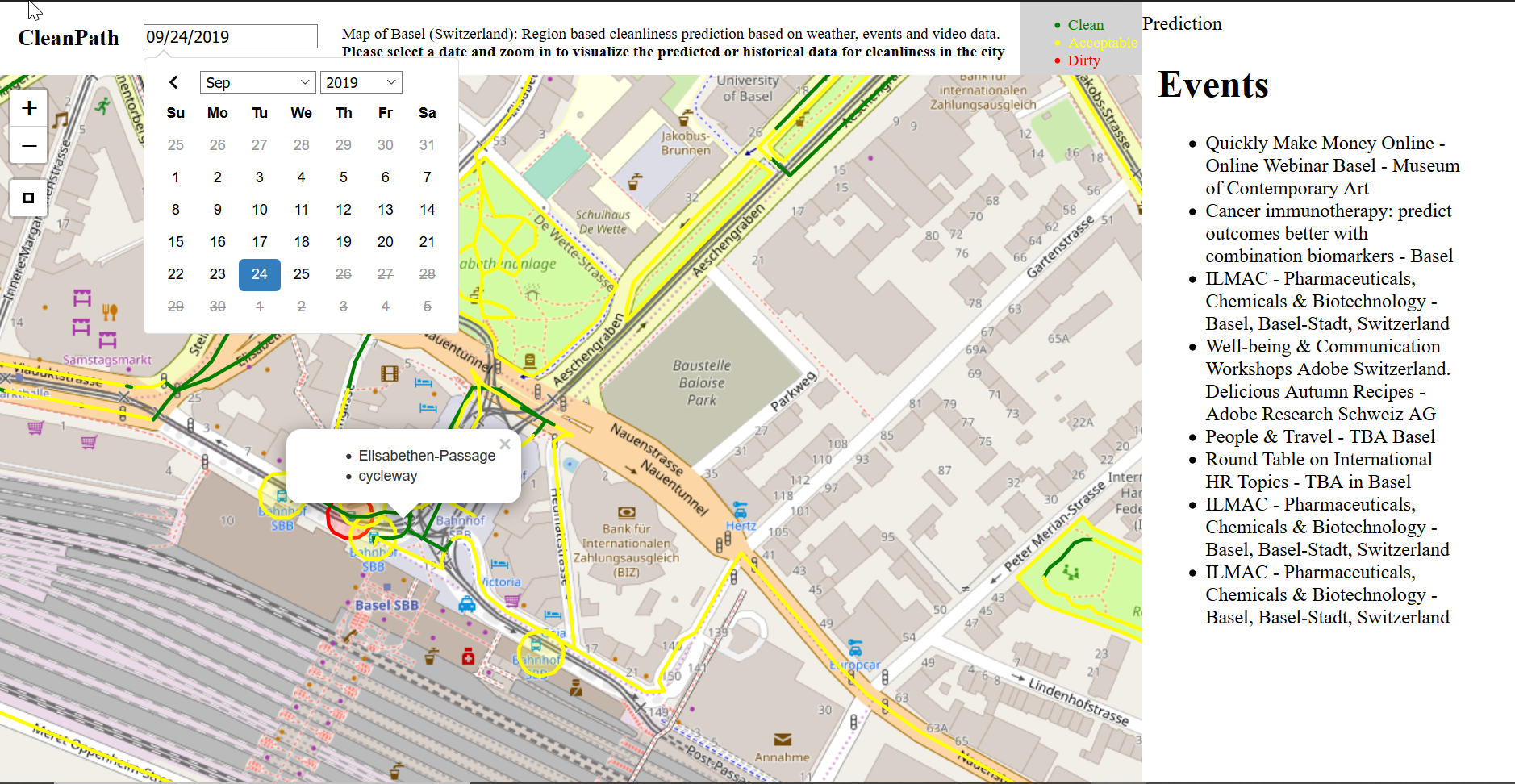
Actual and Predicted values on our model
-
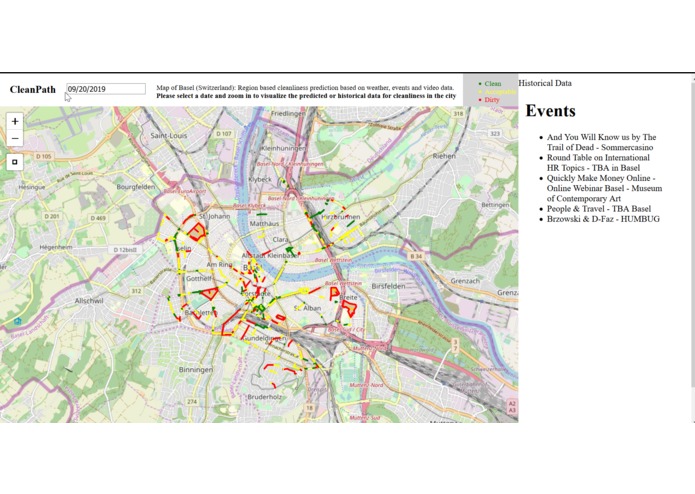
Visualization of the cleaning index for the city of Basel.
