-
-
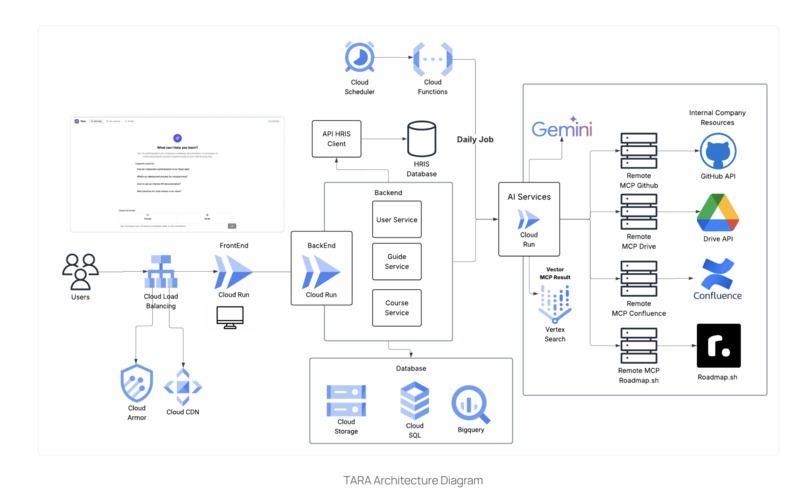
Architecture Diagram
-
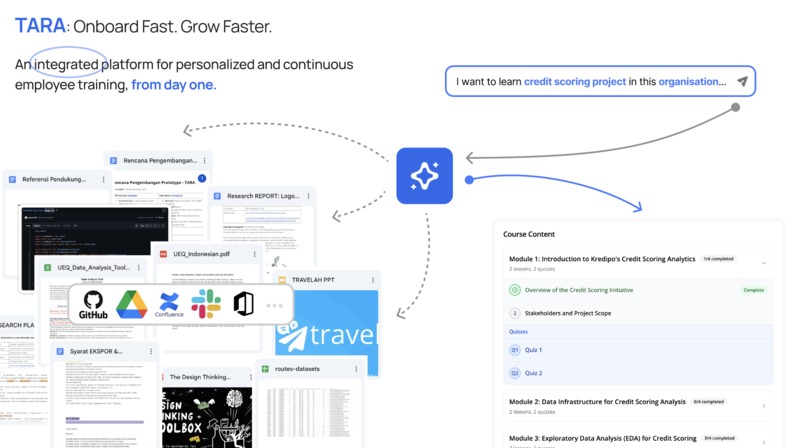
Overview
-
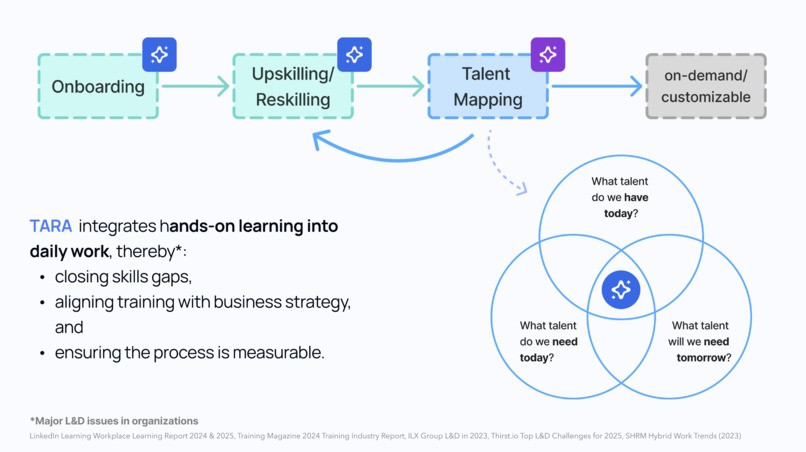
Value Proposition


TARA: On-Demand Course Generation Platform for Employee Onboarding
Cloud Run Hackathon Submission - AI Agents Category
Project Overview
TARA is an AIaaS platform that transforms internal company knowledge into personalized, interactive training courses using multi-agent AI orchestration. Built with Google's Agent Development Kit (ADK) and deployed on Cloud Run, TARA accelerates employee onboarding and closes digital talent gaps by automatically generating comprehensive courses from internal codebases, documentation, and web resources.
