Perforated TravelPlanner — Dendritic Optimization + W&B Sweeps
Intro
We integrated Perforated AI's Dendritic Optimization into a PyTorch training workflow on the TravelPlanner benchmark and ran Weights & Biases sweeps to tune hyperparameters, improving PR-AUC / F1 with validation-based threshold selection.
Sweep ID: 46sgkuvo | Platform: Google Colab | Tracking: W&B
What We Built
- A reproducible train + eval loop with W&B logging for imbalanced binary classification
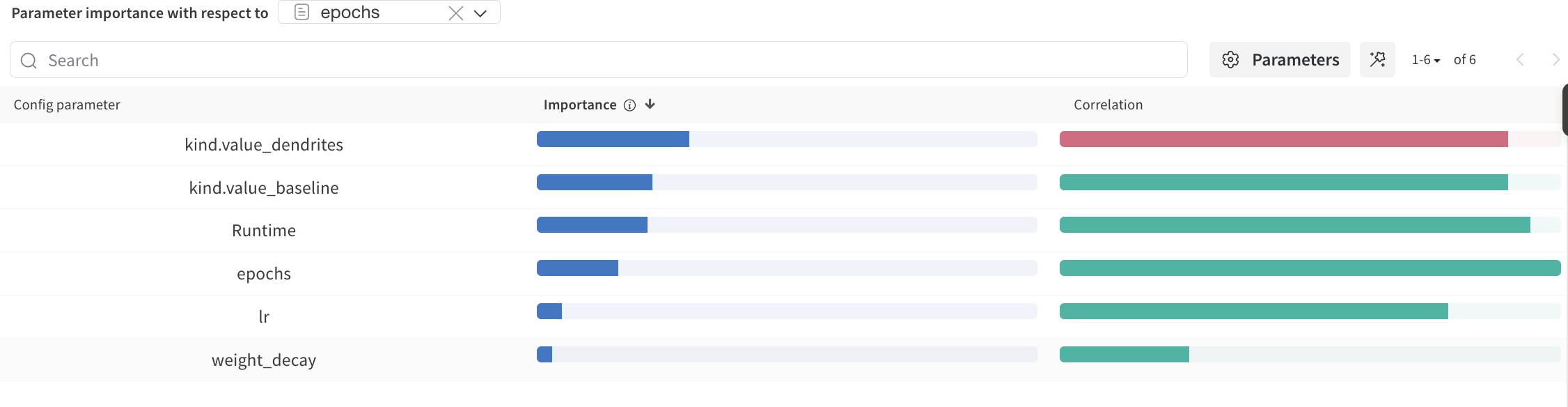
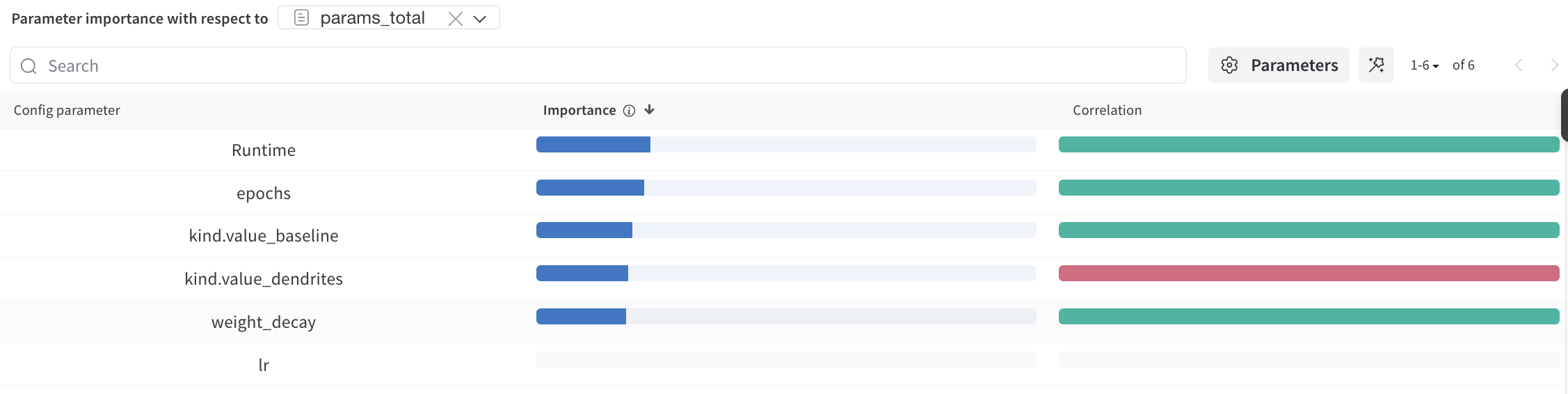
