-
-
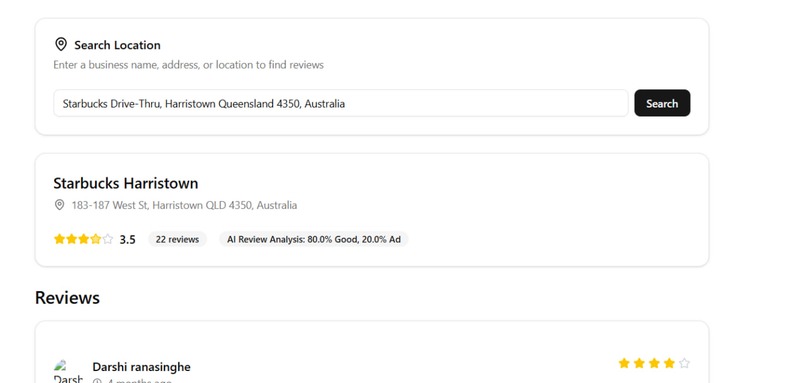
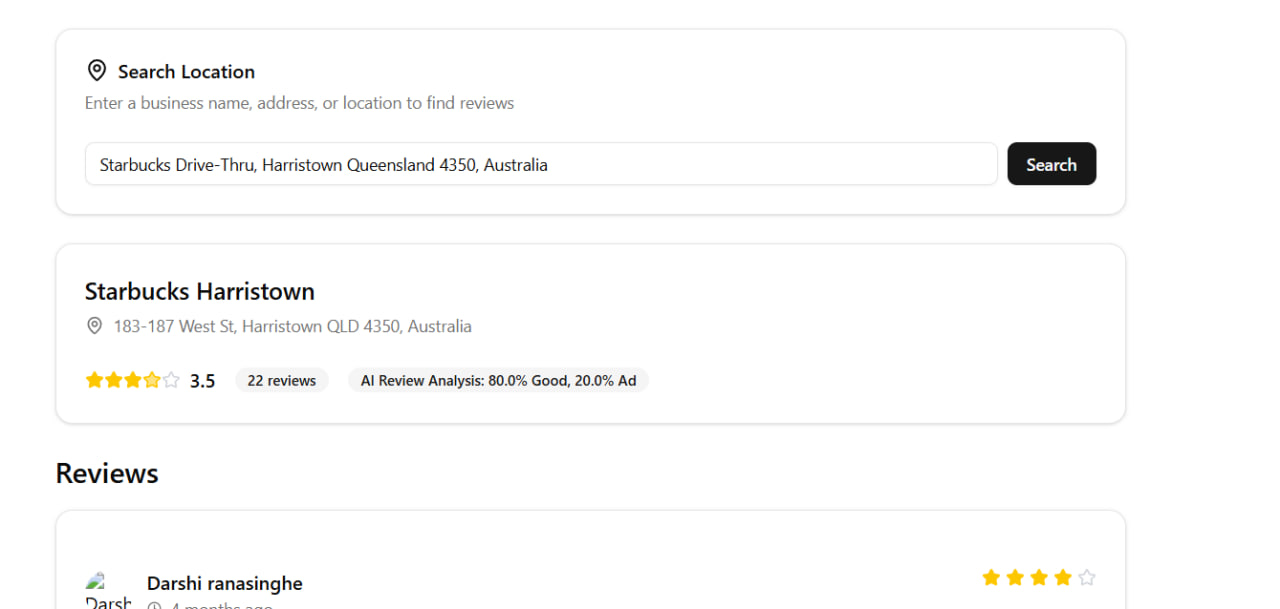
Picture of our front end search engine
Inspiration
We noticed how online reviews are flooded with fake promotions, rants, and outright spam. It’s noisy, unfair to real businesses, and confusing for users. We wanted to build something that can separate genuine voices from the chaos like noise-cancelling headphones, but for reviews.
What it does
Our system automatically moderates reviews by classifying them as Good, Ad, Rant, or Spam. Obvious spam or ads get flagged with simple rules, while trickier cases are passed to a transformer model fine-tuned with pseudo-labeling. On top of that, we built a simple frontend where users can key in a verified address and we fetch reviews directly using the Google Maps API and run them through our model and produce a cleaner and more trustworthy feed of reviews.
How we built it
We started with regex rules to catch “low-hanging fruit” (URLs, phone numbers, gibberish). For everything else, we trained Hugging Face transformers. Since we didn’t have perfectly labeled data, we built a pseudo-labeling pipeline: a teacher model assigns confident labels to undecided cases, then balances the dataset for training. We also experimented with oversampling, class weights, and confidence thresholds to make the model robust.
Challenges we ran into
- Data imbalance: Only a handful of spam/ads vs. thousands of good reviews.
- False positives: Excited reviews (“Best burger!!!!!”) often looked like spam.
- Pipeline complexity: Getting regex, pseudo-labeler, and transformer training to play nicely took a few late-night debugging sprints.
- Stratification errors: Turns out you can’t split a dataset if one class only has 1 sample.
Accomplishments that we're proud of
- Built a hybrid system where rules + transformers complement each other.
- Created a self-improving labeling pipeline that works even with limited ground truth.
- Got the model to recognize not just ads, but also “Rants” — making moderation smarter than a binary good/bad filter.
- Survived data cleaning marathons without losing our sanity.
What we learned
- Regex is great for obvious cases, but terrible for nuance.
- Sometimes, the hardest part of ML isn’t the model, but the data pipeline.
What's next for Team Sleeper Build
We want to:
- Expand label categories (e.g., sarcasm, off-topic, emotional venting).
- Deploy a live moderation API that businesses and platforms can plug into.
- Explore active learning: let the model flag “unsure” cases and ask humans to resolve them, feeding back into training.
- Keep fine-tuning until our model can tell the difference between “spammy” excitement and genuine enthusiasm.
Built With
- confusion-matrices
- google-maps
- huggingface-transformers
- pandas
- pytorch
- scikit-learn




Log in or sign up for Devpost to join the conversation.