-
-
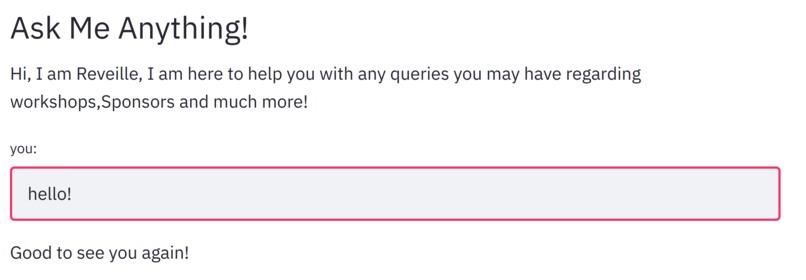
Fig.5
-
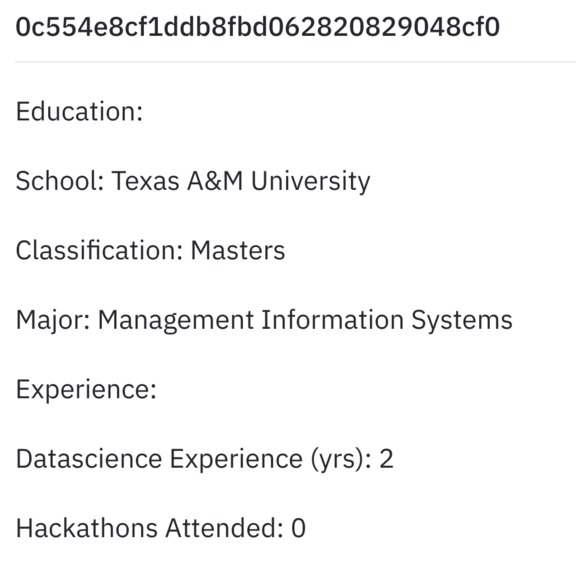
Fig.1
-

Fig.3
-
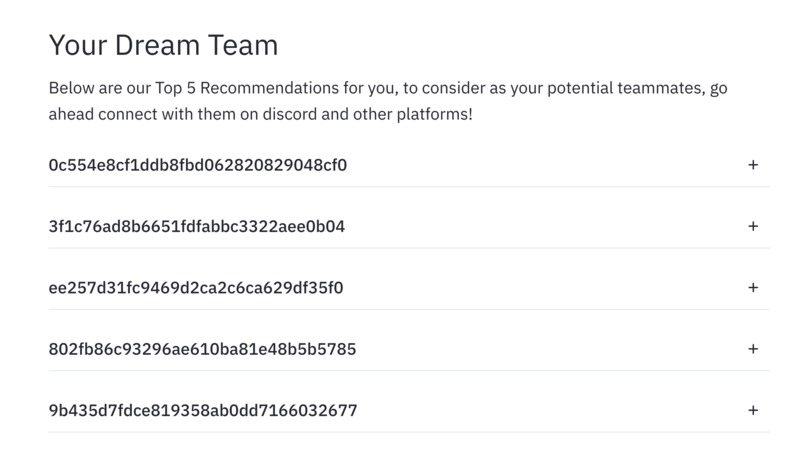
Fig.2
-

Fig.4
-
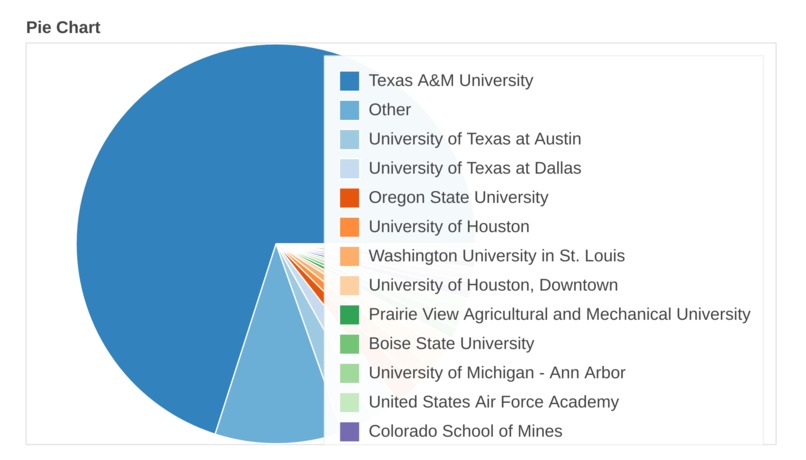
Fig.6
-
Reveille responses
-
Reveille responses

TAMU DATATHON Challenge Chosen: TD for you page Team Name: Gryffindor Members: Aashrith sai, Naga Prasanth, Vishal Indivar.
