-
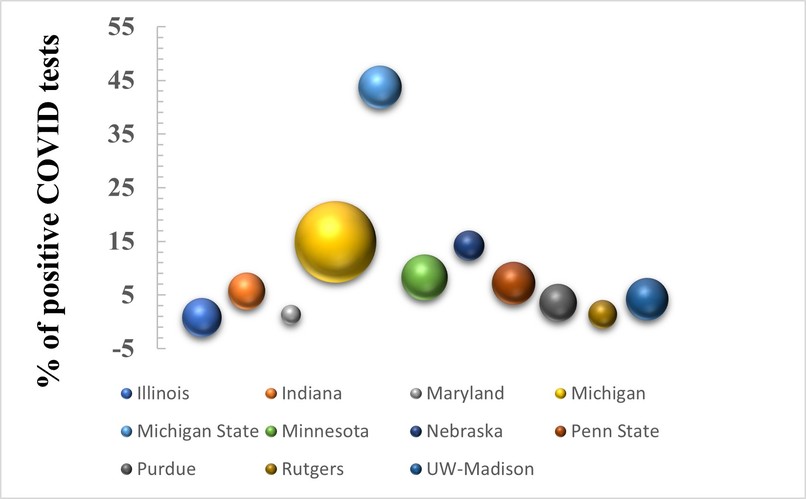
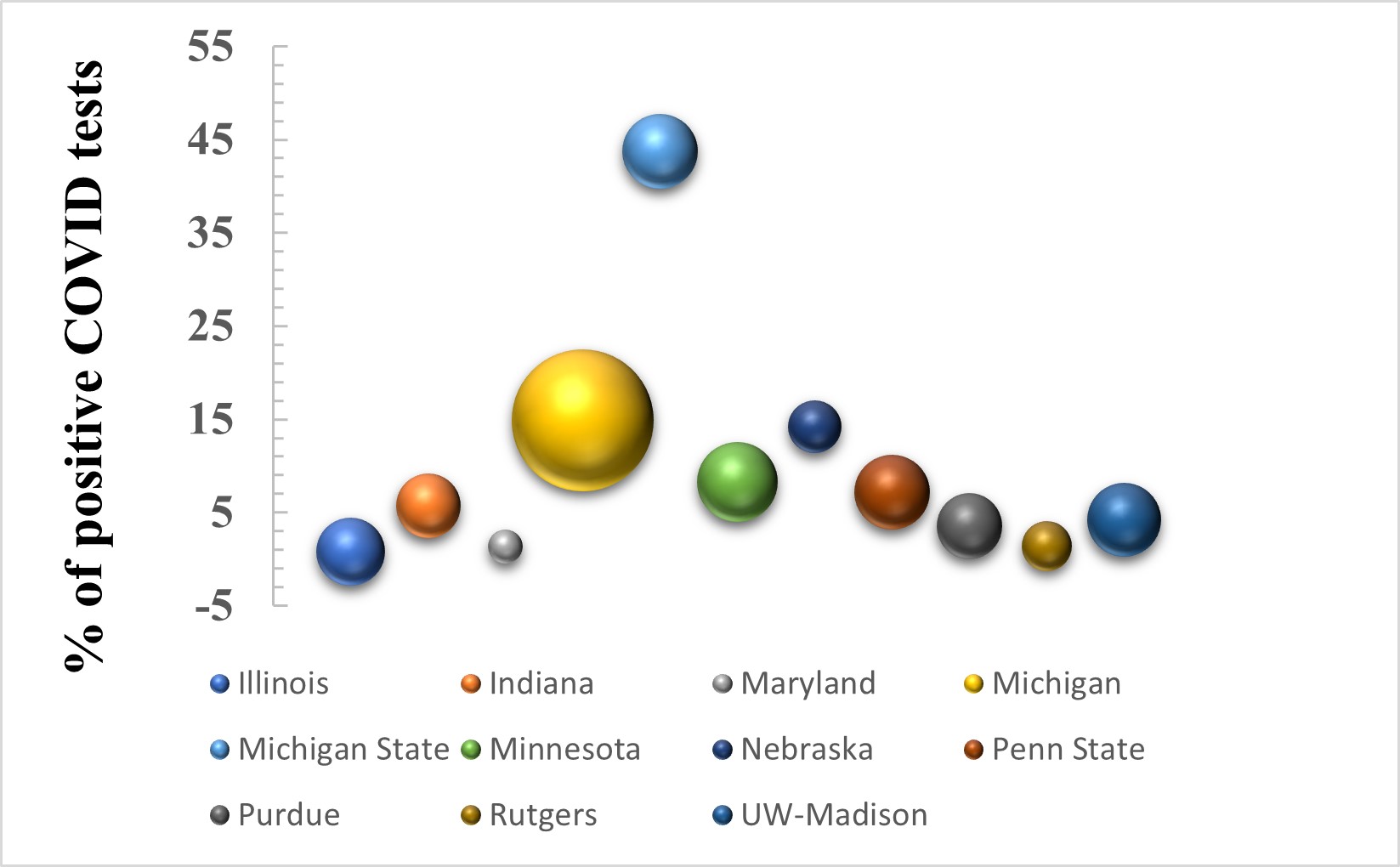
Variation of percent of positive COVID test for different universities. Bubble size represents the endowment amount
-
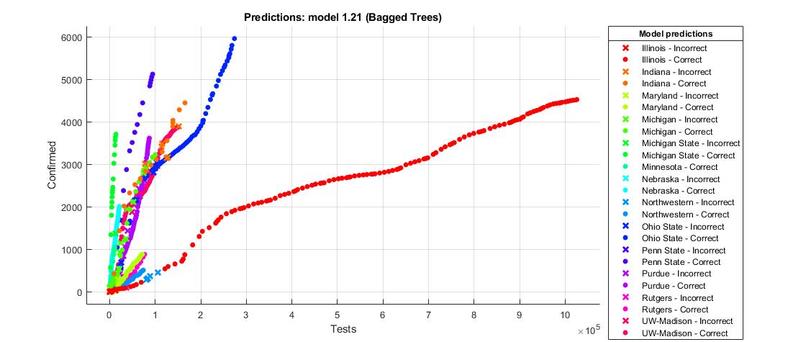
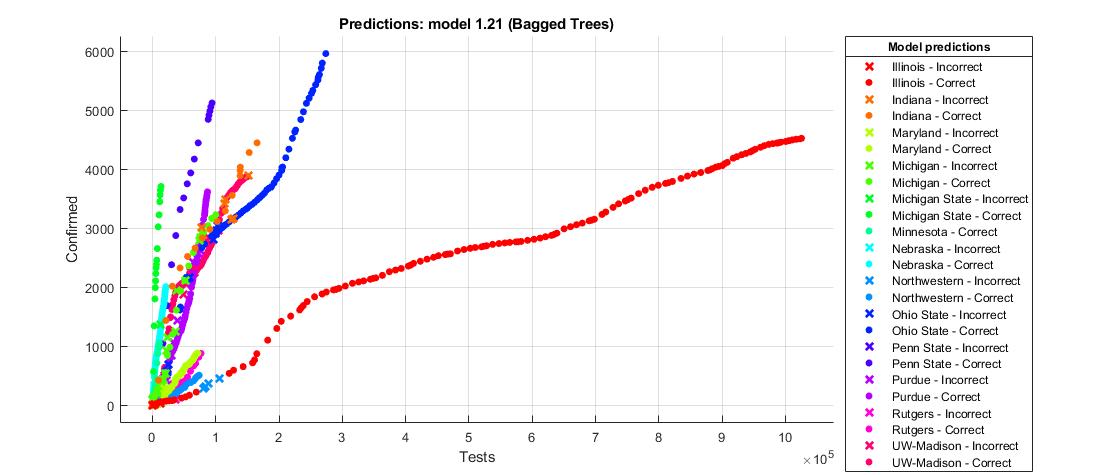
The scattered plot for the COVID tests from different universities
-
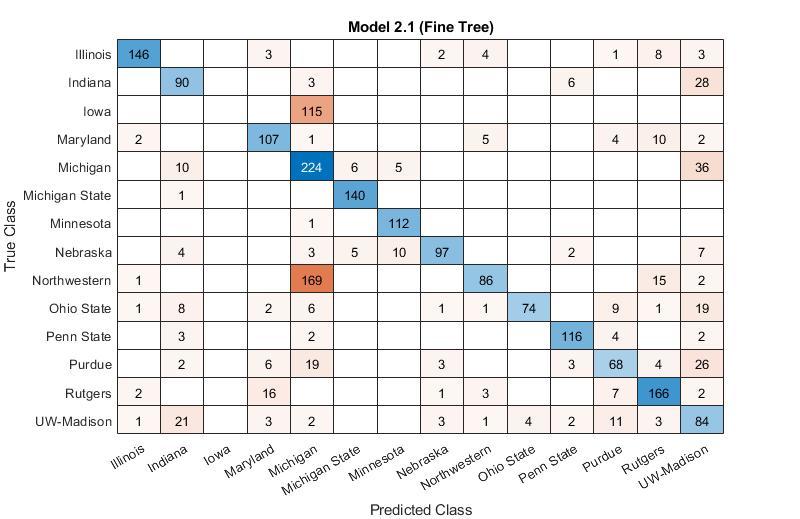
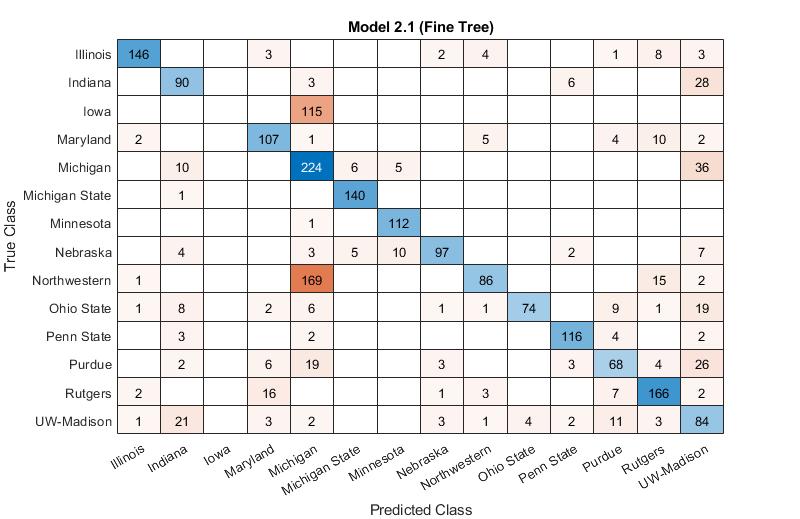
The confusion matrix for the daily COVID tests from different universities
Inspiration
COVID has had an enormous impact on how universities function and how students receive their education. Through open data initiatives, there are infinite possibilities in creating models that can have a positive effect in creating equitable policies.
What it does
We built a training model that can illustrate the number of positive COVID tests for different universities with 85.4% accuracy. There was no correlation found between a university's endowment and the percentage of positive COVID cases it has had.
How we built it
Different software were used for modeling and analysis, including Python for data cleaning and merging, MATLAB for machine learning and predictor analysis, and Excel for simple data visualization.
Challenges we ran into
A lot of time was spent trying to find robust datasets. Oftentimes, when one was found, it was outdated. There were also some difficulties in merging datasets.
Accomplishments that we're proud of
Multiple skills were improved upon by the whole team, including collaboration, communication, and technical skills. We learned a lot about the effort it takes to establish and create a statistical model.
What we learned
We learned that the Stanford Datathon's mission for open data is invaluable, since we had so much struggle locating not only a relevant dataset, but one with a lot of data points attached to it. We now strongly believe in the Datathon's goal for expanding the public's access to data, since it would make entrepreneurial projects much easier to be launched.
What's next for Team_238
Further improve and build upon the models created in this project. Implement datasets that were unable to be used due to time constraints.

Log in or sign up for Devpost to join the conversation.