-
-

Our Team Profile
-
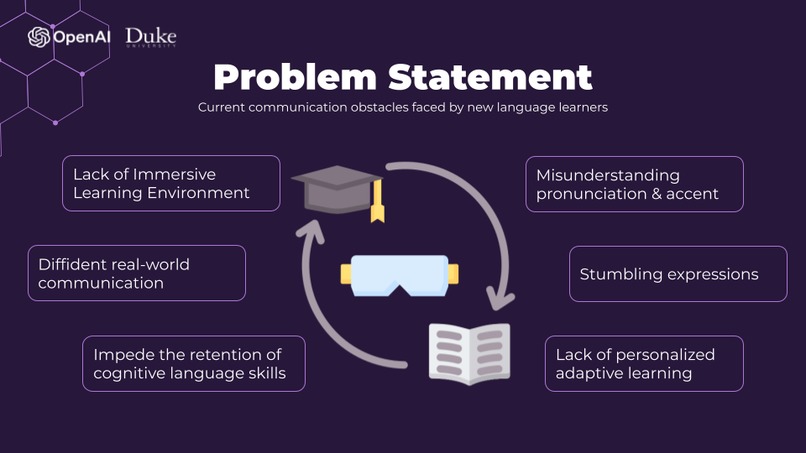
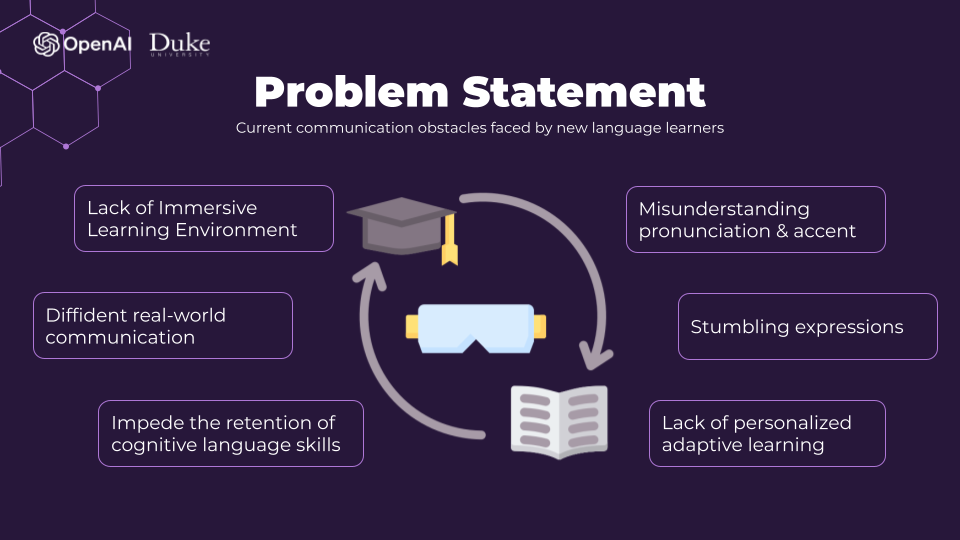
Problem Statement for new language learners
-
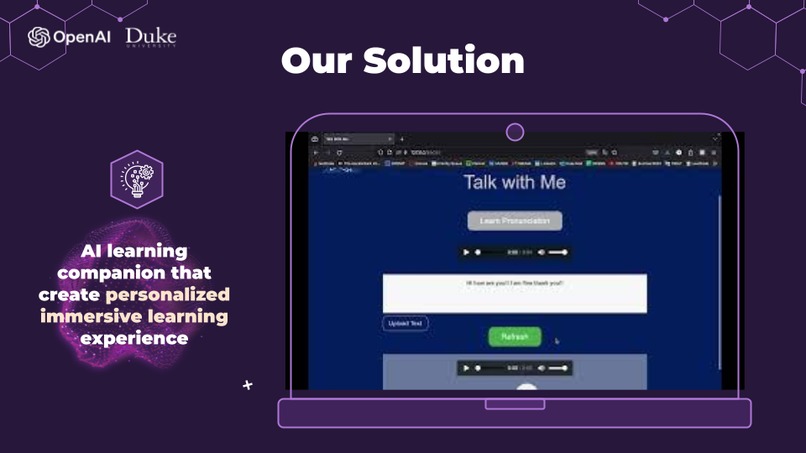
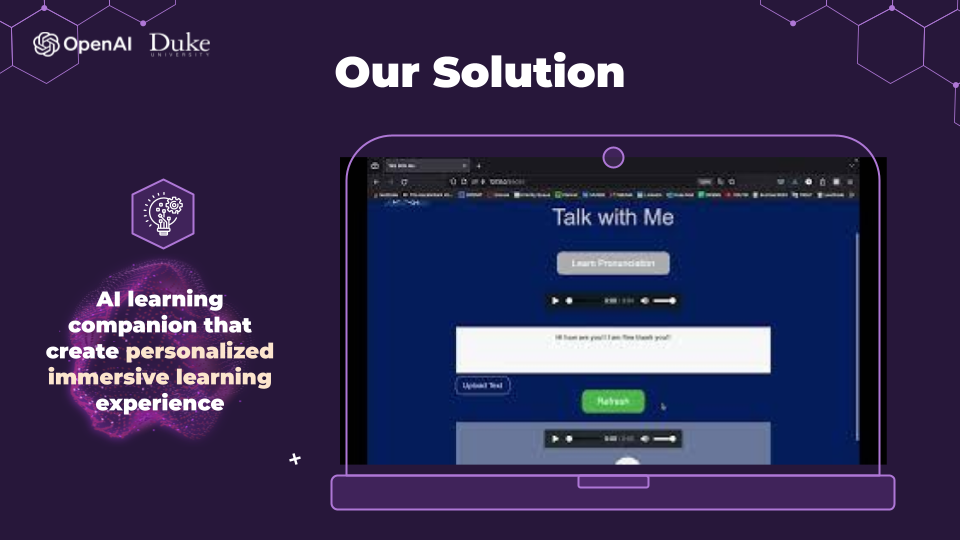
Our solution
-

Technical Implementation with programming and APIs
-
Our Solution and data collection demo
-

Our B2B and B2C Business Model
-
Product Development and Iteration in the future
-
Market Analysis Reference
-
Market Analysis Reference
-
Market Analysis Reference
-
Market Analysis Reference
-

Thank you!




Inspiration
From a spark of inspiration ignited by one of our team-member's quest for perfecting his English pronunciation, a groundbreaking idea was born. Picture this: an extension that not only allows language enthusiasts to practice pronunciation by reading along with their favorite scripts but also offers instant, precise feedback. This isn't just a mere concept; it's a revolution in language learning.
With over six years of experience in educational technology, we've navigated through a sea of products, yet none could match our vision. That's when we decided to take the reins and craft this innovative solution ourselves. We envisage a tool that transcends boundaries, becoming an indispensable ally not only for casual learners but also for professionals honing their presentation and speech skills.
Envision an application that evolves with you, akin to the dynamic ChatGPT-3.5, and embraces the ethos of open-source collaboration. Our aspiration is to integrate this marvel into the OpenAI ecosystem, harnessing the unparalleled language models and algorithms. Users won't just benefit from an ever-expanding corpus of language but will also have the unique opportunity to acquaint themselves with diverse global accents.
TalkwithMe Functionality
Our solution to address the challenges faced by new language learners is the development of an AI learning companion. This companion will be designed to create a "Personalized Immersive Learning Experience." By leveraging advanced AI technologies, we aim to offer learners a tailored and immersive journey in acquiring a new language.
