-
-
-
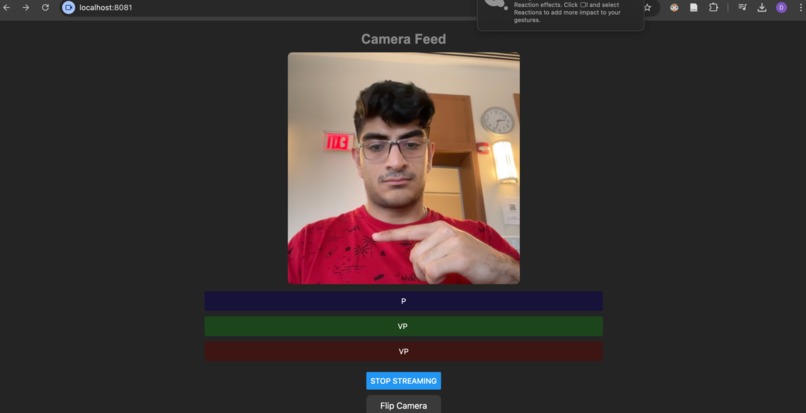
char-level real time translation
-
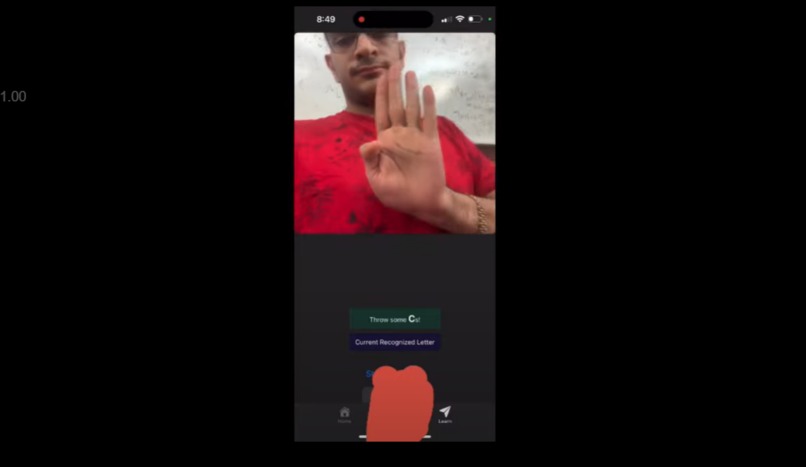
ASL game
-