GOAL: Create a for you page that is customized for each attendee using tamu datathon application. We have created an individual specific For-you page which is completely dynamic and constantly keeps updating as there are more entries into the database. We have created this application keeping these key features in mind.
Key features: Team members recommendation Workshops recommendation chatbot that answers all the queries Real time graph visualizations
Implementation specifics:
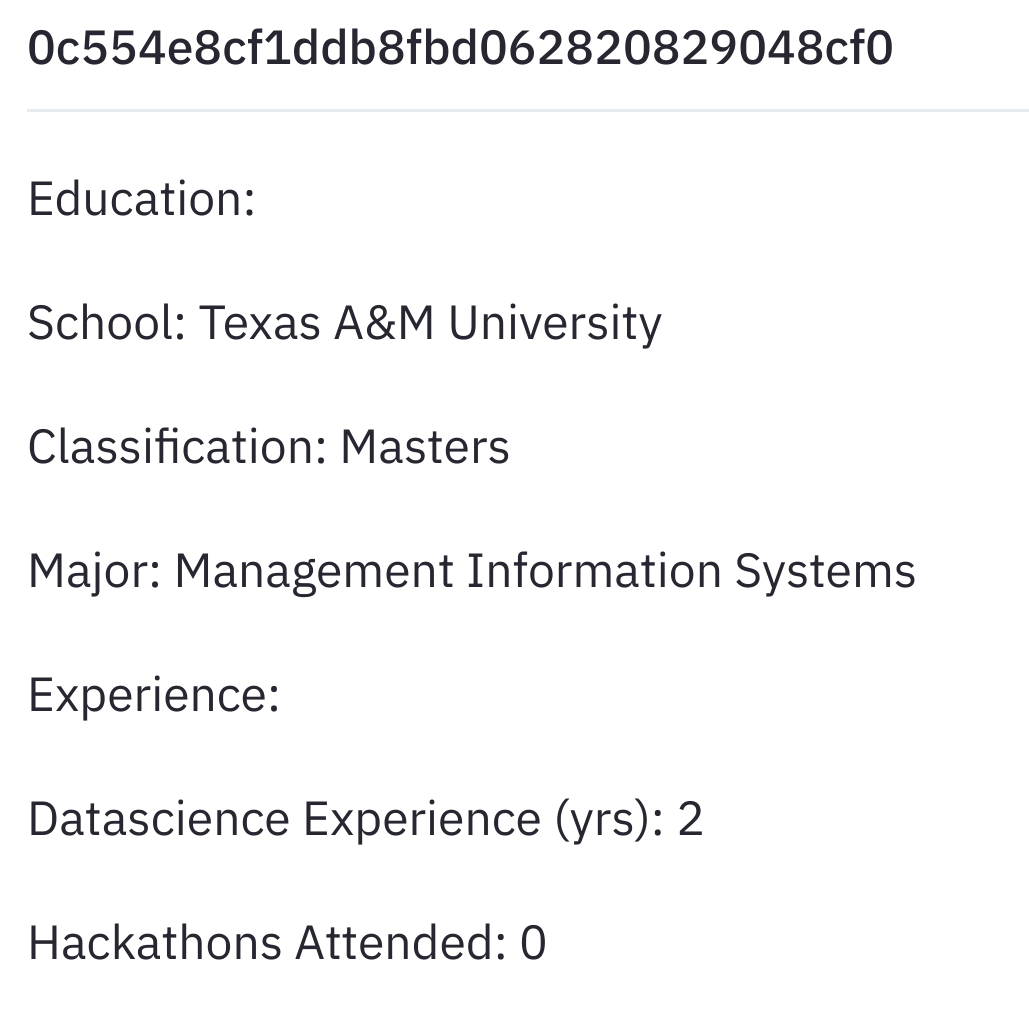
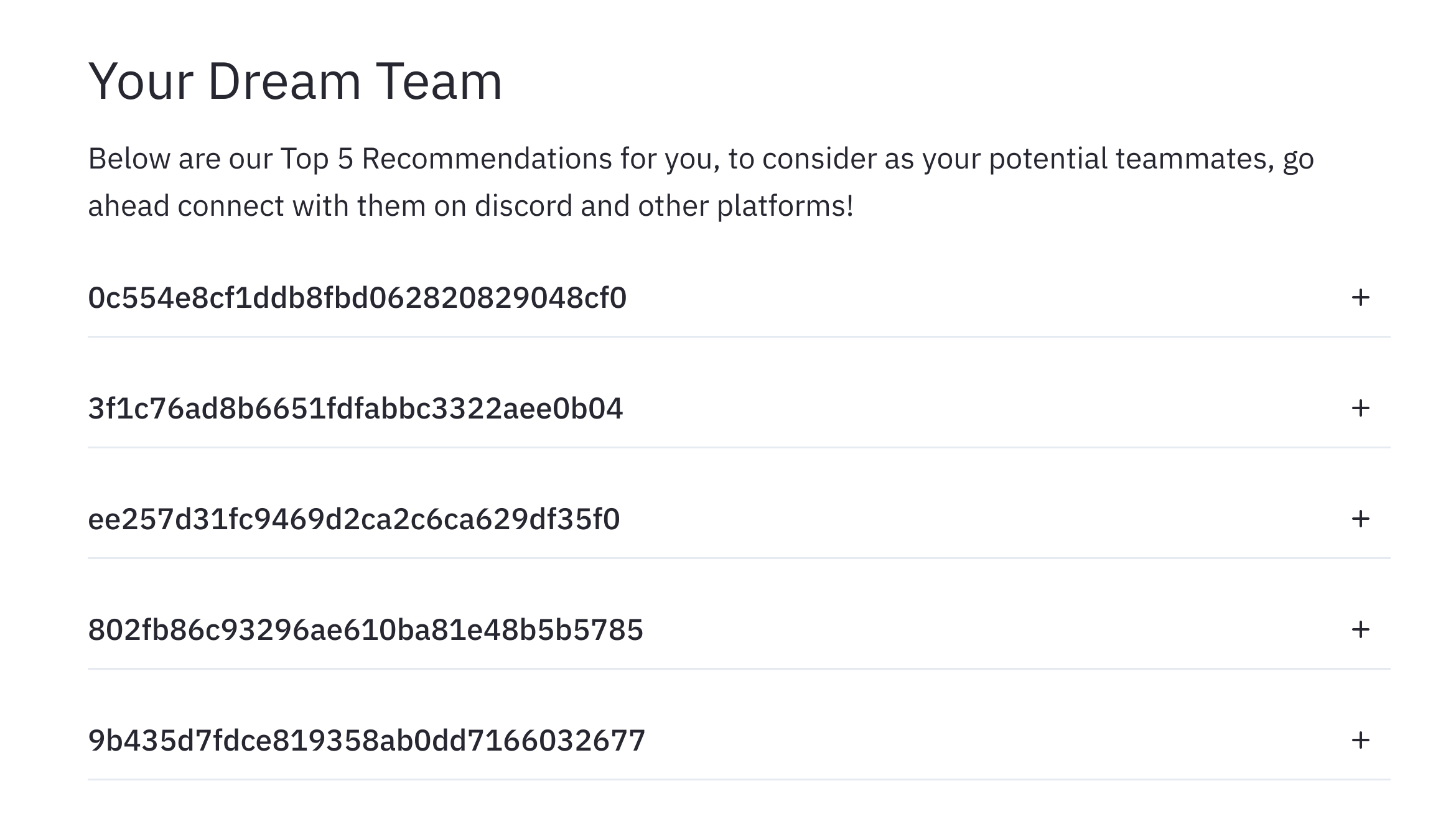
Team members recommendation: An ideal team has team members from similar backgrounds who have varied skills required to complete a project. So for our website we developed a team member recommendation system by first finding the similar individuals. To find similar individuals we used school name ( individuals from same school stay at close proximity and may know each other), degree pursuing, majors (People from similar backgrounds would like to work on similar problems), data science experience,number of hackathons attended (as projects are classified easy, medium, hard people with similar experience choose same projects) as features. We first encoded these categorical attributes using one-hot encoding and then clustered these individuals based on the above mentioned features to find highly similar individuals using cosine similarity. We then further improved our system by matching individuals with high similarity and having complementary skills as people with different skills are required to complete a good project. We tried to recommend people to maximise the skill-set of the team as a whole.