Technical Implementation
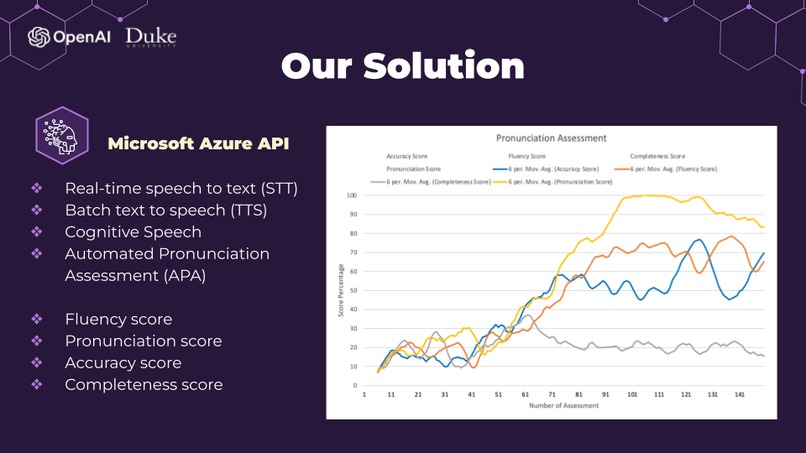
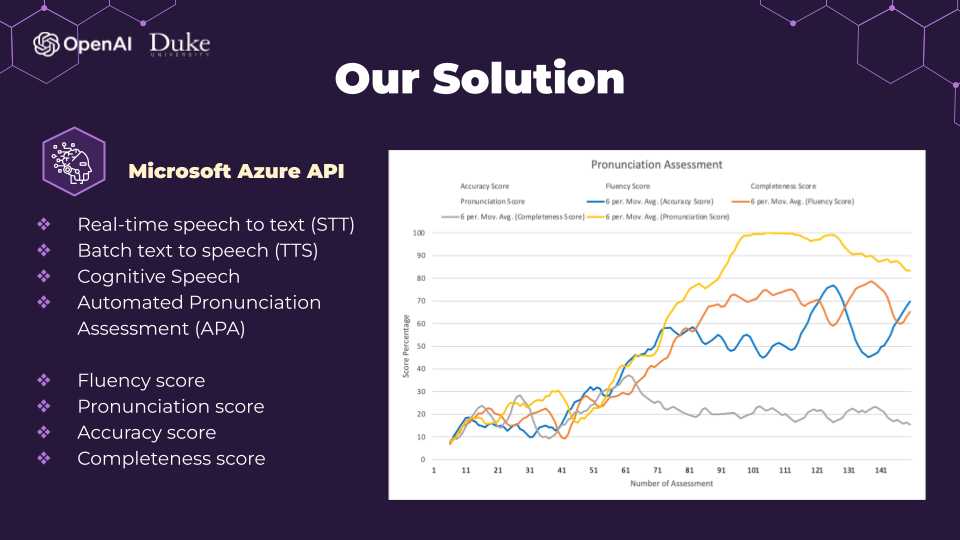
The general pipeline for our Minimum-Viable-Product is divided into two independent processes: Text-to-Speech (TTS) and Automatic Pronunciation Assessment (APA). Both are done with the help of Microsoft Azure.
Text-to-Speech (TTS)
The initial step in the technical implementation of text-to-speech involves obtaining user input text. This input is provided via a text box or as txt file. The user's input serves as the content that needs to be converted into synthetic speech.
Once the user's input is acquired, we convert the input into an audio blob. This step was done with the help of Microsoft Speech Synthesizer class (Updated in September 2023).This API takes the input text and returns an audio blob, which is essentially a binary audio data representation.
Within the Microsoft SpeechSynthesizer class, we used specific configurations to fine-tune the text-to-speech process. These configurations are essential for customizing the synthesized speech to meet the user's requirements. The language setting is crucial and depends on the speaker, and in this case, it is set to "en-US," ensuring that the generated speech is in US English. Furthermore, the choice of voice is significant. The "Microsoft Server Speech Text to Speech Voice (en-US, JennyNeural)" is specified, which is what we believed to be the most natural and realistic voice provided.
After the text-to-speech conversion is successfully executed, the resulting audio blob is returned to the user interface by creating an audio bar element in JavaScript. The audio blob contains the synthesized speech, and users are provided with the capability to play and stop it at their discretion.
Automatic Pronunciation Assessment (APA)