Problem Solved: Companies struggle with lengthy onboarding (Time to First Commit > 1 week) and knowledge silos. TARA reduces this to under 4 hours by converting internal knowledge into structured, AI-generated courses.
Multi-Agent Architecture (ADK)
TARA implements a sophisticated multi-agent system using Google's Agent Development Kit with five cooperating agents:
Primary Course Generation Agent
Built with ADK's Agent class and powered by Gemini 2.5 Flash:
from google.adk.agents import Agent
from google.adk.tools import FunctionTool
class CourseGenerationAgent:
def __init__(self, github_token=None, drive_token=None, user_id=None):
self.source_manager = SourceManager()
self.source_tracker = EnhancedSourceTracker()
# Initialize specialized tool agents
self.github_tool = GitHubMCPTool()
self.drive_tool = GoogleDriveMCPTool(user_id, drive_token)
self.search_tool = GoogleSearchTool()
# Create ADK agent with tool orchestration
self.agent = self._create_agent()
def _create_agent(self) -> Agent:
"""Create ADK agent with all tools."""
tools = []
# Add tool functions for agent to use
tools.extend([
FunctionTool(self.discover_sources),
FunctionTool(self.analyze_tech_stack),
FunctionTool(self.extract_repository_content),
FunctionTool(self.determine_difficulty),
])
return Agent(
model=settings.model_name, # gemini-2.5-flash
name=settings.name,
instruction="""You are an expert course generation agent...""",
tools=tools,
)
Deployment: Cloud Run Service exposing REST API via FastAPI
Four Specialized Tool Agents
1. RAG Search Agent
Source:
course_agent/tools/rag_tool.py
Uses BigQuery Vector Search for internal knowledge retrieval:
class RAGSearchTool(ContentSource):
def __init__(self):
# Initialize BigQuery vector search client
self.vector_search = BigQueryVectorSearch(
project_id=settings.google_cloud_project,
dataset_id="tara_knowledge",
table_id="document_embeddings"
)
async def search(self, query: SearchQuery) -> List[SourceResult]:
"""Semantic search across internal documents."""
# Generate query embedding
query_embedding = await self._embed_query(query.query)
# Vector similarity search in BigQuery
results = await self.vector_search.similarity_search(
query_vector=query_embedding,
top_k=query.max_results,
threshold=0.7
)
# Convert to SourceResult format
return [
SourceResult(
content=result['content'],
source=result['source'],
relevance_score=result['similarity'],
source_type=SourceType.INTERNAL
)
for result in results
]
Data Sources: HRIS, Confluence, Google Drive, CVs, learning paths
Priority: First agent called - internal knowledge prioritized
GraphRAG Implementation:
TARA uses roadmap.sh dataset as the foundation for course structure, implementing GraphRAG (Graph-based RAG) to understand skill relationships and prerequisites.
Source:
learning_path/roadmap_graph.pyandlearning_path/roadmap_scraper.py
# learning_path/roadmap_graph.py
class RoadmapGraph:
"""Manages roadmap.sh data as a directed graph using NetworkX."""
...
# Add edges (prerequisites/progressions)
for edge in roadmap_data['edges']:
self.graph.add_edge(
edge['from'],
edge['to'],
weight=edge.get('weight', 1.0),
relationship=edge.get('type', 'prerequisite')
)
def find_learning_path(self, current_skills: List[str], target_skill: str):
"""Find optimal learning path using graph traversal."""
if not current_skills:
# Start from prerequisites
path = self._get_all_prerequisites(target_skill)
else:
# Find shortest path from current position
try:
path = networkx.shortest_path(
self.graph,
source=current_skills[-1],
target=target_skill
)
except networkx.NetworkXNoPath:
# No direct path, get prerequisites
path = self._get_all_prerequisites(target_skill)
return path
def _get_all_prerequisites(self, skill: str) -> List[str]:
"""Get all prerequisites using topological sort."""
