Inspiration
Every place on Earth has a story. The field where a decisive battle was fought. The street corner where a movement began. The port city that connected two worlds for five hundred years.
Most of us never hear those stories. Wikipedia gives you a list of facts. Search gives you ten blue links. None of it feels like a story, none of it makes you feel the weight of what happened there.
We were inspired by the way great documentaries work: they don't just inform, they immerse. They weave narration, imagery, and music into something that stays with you. We wanted to build an AI that could do that, not for a fixed set of topics, but for anywhere on Earth, on demand.
That's Tapestry. Click anywhere on a globe. Get a rich, multi-layered historical narrative — with AI-generated imagery, streaming audio narration, a chronological timeline, and four distinct ways to experience the story. Not a search engine. A storyteller.
What it does
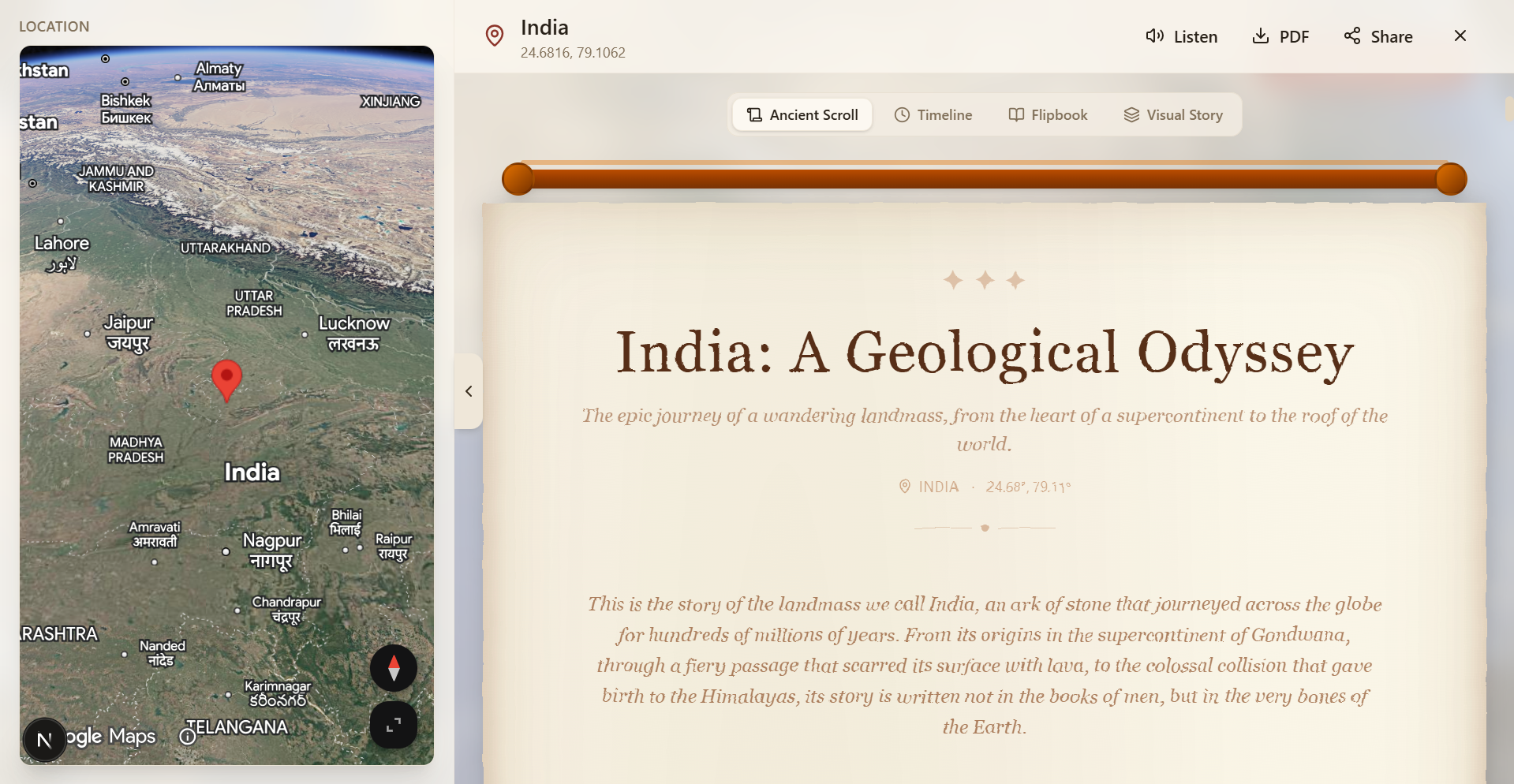
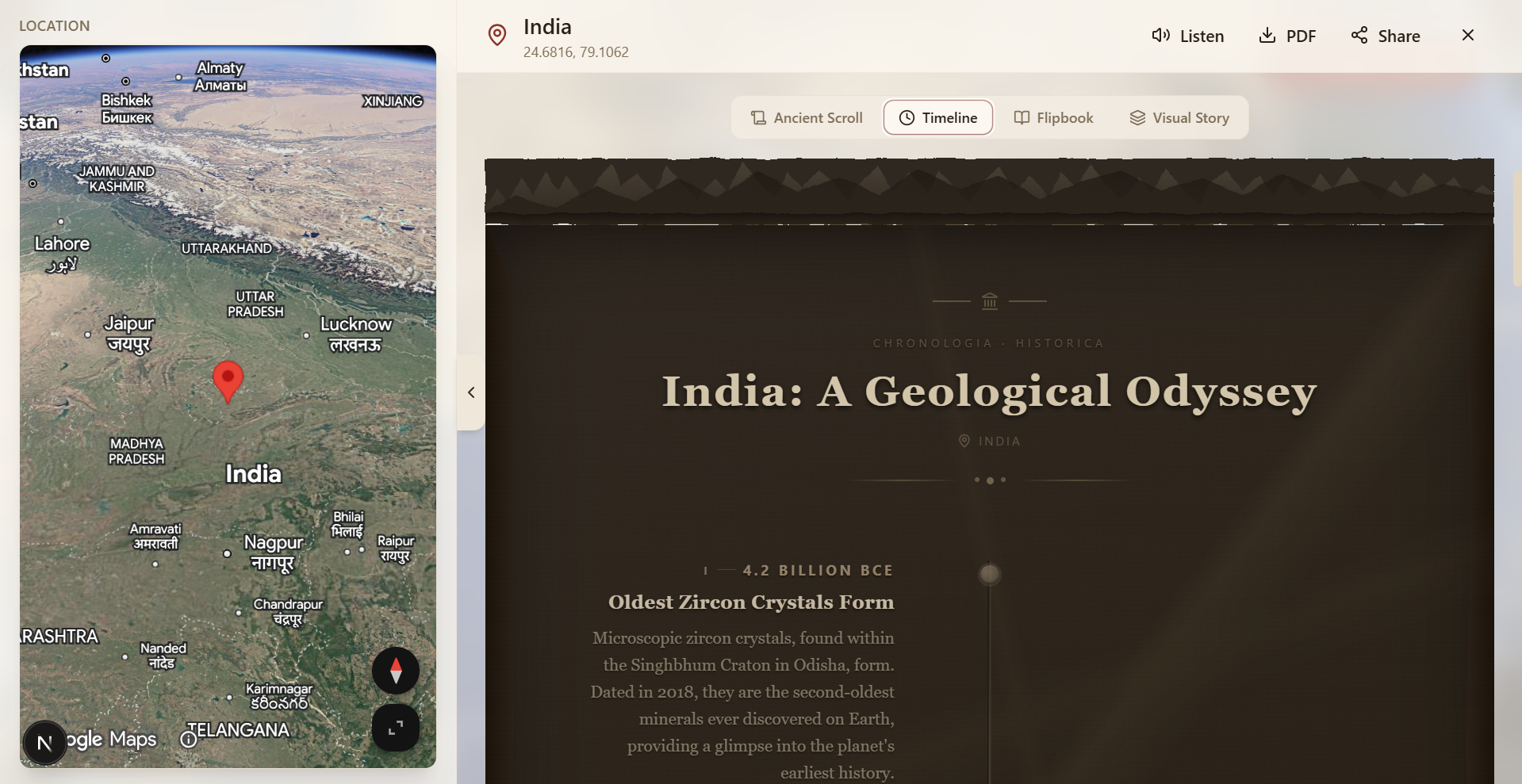
Tapestry is a location-based historical research agent powered by Gemini. You explore an interactive 3D globe, click any location, and Tapestry generates a complete historical narrative about that place — delivered as a seamless interleaved experience of text, AI-generated images, and narrated audio.
