Google Location Review Quality Assessment
Inspiration
In an era where online reviews significantly influence consumer decisions, maintaining the integrity of these reviews is paramount. We were inspired by the challenge of sifting through vast amounts of user-generated content to ensure that genuine, helpful feedback rises to the top. The prevalence of spam, irrelevant content, and unhelpful rants on platforms like Google Maps not only degrades the user experience but also unfairly impacts businesses. This project was born out of a desire to create an intelligent, automated system that can uphold the quality and relevance of location-based reviews, fostering a more trustworthy online ecosystem for both consumers and businesses.
What it does
Our project is an advanced ML-based system designed to evaluate the quality and relevancy of Google location reviews. At its core, the system addresses the following key challenges:
- Gauges Review Quality: Intelligently detects and flags various forms of low-quality content, including spam, advertisements, irrelevant reviews, and rants from users who have likely never visited the location.
- Assesses Relevancy: Determines whether the content of a review is genuinely related to the location being reviewed, ensuring that feedback is contextually appropriate.
- Enforces Policies: Automatically filters out reviews that violate content policies, such as those containing promotional material or off-topic discussions.
This is achieved through a multi-stage pipeline that processes, labels, and classifies reviews, culminating in a robust quality assessment model.
How we built it
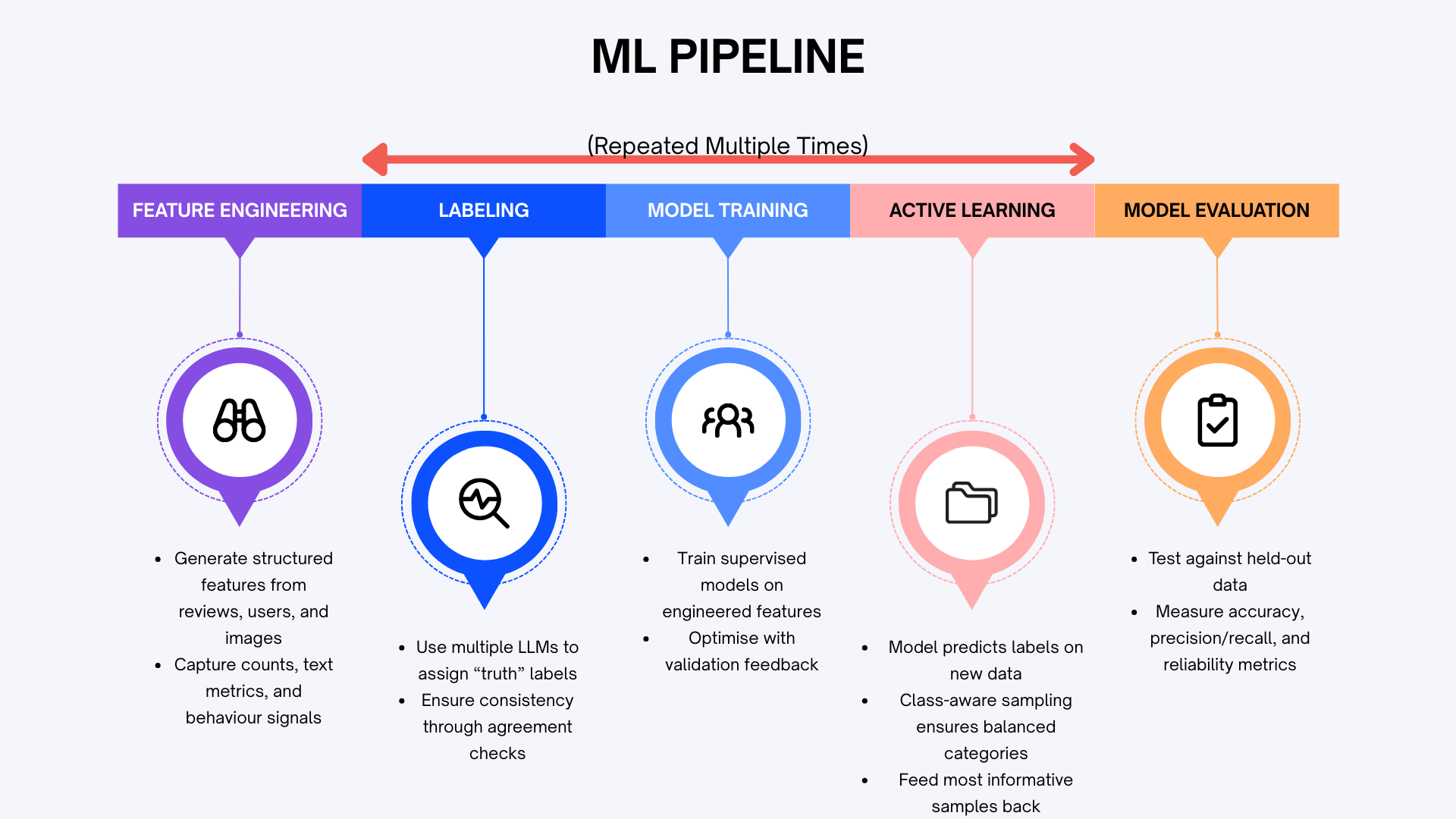
Our solution is a comprehensive pipeline that transforms raw review data into actionable quality insights.
