-
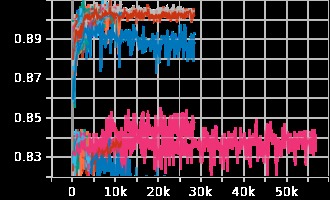
Accuracy Per Iteration Graph
-
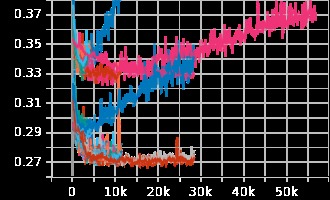
Loss per Iteration Graph
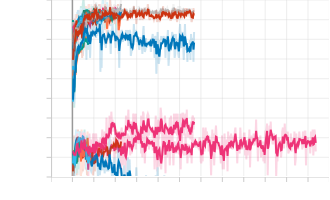
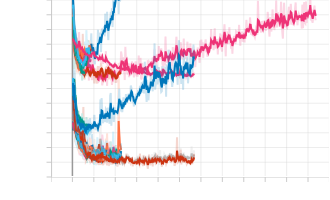
The Journey through TD Hospital Exploration
Everyone in the group is pretty new to machine learning as a whole. For us, this is the first time making any kind of model that could actually have real-world applications.
The sample code was very useful. ChatGPT was a very useful tool to learn what each section of code did, and it was a big help in teaching us how to use things like TensorFlow. Over the course of the challenge, the code and strategy changed quite a bit. At first, we used linear regression to select data columns that could be useful for this application. One of us decided to experiment with the training code and, after inputting some values into the model_train.py file, they had to show everyone else how to use it. The first strategy employed by us was to randomly select values to plug into the training function. We experimented with picking random values and learning more about how the two files are supposed to interact. The only real problem was that the accuracy was quite low. After some time, we decided to ask ChatGPT for some tips on how to choose better values. One of the suggestions we got was to use SelectKBest (for Classification/Regression). There were some data issues where some values were objects. We learned that objects can't be used as inputs for a model, and they have to be floats. So, we used the pandas library to map certain values like "male" to 1 and "female" to 0. After imputing all the NaN values from the dataset, we were ready to train the bot. Once the data was converted into float values, they could be used to train the model as well.
From what we understood, SelectKBest seems to be a decent algorithm for taking a column and comparing it to another column (the death column). We made it select the top 10 values that are most correlated with the death column.
As stated previously, our first strategy was to input random combinations of values, but this doesn't scale well. At this point, one of us believed that accuracy was the only important output value. Their idea to maximize this value was to run the program for 1200 combinations of values. We set up three for loops, one that adds more values, one that adds values for the first layer, and one that does the same for a second layer. The model would train, and if the value was less than a maximum, then that model would be thrown away, and the cycle would repeat until the highest accuracy model remained. That file ended up scoring around 68, which opened our eyes to the other things we had to do to make this model give accurate predictions. After more consulting with ChatGPT, we were told that it was more important to minimize loss rather than maximize accuracy. So, as sleepy bois, we decided to run all 1200 training sessions again, but this time we would also save the model with the lowest loss. While we were waiting for the training steps to finish, one of the event staff came over to my desk to answer questions. I explained to him what we were doing, and he basically said that using TensorFlow for something this trivial is like using a chainsaw to cut a sandwich and recommended something called Logistic Regression.
One of us tried for about 5 hours to get Logistic Regression to work. The highest score they got for submitting was 22. Continuing development with linear regression would have been nice, but ChatGPT wasn't being much help, and it was pretty late into the night. So, we put that method on hold for a little bit and switched back to TensorFlow as the code already existed.
When we pulled up the old code again, one of us saw three numbers: a "learning rate," an "epoch," and a "batch size." We had no idea what these were, so we got a lot of help from the people around me. We kept randomly changing these hyperparameters and seeing how that affected accuracy and loss. One of us overheard someone mention something about plotting data, and we asked ChatGPT how to set it up. We were told it was something called TensorBoard. It was super easy to add to the program and it made our life a lot easier when it came to seeing how different hyperparameters would affect the output accuracy. After a quick tutorial from @Akil | Challenges Organizer, we could understand the graphs, and we got a score in the high 80s, putting us in third place. Being able to see the model visually was a game-changer. It was nice to finally see the loss and the accuracy and to know when the model is overtraining and accuracy is being lost.
Over the past day, we have gone from total newbies to people who could probably understand some basic concepts if they were used in a conversation. As a reminder, our approach started with random data, and over time it just got more and more refined to where we feel confident that we could filter data and prepare it to be fed into a neural network.
Built With
- python
- tensorflow


Log in or sign up for Devpost to join the conversation.