This pipeline begins with user input in the form of audio, which is captured and processed using the Media Capture and Streams API in JavaScript. The main objective here is to assess the user's pronunciation based on the reference text they provide.
To initiate the pronunciation assessment pipeline, we create a WAV blob from the user's input audio. This allows us to efficiently work with the audio data. The audio data and reference text are then extracted from the user's request.
Once we have the necessary data, we proceed to assess the pronunciation. The audio data is read in manageable chunks, here we chose 1024 bytes which is the typical size. These audio data chunks are then sent to the Azure Cognitive Speech API, configured with Pronunciation Assessment settings. The key configurations include:
- ReferenceText: The user-provided text is used as the reference for pronunciation assessment. It is a crucial element in evaluating the user's speech.
- Grading System: The Grading System is set to a HundredMarks scale, providing a floating-point value ranging from 0 to 100. This scale serves as a comprehensive measure of pronunciation quality.
- Granularity: Pronunciation assessment is performed at the Phoneme level. Phonemes are the fundamental sound units in American English and are represented using the American English Phoneme Representation released by Microsoft in April 2012 (SAPI 5.3). For instance, the word "hello" is represented as "h eh l ow." The word “photosynthesis” is represented as “f ow t ax s ih n th ax s ih s”.
- EnableMiscue: This configuration is set to "True," indicating that pronunciation errors or mispronunciations are considered in the assessment.
The result of the assessment is provided in the form of JSON data, which includes both Word Level and Phoneme Level evaluation. The scoring process involves comparing the spoken phonemes from the user's audio input with the expected phonemes from the reference text and computing a confidence score on how well it matches.
