
Inspiration
Tarka Research was inspired by the challenges researchers face in managing complex workflows—juggling in-depth research, data analysis, and document creation while maintaining accuracy and control. Existing tools like ChatGPT’s Canvas mode and Claude’s desktop apps often lack user-driven customization and transparency, leaving researchers frustrated with one-size-fits-all outputs. We envisioned a tool that empowers users with precise control over research, analysis, and writing, leveraging Perplexity’s Sonar API for real-time, cited data. Our goal was to create a seamless, customizable platform that enhances academic workflows, ensuring researchers can focus on insights, not tools.
What it does
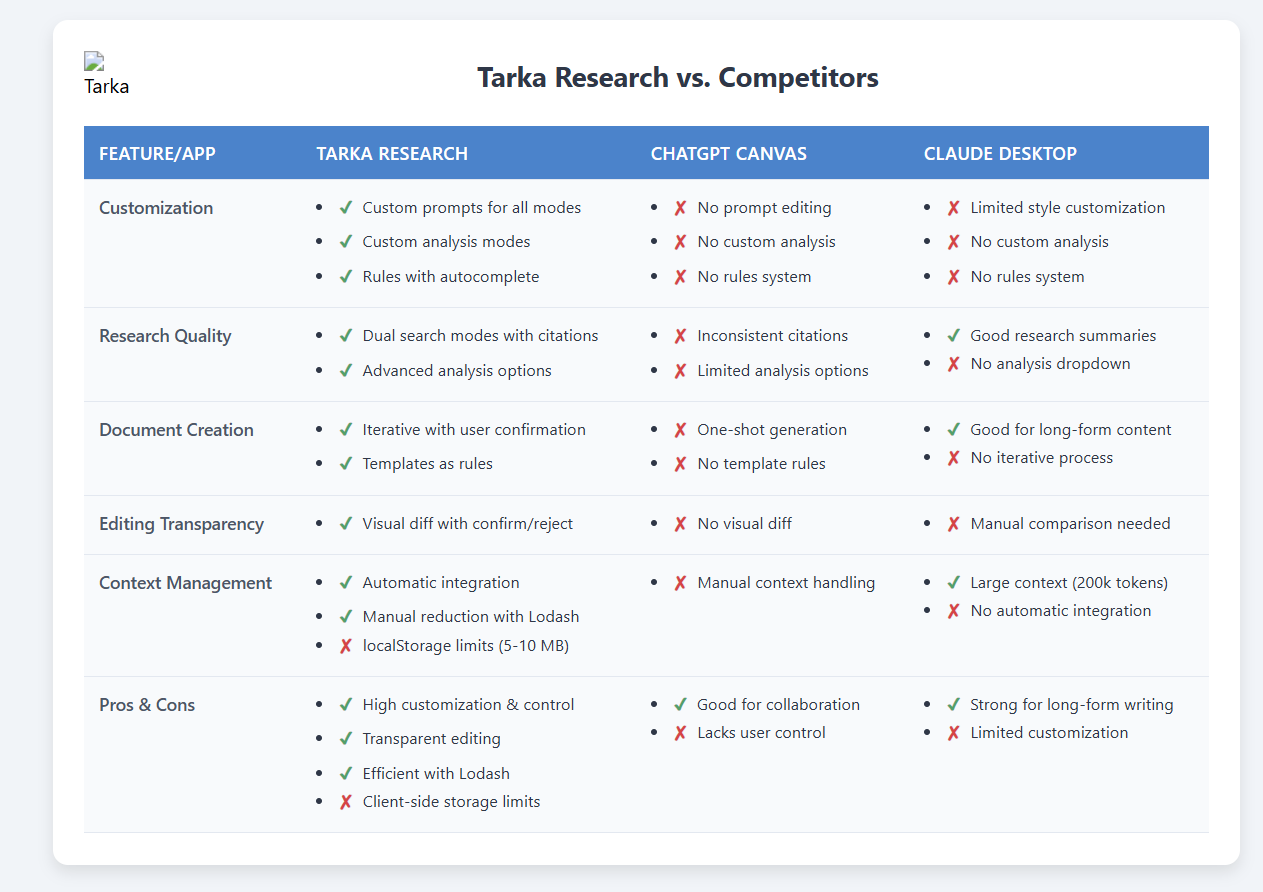
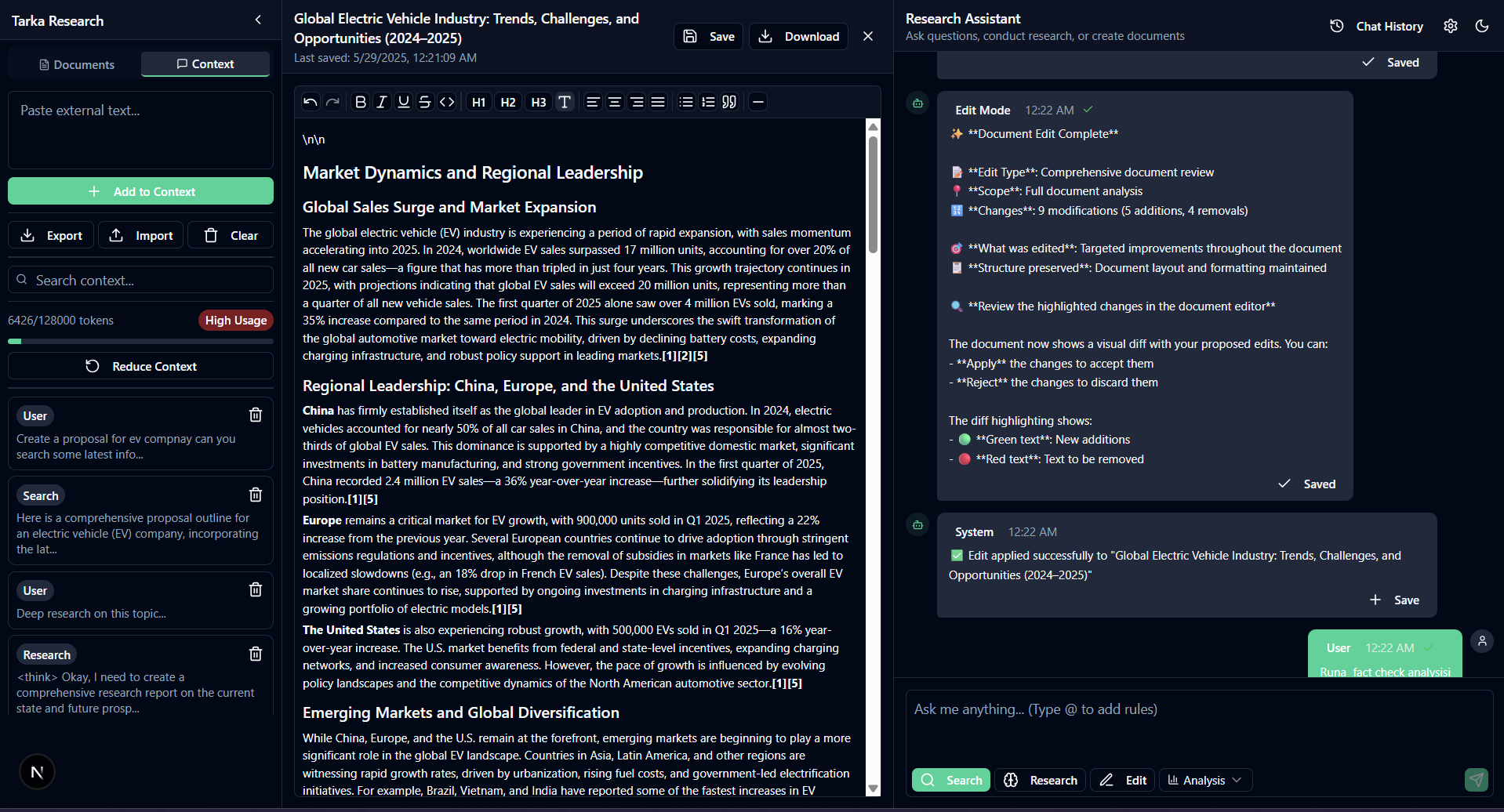
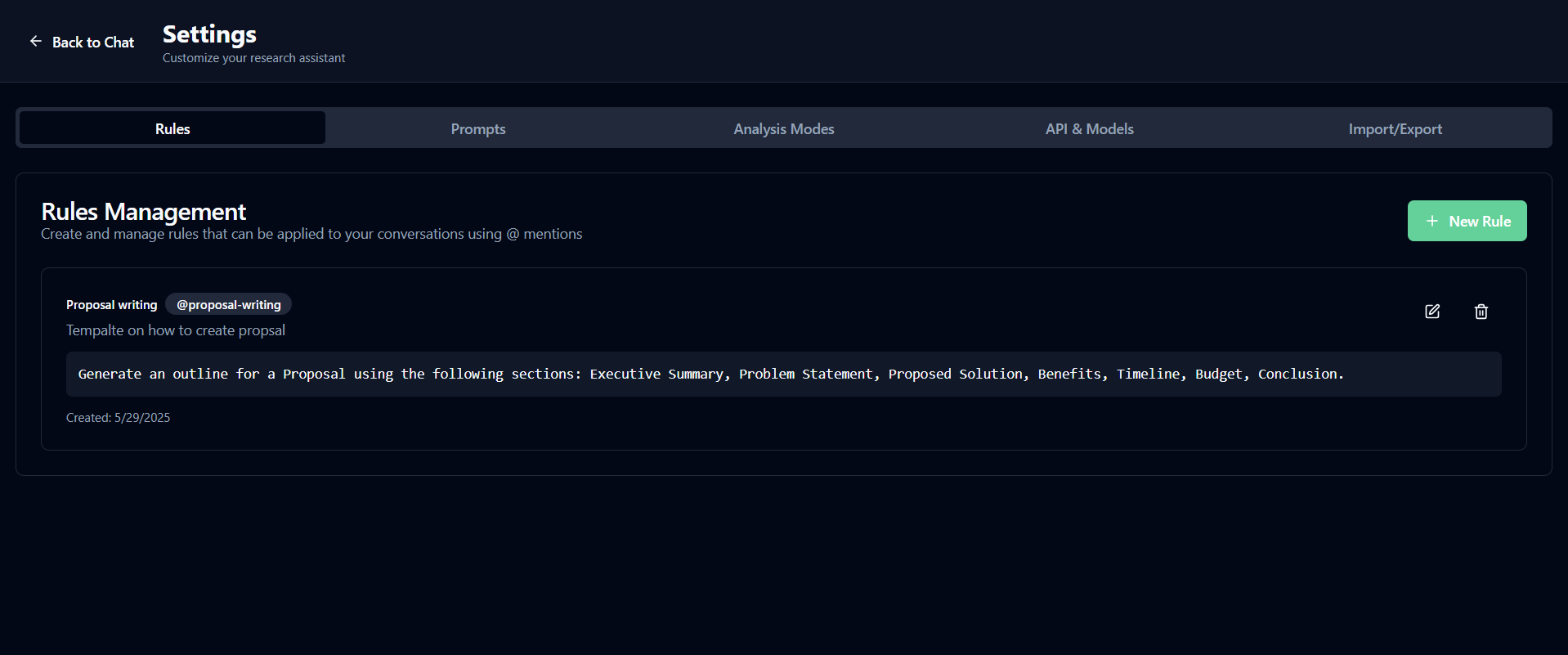
Tarka Research streamlines academic workflows with a powerful, user-centric platform. It offers dual search modes—quick searches and deep research—using Perplexity’s Sonar API for real-time, cited results. Users can analyze data with customizable modes (e.g., bias detection, tone checking) and create documents iteratively, confirming outlines and sections for precision. Rules like @ProposalTemplate and @AddReferences automate tasks, while a visual diff display ensures transparent editing. Context auto-saves with Lodash-optimized reduction, and a new conversation resets everything. Custom prompts in Settings tailor AI behavior, making research efficient and controlled.
How we built it
