-
-
Index Page
-
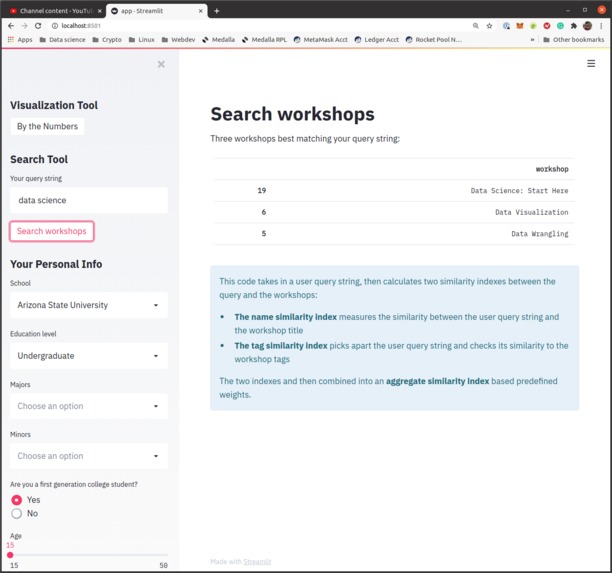
Workshop search engine
-
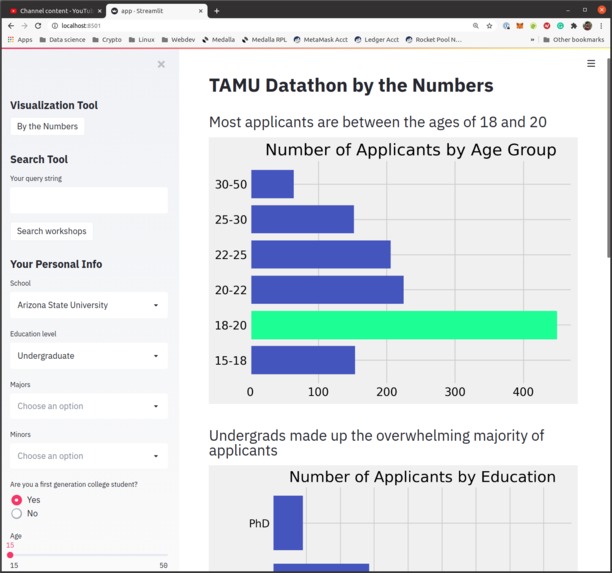
Visualization
-
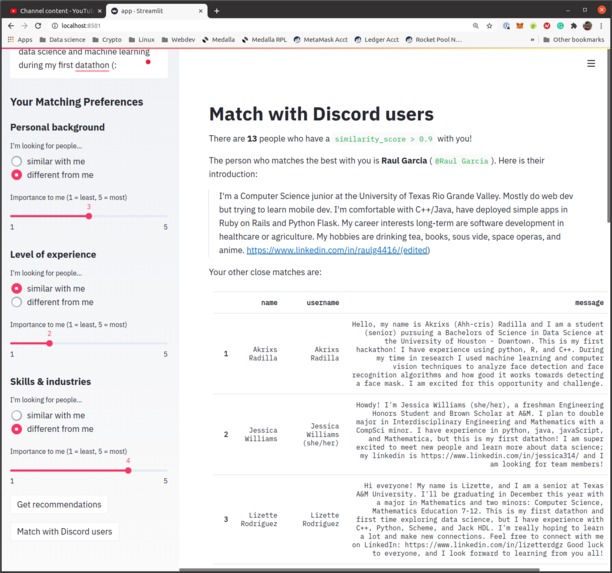
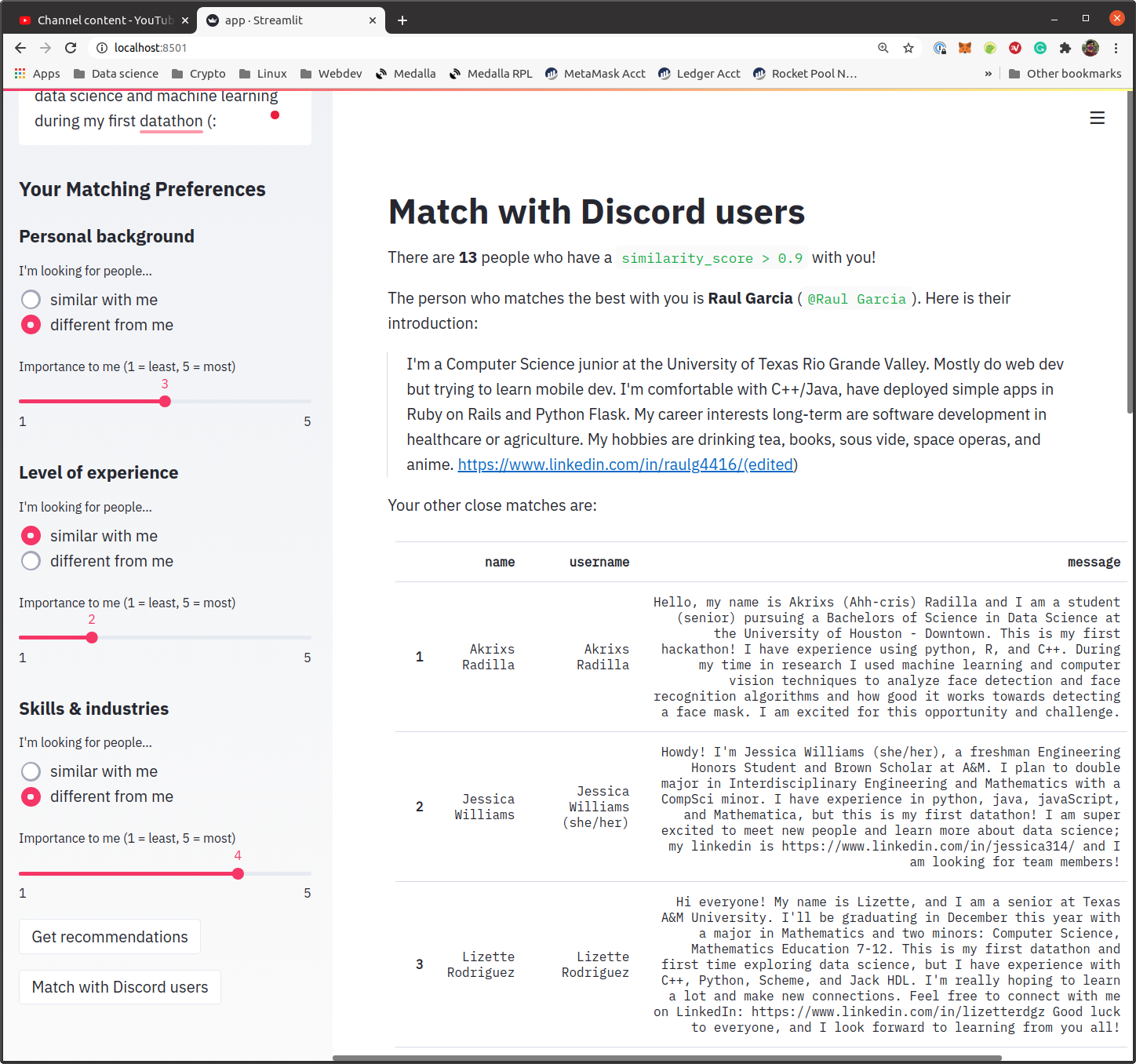
discord user match
-
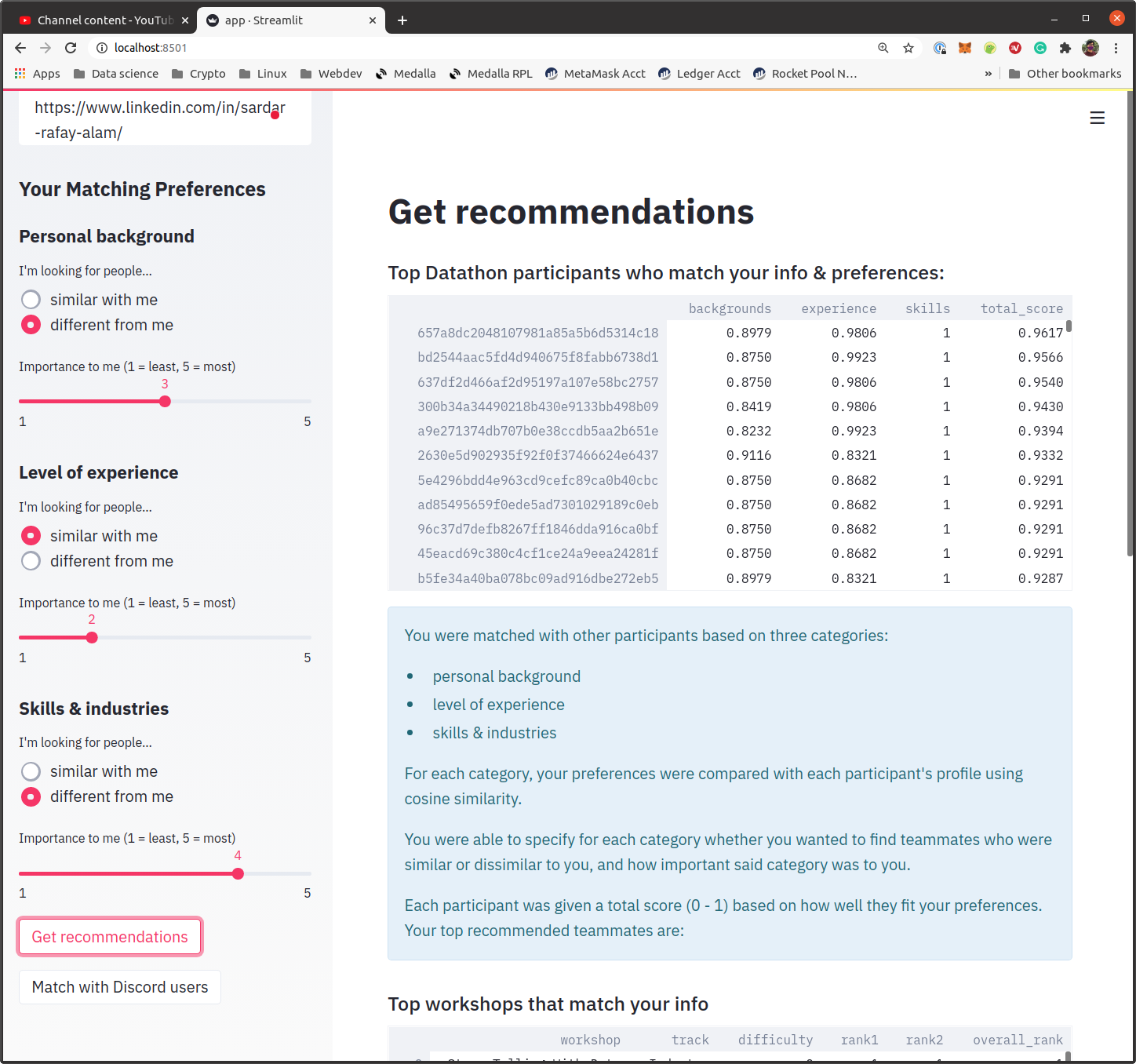
user search engine and workshop recommendation
TD For-you Page
We wanted to get to know the diverse range of participants a little better. Since we didn't have time to talk to every person, we were inspired by the task to create a personalized recommendation for every person. Through the data, we learned a bit more about each person's background, their interests, experiences, and their hopes for the future. Along the way, we also deepened our understanding of NLP and search matching. Overall challenges we faced as a team included working remotely and synthesizing different coding styles together into a cohesive project. However, we had good communication throughout the competition which allowed us to work through any road bumps.