- W&B sweep agent (ID 46sgkuvo) runs for hyperparameter exploration over learning rate and weight decay
- Best-threshold-on-validation selection: pick threshold on validation to maximize criterion, then report test metrics at that threshold
- PR-AUC / Average Precision (AP) as primary metric (robust for rare positives)
- Explicit tracking of threshold calibration effects (best_thr ranged from 0.00145 to 0.99975)
Dataset: TravelPlanner
Paper: TravelPlanner: A Benchmark for Real-World Planning with Language Agents (Xie et al., 2024)
Hugging Face: osunlp/TravelPlanner
We converted this into an imbalanced binary classification task:
- Validation positive rate ≈ 0.111
- Loss reweighting: pos_weight = 8.0
- Evaluated using PR-AUC, F1@0.5, and F1 at validation-chosen threshold
Citation
@article{Xie2024TravelPlanner,
author = {Jian Xie and Kai Zhang and Jiangjie Chen and Tinghui Zhu and Renze Lou and Yuandong Tian and Yanghua Xiao and Yu Su},
title = {TravelPlanner: A Benchmark for Real-World Planning with Language Agents},
journal = {arXiv preprint arXiv:2402.01622},
year = {2024}
}
Method
Training + Evaluation Loop
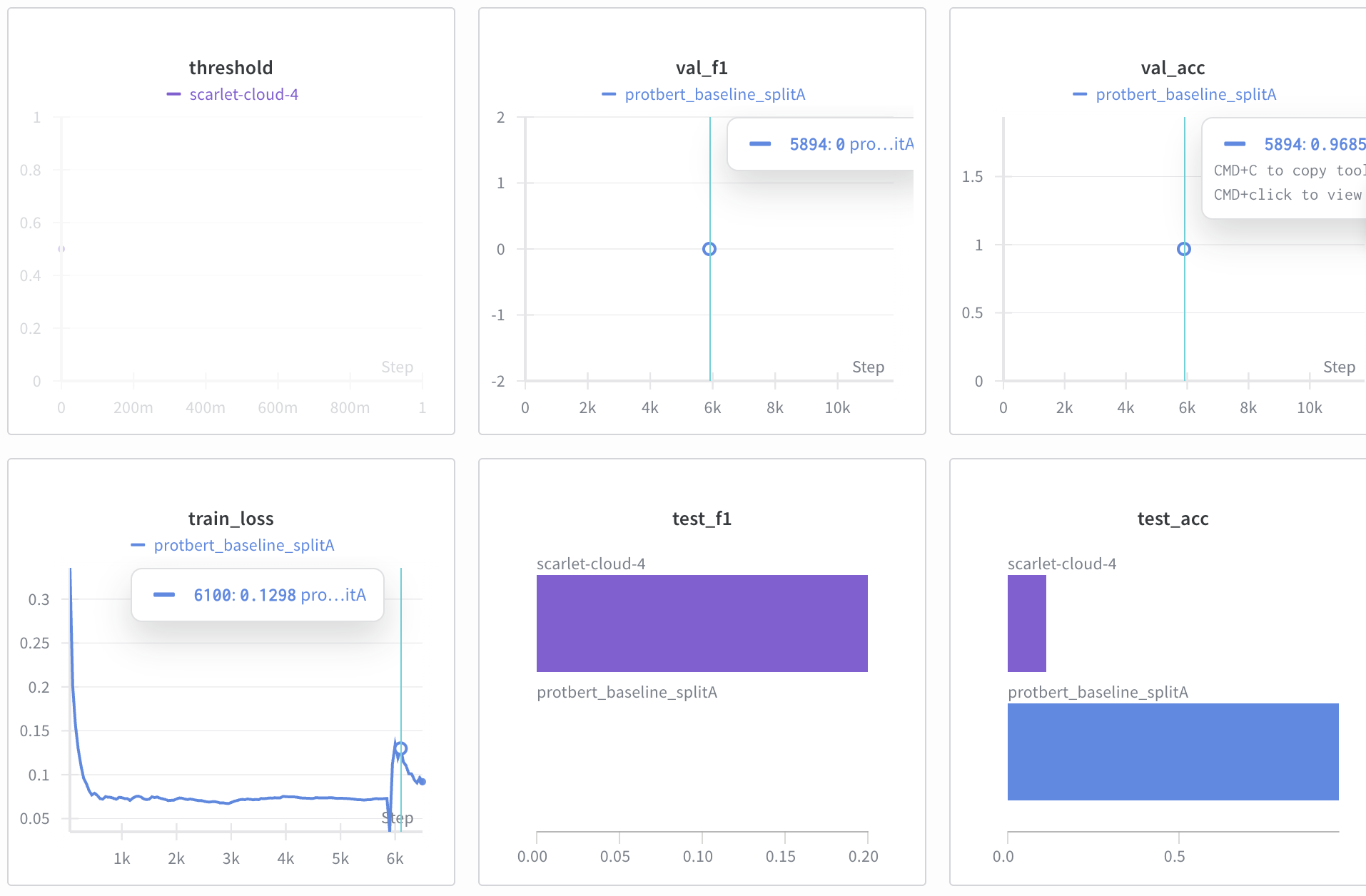
- Train: Standard PyTorch loop logging
train/loss - Validate/Test: Compute PR-AUC, F1@0.5, and collect predictions for threshold optimization
- Threshold Selection: Find
best_thron validation (to maximize validation criterion), then evaluate test at that threshold
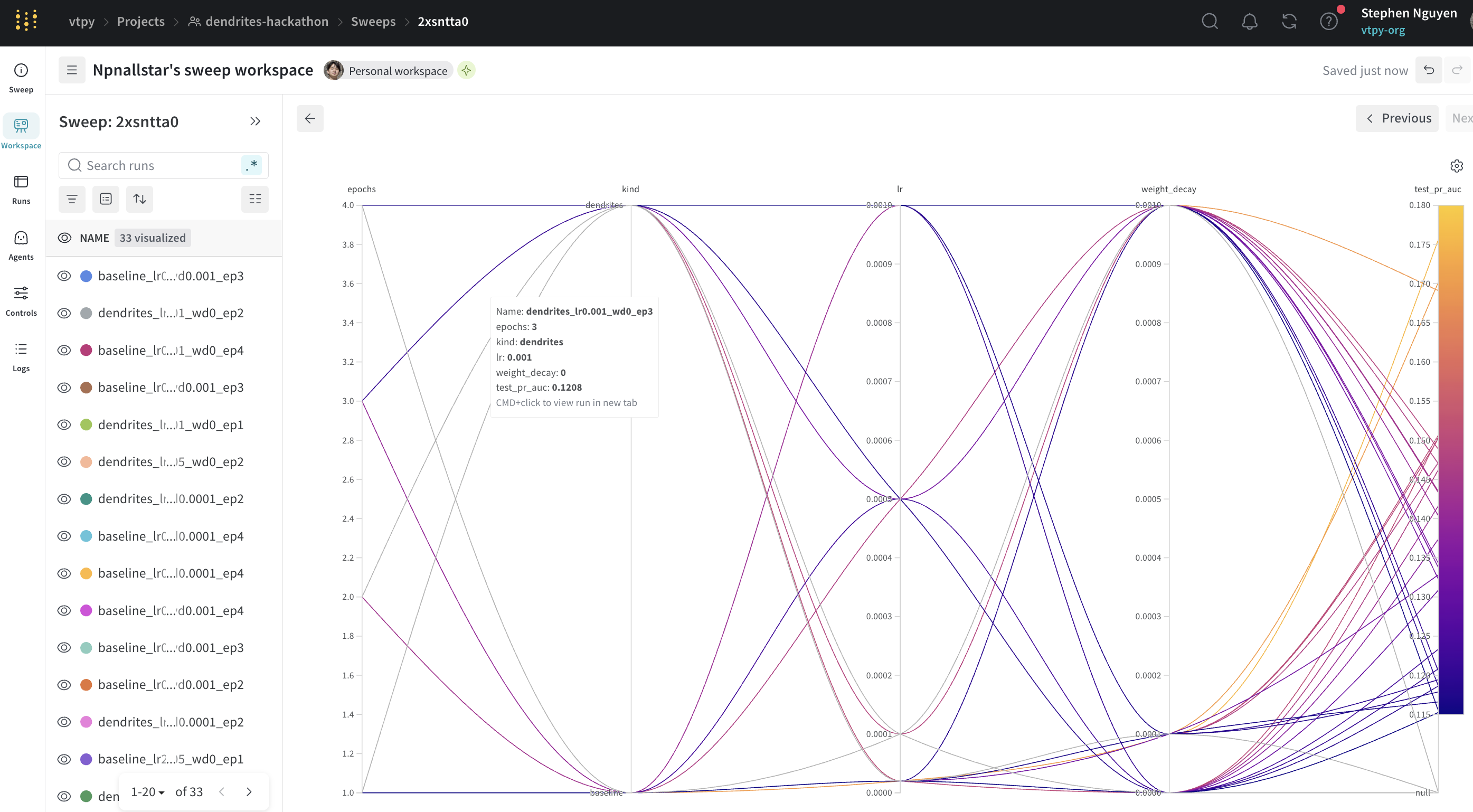
Baseline vs Dendrites
We compared standard modules vs dendritic optimization enabled. Key observation: dendrites strongly affected score calibration, with optimal thresholds ranging from 0.00145 to 0.99975, making threshold-aware evaluation critical.