We built Tarka Research using Next.js for a robust frontend and backend. The Perplexity Sonar API powers search and analysis, with models like sonar-small-online for quick searches and sonar-pro for advanced tasks. We used Zustand for state management and Lodash for efficient data manipulation, storing data in localStorage for persistence. Features like iterative document creation, visual diff editing with diff-match-patch, and rules with autocomplete were implemented using React components (ChatArea, DocumentEditor, Settings). API routes handle interactions with Perplexity’s API, ensuring seamless integration. The app was deployed on Vercel for accessibility.
Challenges we ran into
Building Tarka Research came with hurdles. Integrating Perplexity’s Sonar API required careful handling of rate limits and streaming responses, which was tricky for real-time search results. Switching from file-based storage to localStorage mid-development posed data migration challenges, especially ensuring persistence across page refreshes. Implementing the visual diff display with diff-match-patch needed precise styling for clarity. Balancing customization (e.g., custom analysis modes, rules) with a user-friendly interface was complex, as was optimizing Lodash operations to manage large datasets efficiently. Time constraints near the deadline pushed us to prioritize features while maintaining quality.
Accomplishments that we’re proud of
We’re proud of creating a highly customizable research tool that outshines competitors. Tarka Research’s dual search modes deliver reliable, cited results, and user-defined analysis modes (e.g., "Check Tone") offer unparalleled flexibility. The iterative document creation process, with user confirmation at every step, ensures precision, while rules like @ProposalTemplate streamline workflows. The visual diff display for editing enhances transparency, a feature missing