# Get subgraph of all ancestors (prerequisites)
ancestors = networkx.ancestors(self.graph, skill)
subgraph = self.graph.subgraph(list(ancestors) + [skill])
# Return topologically sorted path
return list(networkx.topological_sort(subgraph))
def get_course_structure(self, learning_path: List[str]):
"""Convert learning path to structured course modules."""
modules = []
for idx, skill_id in enumerate(learning_path, 1):
node_data = self.graph.nodes[skill_id]
modules.append({
"index": idx,
"skill_id": skill_id,
"title": node_data['title'],
"category": node_data['category'],
"prerequisites": list(self.graph.predecessors(skill_id)),
"next_skills": list(self.graph.successors(skill_id)),
"roadmap_source": node_data['roadmap']
})
return modules
def calculate_skill_gap(self, current_skills: List[str], target_skill: str):
"""Calculate the gap between current and target skills."""
path = self.find_learning_path(current_skills, target_skill)
# Remove already known skills
gap = [skill for skill in path if skill not in current_skills]
return {
"missing_skills": gap,
"gap_size": len(gap),
"estimated_duration": len(gap) * 2, # 2 hours per skill
"learning_path": path
}
# course_agent/tools/roadmap_tool.py
class RoadmapTool:
"""Tool for accessing roadmap.sh GraphRAG."""
def __init__(self):
self.graph = RoadmapGraph()
async def generate_course_outline(self, user_skills: List[str], target_skill: str):
"""Generate structured course outline from graph."""
# Calculate skill gap
gap_analysis = self.graph.calculate_skill_gap(user_skills, target_skill)
# Get structured course modules
course_structure = self.graph.get_course_structure(
gap_analysis['learning_path']
)
return {
"learning_path": gap_analysis['learning_path'],
"skill_gap": gap_analysis['missing_skills'],
"total_modules": len(gap_analysis['learning_path']),
"estimated_duration": gap_analysis['estimated_duration'],
"modules": course_structure,
"source": "roadmap.sh via RoadmapGraph"
}
Knowledge Graph Structure:
roadmap.sh Dataset (learning_path/)
│
├─── frontend.json
├─── backend.json
├─── python.json
├─── react.json
└─── machine-learning.json
│
▼
┌─────────────────────────────────────┐
│ GraphRAG (NetworkX) │
│ │
│ HTML ──→ CSS ──→ JavaScript │
│ │ │ │ │
│ │ │ ├──→ React │
│ │ │ ├──→ Vue │
│ │ │ └──→ Angular │
│ │ │ │
│ │ └──→ Responsive Design │
│ └──→ Semantic HTML │
│ │
│ Python ──→ NumPy ──→ Pandas │
│ │ │ │
│ └──────────┴──→ ML │
└─────────────────────────────────────┘
│
▼
Course Structure Generation
• Find prerequisites (graph.predecessors)
• Calculate skill gap (path finding)
• Optimize learning path (shortest_path)
• Topological sort modules (topological_sort)
2. GitHub MCP Agent
Leverages Model Context Protocol for repository access:
from google.adk.tools.mcp_tool import McpToolset, StreamableHTTPConnectionParams
class GitHubMCPTool(RepositoryTool):
def __init__(self):
self._initialize_mcp()
def _initialize_mcp(self):
"""Initialize MCP connection to GitHub."""
token = os.getenv('GITHUB_PERSONAL_ACCESS_TOKEN')
# Create MCP toolset with GitHub server
self._mcp_tools = McpToolset(
connection_params=StreamableHTTPConnectionParams(
url="http://localhost:3000",
headers={"Authorization": f"Bearer {token}"}
)
)
async def search_repositories(self, query: str) -> List[Dict]:
"""Search GitHub repositories via MCP."""
