-
-
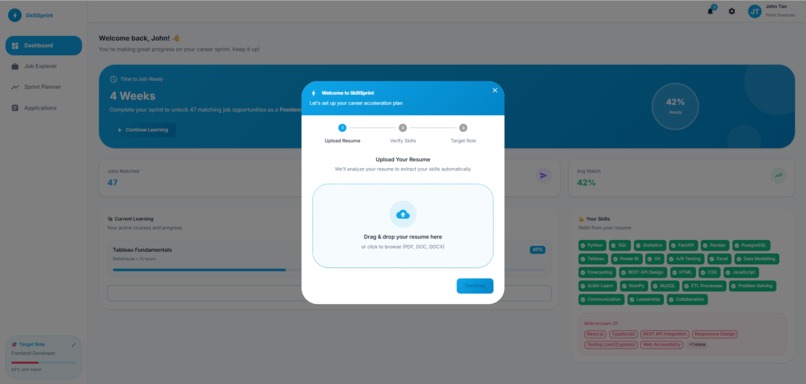
Homepage Thumbnail
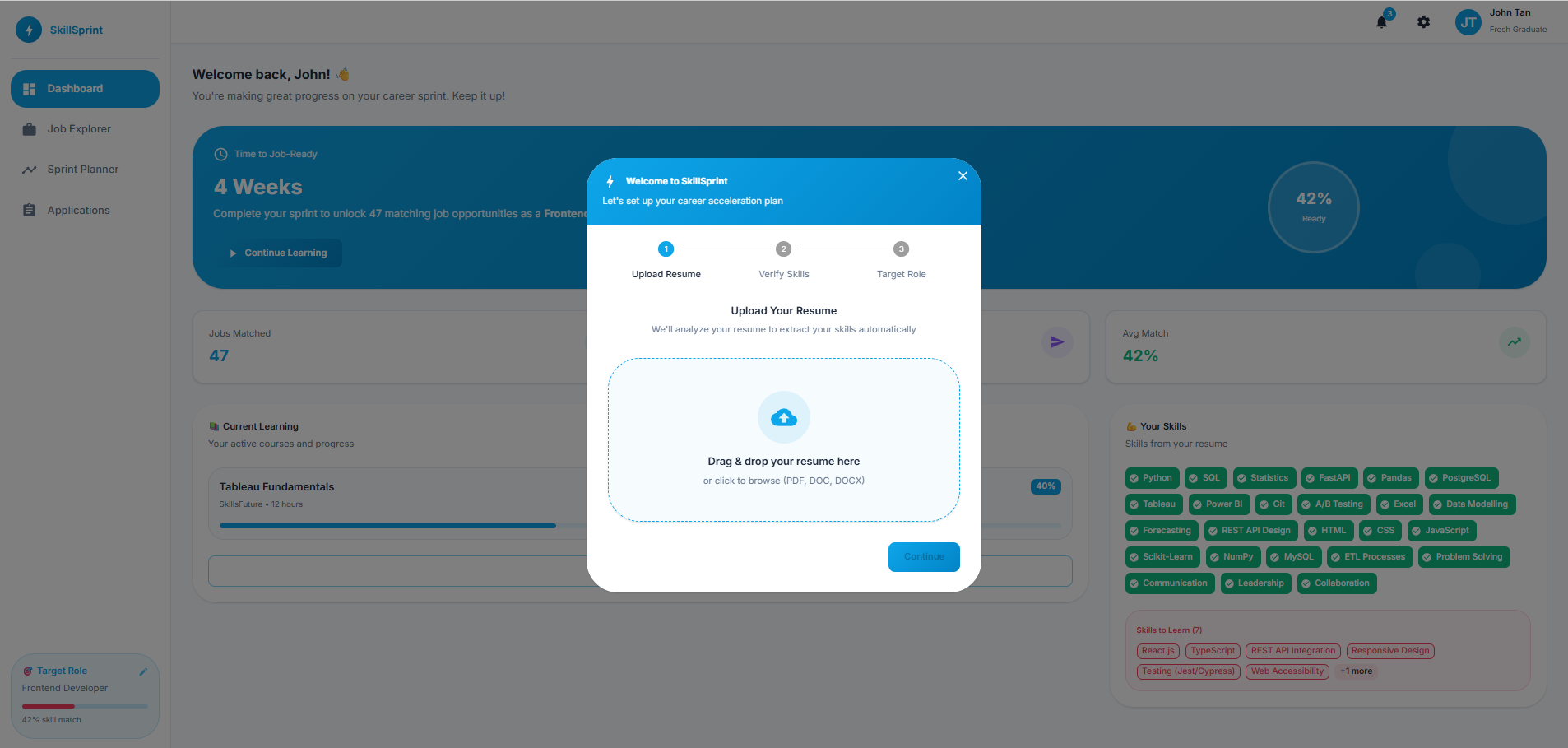
Inspiration
We've all been there—scrolling through job listings as fresh graduates, staring at endless skill requirements, and feeling completely overwhelmed. Python, SQL, Tableau, Power BI, 2+ years experience... Where do you even start? The frustrating part? The information exists. MyCareersFuture lists jobs. Glassdoor shows salaries. SkillsFuture offers subsidized courses. But it's all fragmented. There's no single place that connects what jobs need, what you already have, and how to bridge the gap. We wanted to build something that doesn't just show the problem—it solves it.
What it does
SkillSprint is a unified career platform that transforms scattered job data into personalized, time-bound learning plans. Our key innovation is the Time-to-Ready Calculator. Most platforms tell you what skills you need. SkillSprint tells you how long it'll take and exactly what to do, week by week. Core features:
- Smart Resume Parsing — Upload your resume and we extract your skills automatically
- Job Explorer with Skill Matching — Aggregated jobs from multiple sources with color-coded skill gaps (green = have, red = missing)
- Sprint Planner — AI-generated week-by-week learning roadmaps with curated resources, including SkillsFuture-subsidized courses
- Application Tracker — Kanban board to manage your job search pipeline from Saved → Applied → Interviewing → Offer
How we built it
We followed a clean architecture approach—separating data models (Pydantic schemas), business logic (service classes), and API endpoints (FastAPI routers). Our database design includes row-level security policies, performance indexes, and helper functions for skill-matching calculations. For data, we aggregated job listings from multiple sources and built a normalized skill taxonomy to handle inconsistent naming across platforms.
Challenges we ran into
