-

Landing Page
-
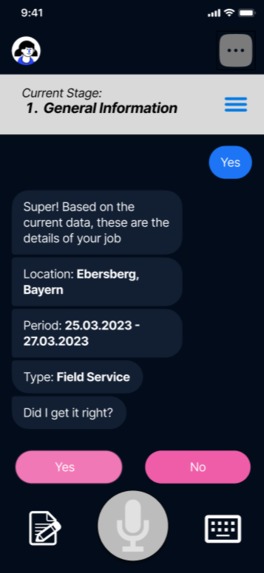
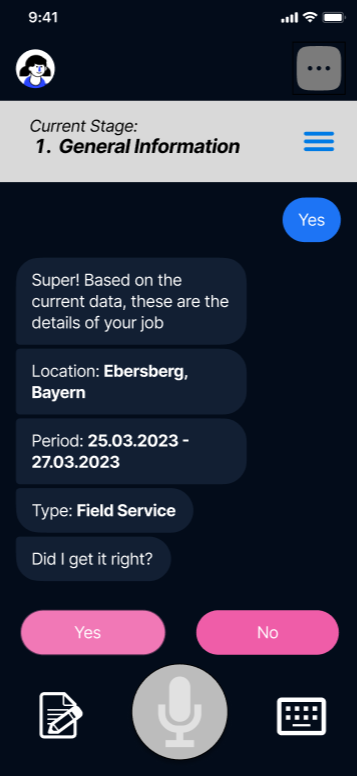
Guided Chat Process for Generating your Report
-
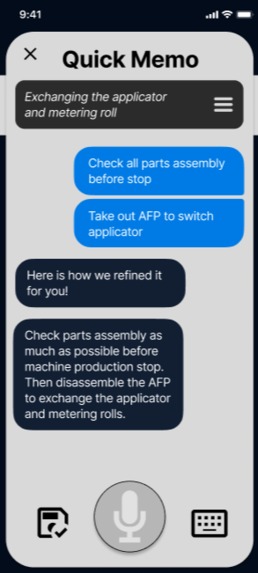
Quick Memo Interface


Inspiration
The challenge of overcoming burdensome paperwork is a shared struggle that affects millions globally. For some, it can hinder their ability to reach their full potential, especially among blue-collar workers. In response, we developed an easy-to-use, efficient chatbot to assist with this issue. However, concerns surrounding data security and confidentiality in the business context have limited the adoption of popular options like GPT.
Understanding these concerns, we opted for an alternative, the Alpaca model, which boasts 7 billion parameters. By fine-tuning it for optimal performance, we created an efficient web app that addresses paperwork challenges without compromising data security. This user-friendly solution enables individuals to overcome barriers and achieve greater success in their professional lives.
What it does
At its core, it is a chatbot assistant that helps technicians who may not be fluent in English or German to easily generate a service report for everyone to see.
It guides the users through a step-by-step process to accurately fill in the gaps in their voice/text/camera responses, and prompts them for more information if so as to fill in the gaps in their report. At the an it generates a pdf report that is shared with their supervisors. A summary version of the report, translated into other native language, will also be available for their colleagues.
It includes other simple feature such as quick memo: one that automatically transcribe your speech and convert it into report-styled text. These quick notes will be used to prompt the users when filling in the report.
How we built it
The prototyping was done using Figma. The frontend chatbot interface was developed using the Nuxt.js, which makes API calls with prompt engineering to our trained Alpaca model trained in the Azure Machine Learning Suite. Our model is trained on samples of service reports, technical instruction manuals, internship reports and police reports among many.
Challenges we ran into
Given the short timeframe, we were not able to implement all our expected features, especially in terms of refining our backend database to store and process the current information of each technician. Some of the other good-to-have features were not developed in time too. In terms of our Machine Learning model, we could implemented more selection criteria with more time and expertise.
Accomplishments that we're proud of
Our team has made significant strides in the development and implementation of our machine learning model. We have successfully identified solutions, such as utilizing police records and internship reports, to gather the necessary data for training our model. In addition, we conducted extensive research and testing to determine the most effective model for our purposes, ultimately selecting the alpaca model.
What we learned
Throughout this process, we have gained invaluable knowledge and experience in deploying large language models (LLMs) in real-world scenarios. Our expertise has grown particularly in the areas of the Cerebra family of models and data mining techniques. Overall, our hands-on approach has enabled us to effectively apply LLMs in practical applications, setting the foundation for future advancements in the field.
What's next for Team Artificial Incompetence
It was a good learning experience, and hoping to develop our project further. Peace out from one of the most diverse team in town!

Log in or sign up for Devpost to join the conversation.