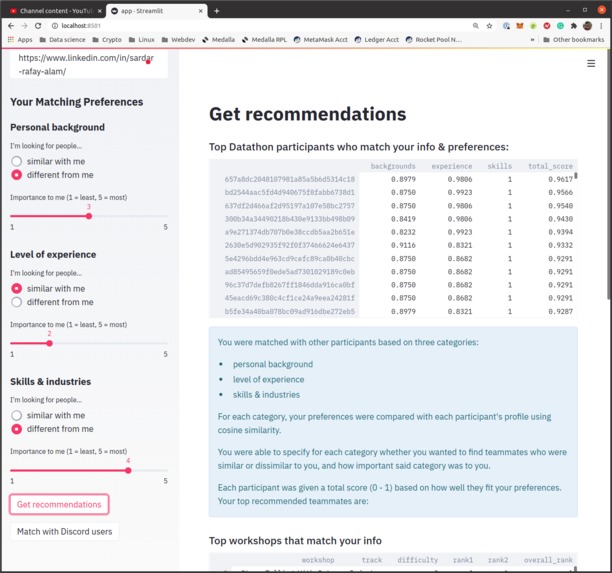
We started building the recommendation engine for participants - the heart of our project. There were many applicants from a broad variety of different schools, and creating dummy variables would become too complex. So, Arch decided to implement binary encoding instead. Cosine similarity was used instead of Euclidian distance as the latter suffers from the curse-of-dimensionality.
Building the workshop recommendation required multiple ML models, and assigning ranks to the workshops was tricky. Arch gave weight to workshop difficulty and then workshop track to get the final ranking. To predict the difficulty of workshop the user would attend, he used multiple random forest models to handle ordinal classes. He also did a sanity check of the workshop recommendation engine which resulted in 63% of accuracy.
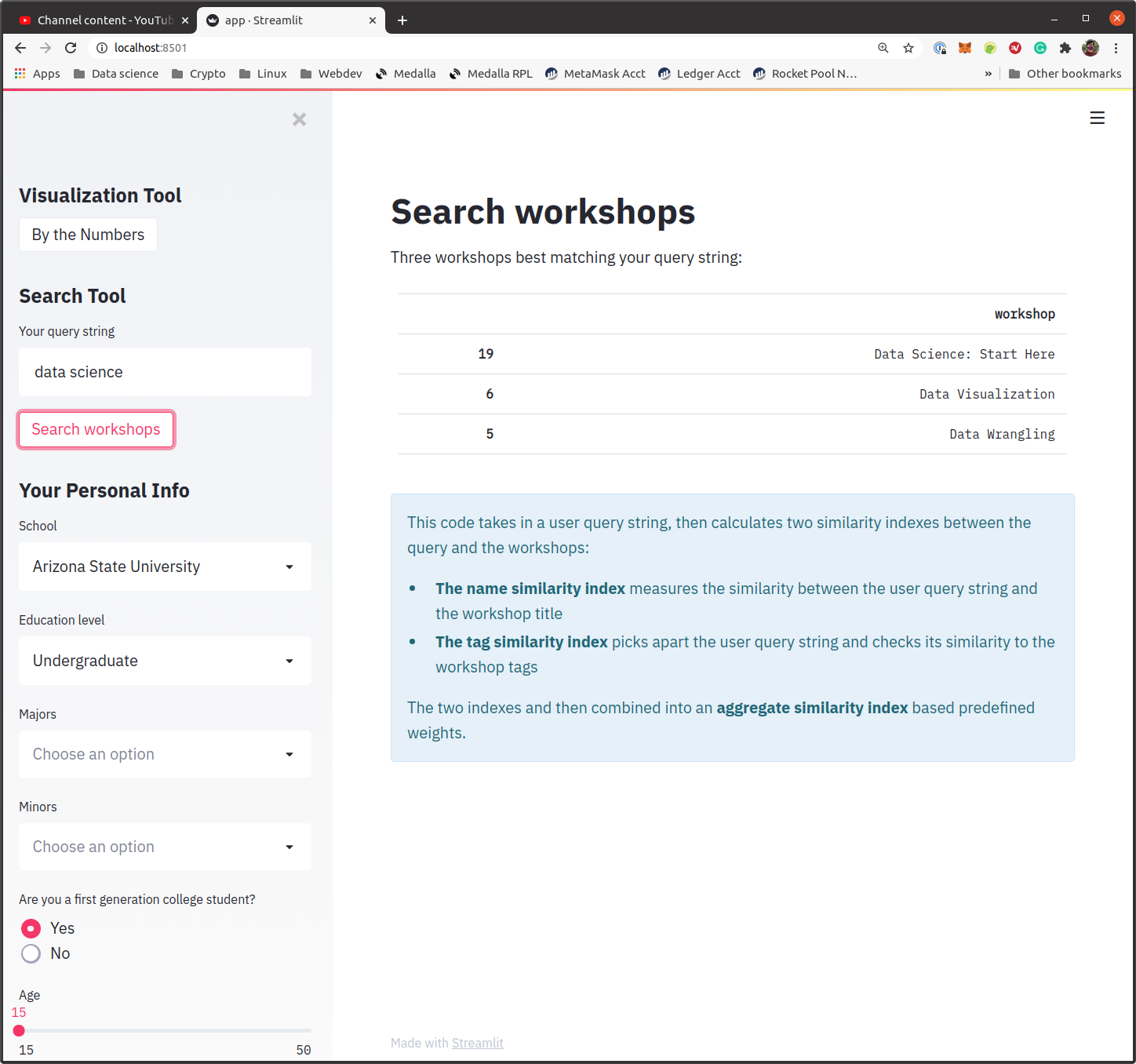
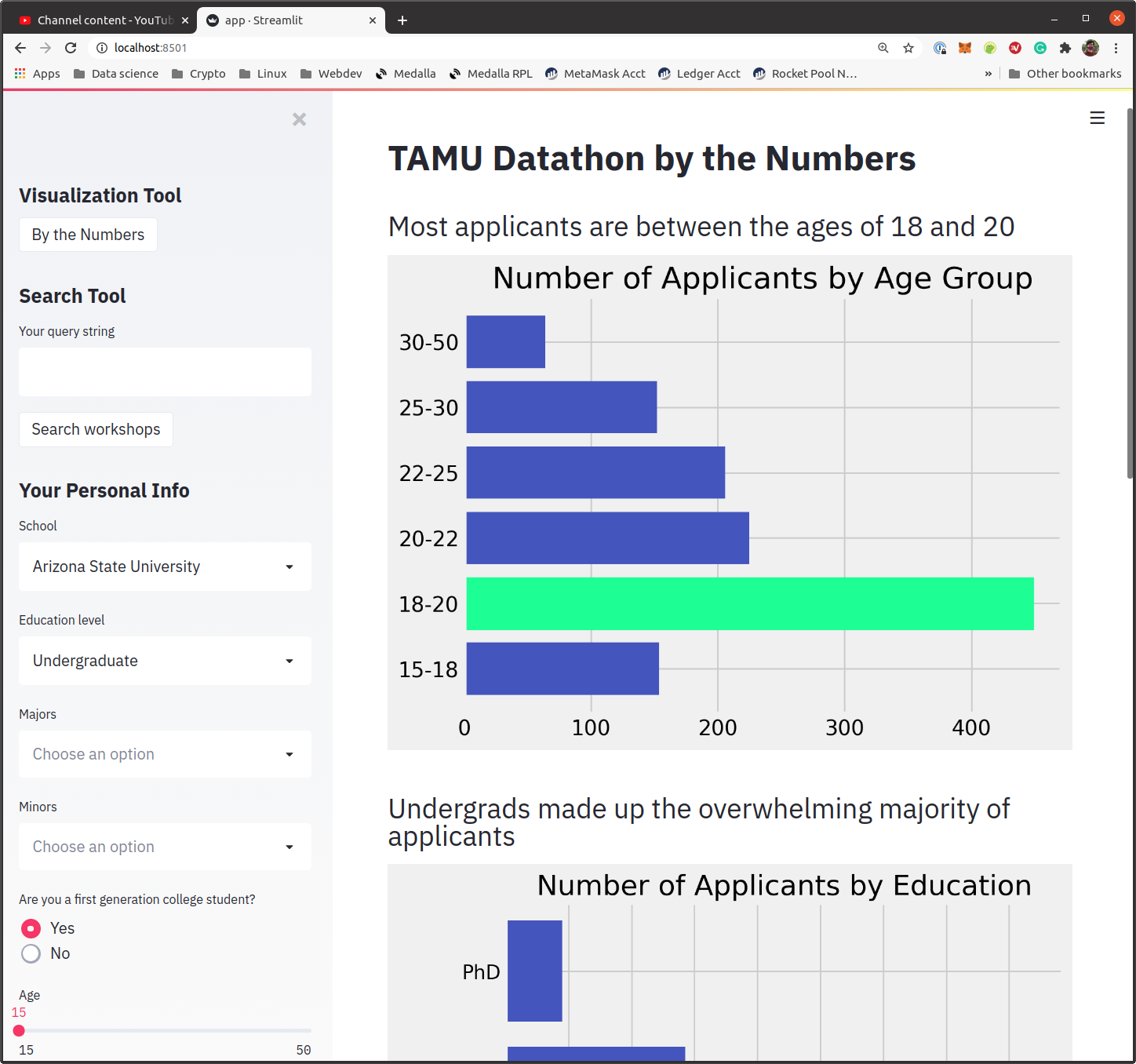
Dillon built the workshop search engine and data visualizations. The data visualizations were made with matplotlib. He used pandas to subset relevant data and calculate sums and pyplot to plot horizontal bar charts. As an extra treat, he changed the bar colors to the colors from the TD website. He was inspired by the sheer number of applicants and the diversity of their backgrounds. He felt that a lot of interesting things could be done with that kind of data. He learned a lot about NLP with Python