Data Preprocessing and Feature Engineering
- Cleaning: Handling missing values and standardising formats.
- Textual Features (NLP): Sentiment analysis, topic modelling using LDA, and keyword extraction.
- Metadata Features: Review length, posting time, user history, etc.
Pseudo-Labeling with Multiple LLMs
To address the challenge of acquiring a large, accurately labeled dataset, we employed multiple large language models (LLMs)—Mistral, Gemma, and Llama—to generate pseudo-labels. By presenting each model with the same policy definitions, we created a diverse set of initial labels.
Hybrid Machine Learning Approach
Our hybrid model combines the strengths of different data types:
- Text Branch: DistilBERT model with LoRA for efficient fine-tuning on review text.
- Categorical Branch: Embedding layers for categorical features (e.g., day of week, dominant topic).
- Continuous Branch: Feed-forward network for numerical features such as sentiment score and review length.
Active Learning Pipeline
We integrated active learning to reduce the need for manual labeling. This system identifies the most uncertain and informative samples, ensuring progressively stronger training data.
Challenges we ran into
- Data scarcity: Lack of a large, labelled dataset for training.
- Solution: Used multiple LLMs for pseudo-labeling.
- Consistency issues: AI-generated labels varied in quality.
- Solution: Implemented a multi-model consensus mechanism with Fleiss' Kappa to measure inter-rater agreement and filter high-confidence labels.
Accomplishments that we're proud of
- End-to-End Pipeline: We successfully built a complete, end-to-end pipeline that handles everything from raw data ingestion to feature engineering, model training, and evaluation.
- Innovative Data Labeling: Our use of a multi-LLM consensus mechanism for pseudo-labeling is a novel solution to the common problem of data scarcity in machine learning projects.
- Sophisticated Hybrid Model: Three-branch architecture combining NLP, categorical, and numerical data streams.
What we learned
This project was a tremendous learning experience. We gained deep insights into the nuances of prompt engineering and the importance of clear, unambiguous policy definitions for achieving consistent results from LLMs. We also learned the value of a multi-model approach, as different models exhibited different strengths and weaknesses. Finally, the process of building a feature engineering pipeline from scratch reinforced the adage that data quality is the foundation of any successful machine learning system.
What's next for Team Brothers
- Real-Time Analysis: Analyse and flag reviews as they are submitted.
- Interactive Dashboard: A moderator dashboard to review flagged content and provide feedback for model refinement.
- User Feedback Integration: Incorporating helpfulness ratings (e.g., “Was this review helpful?”) as additional signals.
Built With
- Development Tools: Visual Studio Code, Google Colab, Jupyter Notebook
- APIs: Hugging Face API
- Libraries and Frameworks:
- Core: pandas, scikit-learn, NLTK
- Deep Learning: PyTorch, Hugging Face Transformers
- LLMs: Mistral, Gemma, Llama, Qwen
- Core: pandas, scikit-learn, NLTK
- Assets and Datasets: Google Local Reviews dataset
Built With
- gemma
- google-colab
- hugging-face-transformers-llms:-mistral
- huggingface
- jupyter-notebook-**apis:**-hugging-face-api-**libraries-and-frameworks:**-core:-pandas
- llama
- nltk-deep-learning:-pytorch
- qwen
- scikit-learn











Log in or sign up for Devpost to join the conversation.