-
-

Main Navigation
-
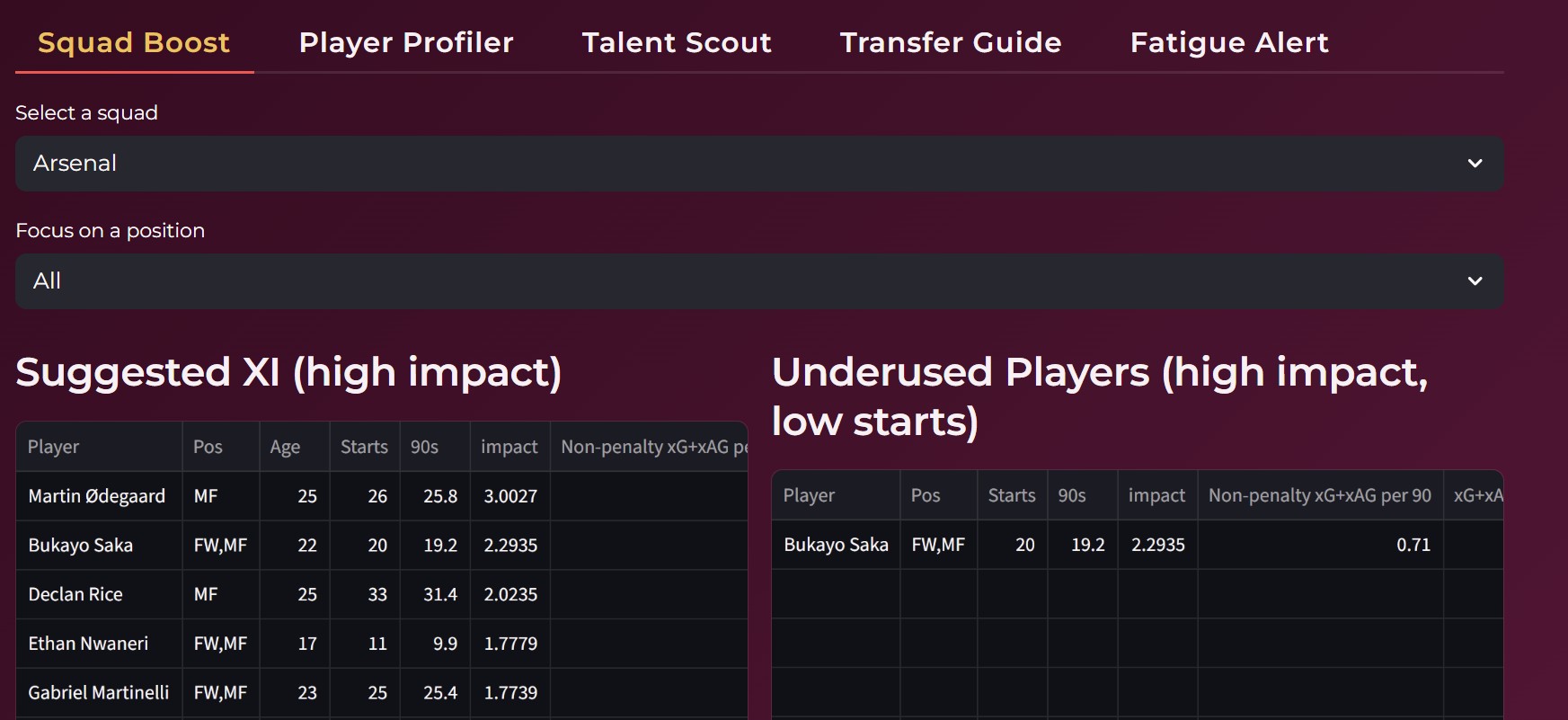
Squad Boost
-
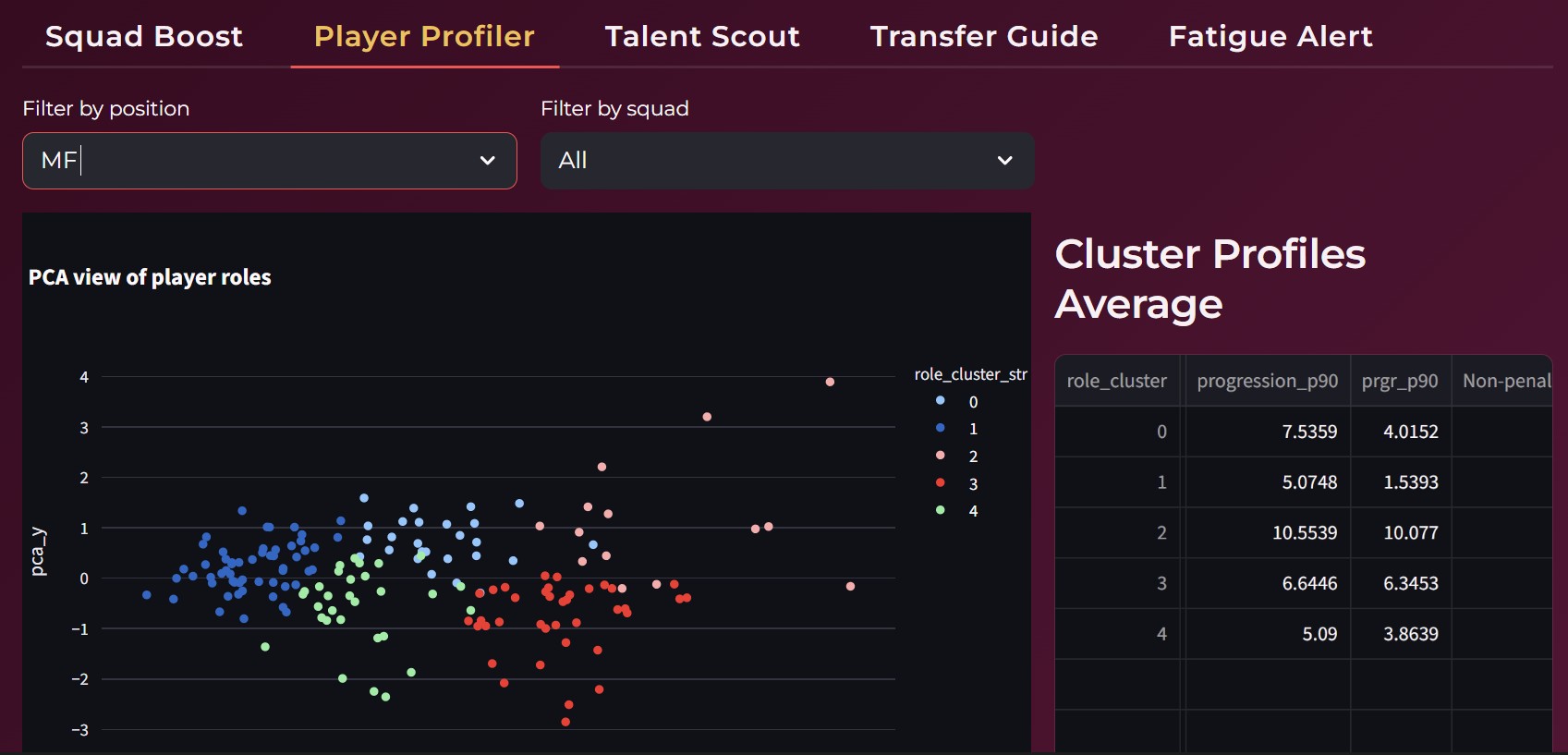
Player profiler
-
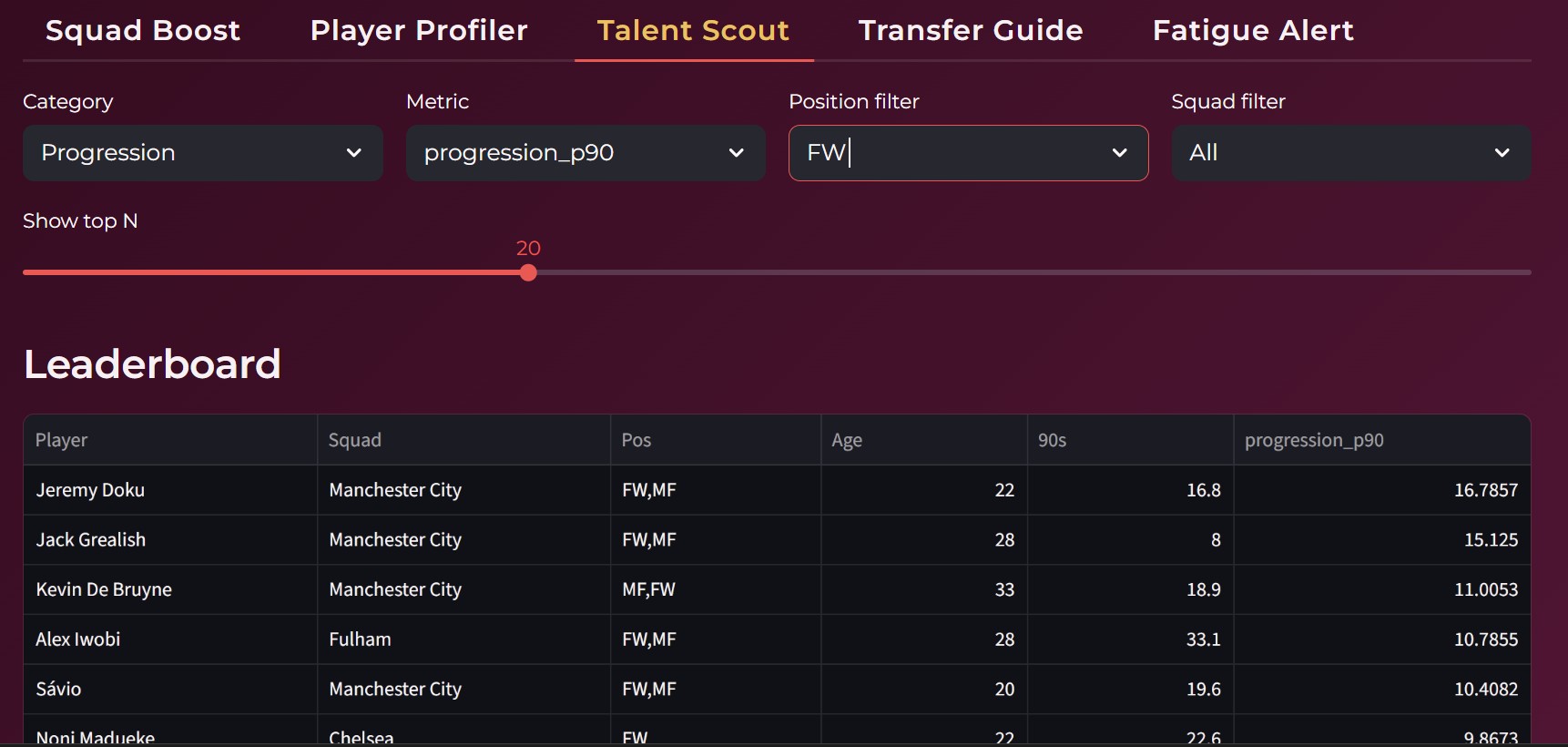
Talent Scout
-
Transfer guide
-
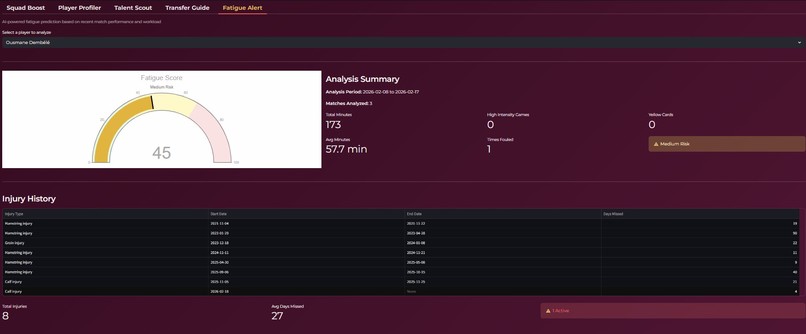
fatigue alert

Inspiration
As lifelong soccer fans, we have closely followed how the modern game has evolved into a faster, more physically demanding