Data quality was brutal. Our job dataset had missing values across location, employment type, salary, and requirements fields. We spent significant time building rule-based cleaning pipelines to extract meaningful information from unstructured job descriptions. Skill taxonomy normalization. "Python" vs "Python 3" vs "Python Programming"—different sources name skills differently. We had to create a standardized mapping to make skill-matching actually work. Scope management under time pressure. With only one day, we had to ruthlessly prioritize. The Sprint Planner was our differentiator, so we protected that scope and cut bonus features when needed. Accomplishments that we're proud of
The Time-to-Ready Calculator actually works. Seeing a concrete "4 weeks to job-ready" instead of vague advice feels genuinely empowering. End-to-end flow. From resume upload → skill extraction → job matching → learning sprint → application tracking. It's a complete journey. Clean architecture. Despite hackathon time pressure, we built maintainable code with proper separation of concerns—over 30 Pydantic models and comprehensive API endpoints. Singapore-specific value. Integration with SkillsFuture subsidized courses makes this genuinely useful for local job seekers.
What we learned
Data preparation is half the battle. We underestimated how much time cleaning and normalizing job data would take. Garbage in, garbage out.
What's next for SkillSprint
Expand data sources — Add more job boards and real-time API integrations Smarter sprint generation — Use ML to personalize learning paths based on learning pace and style Community features — Let users share successful learning sprints and course reviews Mobile app — Job searching happens everywhere; we should too Employer partnerships — Connect companies directly with candidates who've completed relevant sprints
Built With
- agentic
- fastapi
- lovable
- mui
- postgresql
- python
- react
- sql
- supabase

Log in or sign up for Devpost to join the conversation.