


Inspiration
The film industry has been an ever-evolving form of entertainment. Watching a movie is a form of relaxation for many, and given its accessibility, it's common for people to develop their own preferences for newly released movies. We wanted to look at the popularity of movies and their respective characteristics from a data science standpoint. Our passion for clean visualization and binge-watching movies led us to develop an application that tells the story behind the statistics of movie descriptions and an original algorithm for a personalized movie recommendation system.
What it does
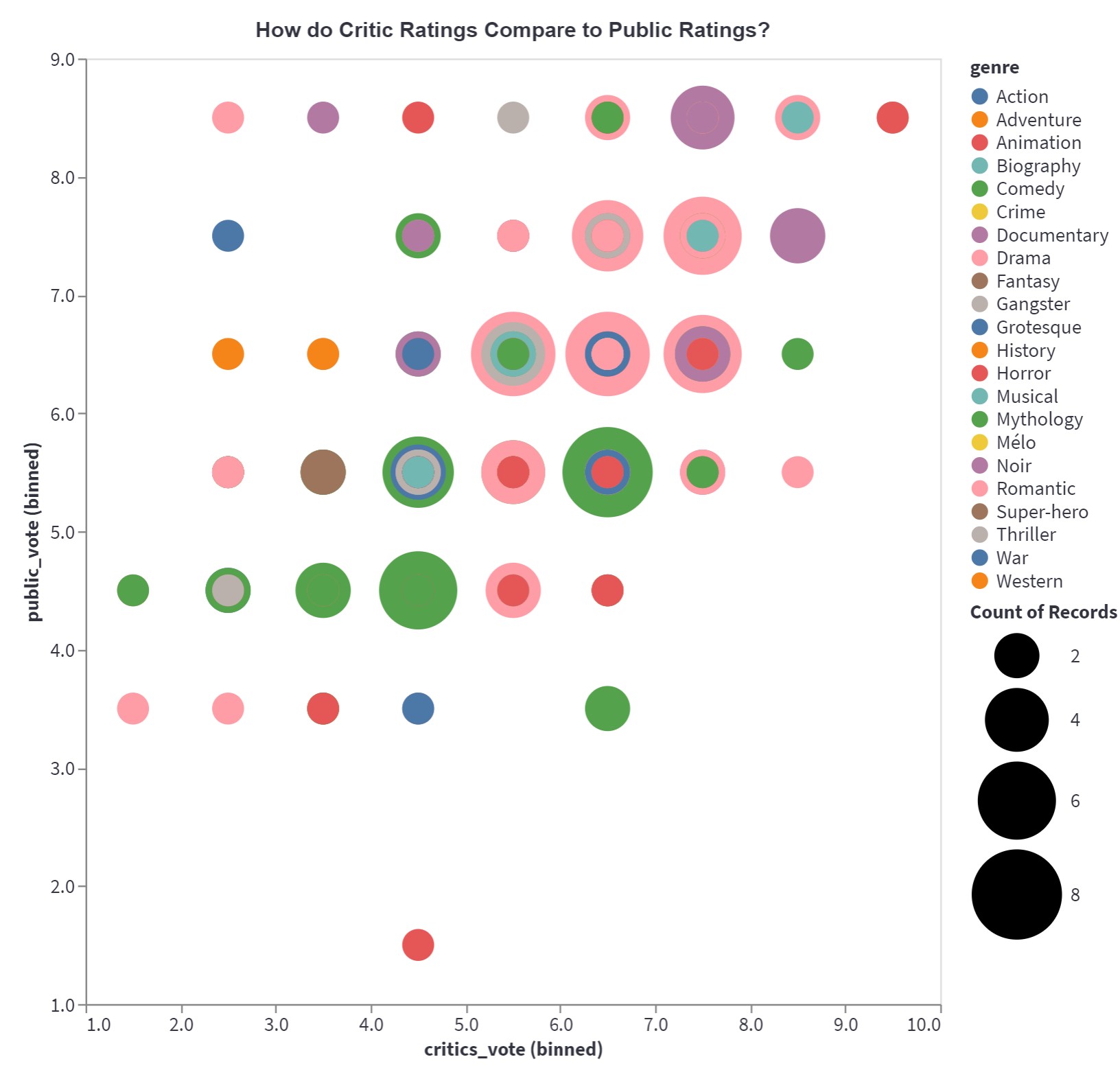
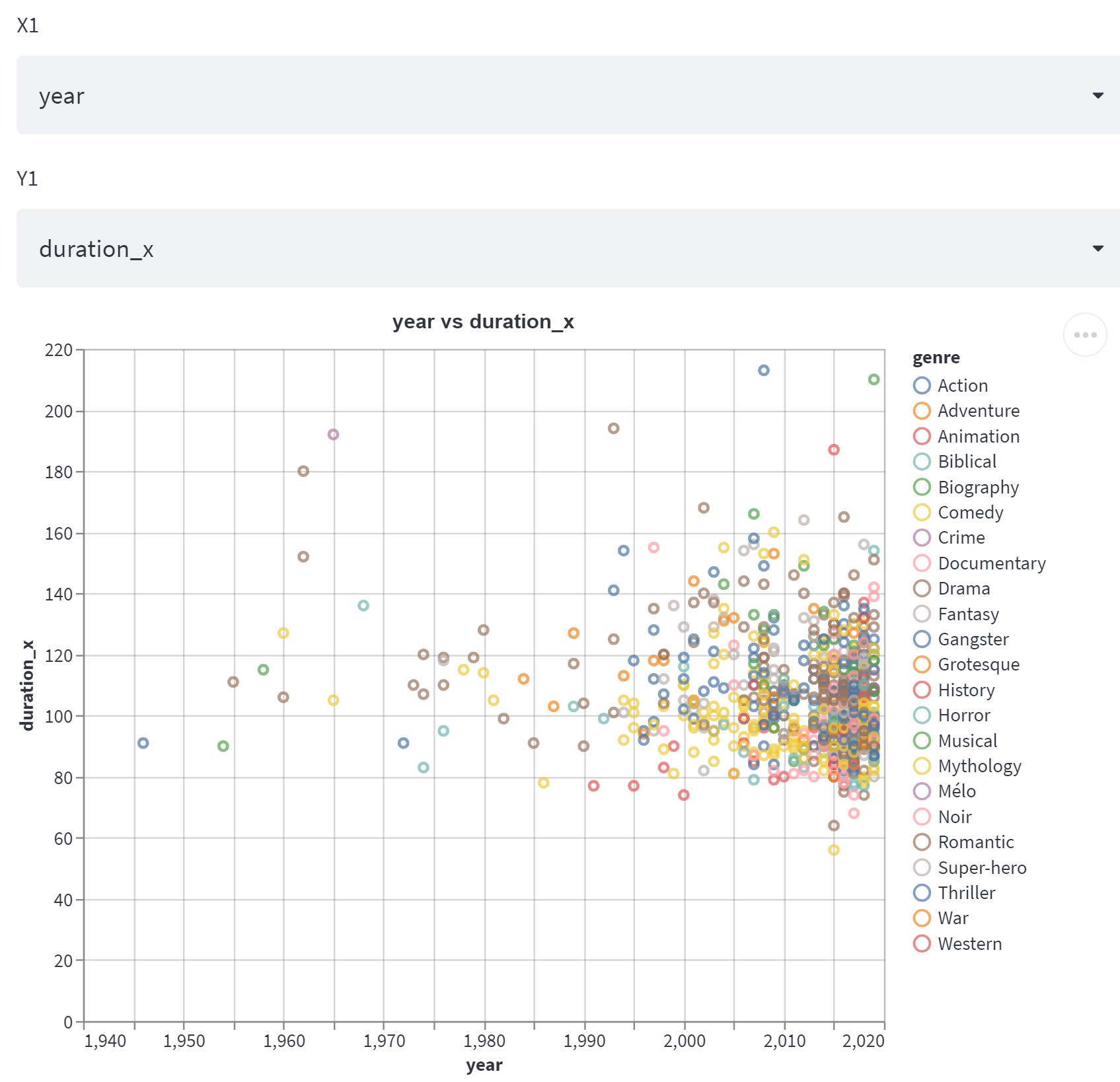
Our Streamlit app reflects our journey of data analysis, application, and coming up with our own algorithm for a recommendation system based on movie descriptions, comments, and ratings. The charts, which are interactive (dynamic inputs, hovering, zooming), uncover relationships that are invisible to us at first glance.
Our recommender system asks a user to enter in a few words or phrases to describe a movie that they would like to watch. Once entered, our recommender system will dynamically run an algorithm to determine the best fitting movies for your interest. Our system outputs the top 5 movies that best suits you!
How we built it
Python was used to perform data preprocessing and analysis. In particular, our datasets were sourced from IMDB and Netflix data and then preprocessed using the NumPy and Pandas libraries. Next, matplotlib was used for our exploratory data analysis. When we were able to identify certain trends and interesting figures in the data, our charts were further developed on Altair for its interactive flair. All of this was soon moved onto Streamlit for hosting.