# Use MCP's search_repositories tool
results = await self._mcp_tools.invoke_tool(
"search_repositories",
arguments={"query": query, "max_results": 5}
)
return results
async def get_file_contents(self, repo: str, path: str) -> str:
"""Retrieve file contents via MCP."""
content = await self._mcp_tools.invoke_tool(
"get_file_contents",
arguments={"repository": repo, "path": path}
)
return content
Output: Production-ready code examples from discovered repositories
Priority: Fallback when internal knowledge is insufficient
3. Web Search Agent
Uses Google Search for external resources:
from google.adk.tools import google_search
class GoogleSearchTool(ContentSource):
def __init__(self):
# Create specialized search agent
self.search_agent = Agent(
model=settings.model_name,
name="course_search_agent",
instruction="""Find educational and technical content.
Focus on tutorials, documentation, and guides.""",
tools=[google_search],
)
self.runner = InMemoryRunner(agent=self.search_agent)
async def search(self, query: SearchQuery) -> List[SourceResult]:
"""Search web for educational content."""
search_prompt = f"""
Search for educational content about: {query.query}
Find {query.max_results} high-quality resources for a technical course.
"""
# Execute search through ADK runner
results = await self.runner.run(search_prompt)
return self._parse_search_results(results, query.query)
Priority: Final fallback for comprehensive coverage
4. Google Drive MCP Agent
Source:
course_agent/tools/drive_tool.py
Accesses company documents via Model Context Protocol:
class GoogleDriveMCPTool(RepositoryTool):
def __init__(self, user_id: str, access_token: str):
self._user_id = user_id
self._access_token = access_token
self._mcp_url = os.getenv("MCP_DRIVE_URL", "http://localhost:9000")
self._initialize_mcp()
def _initialize_mcp(self):
"""Initialize MCP connection to Google Drive."""
# Verify MCP server is reachable
response = requests.post(
self._mcp_url,
json={
"jsonrpc": "2.0",
"id": 0,
"method": "tools/list"
},
timeout=5
)
self._mcp_tools = response.status_code == 200
async def search_files(self, query: str) -> List[Dict]:
"""Search files in Google Drive via MCP."""
response = requests.post(
self._mcp_url,
json={
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": "search_files",
"arguments": {
"query": query,
"access_token": self._access_token
}
}
}
)
return response.json()["result"]
async def read_file(self, file_id: str) -> str:
"""Read file contents from Google Drive."""
response = requests.post(
self._mcp_url,
json={
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": "read_file",
"arguments": {
"file_id": file_id,
"access_token": self._access_token
}
}
}
)
return response.json()["result"]["content"]
Data Sources: Company documentation, presentations, spreadsheets
Integration: Secure token-based authentication per user
Agent Communication Workflow
User Request → Course Generation Agent (ADK)
↓
├─→ [1] RAG Agent: Search Internal Knowledge (PRIORITY)
│ └── BigQuery Vector Search → Company Docs (cached)
│
├─→ [2] Drive Agent: Access Google Drive Documents
│ └── MCP Protocol → Drive Search & File Reading
│
├─→ [3] GitHub Agent: Find Code Examples
│ └── MCP Protocol → Repository Search
│
└─→ [4] Search Agent: Web Resources (FINAL FALLBACK)
└── Google Search → External Content
↓
Agent Synthesis & Course Generation
