-
-
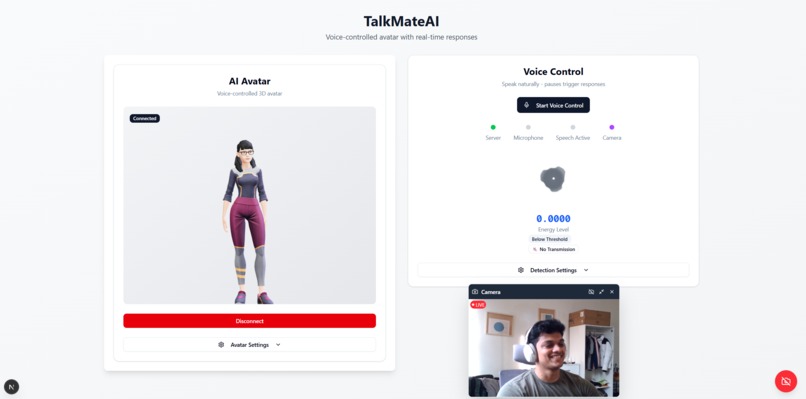
UI
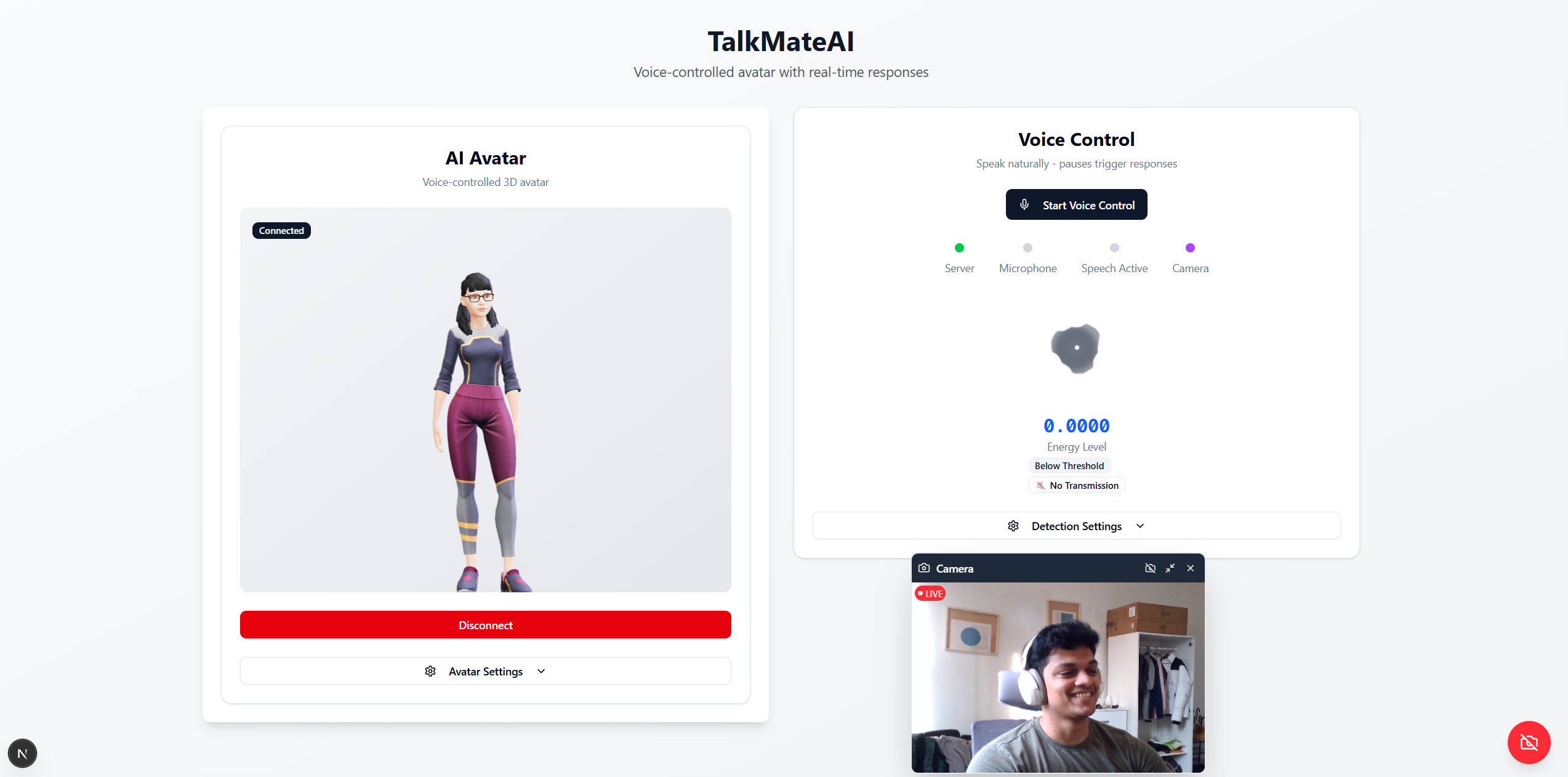
🎭 TalkMateAI - Real-time Voice-Controlled 3D Avatar with Multimodal AI
Inspiration
I was frustrated with the disconnect between advanced AI capabilities and clunky chat interfaces. Why are we still typing to AI in 2025? Humans communicate through voice, expressions, and visual context - so should AI. I wanted to create an experience that feels like talking to a real person, not a chatbot.