Fig-1: Details of the Individual suggested.
For creating the Team member recommendation system we used sklearn to do one-hot encoding, finding cosine similarity and matplotlib to visualize the data and find correlations. This intelligent team building application takes care of matching individuals who can complement each other with their skills. It is often the case where someone with good skills with machine learning needs to be complemented by a web developer. Keeping this in mind we have created this recommendation engine.
Fig-2: Recommendation of top 5 team mates to make a complete team.
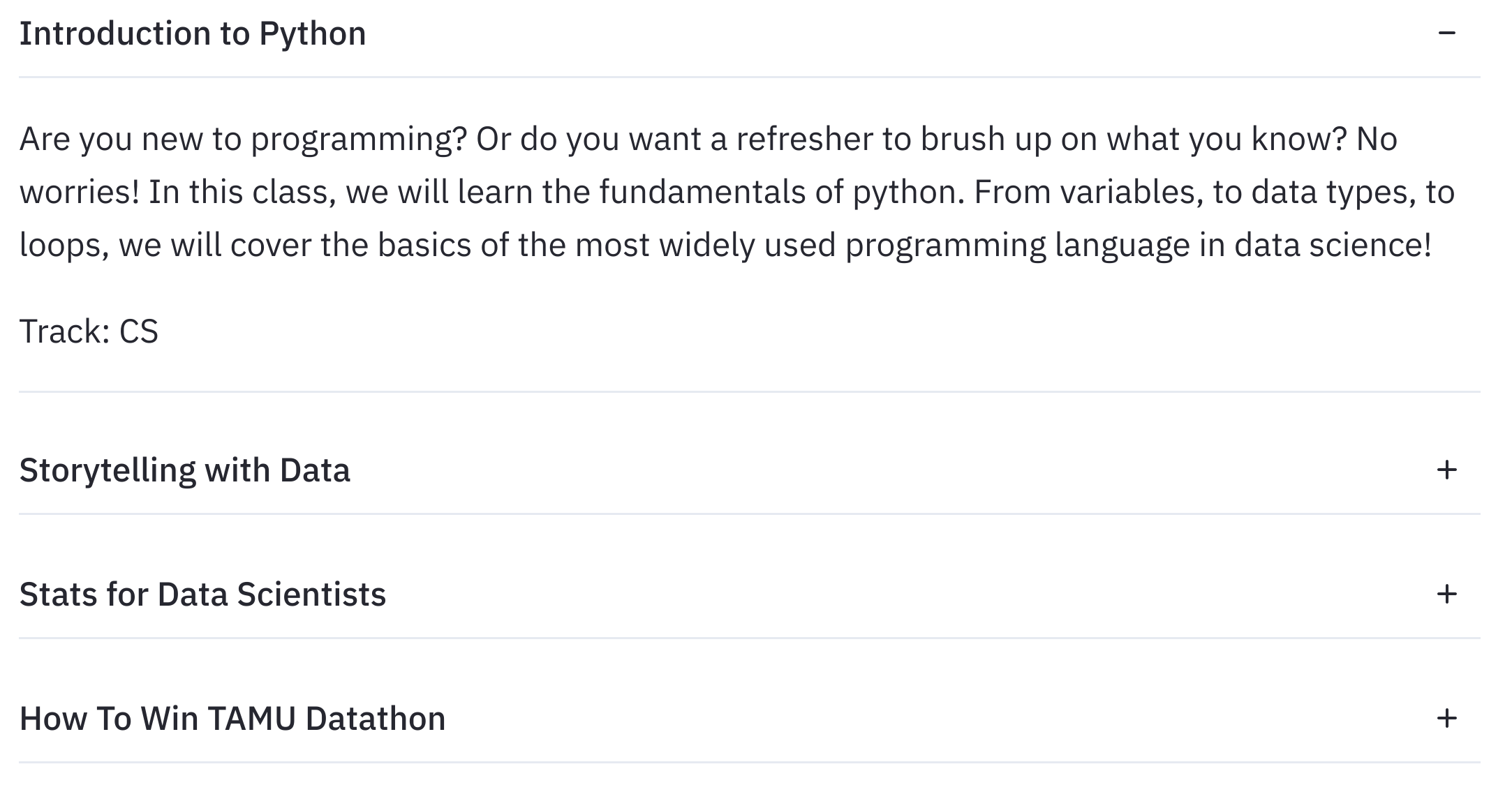
Workshops recommendation: We also created a personalised workshop recommendation system that recommends workshops based on the students' expertise and difficulty of workshops using the “workshops”,”Applicant Data” datasets given to us. For this we first clustered the individuals as beginner, intermediate and advanced by using their data science experience, the number of hackathons attended provided to us when the user signs in. We then recommended