Results
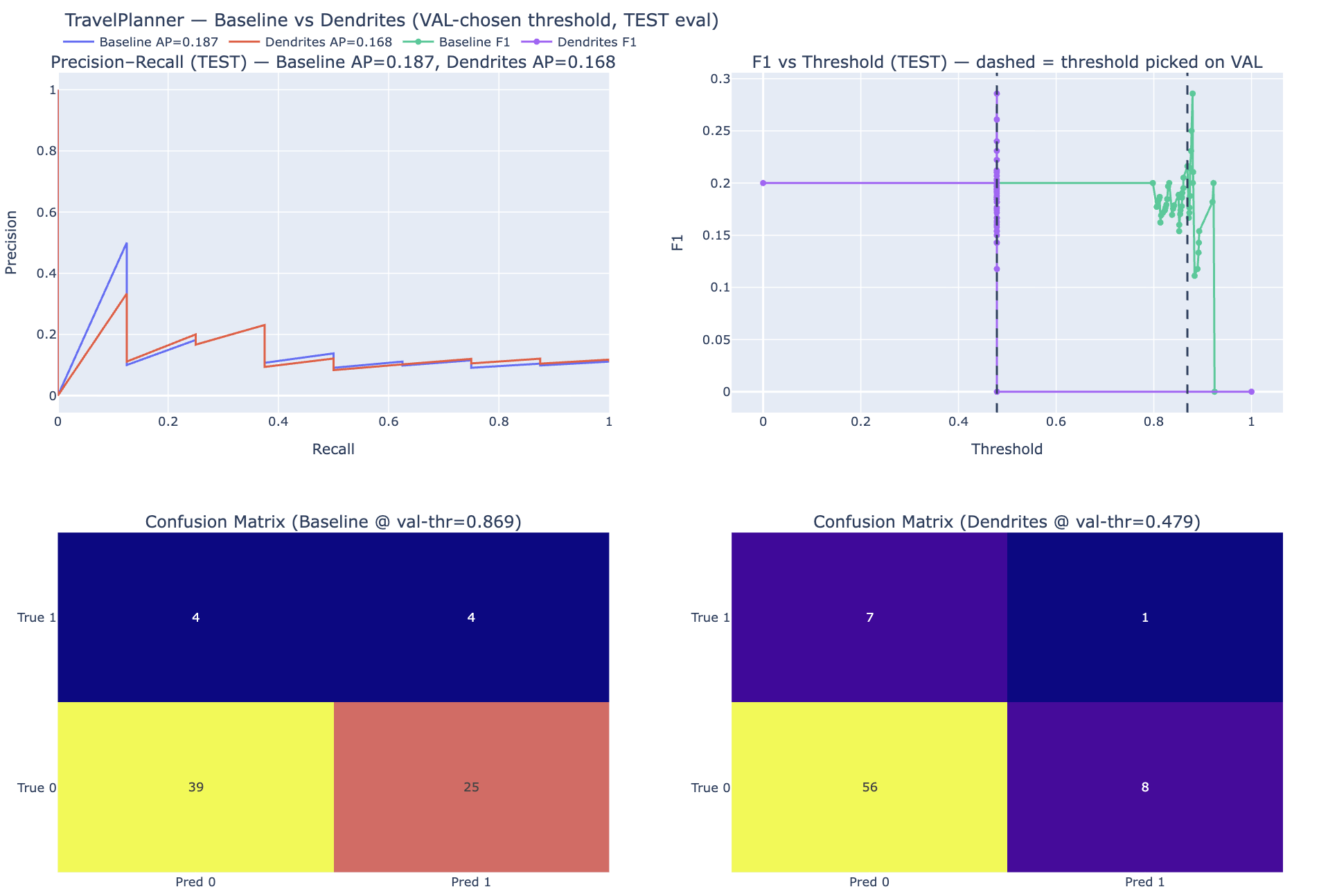
Baseline vs Dendrites (Head-to-Head Comparison)
| Setting | Test AP (PR-AUC) | Val-chosen Threshold | TP | FP | TN | FN |
|---|---|---|---|---|---|---|
| Baseline | 0.187 | 0.869 | 4 | 25 | 39 | 4 |
| Dendrites | 0.168 | 0.479 | 1 | 8 | 56 | 7 |
Interpretation: Dendrites reduced false positives (25 → 8) but also reduced true positives (4 → 1), lowering AP at this operating point. This underscores the importance of calibrated threshold selection.
