-
-

Project Poster
-
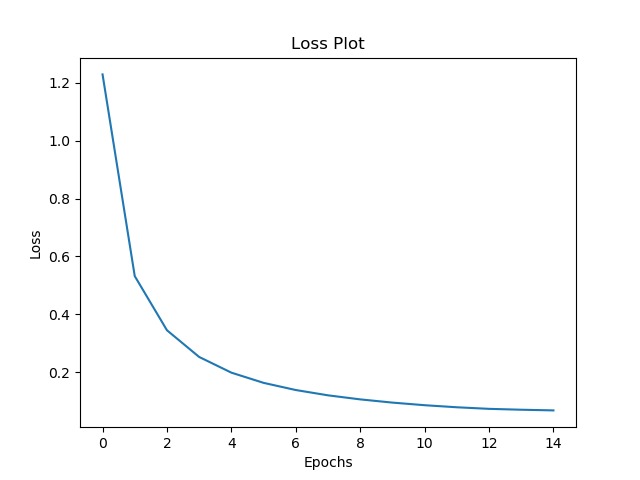
Loss Graph
-

-

-


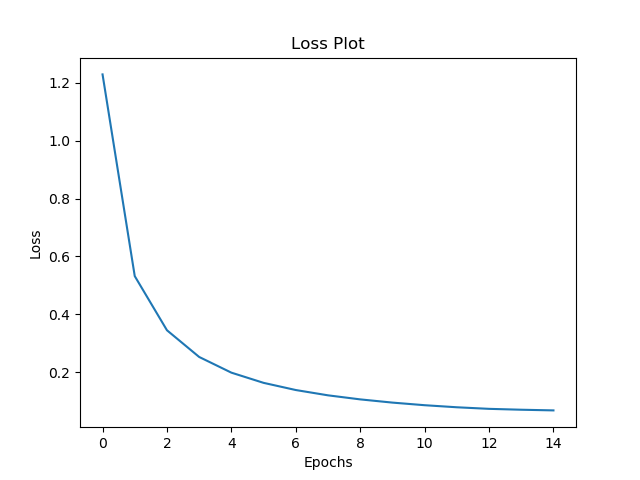



Image Captioning using CNNs and Transformers
Authors: Jacob Axel (jaxel), Paul Molnar (pmolnar), Will Beakley (wbeakley), Enahm Oscar-Phoenix (eoscarph)
Final Report: https://docs.google.com/document/d/1JF4pwvoOovBNmu4xP98aJdvYi2EX9sa0Xigp96ors5M/edit?usp=sharing
The original project proposal is below and the check-in report is in a comment underneath.
Introduction:
- We are implementing an existing paper. The goal of the paper is to explore using Transformers for image captioning instead of RNNs which are currently the industry standard for captioning tasks. We chose this paper because it is well documented and uses a publicly accessible dataset. The paper has good results and uses two deep learning strategies we learned in class to caption, which are CNNs and Transformers. Captioning is an end to end sequence-to-sequence problem similar to some of the word based projects we did in class.
Related Works:
- Paper our work is based on: https://arxiv.org/pdf/1912.08226v2.pdf
- Other papers: https://arxiv.org/pdf/1908.11824v1.pdf
- Image captioning usually focuses on visual processing, but this group aims to use language models to increase performance. The group, led by Lei Ke at the Home Kong University of Science and Technology, used a Reflective Decoding Network for the image captioning. The model learns the visual and textual features, as well as doing additional language processing on the position of the words in the caption to maximize the function of the captioning. CNNs are generally used to extract features from images, which is helpful in captioning. RDNs in this model, however, are used in conjunction with CNNs to decode the images and provide language processing. The Models are based on attention rather than RNNs, increasing the ability for accurate and informative captions. Overall, the results of the study showed that the RDNs perform better than other methods for image captioning.
Data:
- We will be using the COCO dataset, which is commonly used in object recognition and image captioning. It has about 330,000 images with 5 captions per image. This is enough data to successfully train and evaluate a large deep learning model.
Methodology:
- We will be implementing the meshed-memory transformer described in this paper. We will use back propagation to train this model consisting of a CNN, an encoder transformer and a decoder transformer. The most difficult part of implementing this paper will likely be implementing meshed-memory which will require multi-headed attention on the sequential encoder output. If this proves to be difficult, we may have to leave this portion of the model out since past papers have proven that this method to also be effective.
Metrics:
- The metrics for captions used in the paper are BLEU, METEOR, ROUGE, CIDEr, and SPIC. We shouldn’t need to use all of these methods.
- In addition to the tests listed above conducted by the authors of the paper, we plan to hand-test 50 related images with our model. We are going to experiment with the labels that the four of us come up with for the 50 images, and compare our expected output with the results of our model. We will define accuracy as a right or wrong metric, meaning if the result of our model accurately describes the image in front of us (if by reading the caption a user would be able to picture the image without seeing it) we will consider the output accurate. If not, we will consider it inaccurate.
- The authors were trying to build a model that accurately captioned images, and quantified their results using the metrics above. It helped that they had a large data set that had 5 labels for each piece of data to really facilitate the training process.
- What are your base, target, and stretch goals?
- Base: A model that captions images accurately or not
- Target: A model that accurately captions images close to the level of accuracy of the authors
- Stretch: Add on to the architecture of the model presented by the authors to improve upon the model
- What are your base, target, and stretch goals?
Ethics:
- Deep learning is a good approach to this problem because there are not really any other viable approaches. If you try to do scene classification using Bag of Words, then you lose all the spatial data which is vital to a good caption. Using deep learning allows us to let the computer learn for itself what it means to be under/over, behind/in front of, and other important spatial relationships, without having to hard code them in. Some broader societal issues we will run into while implementing this project are misclassification of people/things as well as problematic language. Our model may misclassify people’s genders because of stereotypical pictures/language embedded in the training data. This could lead to problems, because we would then have a prejudiced model. There aren’t any good ways around this problem because of the difficulty in finding/building datasets usable for deep learning, but if we were to build one then we could replace gendered language in the training captions with gender neutral language to stop our model from generalizing.
Division of labor:
- Jacob Axel (jaxel): Building Model: Train & Test Functions
- Paul Molnar (pmolnar): Preprocessing Data
- Will Beakley (wbeakley): Training and Testing: Hyperaerated Optimization
- Enahm Oscar-Phoenix (eoscarph): Building Model: Call, Accuracy and Loss Functions


Log in or sign up for Devpost to join the conversation.