the workshops based on the difficulty of the workshop and also their interests. This recommendation system helps individuals find best workshops that are suited to their skill set and also have the opportunity to learn. We have also displayed relevant information about the workshops, skills targeted, venue and time of the workshop. This would save a lot of time.
Fig-3: Workshop recommendations based on interest and difficulty
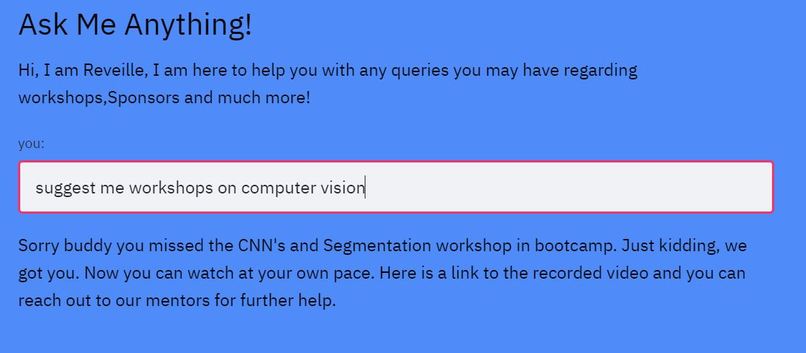
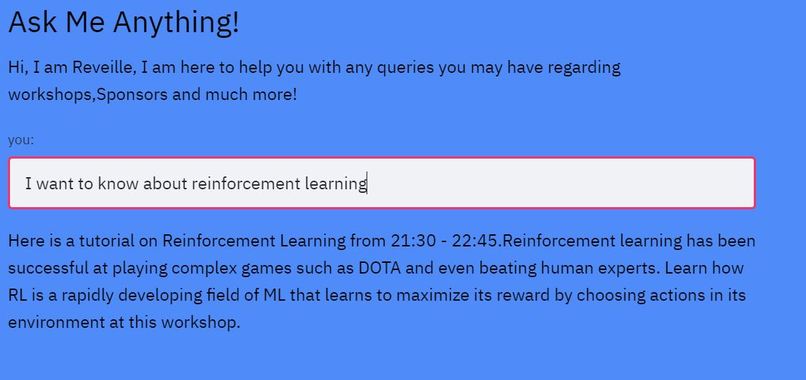
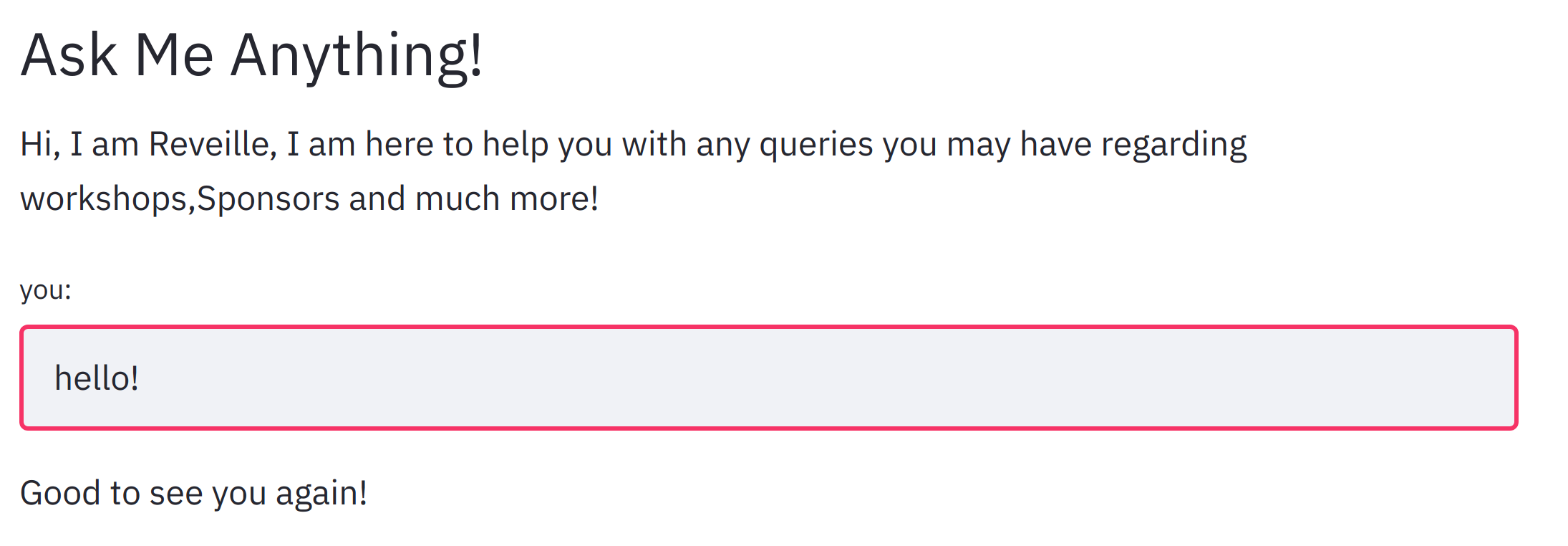
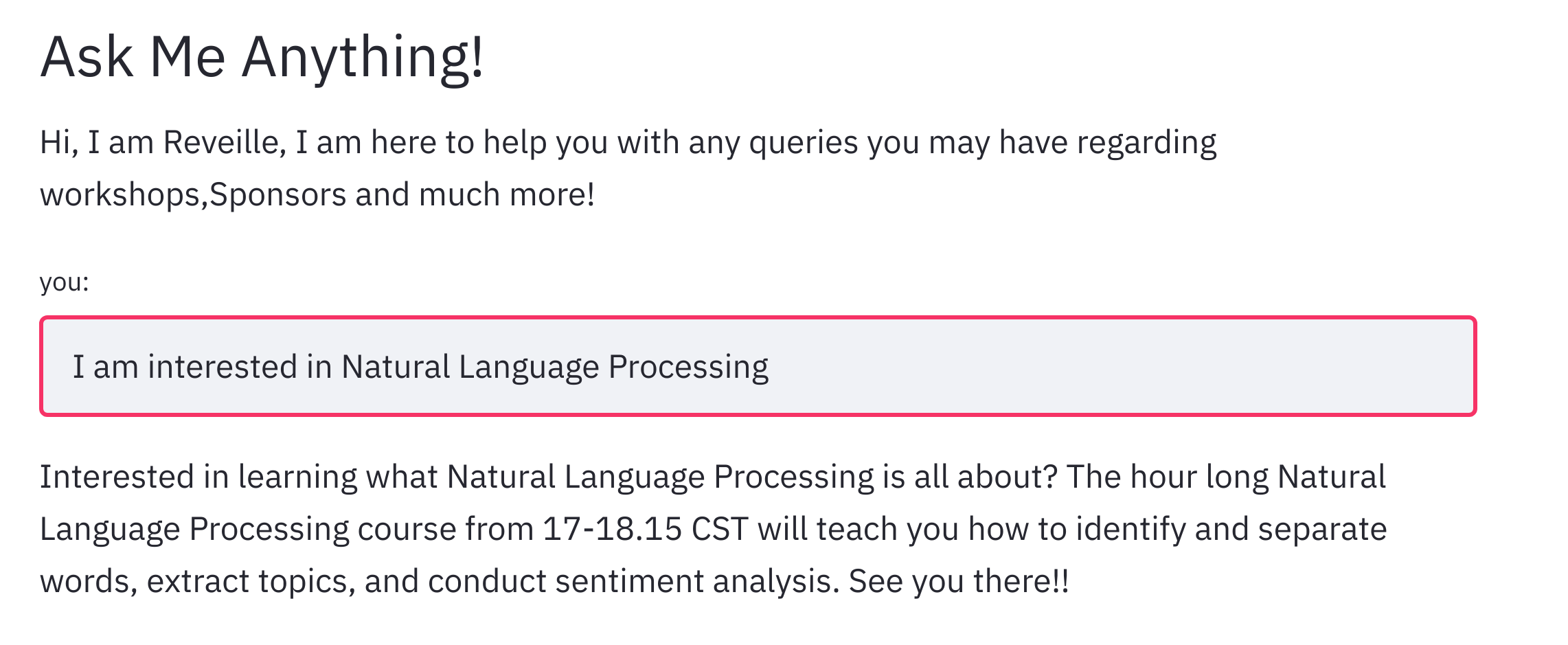
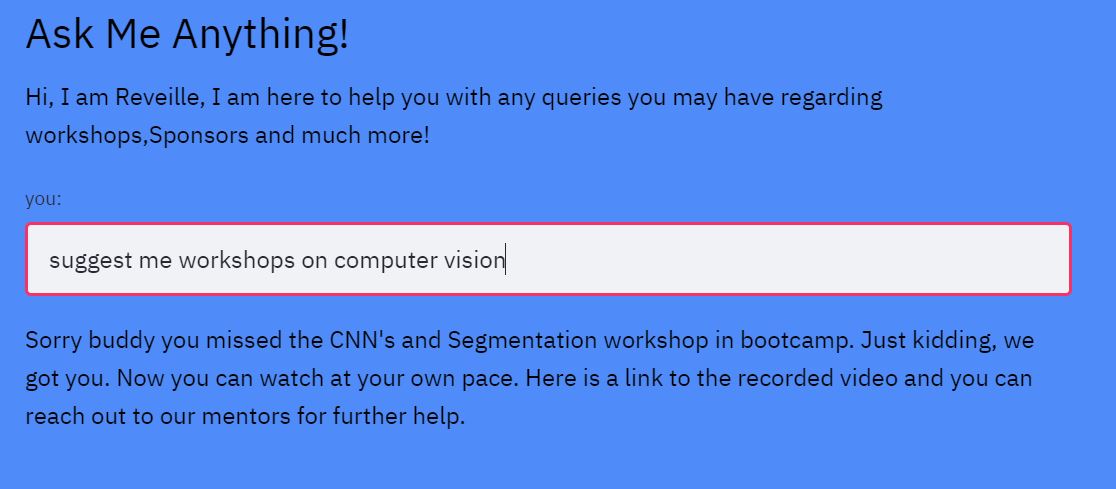
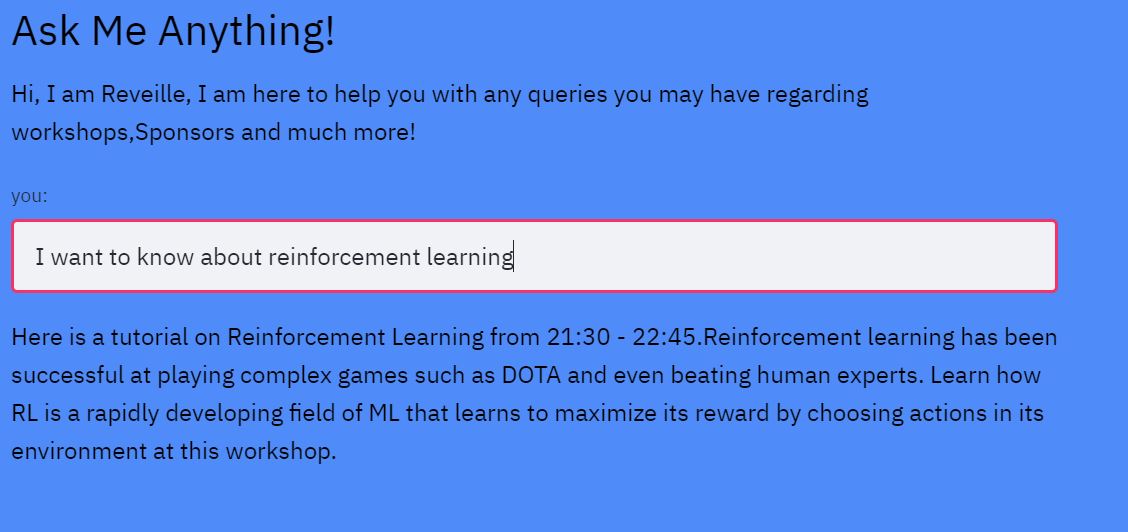
Reveille the Chatbot: We created Reveille to make the website more lively and give users an interactive experience. We implemented a chatbot that answers user queries regarding workshop suggestions, hackathon sponsors, prizes, competitions etc. For implementing the chatbot we used the workshops dataset to get the relevant information about each workshop and then the tamu datathon website to get information