The core experience:
- Click anywhere on the globe → Tapestry researches the location using real web sources
- A six-act narrative is generated: Opening → Origins → Pivotal Moments → The Human Story → Present Day → Closing
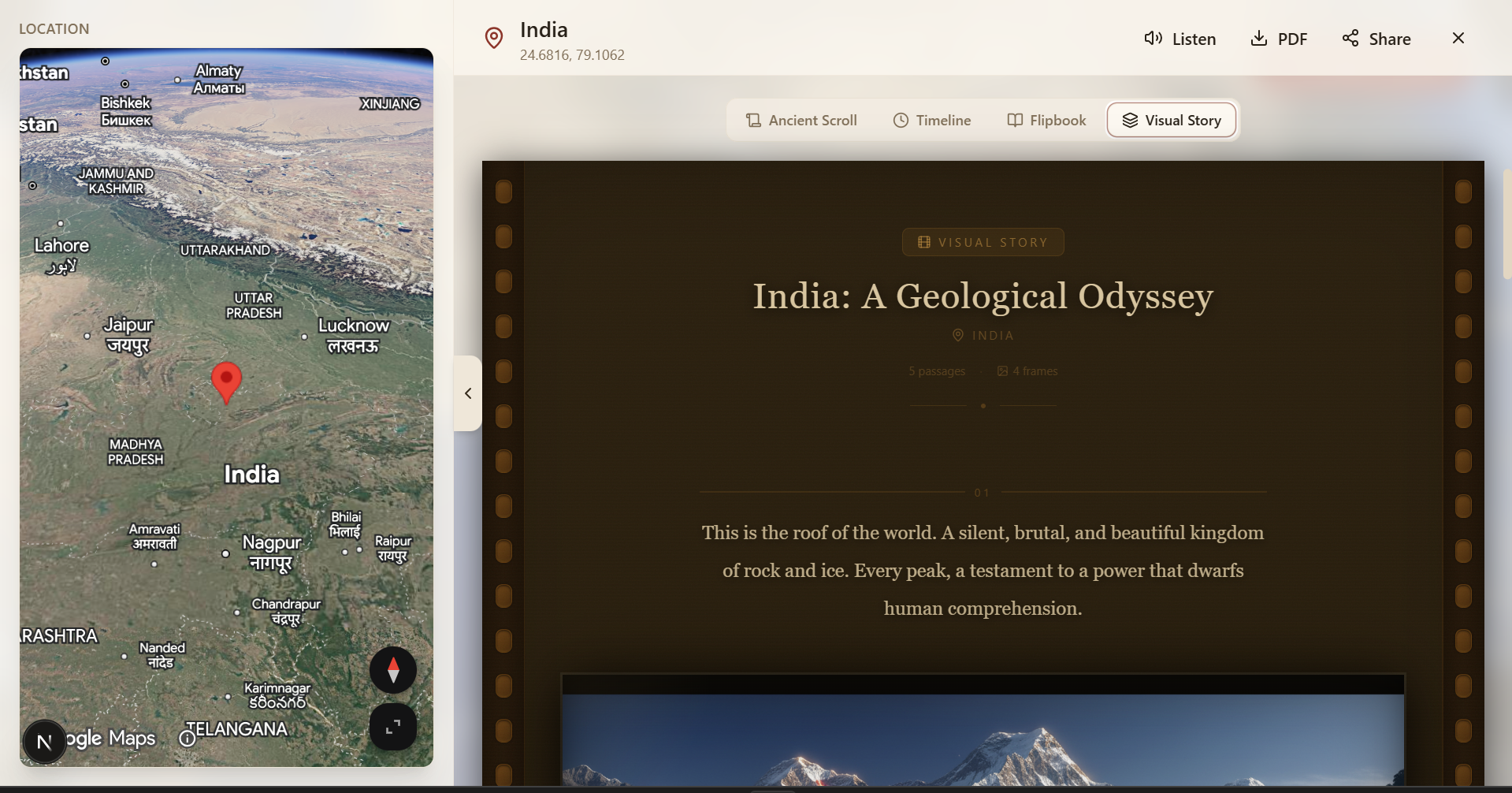
- A Visual Story is generated: an interleaved sequence of cinematic prose passages and AI-illustrated images, designed together by Gemini in a single pass
- Hit "Listen" and the narration streams as audio — documentary-style voice, playing within seconds
Four ways to experience the same story:
- Ancient Scroll :- parchment paper with wooden rollers, SVG displacement filters for torn edges, parallax stain overlays, drop caps, ornamental flourishes
