-
-
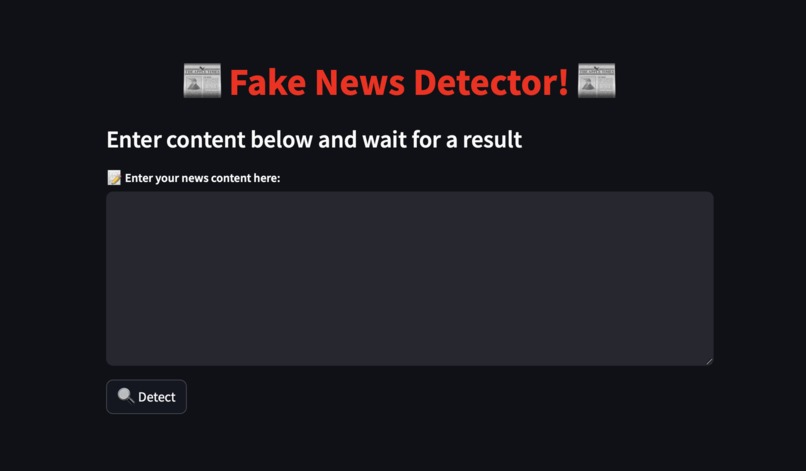
Website at the start.
-
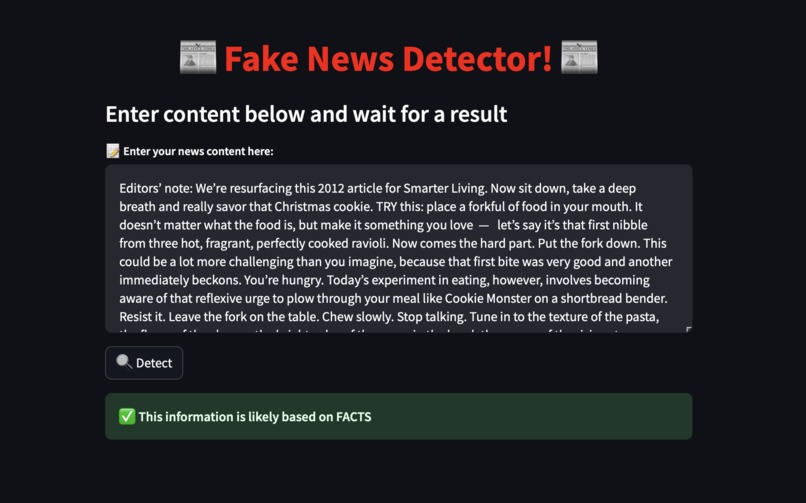
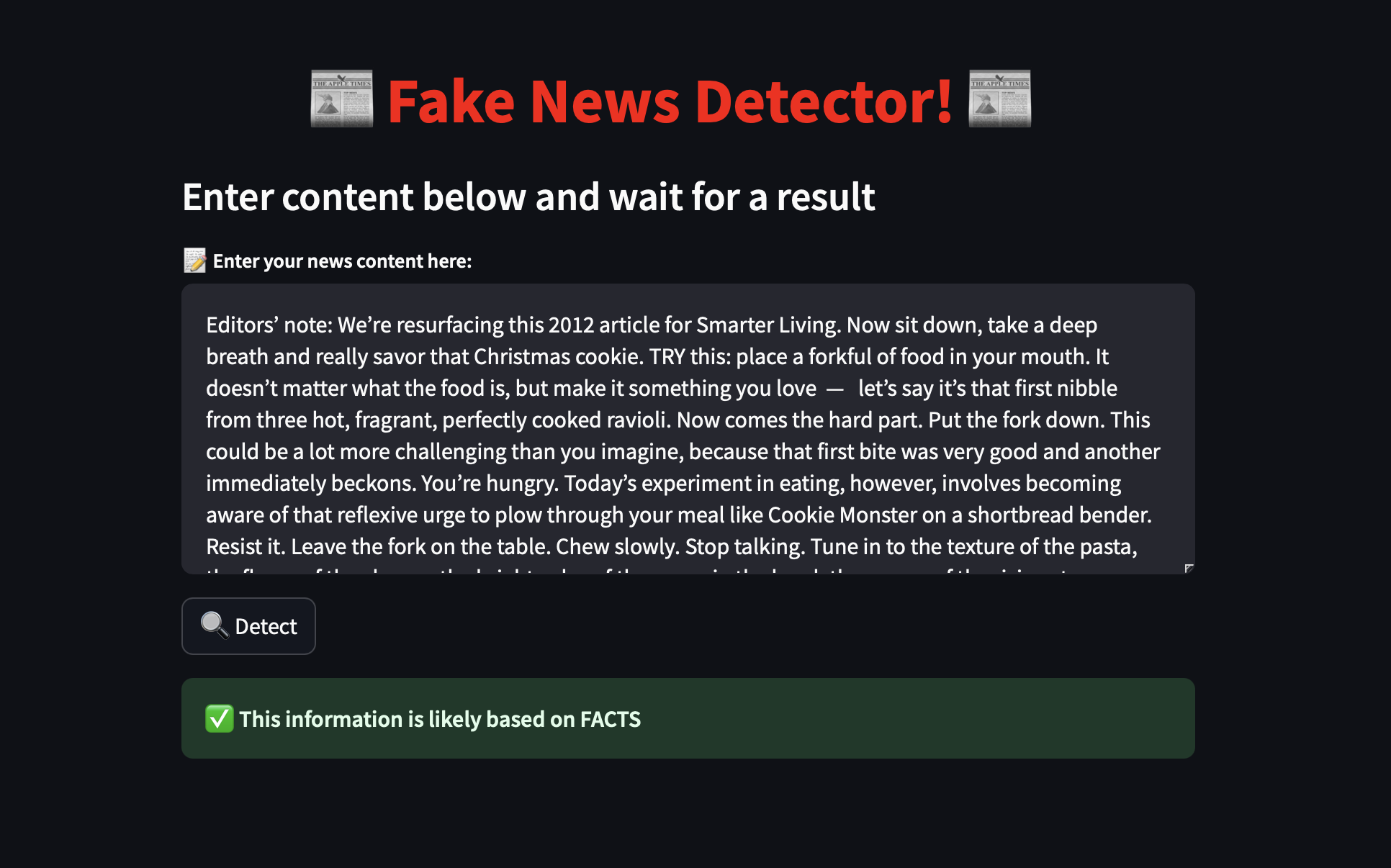
Output if a reliable news article was given.
-
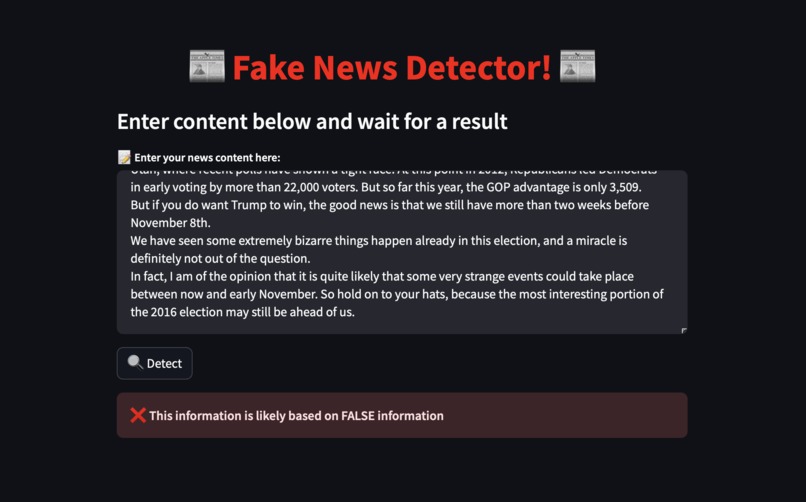
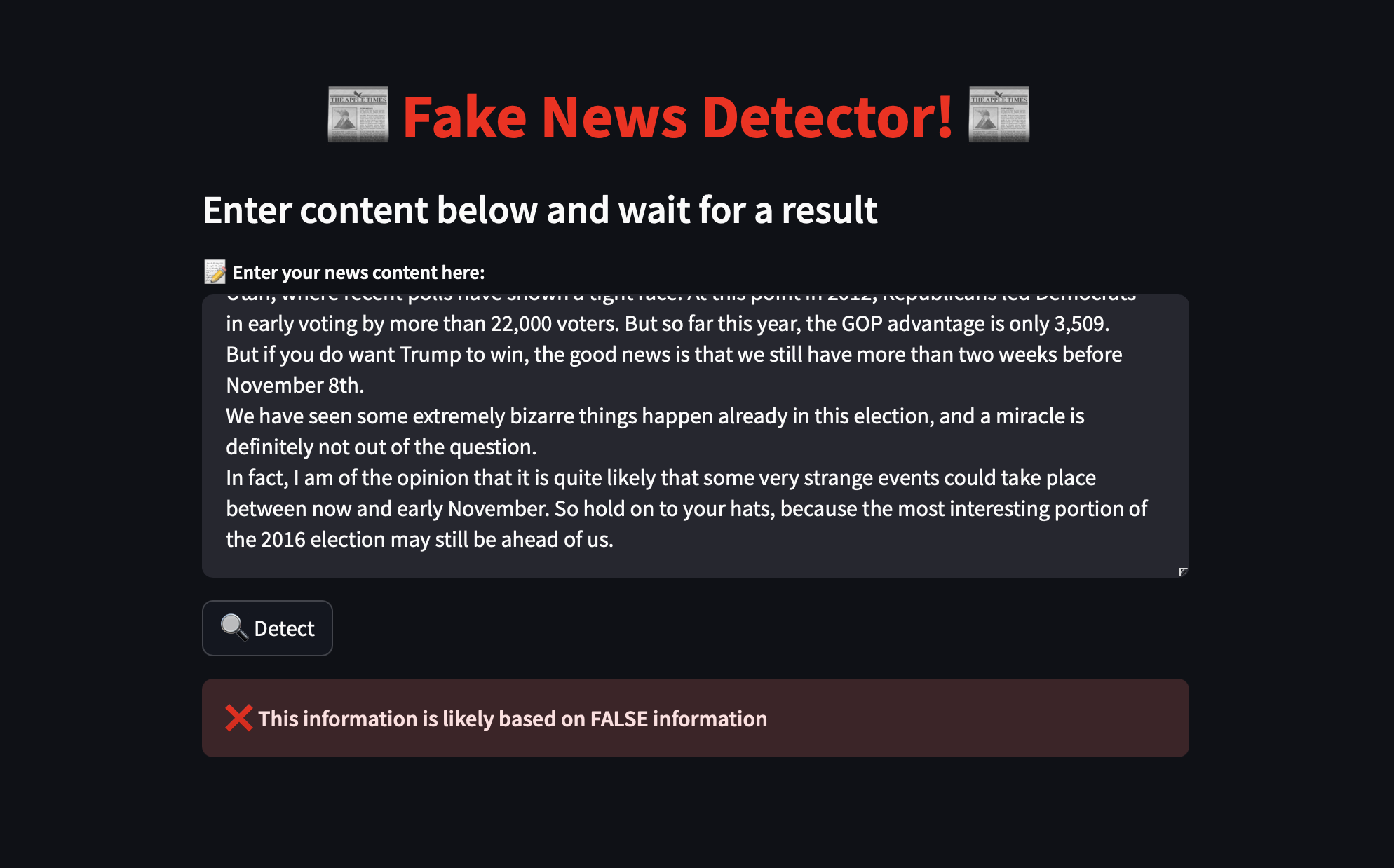
Output if an unreliable news article was given.
Inspiration
We were inspired to make a website as it was very simple and straightforward for the average non-tech user to use — a website requires no downloading and can run on any operating system and any browser, as long as the user has an internet connection.
What it does
The website takes in text-based news articles and gives a binary result: the news article is either reliable or unreliable. This dual result makes it easy for users to understand and ensures that they do not second-guess themselves. It also makes the result less open to misinterpretation.
How we built it
For simplicity and scalability, the entire project was built on Python.
The dataset was initially proposed to be web scrapped, but the idea was passed over for a Kaggle dataset instead due to the complexity and time required for creating a scraping bot and the scraping itself.