regarding the hackathon. The chatbot needs keywords and phrases to respond as it is rule-based, we referred and scraped websites to get relevant keywords for industries, technologies etc. For implementing the chatbot we used TensorFlow deep learning framework to create and train the neural network, NLTK library to text preprocessing(stemming, lemmatization, removing stop words, removing punctuation), and a custom bag of words function in python. We then used the bag of words approach to convert text to features and trained a feed forward neural network (FNN) that determines the class of question. Based on the output of the neural network the chatbot program determines the subset of answers from which it returns a relevant answer as output. For testing the chatbot experience we used the queries dataset to determine if the workshop details for the questions present were answered perfectly without any error. We then also tested and trained it with several queries to make it robust and relevant. Reveille makes the user experience whole and complete, it answers questions from the date and time of the workshops to suggesting challenges, talks and workshops to work on one's skills. It is a one stop shop for anyone who is participating in the datathon.
Fig-4: Reveille lets users learn about workshops of their interest and also makes meaningful conversations
Fig-5: Conversations with reveille.
Real Time Graph Visualizations: We have also added several real time graph analysis tools, where one can filter on what criteria the data should be visualized. We included categories such as students ratio from different colleges, classification, expertise and industry from which they are from. This analysis tool helps individuals to have a better understanding of their peer group and can be well prepared about their competition. We have used a machine learning model to categorize individuals into beginner, intermediate and advanced based on their inputs, every time new records are added to the database, real time visualization takes place. There is no time latency or there is no requirement of additional computations to create visualizations.
Fig-6: Visualization based on college.
Challenges Faced:
- Our team did not consist of a well versed UI/UX developer and hence we spent a lot of time figuring out streamlit tool for hosting or webpage. We successfully hosted our project and its up and running finally.
- It took us a lot of time to extract data from external data sources from kaggle and scraped few webpages as we had to train the neural network for our chatbot(Reveille).
- It took us some time to figure out how to cluster the users as there were a lot of categorical values to be considered, but through some hurdles we could efficiently develop the clustering algorithm.
Key Learnings:
- We were all persistent and were willing to get to the final product. That made us successfully achieve all our goals that we initially thought yesterday morning.
- We learnt UI development, better hyperparameter tuning of neural network.
- We tried several models for clustering that helped us build efficient models.
- We used interactive data visualization tools for the first time.


Log in or sign up for Devpost to join the conversation.