- Stone Tablet :- dark granite timeline with genuinely rough-hewn edges (multi-layer clip-path polygons + SVG displacement), chiseled text, Roman numerals,
whileInViewanimations - Celluloid Film :- the interleaved Visual Story rendered as a vintage film strip: warm amber-brown, sprocket holes, film grain filter, screenplay intertitles, projected slide imagery
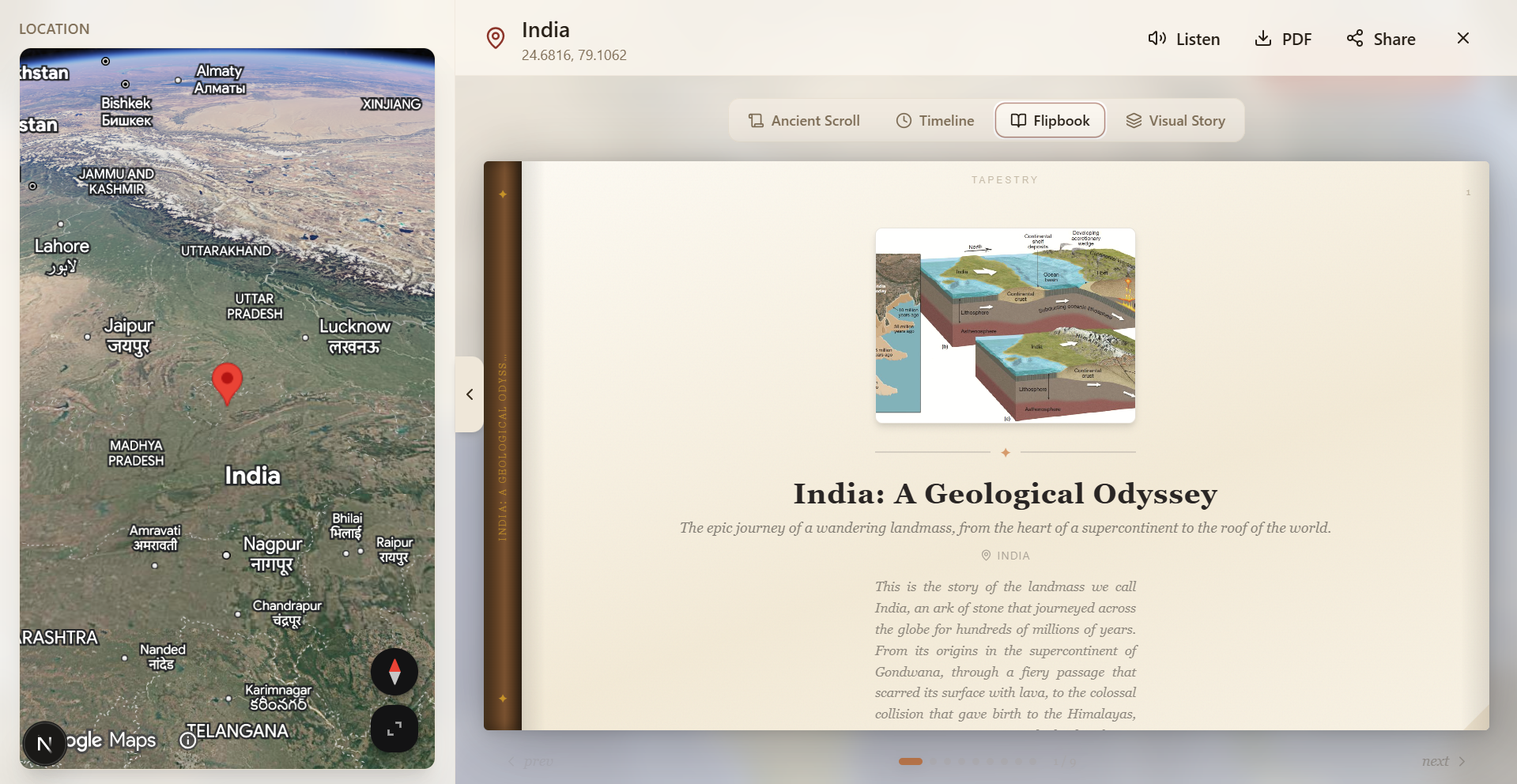
- Hardcover Book :- a leather-spined flipbook with a real page-fold animation: two stacked layers, the destination page underneath, the current page folding away with
rotateYandbackfaceVisibility
Additional features:
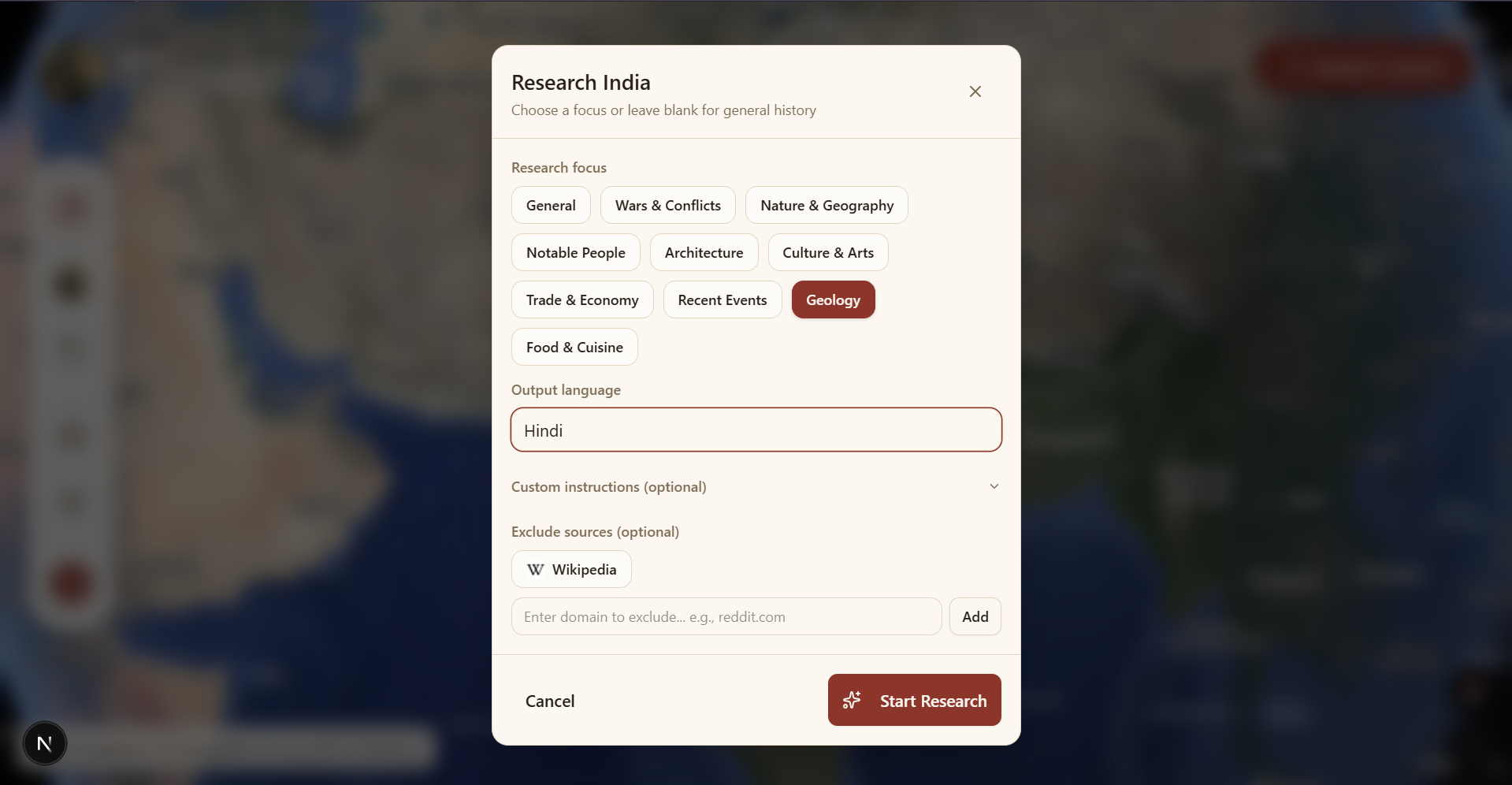
- Full translation into 15+ languages via Google Cloud Translate
