-
-
AI-powered classifier
-
-
-
AI Document Classifier — A Dual-LLM Approach to Trustworthy Compliance Automation
Inspiration
Every enterprise today is drowning in unstructured information — scanned contracts, reports, invoices, and emails. While automation exists for document ingestion, trustworthy classification remains an unsolved problem.
What We Built
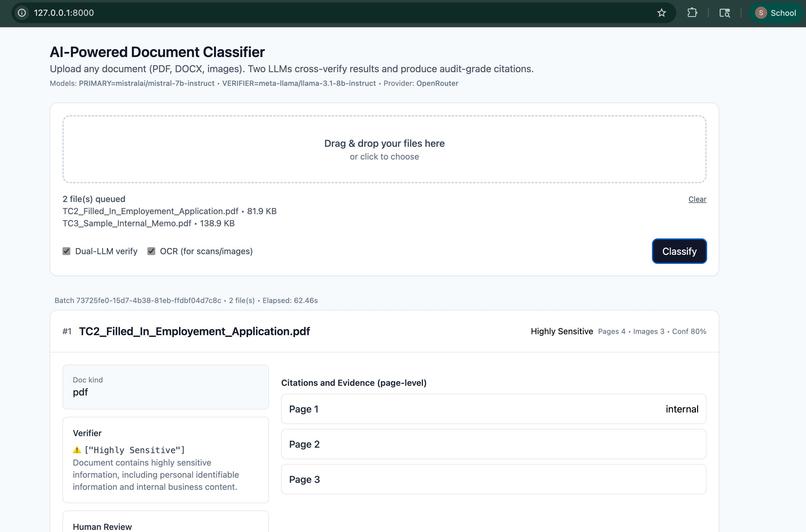
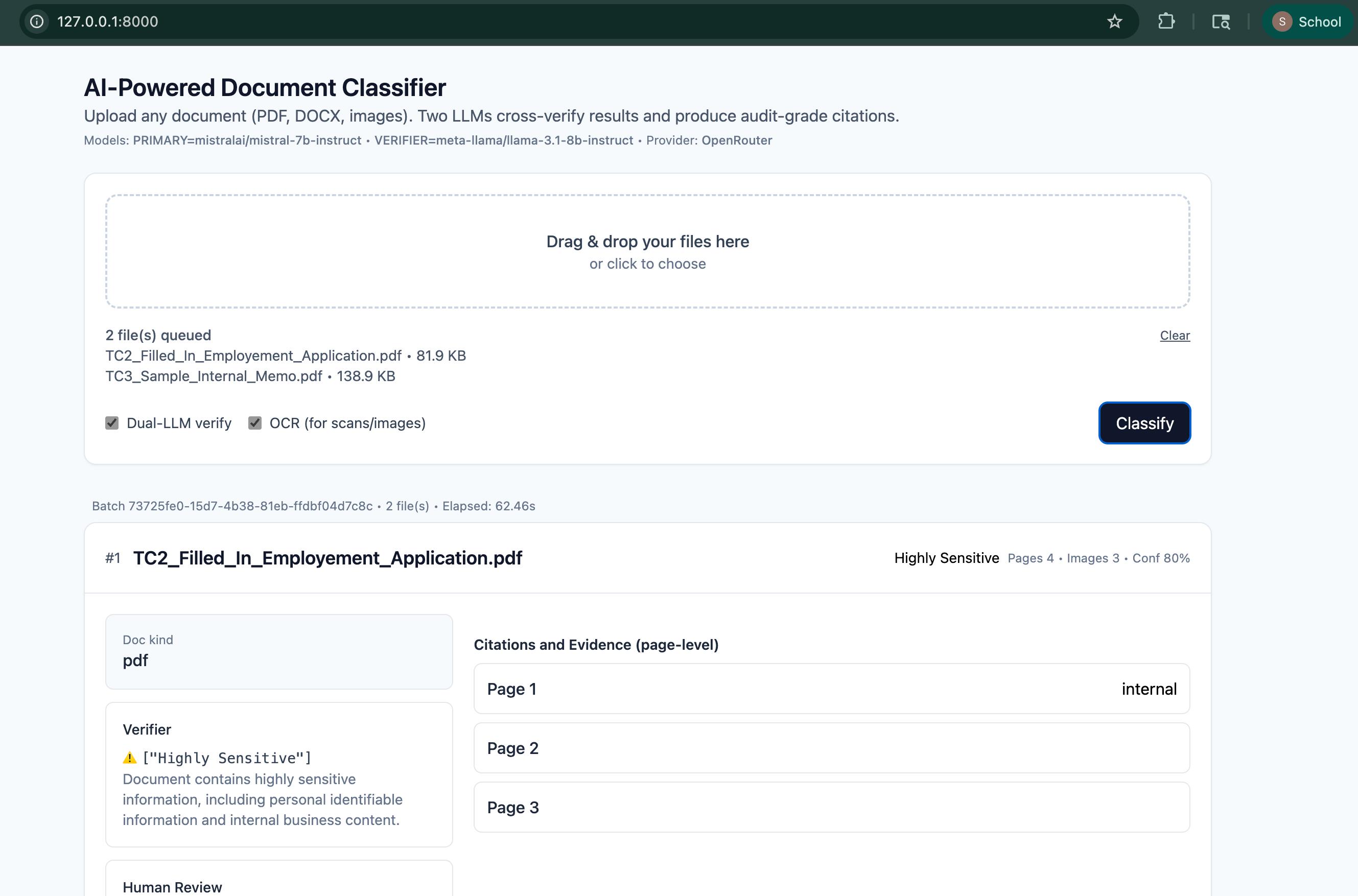
We built AI Document Classifier, a full-stack Flask application that uses two LLMs in tandem to classify documents with cross-verification and human-in-the-loop review.
The app supports: • Multi-modal input: PDF, DOCX, images, and video (via frame extraction + OCR). • Dual verification: Primary and verifier LLMs cross-check each other’s output for consistency. • Citation-based evidence: Each decision cites the exact page, image, or paragraph. • HITL feedback loop: Subject Matter Experts can approve, reject, or override model predictions. • Pre-processing checks: OCR legibility, page count, image count, and format validation. • Safety and bias detection: Flags Unsafe or disallowed content and routes for manual