The four most significant features are extracted from the JSON results and stored persistently in a CSV format. These features are presented to the user, allowing them to track their pronunciation progress effectively. The four primary features include:
- Accuracy Score: This score quantifies the accuracy of the user's pronunciation, providing insight into how well they match the reference text.
- Fluency Score: The fluency score measures the smoothness and flow of the spoken words and phrases, giving users valuable feedback on their fluency.
- Completeness Score: This score assesses how comprehensively the user pronounces words and ensures that no parts of the text are omitted.
- Pronunciation Score: The overall pronunciation score combines various aspects of pronunciation quality and fluency, offering a comprehensive evaluation of the user's spoken language.
Challenges and Overcome
One of the initial hurdles was conducting a comprehensive literature review and industry research to identify the best available tools that could be utilized to deliver fast and accurate results. We looked into new papers in NLP from renowned universities about TTS and well-developed AI services from OpenAI, AWS, Google, and we eventually decided to use Microsoft Azure for our task due to the naturalness of its speech synthesis models and easy to configure parameters.
A significant milestone we overcame was figuring out how to seamlessly combine the Text-to-Speech (TTS) and Automatic Pronunciation Assessment (APA) pipelines to create a user experience that was both smooth and comfortable. This involved careful configuration and integration of various components to ensure that users could easily transition from generating synthetic speech to assessing their pronunciation with minimal friction.
Other challenges we encountered were programming and implementation tasks, such as how to persist user data into CSV format effectively, how to send requests and combine JavaScript (Frontend) and Python (Backend) without bugs. This involved carefully coordinating the two components to ensure a synchronized and efficient operation. In terms of user interface (UI) design, we needed to create an interface that was not only intuitive and easy to use but also visually appealing. We opted for a Duke-themed color scheme that struck a balance between aesthetics and user-friendliness. These design choices enhanced the overall user experience and usability of our system.
Accomplishments
In our technical achievements for the demo, we successfully integrated various APIs and SDKs provided by Microsoft Azure and deployed them using Flask/Python3. This integration allowed us to create a seamless user experience, combining Text-to-Speech (TTS) and Automatic Pronunciation Assessment (APA) functionalities.
We successfully fine-tuned the parameters and configurations of our models to tailor them to our specific requirements. For the TTS component, we paid careful attention to language settings, ensuring that the generated speech matched the user's preferences. In the Pronunciation Assessment Model, we made key configurations such as granularity and miscue to improve the accuracy of assessments. Additionally, we developed a visually appealing and fully interactive user interface using vanilla JavaScript, HTML, and CSS. This interface facilitated a user-friendly experience, allowing users to interact easily with the system.
We provided a practical and intuitive working prototype designed for people who wish to practice their speaking skills extensively. Furthermore, our efforts were recognized by our peers at a hackathon, where we received excellent feedback from peers. This positive reception is a testament to the potential of our system and its effectiveness in addressing the needs of speakers looking to enhance their pronunciation and speaking abilities.
Lessons Learned
In just two days Hackathon, we turned our vision into reality by completing the Minimum Viable Product (MVP) of our product, surpassing our expectations with its performance. Leveraging the power of Microsoft Azure API, our technical prowess shone through. Our comprehensive market analysis, gave us a competitive edge in the U.S. language learning market.
Pedagogically sound, our product stands out with clear objectives and a tailored learning journey. Whether it's reading full sentences or individual words, learners receive visualized feedback, paving the way for a transformative language learning experience. We're not just building a tool; we're shaping the future of language mastery.