word-level real time translation

Inspiration
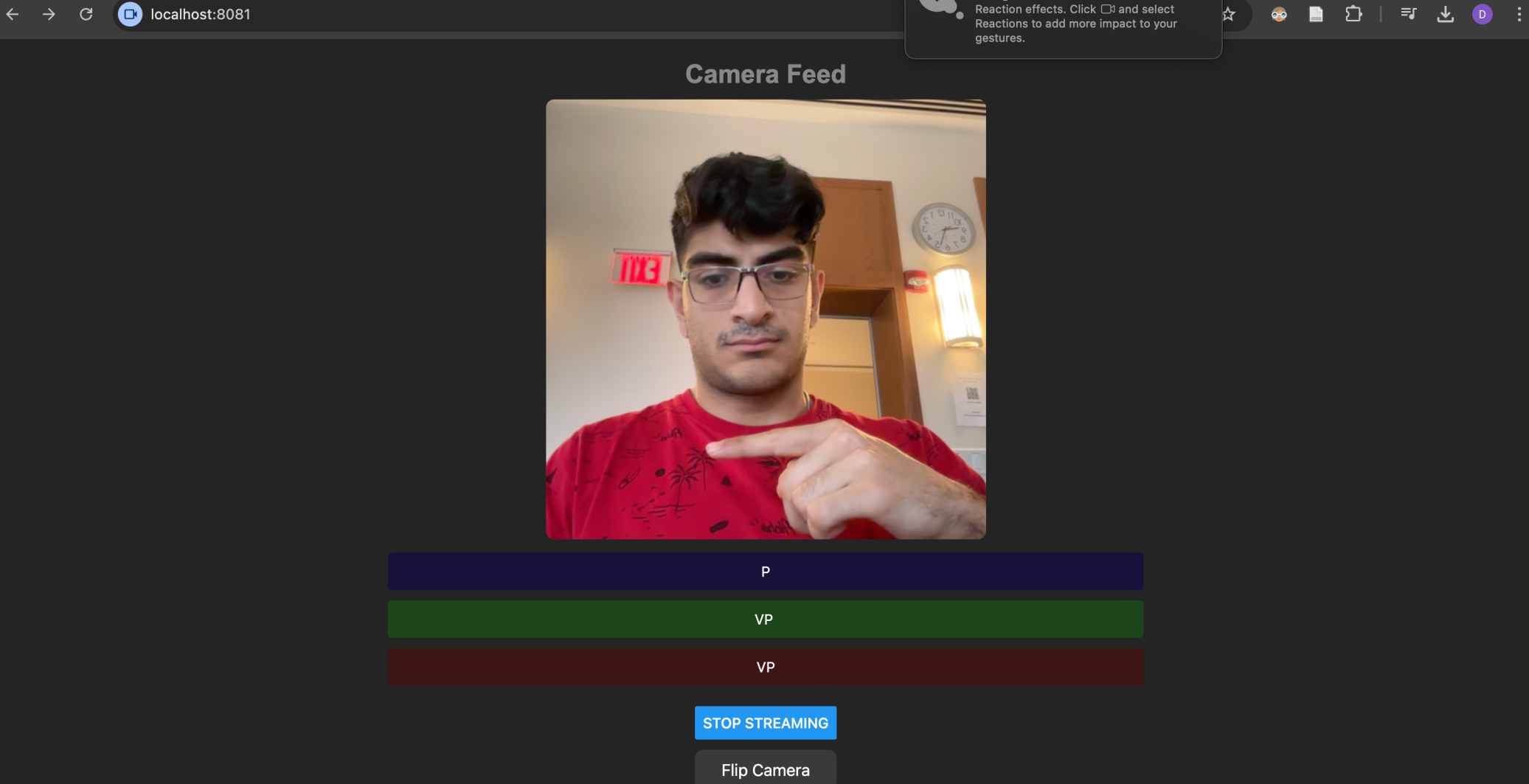
People with hearing disabilities sometimes have difficulty communicating ideas, especially since not many people speak sign language. Our goal is to fix this problem by developing an app that translates sign language to text using both vision models and language models to make this communication happen in real time.
To make learning inclusive and fun, we also added a mini-game that helps users practice and learn ASL interactively.
What it does
The app uses the camera to detect sign gestures and displays real-time subtitles. It supports:
Character-level translation:
- MediaPipe landmark extraction
- Custom dataset + classifier based on Random Forest Model
- LLM-powered autocomplete for fast, predictive text
- MediaPipe landmark extraction
Word-level translation:
- Pretrained I3D (dataset: WLASL-2000)
- Fine-tuned T5 (dataset: ASLG-PC12) to translate glosses (e.g., “NAME WHAT”) → natural English (“What’s your name?”)
- Pretrained I3D (dataset: WLASL-2000)
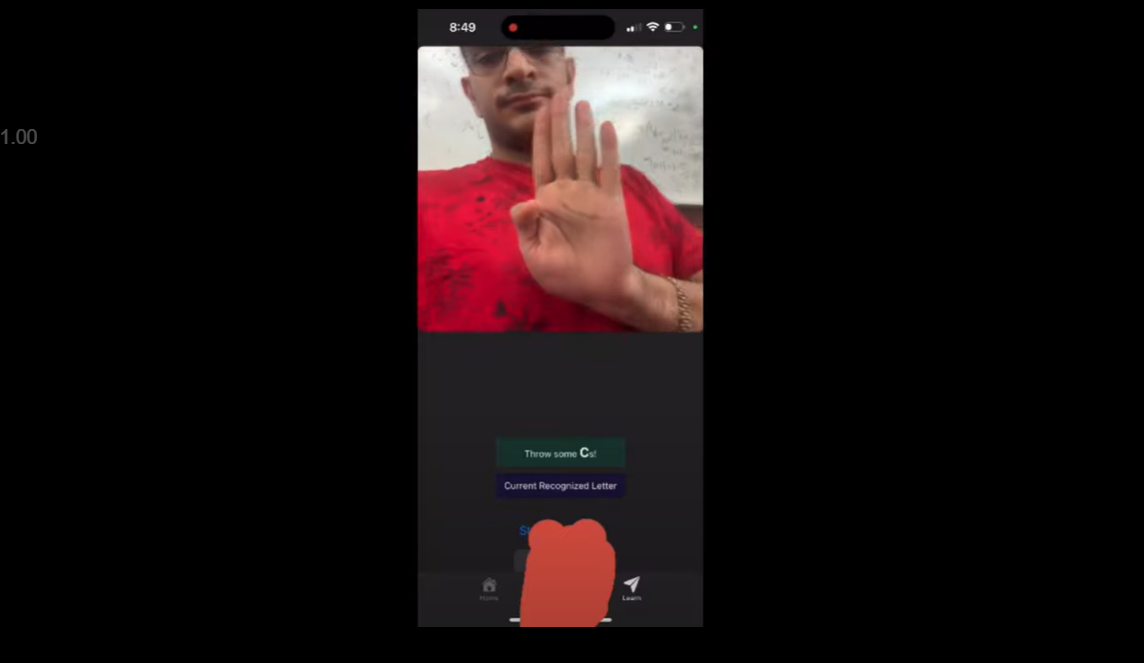
Mini-Game Mode
- ASL learning game: users must perform correct characters to progress
How we built it
- Frontend: Expo
- Backend: Modal for scalable model inference
Vision Models:
- MediaPipe landmarks + custom character classifier
- I3D for word-level classification, which has been trained on 26,027 WLASL word videos
- MediaPipe landmarks + custom character classifier
Language Models:
- T5 fine-tuned on ASLG-PC12
- Gemini API for real-time smart suggestions
- T5 fine-tuned on ASLG-PC12
Challenges we ran into
- Expo has some issues with WebSocket on phone
- Modal has some initial latency that causes lags when users query the model for the first time
- In the word-level translation, it has lower accuracy compared to the character level because it has to classify the words in the 2,000 WLASL dictionary.
Accomplishments that we're proud of
- Dual-level gesture recognition (char + word)
- Fine-tuned T5 for ASL gloss-to-English
- Real-time interactive app with:
- Subtitle overlay
- ASL mini-game
- LLM-powered suggestions
- Subtitle overlay
📚 What We Learned
- Modal = dead-simple scalable ML infra
- Expo = rapid cross-platform mobile dev
- LLM + vision fusion dramatically improves UX
🔮 What's Next
- Context-aware suggestions (e.g., location, topic)
- Text-to-speech for full bidirectional comms
- Multi-person sign detection
- Expanded vocab and regional dialect support
Built With
- aslg
- expo.io
- gemini
- i3d
- mediapipe
- modal
- python
- pytorch
- t5
- typescript
- webcam
- wlasl


Log in or sign up for Devpost to join the conversation.