sport. With congested fixtures, high pressing systems, and global tournaments, injuries have become increasingly frequent and impactful. At the same time, an unprecedented amount of player performance data is publicly available, yet much of it remains underutilized in practical decision making.
We wanted to bridge that gap by combining our technical expertise in data science and machine learning with our passion for soccer . The goal was to create a system that translates raw data into actionable insights that coaches and analysts can actually use.
What it does
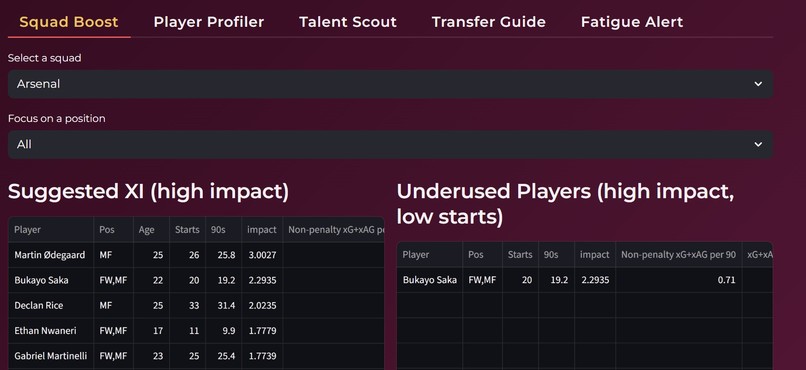
Coachlens serves as a comprehensive analytical assistant for coaches and performance teams. It acts as a one stop shop that consolidates player insights into a single, intuitive dashboard.