Commercial Viability
Market Overview
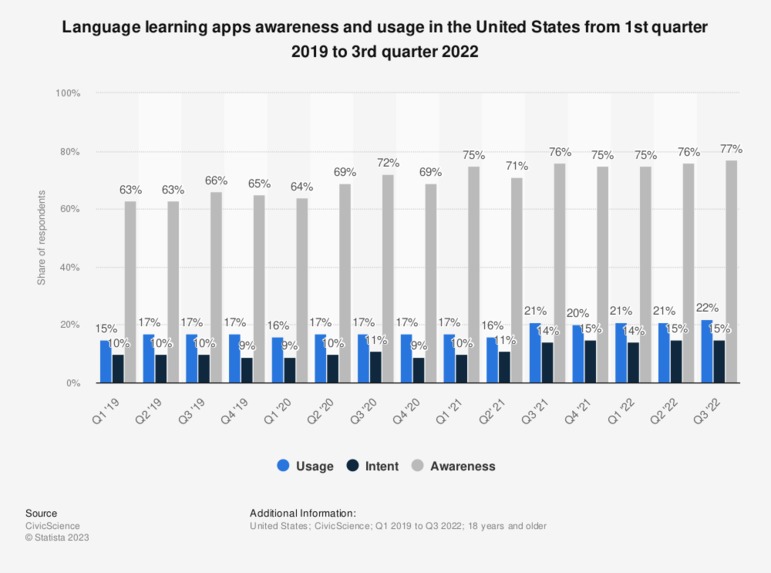
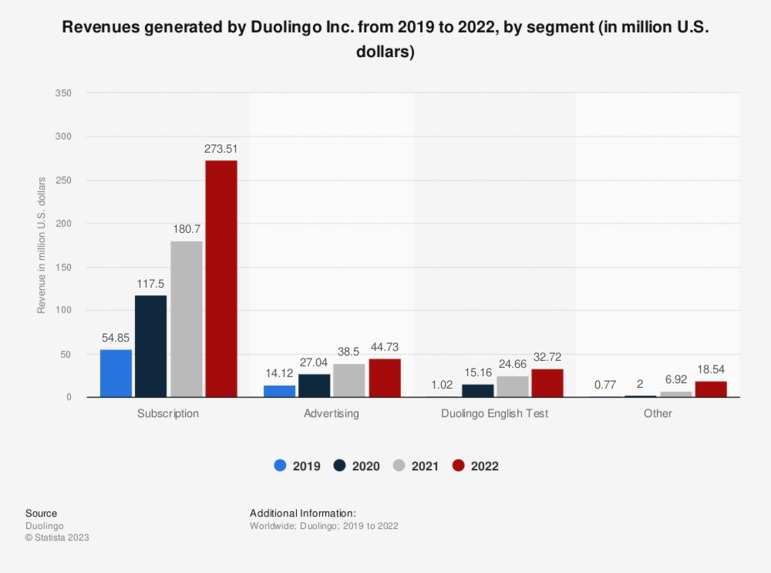
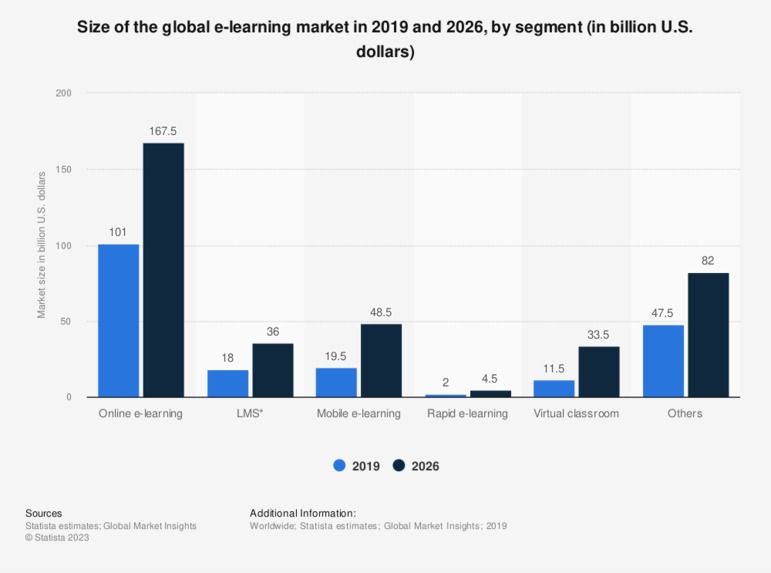
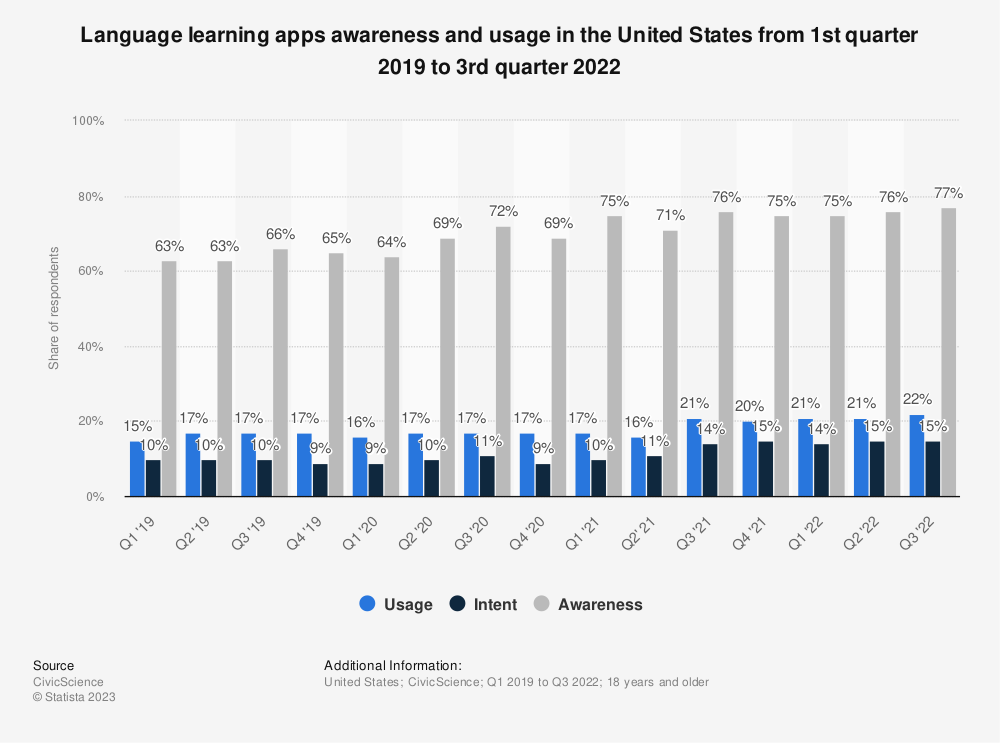
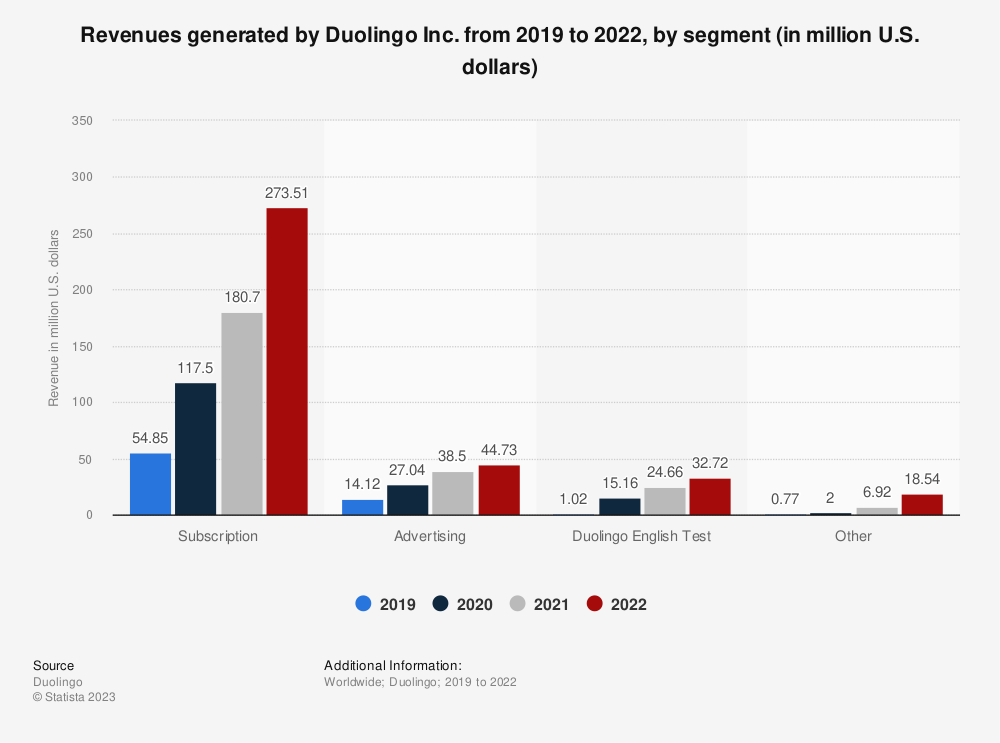
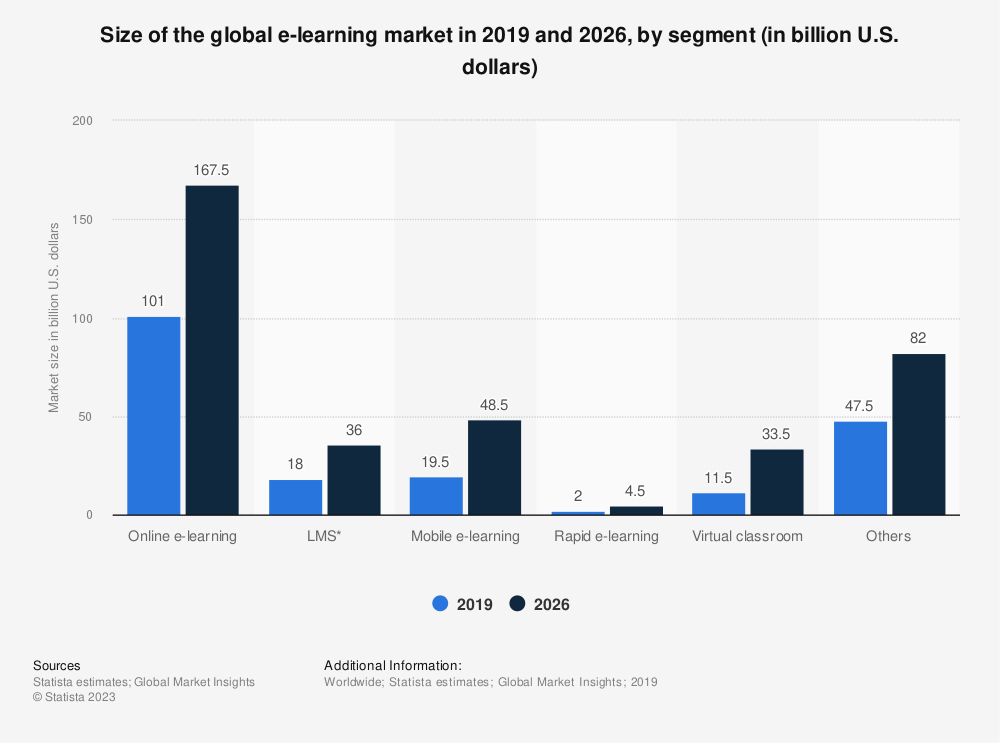
Referencing and analyzing the graph of “Size of Global E-learning market from 2019 to 2026”, “Revenues generated by Duolingo from 2019 to 2022”, and “Language learning apps awareness and usage in the U.S. from 2019 to 2022”, we interpreted:
- Market player strong revenue growth: In 2022, Duolingo Inc. experienced significant growth in its revenues from subscriptions to its premium plan, Duolingo Plus. The revenue reached 273.5 million U.S. dollars, which was more than double the subscription revenues from 2019. This indicates a growing interest in premium language learning services, while the diversified revenue stream suggest that the company is not solely reliant on one source of income. Our product TalkwithMe will also be able to capture part of the market.
- Prospective Market Growth: In a survey conducted in the United States during the third quarter of 2022, 77 percent of respondents were aware of mobile language learning apps. This suggests a high level of awareness and interest in