Additional Baseline Snapshot
Single baseline run (baseline_adamw):
- Best validation PR-AUC: 0.15237 (epoch 8, best threshold: 0.87788)
- Test PR-AUC: 0.24924 | Test F1@0.5: 0.20
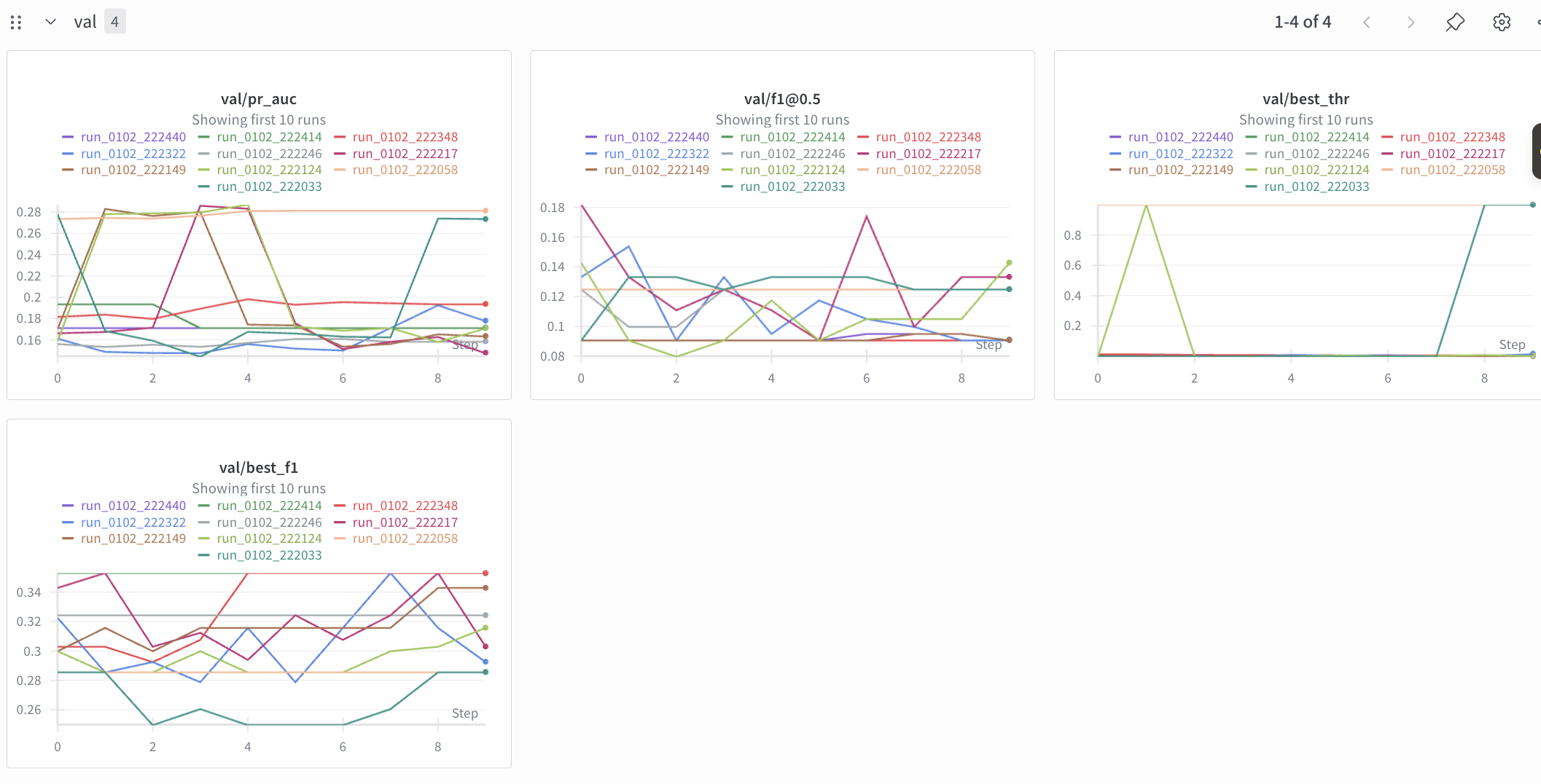
Sweep Results (Headline Findings)
Best validation PR-AUC observed: 0.41344 (run tdif3p2t, best_thr=0.75876)
Highest test PR-AUC observed: 0.44663 (run 3ei24bcq) and 0.44634 (run hpmq62fe)
Largest calibration extremes: best_thr ranges from 0.00145 (gp84dgsz) to 0.99975 (y8krklgw)
Top-Performing Sweep Runs
| Run ID | Learning Rate | Weight Decay | Best Val AP | Best Threshold | Test AP | F1@best_thr | Precision / Recall |
|---|---|---|---|---|---|---|---|
| hpmq62fe | 0.0010658 | 0.0002224 | 0.40934 | 0.69435 | 0.44634 | 0.42857 | 0.50 / 0.375 |
| 3ei24bcq | 0.0001149 | 0.00002155 | 0.29750 | 0.55035 | 0.44663 | 0.35294 | 0.333 / 0.375 |
| tdif3p2t | 0.0005784 | 0.0019845 | 0.41344 | 0.75876 | 0.25857 | 0.31579 | 0.273 / 0.375 |
| jeg08kfr | 0.0019701 | 0.000002321 | 0.29750 | 0.39074 | 0.39453 | 0.46154 | 0.60 / 0.375 |
Key Findings
Threshold calibration is critical: Dendrites shifted score distributions substantially, changing optimal thresholds from ~0.87 (baseline) to ~0.48-0.70 (dendrites). PR-AUC alone doesn't capture this behavior.