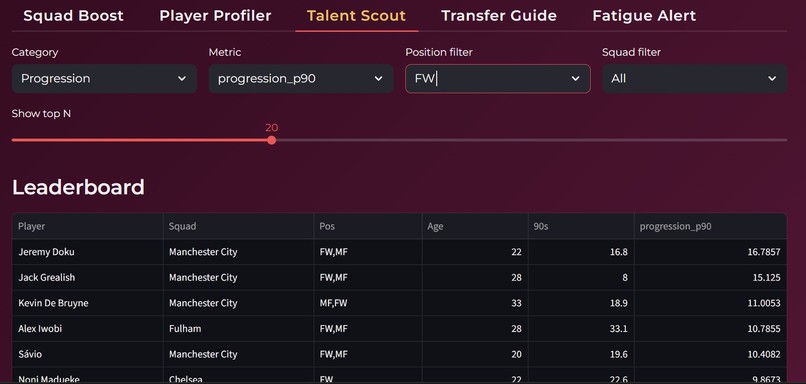
The platform identifies the most impactful players in a squad, highlights underperformers and overperformers, and provides context driven comparisons within the same league.
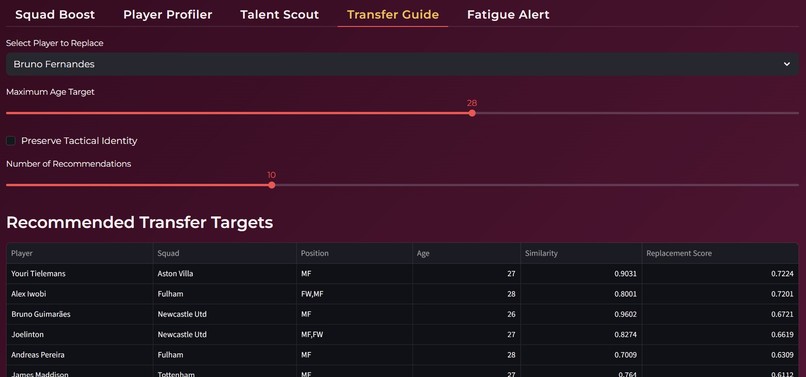
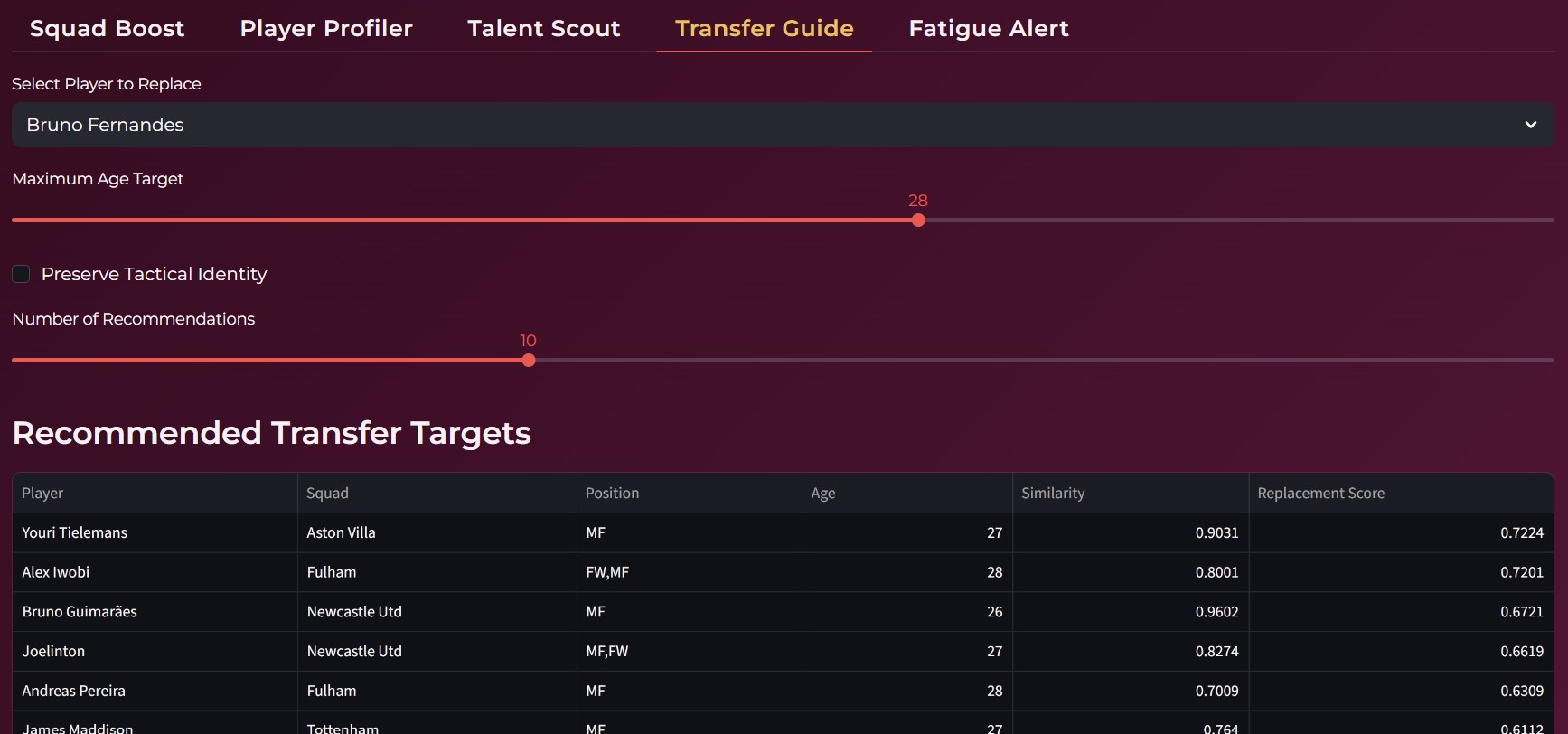
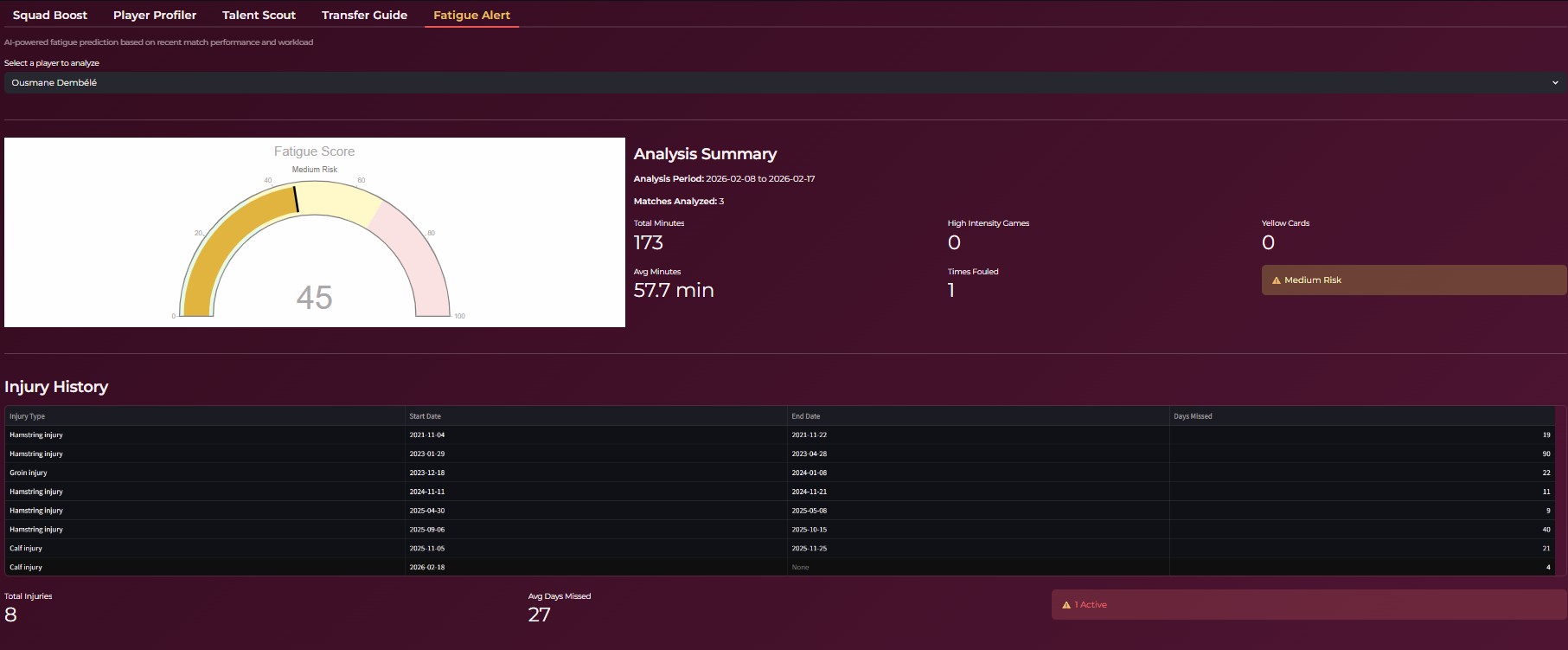
It also supports recruitment and squad management by recommending potential replacements when a player is unavailable, using similarity based retrieval techniques. Additionally, the system monitors fatigue levels by analyzing factors such as games played, minutes accumulated, and the nature of fouls suffered. Based on this, it guides managers in optimizing player minutes to reduce injury risk while maintaining competitive performance.