such apps. Additionally, 22 percent of respondents reported using mobile language learning apps. With users demonstrating a growing interest and demand, the global e-learning market is expected to reach nearly 400 billion U.S. dollars by 2026. This represents significant growth compared to its size of almost 200 billion U.S. dollars in 2019. The learning management system (LMS) market generated around 18 billion U.S. dollars in 2019. Our Chrome Extension business model serves as a more preferred and convenient innovation.
- Competitive landscape with unique feature: Though Duolingo and Babbel have a stronger presence in the online language learning market, we are targeting a unique niche of new language learners that have a customized and immersive learning needs that will improve communication and speech delivery skills. In summary, the online language learning market is experiencing robust growth, with Duolingo being a prominent player, while still a large proportion of unexplored users. The increasing demand for premium language learning services, diversification of revenue sources, and the expanding global e-learning market all indicate a positive outlook for this industry. Additionally, the popularity of mobile language learning apps suggests that learners are increasingly turning to digital platforms to acquire language skills.
Business Model
Our business model entails a multifaceted approach to resource allocation and user acquisition:
- Free Chrome Extension (50%): We anticipate that approximately half of our resources and potential users will originate from the deployment of a free Chrome extension. This extension will cater to both B2B and B2C segments within the Chrome user community, addressing their speech-related needs. This approach serves as a fundamental pillar for market penetration.
- Organizational Collaborations (30%): A significant portion, 30%, of our resources and prospective user base will be cultivated through strategic collaborations with organizations and companies with presentation requirements. By integrating our extension into their corporate internal websites, we aim to meet the specific demands of these entities, ensuring seamless speech-related functionalities.
- Premium Subscription Promotion (20%): To establish a sustainable revenue stream, we will allocate 20% of our resources to promotional activities targeting users willing to invest in premium subscription plans. This segment constitutes a primary revenue source and will receive targeted marketing efforts to enhance subscription adoption.