Unlike typical recommendation systems that use Term Frequency-Intermediate Document Frequency (TF-IDF) and Cosine Similarity, our system blends the use of Natural Language Processing techniques, along with TF-IDF, Non-Negative Matrix Factorization (NMF), and Jaccard Distance to cluster movies based on related topics. A list of topics that were similar to the user's input was found. Movies were filtered based on comparing the descriptions' Jaccard Distance from the user input. The top five movies with the smallest Jaccard Distance were set to be returned as recommendations.
Challenges we ran into
- The domain of Movies and data science had a wide range popular applications. Initially we faced the difficulty to define a unique problem statement and its scope. Also there is very limited data available on movies and inclusivity combined. Finding a dataset that would fit what we wanted to explore was a hurdle.
- Our teammates who were in charge of deploying the application ended up withdrawing themselves from our team at the very last minute. Learning how to use a new application for deployment and showing our work in a professional form was challenging.
Accomplishments that we're proud of
- The original algorithm we have developed to recommend similar movies
- Time management, Team work, Planning ( we are a team of two different from different parts of the world)
What we learned
- Brain storming
- Developing streamlit application
- There are several features of Deepnote we explored
- Using the data visualization package “Altair”
- Video editing
What's next for our project
We plan on optimizing our algorithm and expanding our movie database to include more ratings, descriptions, and reviews. We plan on creating a better user interface and allowing more user flexibility on word input. In the next steps, we would like to find and expand our research on how we add the aspects of inclusivity in this domain and provide a wide range of recommendations.
Built With
- data-science-toolkit
- deepnote
- natural-language-processing
- python
- streamlit
Log in or sign up for Devpost to join the conversation.