How we built it
The web interface was built using Streamlit in Python to enable rapid prototyping and interactive visualization.
For the database layer, we used Actian Vector Database to enable efficient storage and similarity based retrieval for player comparisons and transfer recommendations.
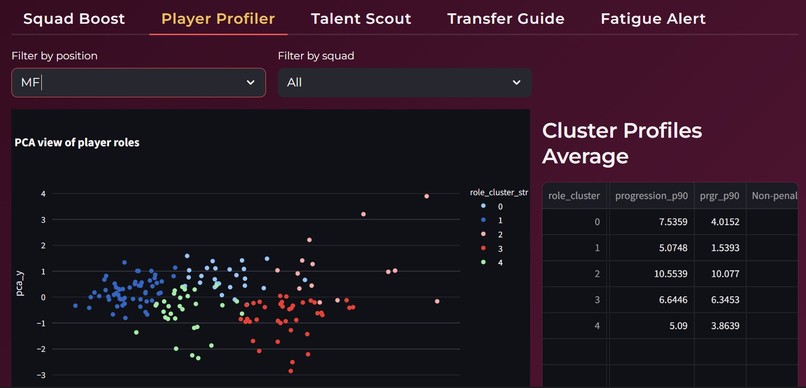
On the machine learning side, we applied Principal Component Analysis for dimensionality reduction and visualization of player profiles. KMeans clustering was used to group similar players based on performance metrics. XGBoost was implemented to compute and track a composite fatigue score by learning patterns from multiple workload and match related features.
Our primary datasets were sourced from freely available Kaggle repositories, including the Full Premier League 2024 to 2025 roster dataset, which we enriched through feature engineering.
Challenges we ran into
Setting up and configuring the Actian database with docker
A major challenge was quantifying abstract soccer concepts such as impact and fatigue. Translating these into measurable features required extensive feature engineering, domain understanding, and iterative validation.
We also faced difficulties in identifying reliable, comprehensive datasets. Public datasets often had missing fields, inconsistent formatting, or lacked certain advanced metrics, which required preprocessing and thoughtful assumptions.
Accomplishments that we're proud of
We successfully engineered meaningful metrics using only freely available statistics, combining mathematical formulations with learned machine learning models.
We also integrated modern technologies such as Actian Vector Database and machine learning optimization techniques to ensure fast similarity search and efficient hyperparameter tuning.
What we learned
Data driven decision making is becoming essential in modern soccer, especially to protect player health and maintain a competitive edge. Clubs that effectively translate data into strategy gain measurable advantages.
We also learned that the journey from raw data to actionable insights is far more complex than it appears. It requires not only technical expertise in data engineering and modeling but also strong domain knowledge to ensure that metrics reflect real world soccer dynamics.
What's next for Coachlens
We plan to incorporate video based annotations as additional and potentially real time inputs to our data pipeline. This will help validate and strengthen our metrics by linking quantitative outputs with visual evidence.
We also aim to expand beyond a single league by incorporating more historical and multi league datasets. By broadening coverage and increasing data depth, we intend to further improve model robustness, reliability, and practical applicability for professional teams.
Built With
- actian
- agentic-coding
- numpy
- pandas
- python
- scikit-learn
- streamlit


Log in or sign up for Devpost to join the conversation.