-
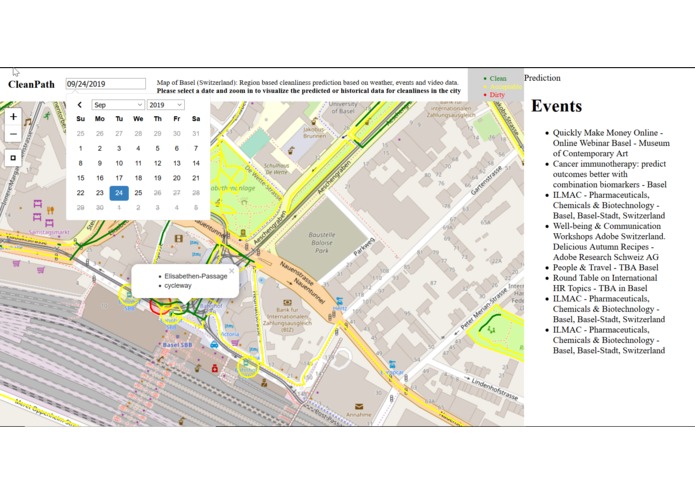
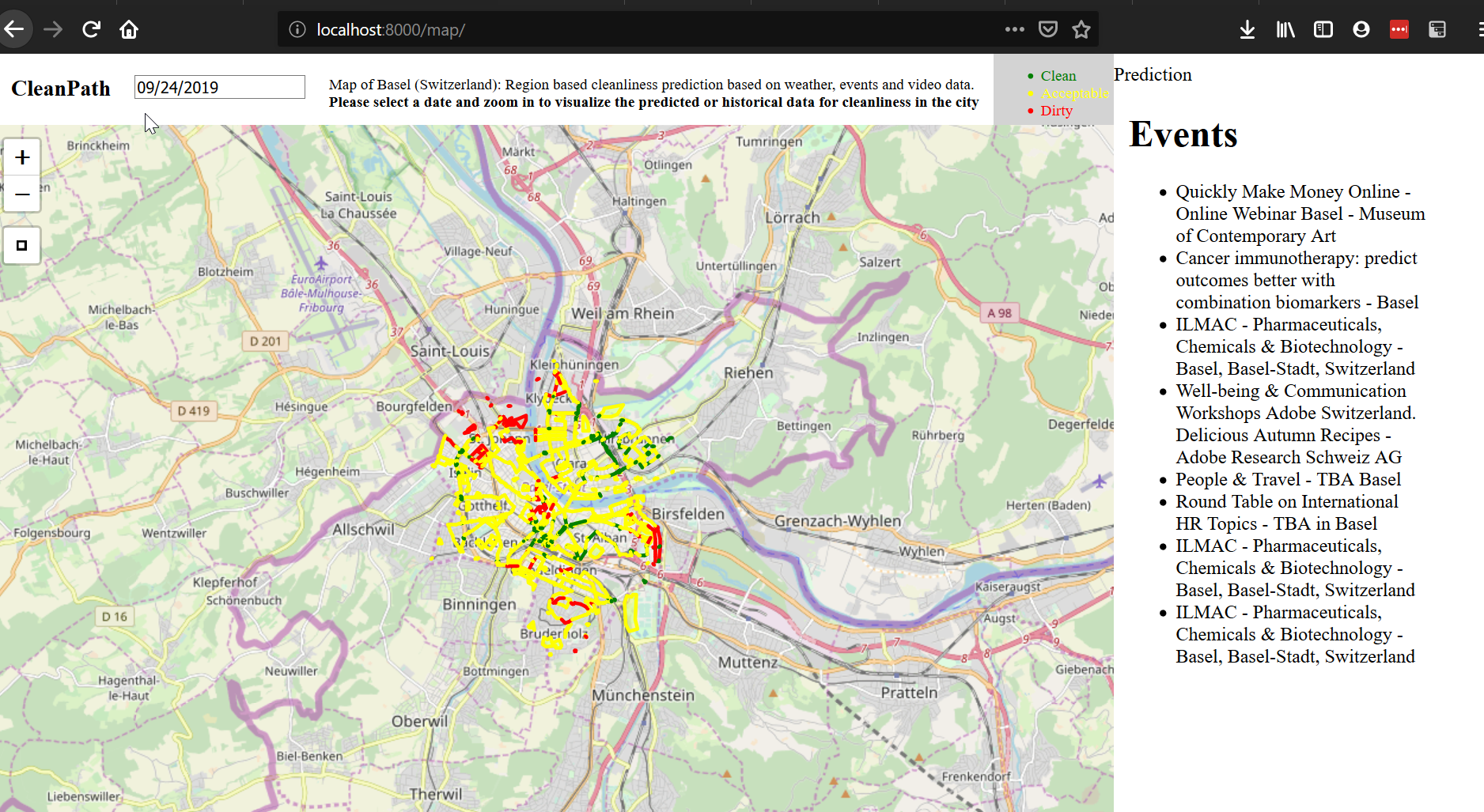
Visualization of extra information shown for each point and venue.