Future Steps
Our future product development strategy encompasses the following key objectives, designed to enhance user experience and engagement:
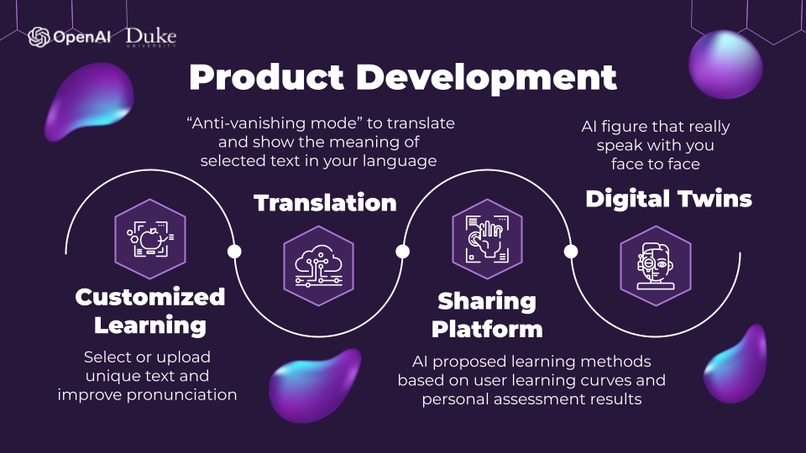
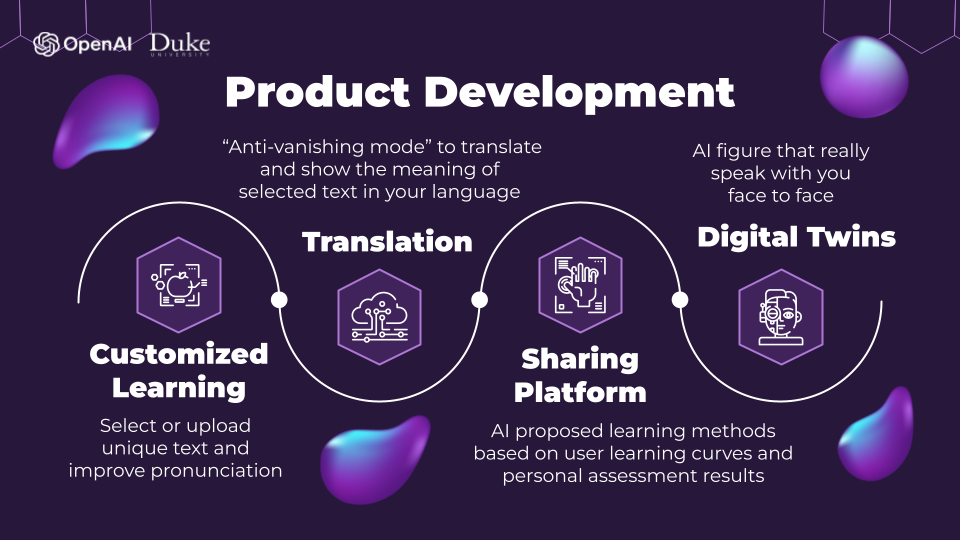
Customized Learning Enhancement: We aim to facilitate personalized learning experiences by enabling users to select or upload distinct text content, with a focus on refining pronunciation. This feature empowers individuals to address their unique linguistic challenges and improve their language proficiency effectively.
Innovative Translation with "Anti-Vanishing Mode": Our product will introduce a cutting-edge "Anti-vanishing mode" for translation, providing users with real-time, context-aware translation capabilities. This ensures that the selected text is not only translated but also comprehensively explained, bridging language gaps and enhancing linguistic comprehension.
Collaborative Learning Platform: To foster efficient and collaborative user study, our platform will introduce a shared learning space. Leveraging AI capabilities, the platform will recommend learning methods based on collective user learning curves and individual assessment results. This collective intelligence approach will empower users to optimize their learning strategies.
Digital Twins for Personalized Interaction: We are pioneering the development of "digital twins" that will create AI representations tailored to individual users. These digital figures will engage users in face-to-face interactions, offering conversational and instructional support, further enhancing the immersive and personalized nature of our plan
Built With
- apa
- azure
- chatgpt
- csv
- excel
- javascript
- json
- microsft
- pandas
- powerpoint
- pronunciationassessment
- python
- speechstudio
- statista
- tts-api.com



 Meng")


Log in or sign up for Devpost to join the conversation.