and got a small taste of Streamlit. One of the challenges he faced was taking the knowledge he had from R and finding ways to translate it into Python. Another challenge was deciding when to stop fine-tuning. At around 1 AM, he suddenly came up with an idea on how I could use ML to drastically improve my search engine. Even though a mentor liked the idea, he realized it was unfeasible to complete it on time without completely sacrificing the data visualizations.
Michelle built the discord user matching feature to provide a more personalized website experience. As a an MIS major interested in a more CS-related career, she understood that while user stats were important, there was very little additional data on applicants, which created a one-dimensional feel to the website. As a result, she scraped the discord introductions channel for more user-generated content and used a word-vectorized approach to match user inputted text with discord users.
Larry built the front-end for the app and synethesized our work together into a Streamlit app. He learnt how to use streamlit, a great tool for fast prototyping data science products. Challenges he faced included learning to use the new tool and synthesizing all of our code to provide a smooth and integrated user experience.
How to use
Install dependencies:
conda env create -n streamlit -f environment.yml
Run Streamlit:
conda activate streamlit
cd td_frontend
streamlit run app.py
Project Organization
.
├── for you : Contains the python notebooks, scripts and pickle files
│ ├── matplotlib_visualizations.ipynb : Python Notebook to visualize users profiles
│ ├── search_engine.py : Script to search workshops using queries
│ ├── Clean data.ipynb : Python Notebook to clean applicants data
│ ├── Similar users.ipynb : Python Notebook to find similar or different users based on filters
│ ├── workshop recommendation.ipynb : Python Notebook to get recommendation of workshops
│ └── discord_rec
│ └── discord_sim.ipynb : Python Notebook to match with discord users
├── screenshots : Contains the Streamlit APP figures
├── td_frontend : Customer Segmentation based on product aisles
│ ├── app.py : Streamlit App
│ ├── environment.yaml : Environment requirements file
│ ├── discord_sim.py : Script to match with discord users
│ ├── search_engine.py : Script to search workshops using queries
│ ├── similar_users.py : Script to find similar or different users based on filters
│ ├── visualizations.py : Script to visualize users profiles
│ └── workshop_recommend.py : Script to get recommendation of workshops
├── gitignore : gitignore file
└── README.md : Project Report
Built With
- cosine-similarity
- jupyter-notebook
- machine-learning
- matplotlib
- natural-language-processing
- nltk
- python
- random-forest
- recommendation
- spacy
- streamlit




 Lyu")


Log in or sign up for Devpost to join the conversation.