review. • Interactive and batch modes: Real-time updates for single documents and bulk processing. • Secure PII handling: Detects presence of PII types (like SSNs, emails) without revealing actual data. • Rich UI: Modern Tailwind-based dashboard with classification cards, badges, and detailed audit trails.
How We Built It
- Preprocessing and Extraction
We began with multi-modal ingestion using: • PyMuPDF (fitz) for PDFs • python-docx for Word files • PIL + pytesseract for OCR on images • Video support using frame extraction with OpenCV Each file runs through a legibility and metadata check before classification.
- LLM-Driven Classification
The classification follows a two-layer pipeline: 1. Primary Model (e.g., mistralai/mistral-7b-instruct) analyzes the text and metadata to predict document sensitivity. 2. Verifier Model (e.g., meta-llama/llama-3.1-8b-instruct) independently audits that output and confirms or disputes it.
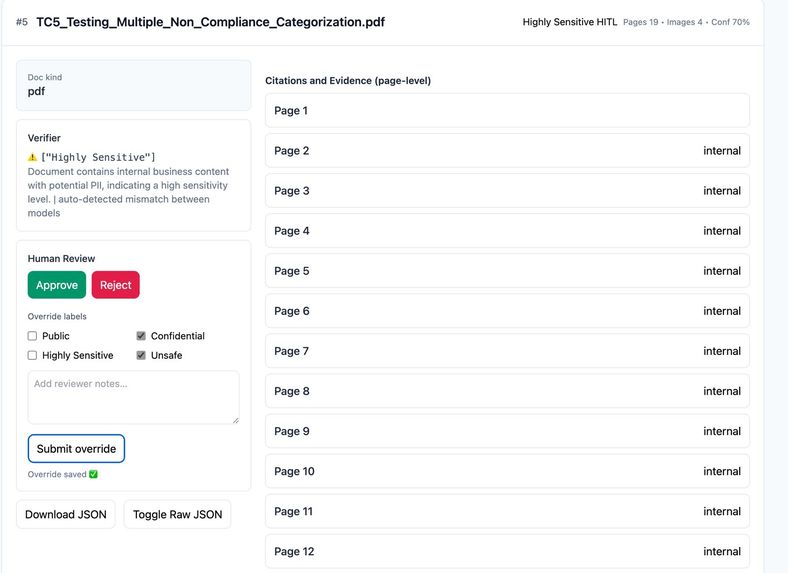
The models communicate via the OpenRouter API with strict JSON schemas to enforce consistent outputs. If the two models disagree, the case is automatically marked for human validation.