The breakthrough moment came when I realized I could combine multiple cutting-edge models (Whisper for speech, SmolVLM2 for vision, Kokoro for natural TTS) into a seamless real-time pipeline that actually works locally on consumer hardware.
What it does
TalkMateAI transforms boring text-based AI interactions into immersive voice conversations with photorealistic 3D avatars. Simply speak naturally - the AI sees through your camera, processes your speech in real-time, and responds with perfect lip-sync and natural voice. It's like having a digital human that understands both what you say AND what you show it.
How we built it
Architecture:
- Backend: Python FastAPI server with WebSocket communication
- Frontend: Next.js with TypeScript and real-time audio processing
- AI Pipeline: Whisper → SmolVLM2 → Kokoro TTS with native timing extraction
- 3D Rendering: TalkingHead.js for avatar animation and lip-sync
Key Technical Decisions:
- Local-first approach - Everything runs on your machine for privacy and speed
- Streaming architecture - Audio is processed and returned in chunks for minimal latency
- Native timing integration - Extract word-level timing from Kokoro TTS for perfect lip-sync
- Voice Activity Detection - Smart audio segmentation based on speech patterns
- Multimodal integration - Seamlessly combine camera input with voice commands
Tech Stack:
- Models:
openai/whisper-tiny,SmolVLM2-256M-Video-Instruct,Kokoro TTS - Backend: PyTorch, Transformers, Flash Attention 2, FastAPI, WebSocket
- Frontend: React, Web Audio API, AudioWorklet, Tailwind CSS
- 3D: TalkingHead library for avatar rendering
Challenges we ran into
1. Audio Synchronization Hell
Getting perfect lip-sync was the hardest part. Initially tried estimating timing from text, but it was always off. The breakthrough was extracting native timing data directly from Kokoro TTS tokens. ( I didn't know it had that at first :) )
2. Real-time Performance
Running Whisper + SmolVLM2 + Kokoro simultaneously on consumer hardware pushed memory limits. Solved through:
- Careful model loading/unloading
- Streaming audio processing
- Optimized tensor operations with Flash Attention 2
3. WebSocket State Management
Coordinating audio streams, interrupts, and model processing across WebSocket connections required building a robust state machine to handle edge cases.
4. Multimodal Data Flow
Synchronizing audio segments with camera captures while maintaining real-time performance needed careful pipeline orchestration.
Accomplishments I'm proud of
- Sub-second response times - Average 800ms from speech to avatar response
- Perfect lip-sync - Native timing integration creates human-like mouth movements
- True multimodal AI - Seamlessly combines voice and vision for natural interactions
- Local deployment - No cloud dependencies, full privacy control
- Real-time streaming - Chunked audio generation for immediate feedback
What's next for TalkMateAI
- Custom avatar creation and personalization
- Conversation memory and context retention
- Plugin system for extending capabilities (MCP?)
- Emotion recognition and empathetic responses
- Multi-avatar conversations and group interactions
Built With
- fastapi
- flash-attention-2
- huggingface
- kokoro
- next.js
- python
- smolvlm2
- transformers
- typescript
- websockets
- whisper


Log in or sign up for Devpost to join the conversation.