
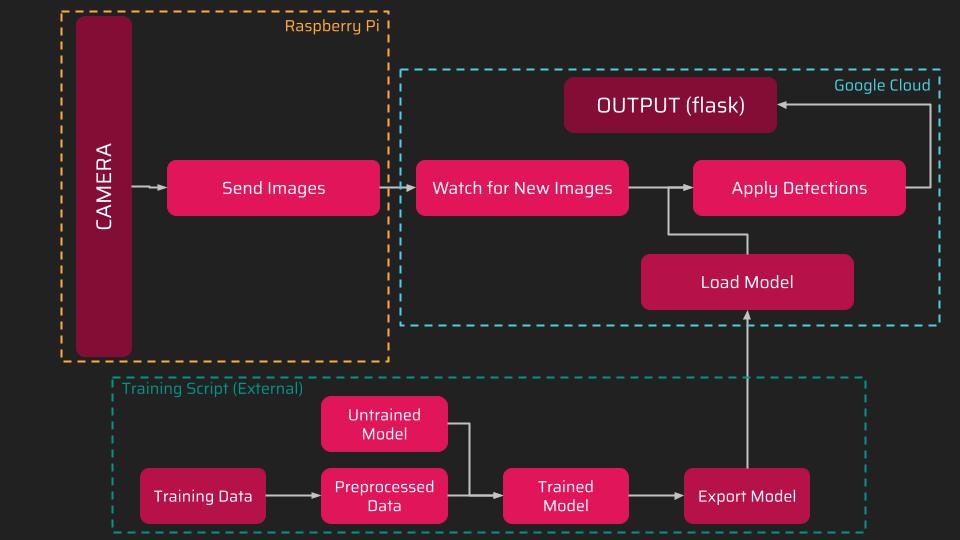
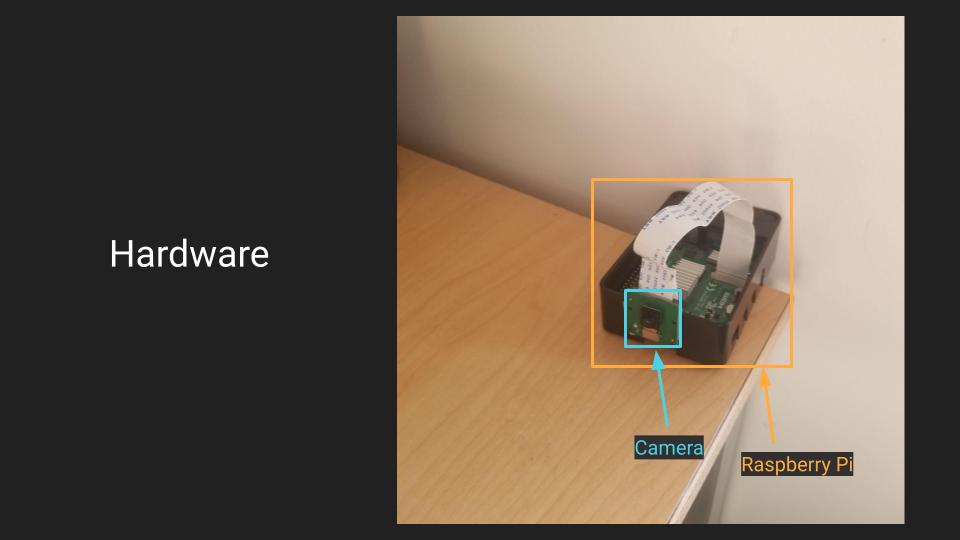

Every year thousands of people are killed by indoor fires. This project hopes to help address this problem, by assisting firefighters with identifying different victims in different locations, so that they can be more effectively evacuated. The hardware of the system contains a camera bundled with a raspberry pi which faces a room, and then these setups are replicated and placed wherever possible throughout the building, so that once a fire has been detected, they can be activated and will start streaming live detections to a website, easily accessible by firefighters from any device. Therefore, firefighters will be able to identify the locations of victims, and the number of people at each, in order to determine which groups are in the most immediate danger, and accurate measures of how many people are still within the building, so that they can effectively prioritize and handle the situation when arriving on scene.
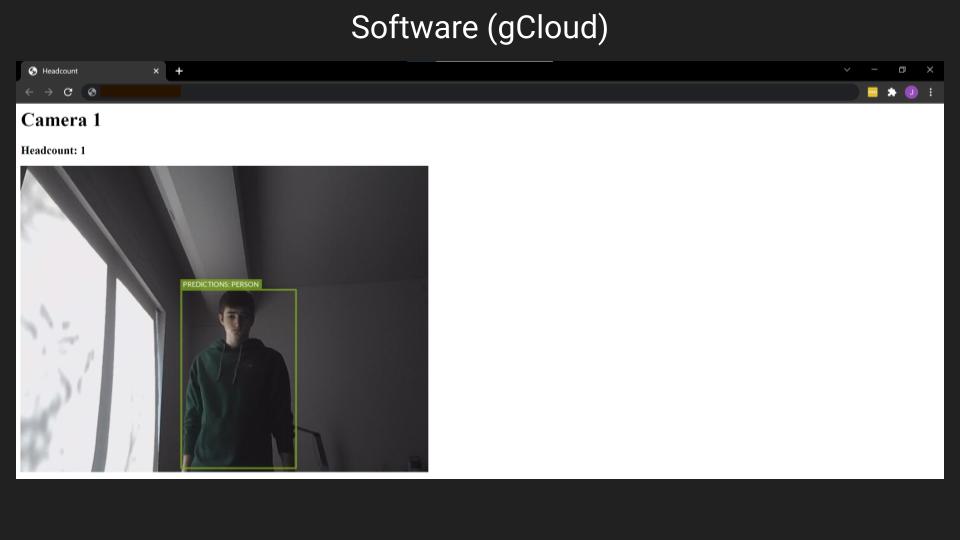
My prototype is essentially this system deployed on a single camera and raspberry pi setup, in order to prove the viability of the detections and live service. The first part of the prototype software is the training algorithm, which is used to create and pretrain the detection model before anything else is set up. This pretrained model allows consistent results between trials, and fast and cheap startups, so that the system can be deployed immediately. This script is self-contained from the other software, so I chose to initially run it on my laptop, but it can be done on any device with a quality GPU. The next part of the software is the raspberry pi scripts, which exist to capture images, and then upload them to the google cloud instance for processing. The processing is done offboard in order to assure more usable frame rates, as the CPU power of the raspberry pi is fairly limited, and to centralize the processing, so that it can be done more effectively if the system is rolled out to more than one device. On the google cloud compute engine instance, these images are processed by the pretrained model which was quickly loaded in when the scripts were started, and then the detection algorithm writes these detections to the screen through a flask app, which is what can be seen on the dashboard here, letting you know how many people have been detected in the camera’s view, and where the system thinks they are (so that potential dangers in that room can be identified, and the system can be validated by humans). The detection calculation script then repeatedly watches for new computations to perform based on the images it is receiving from the raspberry pi, and executes those as needed, letting it operate in real time.
And while this sample dashboard view just has one person in it, the model has been trained and executed on a huge variety of images to ensure that it can always identify people well, even if they are in a wide variety of poses, partial images, or any other varying conditions.

Log in or sign up for Devpost to join the conversation.