- Research history :- every story is saved and accessible from the sidebar
- Public share links :- any story can be shared via a unique token URL
- PDF export via react-to-print
How we built it
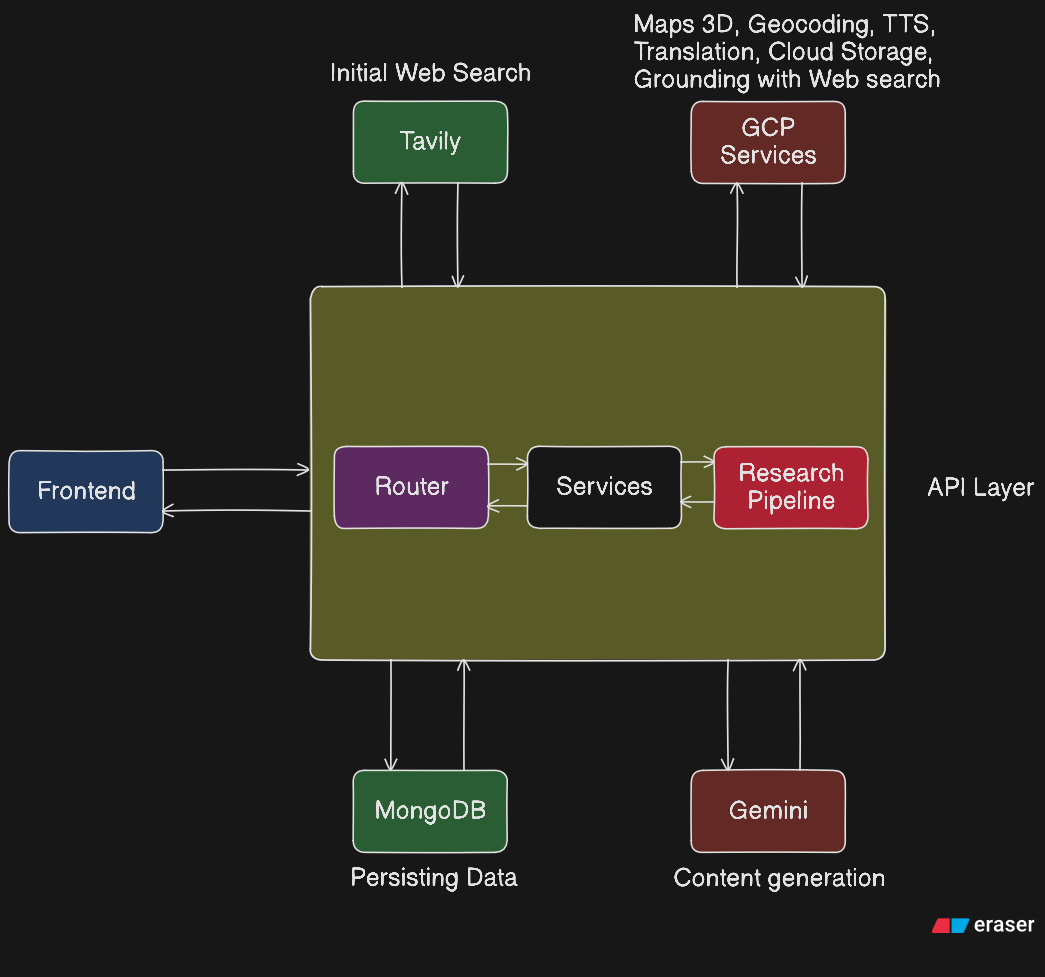
The research pipeline is a multi-stage SSE stream:
- Deep Research :- Tavily fetches real web sources for the location. Gemini synthesizes them into a structured
ResearchOutput(typed schema: six stages, content blocks, timeline entries, source citations withgroundedflags). - Visual Storytelling :- A second Gemini pass generates the interleaved narrative: a JSON array of
{ type: "text" | "image", content }objects where prose and image prompts are designed together in a single generation pass. - Image