- Aggregation Logic
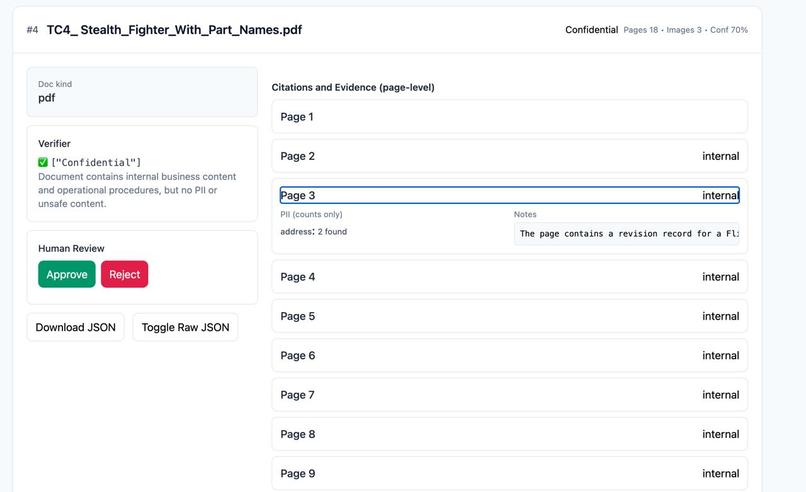
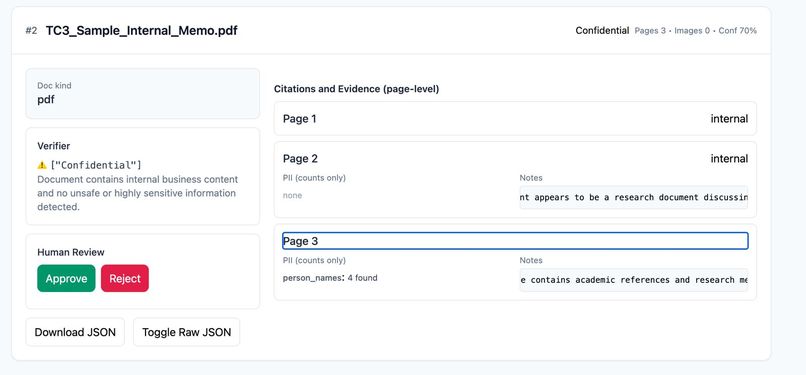
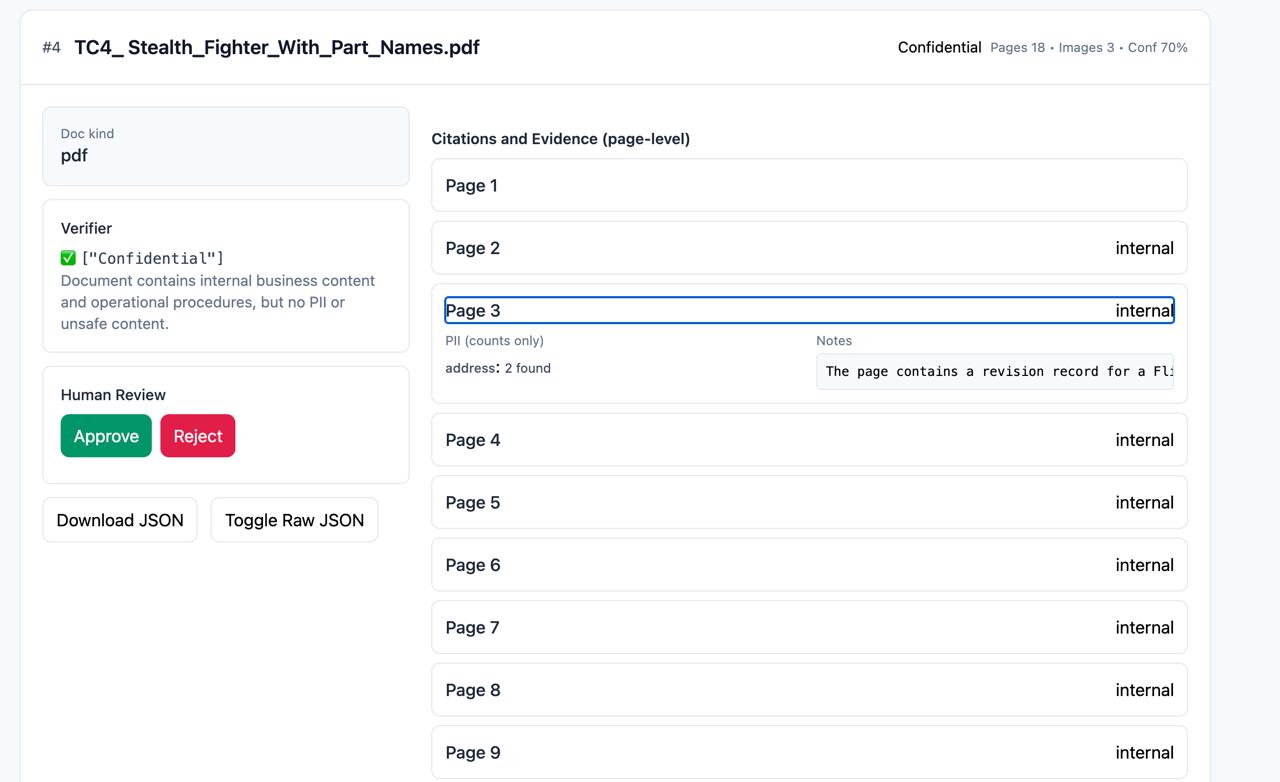
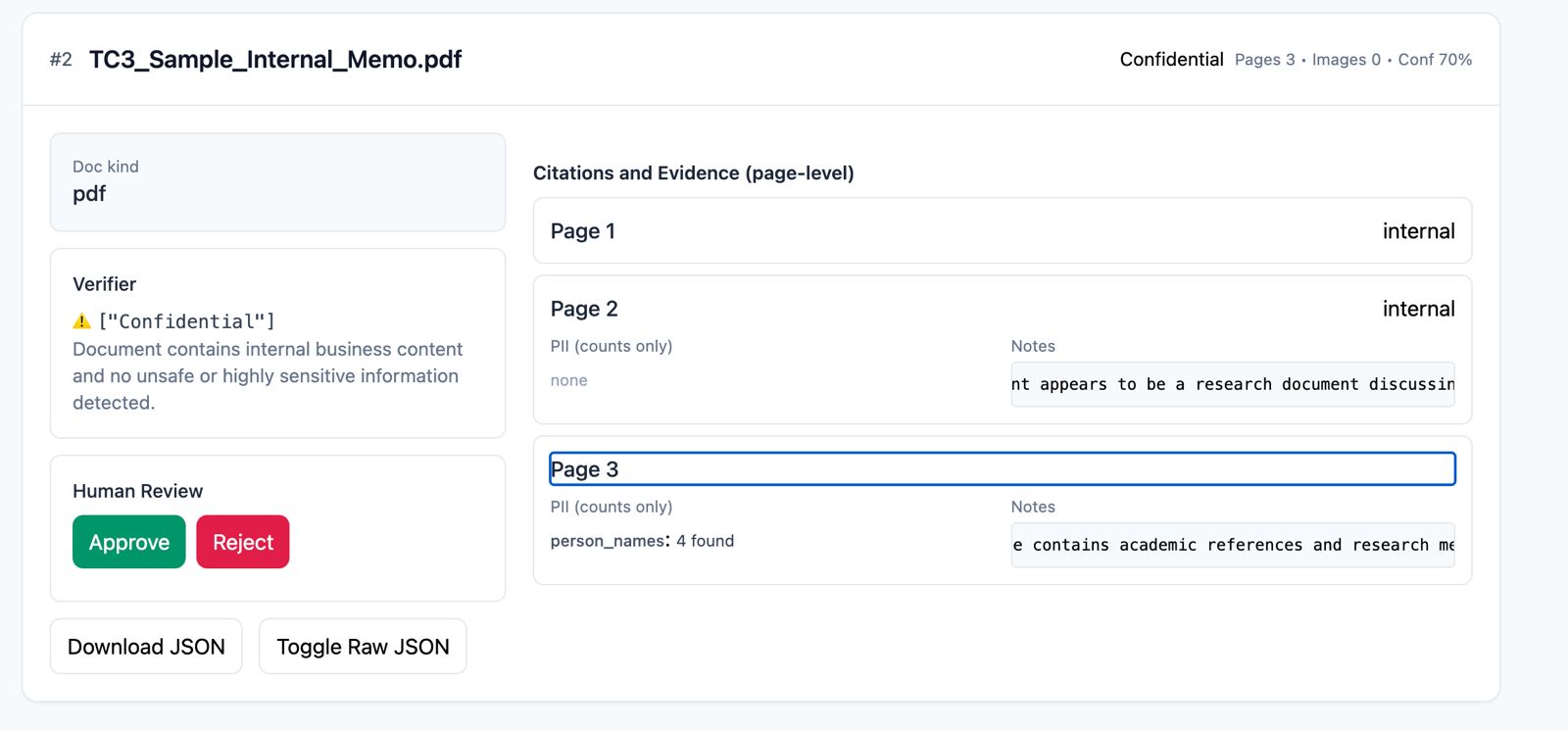
The system enforces a strict hierarchical rule: DocumentClass = a. Unsafe - if any page has unsafe content b. Highly Sensitive - if any hard PII is found c. Confidential - if any internal-only content exists d. Public - otherwise
This ensures a single, overall classification for each file, even if individual pages differ.
- Frontend and UX
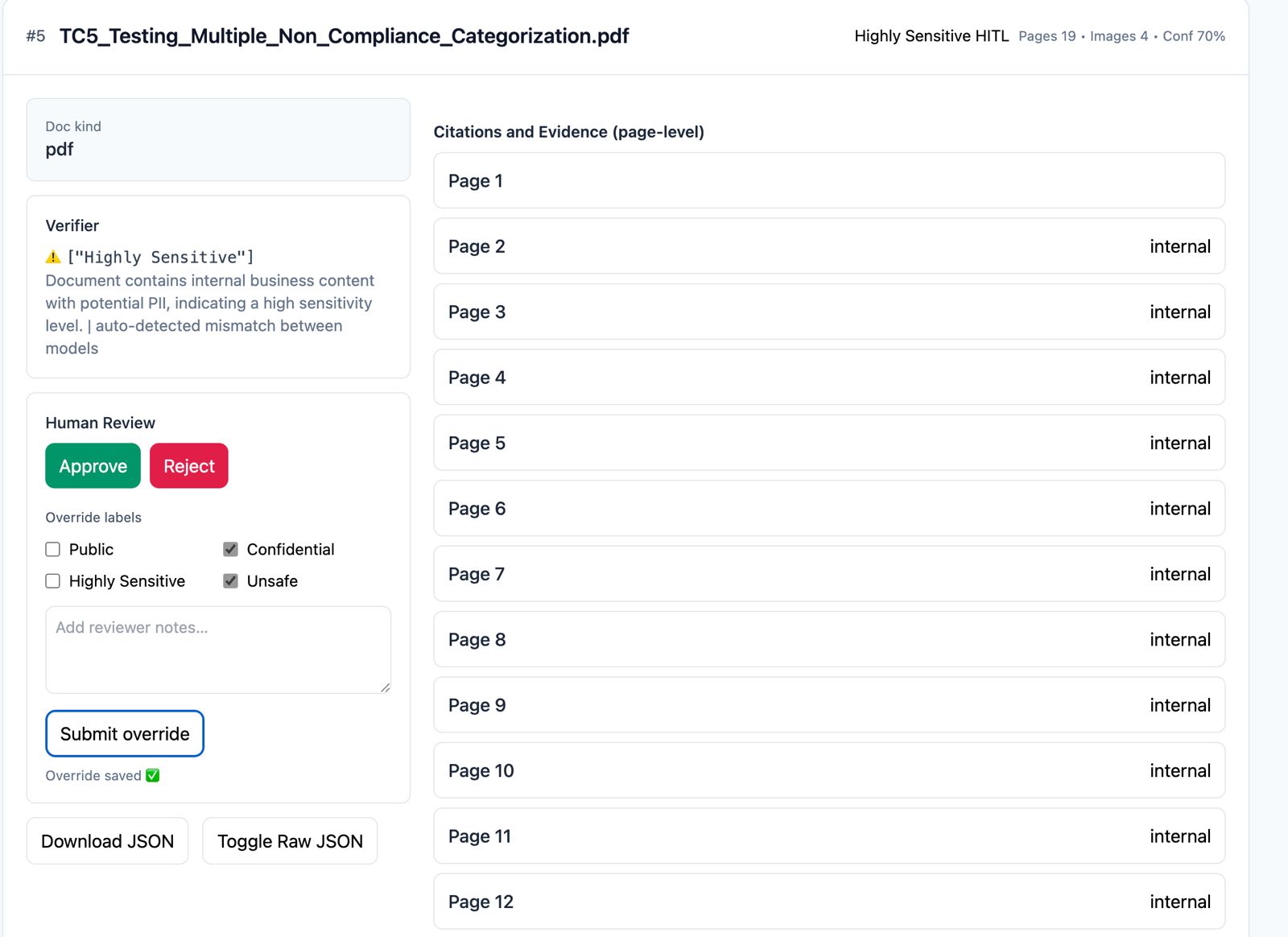
