-
-
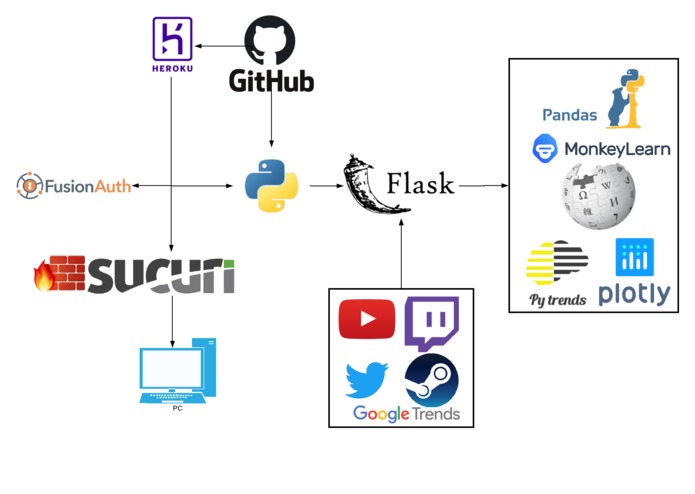
Infrastructure diagram

Inspiration
We were inspired by RealTeamSteam's (RTS) mission to educate adults with science, technology, engineering, and mathematics, or STEM, by bridging the gap between pop culture and STEM. RTS is currently spending loads of time manually researching for pop culture events and related STEM research in order to find content for educational presents at large conferences, such as Phoenix Fan Fusion (formerly Phoenix Comic Con). After researching existing solutions and brainstorming together, we found there is a missing hole in research tools to find the intersection between STEM and trending pop culture. It has taken RTS 3 months to crawl through all the data manually! We can increase efficiency, accuracy, precision, and time management for research for all non-profits, educational platforms, and specialized research.
What it does
We created a web application that it designed to search for the intersection between Pop culture and STEM articles. The application then does the following features:
- Create CSV file of raw data, data analytics, and dates with time stamps
- Easy deploy to Heroku button
- Search button for Pop Culture topics that searches for STEM topics
- Generate Analytics from data as well as summary data
- Generate readable graphs from data
- Display timeline of trending events
- Finding similarity index of Pop culture article with STEM topic
Our automated that process in 5 minutes, saving 3 months of time for the organization. The user options were predicted through data and automated with an intuitive solution.
How we built it
For our beautiful visual demonstration, view our infrastructure diagram. We built a python application built in Flask framework that uses Python libraries Plotly, MonkeyLearn, Wikipedia, Pytrends and the Panda data frame to output analytics, visualization, and time trends. The python application mines from social media feeds such as Twitter, Twitch, Google Trends, YouTube, Steam, and other popular sources to get the relevant pop culture topics. From there, the application is deployed to Heroku with FusionAuth. Between the client and the server, there is a Sucuri firewall security layer.(which can be replaced with another recommended layer, see our thorough security documentation).
Challenges we ran into
Our team had so many issues with Heroku hosting! We had so many different issues with Python libraries, Flask framework, and Heroku path variables that we had to debug. But with hours of sifting through StackedOverflow, Heroku documentation, and asking a billion questions to our wonderful mentors (a huge thanks to Greg, Bryon, Brenna, Rob, Chris, Turtle David, Other David, and Vanessa) we figured it out! And we all become mini experts in Heroku and Python Flask framework.
Accomplishments that we're proud of
After a long, sleepless 30-something hours of non-stop coding, we are extremely proud of our application and that- shockingly- it works! Here are the top 3 highlights that our group decided were our proudest accomplishments:
We went from 0 knowledge on Flask Framework to creating an full python application with it and then deploying that to Heroku! We are proud of this because of how much growth and team collaboration went into this task. Each of our team members ended up looking at this part of the project in attempts to make it work- and all learning something in the process.The debugging process was grueling with it, but afterwards we learned so much about the framework and Heroku.
We worked really hard on perfecting our gorgeous analytics from the data we mined. We wanted to create a intuitive and easy experience with finding topics and tracking popularity engagement with its designated timeline. We searched through multiple libraries to find the best Python libraries to use and put a lot of effort in UI design to display analytics.
We had amazing documentation! We implemented and proposed OWASP TOP 10 mitigation strategies, a web application firewall, and a user authentication system to comply with modern security principals. Due to the flexible and scalability our platform, we knew that this platform could be used by multiple non-profits and have potential to revolutionize specialized research. And because of this fact, we knew that documentation was very important so that any non-profit could find the technical details and non-technical instructions to pick up our application and start using it right away! In the documentation, you will find 15 pages of thorough information including: instructions on how to use our platform, UI/UX analysis and front-end description, back-end description, APIs we used, and security analysis with security recommendations. We put a lot of effort to make our application as easy and digestible to use as possible! (thank you to Rebekah and Nicole for proofreading and Troy for presentation advice and thank you to everyone who was our User Experience testers to improve our intuitive experience!)
What we learned
We learned a lot about Heroku hosting, Flask framework, Python, and data mining!
What's next for Team-6
There's a lot of potential to give our application away to other nonprofits to use for research. To help even more people, we would love to give away our code (and specialize it with more features depending on responses from our users) to more people! We would love to see this application integrated with our nonprofit, RTS, right away, and with as many non-profits as possible! In terms of technical next steps, there is room to widen our search data mining to even more pop culture references to get more raw data and more accurate data analytics.




Log in or sign up for Devpost to join the conversation.