-

title
-
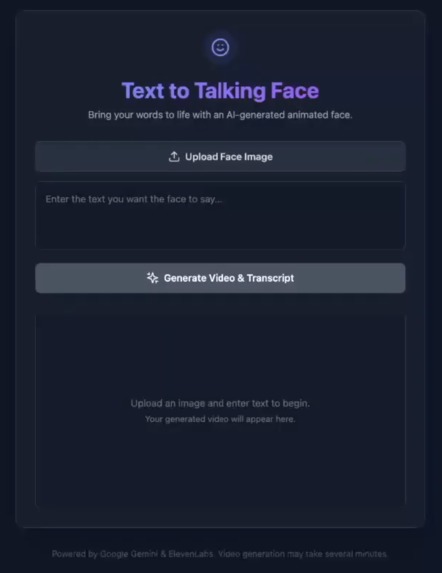
before
-

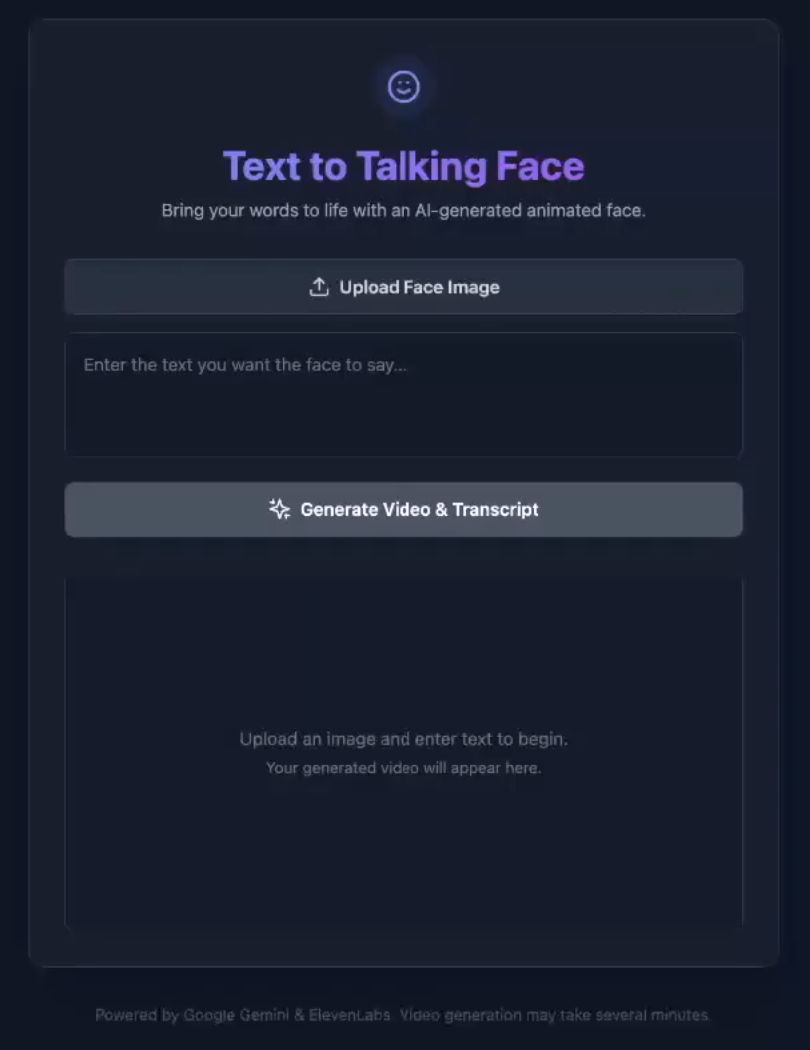
after


Inspiration
One team member’s childhood speech therapy experience inspired him to volunteer at a local clinic, where he saw the need for customizable videos to help apraxia patients better coordinate mouth movements. Together, our team is dedicated to supporting speech therapy patients on their recovery journey.
What it does
Our project takes in a static image of a face and a text input, and applies the Gemini Veo 3.1 Model to convert it to a short video that narrates the text. It then converts the video file to an audio file, which is passed into the ElevenLabs API. Finally, ElevenLabs creates timestamps for each word in the video so the user can replay it and focus on how the mouth moves when saying the selected word.
How we built it
We began with a high-level plan, which mapped out the control flow of the project and modeled it in Canva, being sure to outline each part of the project. Next, we utilized TypeScript, JavaScript, HTML/CSS, React, Next.js, Tailwind CSS, Framer Motion, Node.js, and Vite to develop the project. We also connected to the Gemini Veo and ElevenLabs APIs.
Challenges we ran into
Our main challenge was learning to use the new technologies, namely Veo 3.1, as it was released only a few days ago. Furthermore, we had some issues working around the paid trials, as Veo 3 quotas filled fast, and Veo 2 did not have the functionality to be compatible with what we wanted to do. We also had to pivot a few times, as our original plan was too complex for the time limit; however, we plan to build it out more in the near future.
Accomplishments that we're proud of
We are proud that we were able to persevere and get a working MVP in time for the deadline, as at many points during the process, we were debating redirecting the project's purpose or stuck on bugs for 50+ trials in a row. Additionally, we had great teamwork in splitting up the work and getting a professional and presentable demo product.
What we learned
We gained hands-on experience integrating Gemini Veo for video generation and ElevenLabs for word pronunciation isolation. We learned how to design an intuitive, interactive UI that makes learning more engaging. Beyond coding, we improved teamwork under tight deadlines, troubleshooting efficiently, and prioritizing features for maximum impact.
What's next
We plan to gamify the UI into a choose-your-own-adventure experience, letting users explore different environments and social situations while practicing pronunciation of words. Future features include real-time pronunciation feedback, interactive mini-games, and progress tracking to visualize improvement. Users will also be able to select different AI voices and accents, making the experience immersive, engaging, and context-driven.
Built With
- ai
- elevenlabs
- framer
- gemini
- google-cloud
- html/css
- javascript
- next.js
- node.js
- react
- tailwind
- typescript
- veo
- vite

Log in or sign up for Devpost to join the conversation.