-

Example of a Bucher Sweeper.

Checkout the live demo here
Inspiration
Garbage collection today is conducted on a fixed schedule chosen on human's bias observation. This creates problems when there are events such as concerts where lots of garbage accumulates which may not be cleared until the next garbage collection schedule. This project addresses the problem by predicting a city cleaning index (CCI) for every street and venue around the city. This prediction is made from publicly available data, such as previous events, weather and day characteristics. With this information, the sweeper company is able to develop an optimal schedule and clean the city when needed. Thus, avoiding redundancy around cleaning and ensuring a cleaner city.
What it does
The model is able to predict and visualize the cleaning levels of the city of Basel.
How we built it
There are three aspects to the project:
1. Data collection
Litter detection dataset: A dataset of the garbage from the city of Basel (Switzerland) based on geolocation and images collected over a period of time was provided by BUCHER Municipal AG and Cortexia. The data included geolocation, timestamp, place_name, and Clean City Index (CCI) for that location from the months of April to September 2019. CCI was calculated using computer vision by detecting the different trash objects (cigarettes, plastic bottles, leaves, etc) From that region on that day.
Weather dataset: A python service was implemented to query the Metomatics API for historical weather data.
Event dataset: All the events posted on Eventful during the same period as Littter detection dataset were queried and used.
The extracted data is available here.
The features considered in the final dataset included: latitudes, longitudes, CCI-rating for those latitudes & longitudes, year, month, day, average-cci-rating-in-neighborhood, mean-temperature, total-precipitation, mean-wind-speed, minimum temperature, maximum temperature, day type ((weekday, weekend, or holiday), and event occurrence in neighborhood. It is important to note the last cleaning date for a specific region was used when available.
2. Model development
Multiple models were tested for this use-case as follows:
- Linear regression
- Multi-Layer-Perceptron
- Random Forest Regression
- Statistical analysis between correlated features
The best model for this use case was Random Forest Regression with an accuracy of >86% and mean average precision of < 0.45 on our test dataset. This set consisted of 25% of the available training data.
3. Visualization via web service
The web service was developed in Django. A lot of the data was fetched into a database from the source files to make the business logic easier and more performant.
There is a direct interface to the model, that resides in memory, hence it's capable of producing a lot of predictions in a timeline fashion. Note that we are generating a prediction for every ROI which is in the system for every day selected.
Storing geospatial (GIS) data was something we never worked with. It required database extensions, however, after the initial learnings, a lot of operations became a lot easier, like getting centroids of polygons, looking at intersections etc.
Since both the back-end and the model was written in python, implementing interfaces to the model was straightforward once we understood the requirements.
The front-end was done with using leafletjs.
Challenges we ran into
Model development: To build a model for predicting CCI value to more than 3000 locations was really difficult. Although it was believed that features such temperature and event information would give good results, models such as linear regression and multi-layer perceptron were barely able to reach the baseline accuracy (just outputting the mean city cleaning index).
Getting a website up and running in a limited time: Although this sounds trivial, getting a website with visualization on it was quite a task.
Accomplishments that we're proud of
- Built a model that ingests data and gives a cleanliness rating.
- Built a pipeline that ingests data for events in the given region.
- Built a pipeline that gets weather data based on a query in the given region.
- Built a full-stack web-interface for visualizing the map and the predictions
What we learned
Model development, integration into a web service, historical weather and event data collection from publicly available databases, data pipeline development, collaboration and development in limited time!
Presentation
The following link shows our final presentation for the judges: Presentation
What's next for CleanPath
The next steps would be to use the predicted city cleaning index in order to develop a sweeper scheduled route. By providing this optimal route, we hope to ensure cleaning cities and reduce carbon emissions.



Log in or sign up for Devpost to join the conversation.