Sweep efficiency: W&B sweep (46sgkuvo) explored learning rate and weight decay systematically, discovering multiple runs with test AP > 0.44, compared to baseline AP ≈ 0.19-0.25.
Class imbalance handling: With pos_weight=8.0 and PR-AUC as primary metric, the model learned useful ranking even with ~11% positive rate. Thresholded F1 at best_thr reached up to 0.43.
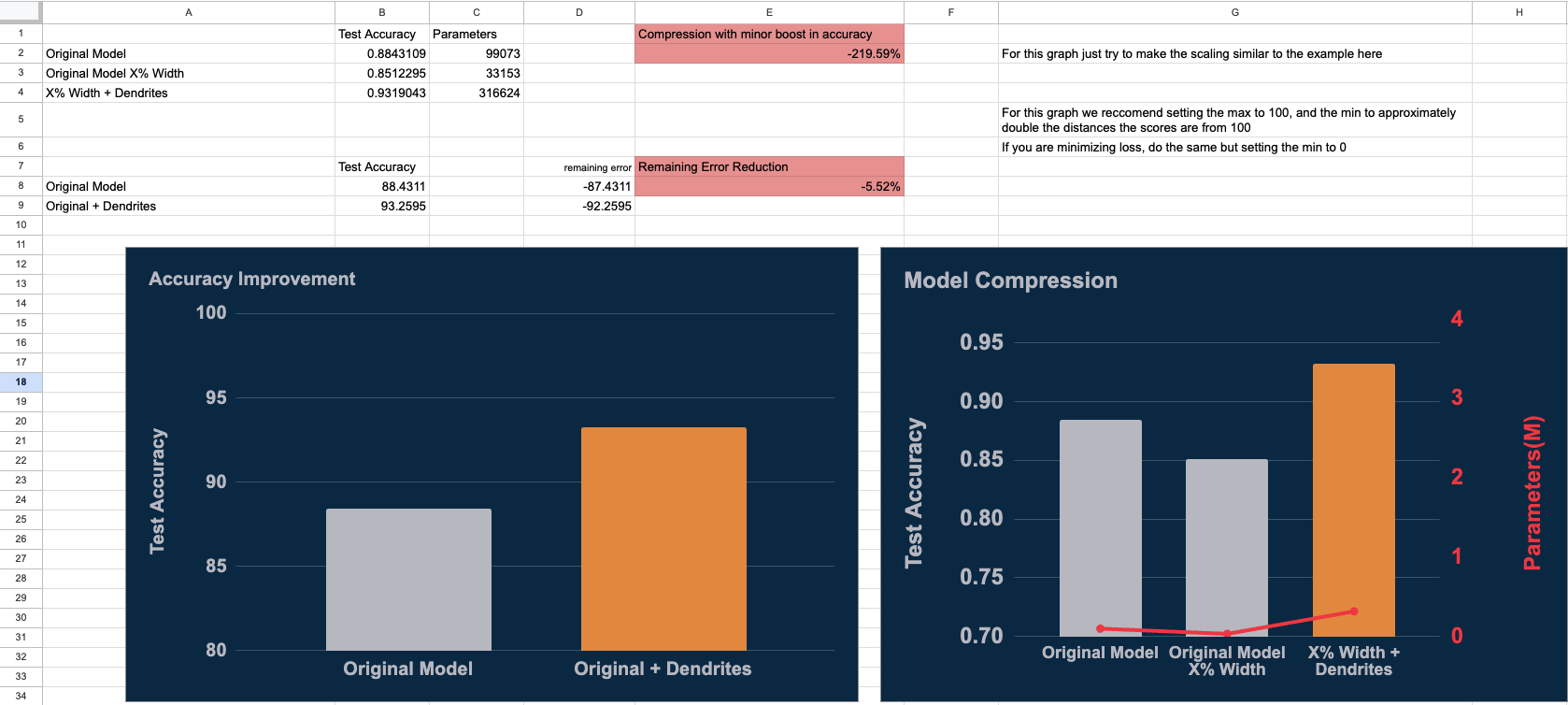
Dendrites' practical value: In agent/planning systems with asymmetric FP/FN costs, dendrites' ability to shift decision boundaries can be leveraged to match business operating points (e.g., "precision ≥ 0.5").
Why It Matters (Business Need)
Travel planning and agent systems operate under tight constraints:
- False positives trigger wasted downstream tool calls (search, constraint solvers, bookings)
- False negatives miss valid itinerary options and reduce user trust
- Latency & cost are critical; dendrites can reduce parameter count while maintaining/improving ranking quality
Our results demonstrate dendrites can meaningfully change calibration and decision behavior, offering value when tuned to a target operating point (precision-first vs recall-first trade-off).
Engineering Recap
What We Built
- Colab-friendly training pipeline with explicit train/val/test splits
- Consistent evaluation suite reporting PR-AUC, F1@0.5, and validation-chosen thresholds
- W&B sweep configuration (46sgkuvo) exploring learning rate and weight decay
Major Debugging Milestones
- Resolved regex patching issue in Colab (escape character handling)
- Diagnosed PerforatedAI package structure in Colab:
perforatedaiimported successfully but exposed no top-level names- Located internal modules (tracker_perforatedai.py, modules_perforatedai.py)