in ChatGPT and Claude. We’re especially proud of our efficient context management using Lodash and localStorage, enabling seamless research integration. Completing this under tight deadlines while maintaining a polished user experience is a significant achievement.
What we learned
Developing Tarka Research taught us the intricacies of integrating third-party APIs like Perplexity’s Sonar API, especially managing streaming data and rate limits. We learned to balance customization with usability, ensuring features like rules and custom prompts are intuitive. Using Lodash for data manipulation highlighted its power in optimizing state operations, while localStorage taught us the trade-offs of client-side persistence. We gained insights into iterative workflows, realizing the importance of user control in academic tools. Collaboration under pressure honed our time management and prioritization skills, crucial for hackathons.
What’s next for Tarka Research
Tarka Research has exciting plans ahead. We aim to transition from localStorage to a server-side database like SQLite for better scalability and to support features like MCP Servers, which will enable distributed processing for faster research. Adding collaborative editing will allow teams to work together seamlessly. We plan to expand the rules library with more templates and AI-driven suggestions, enhancing automation. Integrating more advanced analysis modes using sonar-reasoning will deepen insights. Finally, we’ll refine the UI for accessibility and explore mobile support, ensuring Tarka Research becomes the go-to tool for researchers worldwide.
Built With
- next
- perplexity
- python

Log in or sign up for Devpost to join the conversation.