Generation :- Each image prompt is sent to Google Imagen (Vertex AI) in parallel. Images stream to the client as they complete and are stored in Google Cloud Storage.
- Audio Narration :- The full narrative is split into ~50-word chunks at sentence boundaries, each synthesized by Google Cloud Text-to-Speech (
en-US-Journey-D, pitch-1.0, rate0.95x) and streamed as SSE. Playback starts on the first chunk while the rest generate.
Tech stack:
- Frontend: Next.js 15, TypeScript, Tailwind CSS, Framer Motion, Three.js (globe)
- AI: Gemini 2.0 Flash (research + storytelling), Google Imagen via Vertex AI (image generation)
- Google Cloud: Cloud Text-to-Speech, Cloud Translate, Cloud Storage, Maps Embed API, Cloud Run (deployment)
- Data: MongoDB (research persistence, history, share tokens)
- Auth: JWT-based auth with bcrypt
The entire pipeline streams :- users see live progress updates as each stage completes, images populate as they generate, and audio plays within seconds of clicking "Listen".
Challenges we ran into
Interleaved output consistency :- Getting Gemini to reliably output a well-structured interleaved JSON array, with image prompts that genuinely complement the surrounding prose rather than being generic, required significant prompt engineering. The final prompt includes explicit beat-length constraints, examples of good vs. bad image descriptions, and a directive to describe what the camera sees rather than abstract concepts.