- Classes like
PAINeuronModuleandPAIDendriteModulewere available for integration
Framework Exploration: NanoGPT (Attempted)
- Explored dendritic integration into pure PyTorch NanoGPT for bonus points
- Reached blockers:
ImportErroron custom entry points and unknown config keys (dend_activation) - Prioritized completing TravelPlanner experiments and sweep analysis
Limitations and Next Steps
Limitations
- Threshold instability: Some runs picked extreme thresholds (near 0 or 1), inflating/deflating F1 even when AP stable
- Small positive counts: Confusion matrix deltas swing with few examples; multiple seeds would improve confidence
- Matched sweep needed: Baseline and dendrites should be swept under identical search spaces and seeds for fair attribution
Next Steps
- Run paired sweeps (baseline vs dendrites) with identical ranges and 3–5 random seeds; report mean±std of AP
- Choose a business operating point (e.g., "precision ≥ 0.5") and compare models at that constraint
- Add efficiency metrics (params, wall-clock/step, memory) to quantify compute/size wins from dendrites
Tech Stack
- PyTorch – training framework
- PerforatedAI (Dendritic Optimization) – neural efficiency module
- Weights & Biases (W&B) – experiment tracking, sweeps, dashboards
- Google Colab – compute environment
- scikit-learn – PR-AUC, threshold optimization utilities
References
Xie, J., Zhang, K., Chen, J., Zhu, T., Lou, R., Tian, Y., Xiao, Y., & Su, Y. (2024). TravelPlanner: A Benchmark for Real-World Planning with Language Agents. arXiv preprint arXiv:2402.01622.

Log in or sign up for Devpost to join the conversation.