↓
JSON Output: Modules + Lessons + Quizzes + Skills
Agent Coordination Features:
- Intelligent tool selection based on query context
- Real-time agent iteration and refinement
- Multi-source information synthesis
- Automatic source attribution
Cloud Run Implementation
Our system runs on Google Cloud Run using a multi-service architecture with 4 containers across 3 services:
- tara-frontend: Next.js (1 CPU / 1 Gi)
- tara-backend: FastAPI (2 CPU / 4 Gi)
- tara-ai: AI/ML agent (2 CPU / 4 Gi) + sidecar MCP Drive server for localhost communication
Networking & Security
- Ingress:
internal-and-cloud-load-balancing
→ Only accessible via Google Cloud Load Balancer (secure, DDoS-protected, TLS-terminated) - VPC:
vpc-tarawith--vpc-egress=private-ranges-only
→ Enables private, internal service-to-service networking
Features
- Multi-container & sidecar deployment
- VPC isolation and secure ingress
- Serverless auto-scaling
- CI/CD via GitHub Actions + Google Artifact Registry
Services Architecture
Main API Service
- Type: Cloud Run Service
- Framework: FastAPI (Python 3.13)
- Container: Docker with health checks
- Scaling: Auto-scaling based on request load
- Region: Configurable (us-central1 default)
Deployment Specifications:
Source:
Dockerfile
FROM python:3.13-slim
WORKDIR /app
# Docker CLI included for potential container operations
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
Health Check Endpoint: GET / - Returns service status
GCP Products Integration
| Product | Usage | Implementation | Purpose |
|---|---|---|---|
| Vertex AI | Gemini 2.5 Flash Model | gemini-2.5-flash via Vertex AI API |
Agent reasoning, content generation, quiz creation, skills extraction |
| BigQuery Vector Search | Vector Database | LangChain + BigQuery ML | Semantic search across internal documents with <100ms latency |
| Cloud Run | Container Platform | Docker deployment with auto-scaling | Serverless API hosting, HTTP request handling |
| Cloud Storage | Object Storage | Document pipeline integration | Training materials, parsed documents, embeddings storage |
| Secret Manager | Credentials Management | Secure token storage | GitHub PAT, Drive tokens, API keys |
| Cloud Logging | Monitoring | Structured logging | Agent activity tracking, error monitoring |
| IAM | Access Control | Service accounts | Cross-service authentication |
Technical Implementation
Source:
main.py
API Endpoint
POST /course/generate
Request Body:
{
"token_github": "ghp_xxxxx",
"token_drive": "",
"prompt": "Create a Python machine learning course with XGBoost on Vertex AI",
"files_url": ""
}
Response Structure:
{
"title": "Machine Learning with XGBoost on Vertex AI",
"description": "Comprehensive course covering ML fundamentals...",
"difficulty": "Intermediate",
"estimated_duration": 12,
"learning_objectives": [
"Understand XGBoost algorithm",
"Deploy models on Vertex AI",
"Implement MLOps workflows"
],
"skills": [
"Python",
"XGBoost",
"Vertex AI",
"MLOps",
"Google Cloud",
"scikit-learn",
"Model Deployment",
"Feature Engineering"
],
"modules": [
{
"title": "Introduction to XGBoost",
"index": 1,
"lessons": [
{
"title": "XGBoost Fundamentals",
"index": 1,
"content": "# XGBoost Fundamentals\n\n## Overview\n..."
},
{
"title": "Hands-on: First XGBoost Model",
"index": 2,
"content": "# Building Your First Model\n\n```python\n..."