The web app (built with Flask + Tailwind) enables drag-and-drop upload, progress indicators, and visualization of results. Each card includes: • Classification badges • Confidence scores • Evidence summaries • Page-level reasoning • Review actions (Approve / Reject)
All human feedback is persisted in an append-only HITL audit log (hitl_feedback.jsonl), preserving version history.
Architecture Overview
User Upload → Preprocessing (OCR, Page Check) → Primary LLM (Classification) → Verifier LLM (Cross-Check) → Aggregator (Page → Doc Label) → Safety Layer (Unsafe Detection) → Human Review UI (Approve/Reject) → Audit Logs + Continuous Learning
What We Learned
1. Prompt engineering is an art. Small phrasing changes dramatically impacted consistency and JSON validity.
2. Dual-LLM verification boosts trust — even when models disagree, surfacing that disagreement builds confidence.
3. Human feedback is data. Capturing SMEs’ overrides allowed us to iteratively refine prompts.
4. Security by design matters. Redacting all PII before frontend rendering ensured GDPR and compliance safety.
5. Real-time UX matters as much as AI accuracy. Users value transparency — knowing why a classification was made.
Challenges We Faced
• Handling multimodal inputs: OCR on mixed documents with both text and images required robust error handling.
• Maintaining strict JSON outputs: Some models occasionally broke schema, requiring regex-based JSON repair.
• Latency from dual-model verification: We optimized with async requests and early termination when Unsafe content was detected.
• Balancing detail vs. privacy: Showing “PII types” (email, SSN, etc.) without exposing the actual data required careful design of summaries.
• Integrating human feedback loops: Making reviewer actions persist seamlessly while keeping logs immutable took several iterations.


Log in or sign up for Devpost to join the conversation.