We decided to use natural language processing to analyse our data as the input is supposed to be text-based. We first stem the training data to ensure that only words of semantic value remain. Afterwards, we vectorised the data and used decision tree classification to train the model. We then had to export the model and put it into the website we created. Lastly, the website was created and deployed using streamlit as it allowed us quick and easy deployment.
Challenges we ran into
The first challenge we ran into was that two of our members were in year 1, meaning that they had little experience with data science and machine learning. Thus, the other two members had to quickly get them up to speed and explain to them how we wanted to implement our project idea so that everyone could help out.
The second challenge was that the other two members were software engineers by trade, meaning that they were more familiar with creating apps and websites than they were with data science. However, as the problem statement of this hackathon was based on data science, they had to quickly research how to clean data, which models to use, as well as how natural language processing worked. Despite this lack of knowledge, they also had to ensure that the project idea was feasible before starting, something that they spent many hours on beforehand as there would not have been enough time to start over.
Accomplishments that we're proud of
We are very proud that we could deploy and train the model in just four days. We also achieved an internal accuracy score of >98%. We are glad that despite the lack of formal training and experience that we have with data science, we were able to come up with an idea and executed it well in just 96 hours.
What we learned
Throughout this project, we gained valuable insights into data science, machine learning, and website deployment. Our team members with little prior experience in data science quickly adapted by learning how to preprocess data, select appropriate models, and implement natural language processing techniques. Meanwhile, our more software-oriented members expanded their knowledge beyond development, diving into data cleaning and classification methods to ensure the model performed effectively.
We also learned the importance of adaptability and teamwork. Overcoming technical challenges, working under time constraints, and ensuring the project remained feasible required effective communication and collaboration.
Built With
- python
- streamlit

Log in or sign up for Devpost to join the conversation.