}
],
"quiz": [
{
"question": "What is the primary advantage of XGBoost over traditional decision trees?",
"choices": {
"A": "Faster training on small datasets",
"B": "Gradient boosting with regularization",
"C": "Simpler hyperparameter tuning",
"D": "Better for linear relationships"
},
"answer": "B"
},
{
"question": "Which Vertex AI service is used for model deployment?",
"choices": {
"A": "Cloud Run",
"B": "Vertex AI Endpoints",
"C": "App Engine",
"D": "Cloud Functions"
},
"answer": "B"
}
]
}
],
"source_from": [
"https://github.com/dmlc/xgboost",
"https://github.com/GoogleCloudPlatform/vertex-ai-samples"
]
}
Key Features
| Feature | Description | Technical Detail |
|---|---|---|
| Multi-Source Intelligence | Cascading search strategy | RAG & GraphRAG → Drive → GitHub → Web with configurable priority |
| Automated Assessment | Quiz generation per module | 2-4 multiple choice questions with validated answers |
| Skills Extraction | Technology identification | 8-12 relevant skills per course using NLP |
| Real Code Examples | Production code discovery | GitHub repository analysis with syntax highlighting |
| Source Attribution | Transparency tracking | Complete source lineage with URLs |
| Difficulty Adaptation | Dynamic course levels | Beginner/Intermediate/Advanced based on content analysis |
Technology Stack
| Component | Technology | Purpose |
|---|---|---|
| Agent Framework | Google ADK | Multi-agent orchestration |
| LLM | Gemini 2.5 Flash | Content generation, reasoning |
| Vector Database | BigQuery Vector Search | Semantic knowledge retrieval |
| Knowledge Graph | NetworkX (current), Neo4j (future) | roadmap.sh dataset for skill paths |
| API Framework | FastAPI | REST API server |
| Document Processing | LlamaIndex | Parsing, chunking |
| Vector Integration | LangChain | Vector store operations |
| Container | Docker | Cloud Run deployment |
| MCP Protocol | GitHub MCP, Drive MCP | Repository and file access |
Project Structure
tara-ai-ml-agent/
├── main.py # FastAPI application entry
├── Dockerfile # Cloud Run container config
├── requirements.txt # Python dependencies
├── learning_path/ # roadmap.sh GraphRAG dataset
│ ├── roadmaps/ # Structured learning paths
│ │ ├── frontend.json # Frontend development path
│ │ ├── backend.json # Backend development path
│ │ ├── python.json # Python learning path
│ │ └── ... # Other tech stacks
│ └── roadmap_graph.py # NetworkX graph operations
├── course_agent/
│ ├── agents/
│ │ └── course_agent.py # ADK-powered main agent
│ ├── config/
│ │ └── settings.py # Environment configuration
│ ├── tools/
│ │ ├── rag_tool.py # BigQuery Vector Search tool
│ │ ├── github_tool.py # GitHub MCP tool
│ │ ├── drive_tool.py # Google Drive MCP tool
│ │ ├── search_tool.py # Google Search tool
│ │ └── roadmap_tool.py # GraphRAG roadmap.sh tool
│ ├── core/
│ │ └── source_manager.py # Multi-source orchestration
│ └── rag_processor.py # Document processing pipeline
└── test_new_format.py # Quiz/skills format testing
Business Impact & Metrics
Employee Impact
| Metric | Before TARA | After TARA | Improvement |
|---|---|---|---|
| Time to First Commit (developers) | >1 week | <4 hours | 95% reduction |
| Time to Productivity (all roles) | 6 months | 3.6 months | 40% faster |
| Knowledge Retention Score | Baseline | +30% | 30% increase |
| Training Completion Rate | 60-70% | 90%+ | 20-30% increase |
Company Impact
| Metric | Impact | Description |
|---|---|---|
| New Hire Turnover | -15% | Better onboarding experience reduces early attrition |
| Onboarding Cost | Significant reduction | Automated course generation vs manual training |
| Skill Gap Closure | Accelerated | Faster digital transformation capability |
| Training ROI | Higher completion | More employees finish relevant training |
Target Market
| Segment | Size | Focus Area |
|---|---|---|
| Primary | Tech companies (100-5000 employees) | Developer onboarding, technical training |
| Secondary | Financial institutions | Fintech, banking, regulatory compliance training |
| Geography | Indonesia & Southeast Asia | Country with similar onboarding culture |
Submitted Repositories for this Hackathon:
- Backend: https://github.com/Tara-AI-App/Backend (see details in README.md)
- Frontend: https://github.com/Tara-AI-App/Frontend (see details in README.md)
- AI/ML Agent: https://github.com/Tara-AI-App/devpost-tara-ai
TARA: Onboard Fast. Grow Faster.
Built with Google Cloud Run, ADK, Gemini 2.5 Flash, and BigQuery
#CloudRunHackathon #GoogleCloud #AIAgents #ADK #GeminiAI
Built With
- adk
- cloud-run
- fastapi
- gcp
- mcp
- vertexai


Log in or sign up for Devpost to join the conversation.