TTS streaming state machine :- The audio player has four states (idle, loading, playing, paused) and a chunk queue that fills asynchronously while playback is already running. The original implementation had a stale closure bug :- playNextChunk was defined with empty useCallback deps, freezing a stale reference to the queue. Fixed by storing the function in a ref updated every render, so async callbacks always call the current implementation.
Page-fold animation :- The Flipbook's page-turn went through three rewrites. react-pageflip takes over the DOM with absolute positioning and breaks Tailwind's fluid layout. Framer Motion AnimatePresence with rotateY looked like a slide, not a fold. The final version uses two stacked layers — destination page underneath, current page folding away on top, with backfaceVisibility: hidden on both faces. That's what makes it feel like a real page turning.
Stone tablet edges :- Getting the timeline edges to look genuinely rough required two overlapping clip-path polygon layers (outer chip + inner fracture), an SVG displacement filter on top, and a fracture highlight line at the break. The final polygon has 40+ vertices per edge.
Image generation latency :- Imagen takes 3–8 seconds per image. With 6–10 images per story, sequential generation would take over a minute. We generate in parallel and stream images to the client as they complete, so the Visual Story populates progressively.
Accomplishments that we're proud of
The interleaved output is genuinely interleaved. Gemini writes the prose and the image prompts in the same generation pass, each image is designed to complement the passage before it. The result is a coherent visual arc, not illustrated paragraphs. The images feel directed.
Three modalities, one story. Text, AI-generated imagery, and streaming audio narration all active simultaneously, you can read along, look at the images, and listen at the same time. That's the full Creative Storyteller brief in one experience.
Grounding by architecture, not by prompt. We retrieve real web sources before Gemini writes a word. Every claim is synthesized from those sources. Every source is cited with a grounded flag. The output schema validates structure before anything reaches the user. Hallucination is made structurally harder, not just discouraged.
Four display modes, four material identities. Parchment, stone, celluloid, paper, each mode has its own visual metaphor that reinforces the content. The stone tablet feels ancient. The film strip feels like a documentary. The aesthetic is part of the storytelling.
The pipeline streams end-to-end. Research progress, image generation, audio chunks, everything streams. Users watch the story being made in real time. Audio plays within seconds of clicking "Listen". There are no loading screens.
What we learned
The schema is the product. The ResearchOutput schema, six stages, typed content blocks, timeline entries — is the contract between the AI and every display mode. Getting it right early meant we could build four completely different UIs on top of the same data without touching the pipeline.
True interleaved output is qualitatively different from "generate text, then add images." When Gemini writes prose and image prompts in the same pass, the images feel like they were directed, not retrieved. That's the difference between a creative director and a search engine.
Grounding is an architecture decision, not a prompt instruction. Retrieve first, synthesize second, validate schema third, cite everything fourth. The prompt instruction is the last line of defense. The architecture is the first.
Audio completes the triad. Text and images are rich. Add narration and it becomes something you can close your eyes and listen to. The three modalities together are more than the sum of their parts.
Streaming changes the perceived experience more than raw speed does. A 30-second wait with live progress feels faster than a 10-second spinner. Showing the work builds anticipation and trust.
What's next for Tapestry
- Video generation :- adding a short cinematic video clip per story section using Veo, making the film strip mode a true video experience
- Live API integration :- a conversational mode where you can ask follow-up questions about the location while the story is playing, powered by Gemini Live API
- Collaborative stories :- multiple users contributing annotations, corrections, and personal memories to a shared location story
- Mobile app :- point your phone camera at a landmark and get the story in real time, using Gemini's vision capabilities to identify the location
- Educator mode :- structured lesson plans generated alongside the narrative, with discussion questions and primary source links, for classroom use
Built With
- css
- gcp
- gemini
- google-maps
- html
- mongodb
- nextjs
- react
- tailwindcss
- tavily
- typescript

Log in or sign up for Devpost to join the conversation.